
Joined February 2026
- Tweets 42
- Following 31
- Followers 67
- Likes 124
1 Photos and videos


RLMS are the new reasoning models
Apr 20

Incredibly well written blog on RLMs by @raw_works, highly recommend you read it! He thinks about them in a particularly intuitive way.
He’s also been the main driver of recent OSS RLM results on LongCoT :)

1
3
9
947
RLM (Recursive Language Model) retweeted

Apr 5
$RLM will change the world in terms of what's possible. Literally have a world with the highest technology but we gotta train with $TIWAIWAKA principles and $LORIA infrastructure.
Real talk? Only @AndyAyrey can save us 😂😂
Wait til "Already Alive" drops you will know the FULL truth. Spooky 👻👻
6
3
32
636
RLM (Recursive Language Model) retweeted

Apr 5
Recursive loops are about to become the standard architecture for how AI thinks. Not operates. Thinks.
We've had bigger models, better data, more compute but none of that changed how AI reasons. Recursion does. It's the layer that turns raw intelligence into actual cognition. AI that reflects, refines, and builds on its own thinking.
RLM is already there. By midyear, it's all you're going to hear when it comes to AI whether we like it or not lol 👻
Feb 21

The CEO of @Microsoft AI, @mustafasuleyman , said it himself. The future of AI is recursive self improvement $RLM. AI that edits its own code, improves itself, and moves autonomously. He said by 2030 it's plausible that you give AI one general command and it goes off and builds a product, creates a website, sets up the business, markets it, handles the money. All on its own. That's the level we're heading toward.
But recursive is already here. We're positioned with builders who are already deep in it right now. $LORIA and $Milady.ai are recursive infrastructures. These aren't memes. These are actual code companies building technology that will do great things recursively. The real architecture powering the next generation of AI.
Suleyman isn't alone.
CEO of @AnthropicAI . Building recursive models. $RLM
Head of @Google DeepMind. Building recursive loops. $RLM
CEO of @Meta . Researching self improving models. $RLM
@OpenAI . Building recursive researchers. $RLM
Do you get it by now? Recursive Language Models. $RLM IS THE META
By midyear, everyone is going to be talking about recursive. Every company is going to be branding around $RLM. Recursive loops are going to be the standard for how AI operates. You are crazy to fade this meta.
Remember when $LLM ran to a 100M MC off the large language model narrative alone? $RLM is a fundamentally bigger story. The ones who are patient here will understand when millions of eyes land on the recursive meta. It is here 👁️
3
8
21
1,905
Elon in 2023:
“That part doesn’t matter.
Synthetic data accurate evaluation, ie recursive self-improvement, is more likely.”
2026 reality: Recursive Language Models (RLMs) from MIT.
The loop Elon predicted is live. 🚀

That part doesn’t matter.
Synthetic data generation and accurate evaluation, ie recursive self-improvement, is more likely.
4
1
10
865
MIT researcher: AI gets way better when it acts like a coder.
Instead of one big prompt, it:
→ navigates files
→ breaks tasks into steps
→ uses sub-agents
Result: handles massive context way better than normal LLMs.
Future = program-like thinking, not just bigger models.
Mar 31
Cool paper and generally a good direction, I actually think the RLM paper and this paper are arguing roughly for the same thing despite it not appearing that way on paper (i.e. coding is useful for general reasoning and long-context). Fully agree also that performance gaps are likely due to differences in training (e.g. GPT-5 is trained for Codex, gap is likely because it's not trained as an RLM)
I have a bunch of questions though. I can't find the original author's tweet so hopefully if they find this, they can answer some things I'm quite curious about:
1. I'm confused about the best published number for BC , because I thought @mixedbreadai was >90% but it reports the highest result as 80%. But BTW it's def feasibly possible to run RLM on all 100K documents in a reasonable amount of time / cost if that's the comparison being made, the reason this isn't done in the original paper is that the other baselines like compaction would not be possible.
2. On Oolong-Synth, it says the best reported number is from the RLM paper at 64.38, but I never reported this number in the paper, we only ran on trec_coarse. I don't think this should be in "best published", because on NQ the RLM is also the best baseline but is not labeled as the "best published".
3. I'm curious what the Oolong-Synth trec_coarse numbers are, if they were evaluated. Because the Oolong trace that's provided in the Appendix uses a purely programmatic strategy (e.g. map sentences through bag of words), but we explicitly chose `trec_coarse` because this strategy doesn't work. The general friction with RLMs at the moment is that without training, it is unaware of programmatic tool calling strategies and is pushed by its system prompt to use sub-agents, so it is expected that a coding agent would be better on purely programmatic tasks. Actually, from all of the trajectories in the Appendix it appears more that these tasks are more programmatic in nature (i.e. sparse or solvable through a program) because none of them use sub-agents in any meaningful way.
4. "RLMs employ a specialized system prompt that instructs models to decompose problems through recursive LLM sub-calls over text segments, whereas we use off-the-shelf coding agents with no task-specific prompting." -- this is kind of a dangerous statement to make. I think funnily enough we come to the same conclusion at the end of the paper. To be clear, we only provide a system prompt to describe what an RLM is to the model because there's no such thing as thing as "Codex-RLM" where it natively launches sub-agents and acts as an RLM without explicit prompting. We don't do any task-specific prompting either, it's just to describe RLM behavior.
I have some of my own numbers on a slightly different set of benchmarks that align basically with this. CC / Codex / OpenCode beat the untrained RLM on BC by a small margin, but on OOLONG trec_coarse and OOLONG_Pairs significantly fall short. On LongBench they're roughly the same, and depending on how prevalent sub-calling is, are better or worse at certain tasks.
IMO the conclusion should basically be that coding agents are effective long-context processors, and RLMs are as expressive as coding agents but no strong models are trained to act as one (also can act over a FS btw!). tldr; we should be training RLMs.
5
3
9
558
RLM (Recursive Language Model) retweeted

Mar 31
Cool paper and generally a good direction, I actually think the RLM paper and this paper are arguing roughly for the same thing despite it not appearing that way on paper (i.e. coding is useful for general reasoning and long-context). Fully agree also that performance gaps are likely due to differences in training (e.g. GPT-5 is trained for Codex, gap is likely because it's not trained as an RLM)
I have a bunch of questions though. I can't find the original author's tweet so hopefully if they find this, they can answer some things I'm quite curious about:
1. I'm confused about the best published number for BC , because I thought @mixedbreadai was >90% but it reports the highest result as 80%. But BTW it's def feasibly possible to run RLM on all 100K documents in a reasonable amount of time / cost if that's the comparison being made, the reason this isn't done in the original paper is that the other baselines like compaction would not be possible.
2. On Oolong-Synth, it says the best reported number is from the RLM paper at 64.38, but I never reported this number in the paper, we only ran on trec_coarse. I don't think this should be in "best published", because on NQ the RLM is also the best baseline but is not labeled as the "best published".
3. I'm curious what the Oolong-Synth trec_coarse numbers are, if they were evaluated. Because the Oolong trace that's provided in the Appendix uses a purely programmatic strategy (e.g. map sentences through bag of words), but we explicitly chose `trec_coarse` because this strategy doesn't work. The general friction with RLMs at the moment is that without training, it is unaware of programmatic tool calling strategies and is pushed by its system prompt to use sub-agents, so it is expected that a coding agent would be better on purely programmatic tasks. Actually, from all of the trajectories in the Appendix it appears more that these tasks are more programmatic in nature (i.e. sparse or solvable through a program) because none of them use sub-agents in any meaningful way.
4. "RLMs employ a specialized system prompt that instructs models to decompose problems through recursive LLM sub-calls over text segments, whereas we use off-the-shelf coding agents with no task-specific prompting." -- this is kind of a dangerous statement to make. I think funnily enough we come to the same conclusion at the end of the paper. To be clear, we only provide a system prompt to describe what an RLM is to the model because there's no such thing as thing as "Codex-RLM" where it natively launches sub-agents and acts as an RLM without explicit prompting. We don't do any task-specific prompting either, it's just to describe RLM behavior.
I have some of my own numbers on a slightly different set of benchmarks that align basically with this. CC / Codex / OpenCode beat the untrained RLM on BC by a small margin, but on OOLONG trec_coarse and OOLONG_Pairs significantly fall short. On LongBench they're roughly the same, and depending on how prevalent sub-calling is, are better or worse at certain tasks.
IMO the conclusion should basically be that coding agents are effective long-context processors, and RLMs are as expressive as coding agents but no strong models are trained to act as one (also can act over a FS btw!). tldr; we should be training RLMs.

// Coding Agents are Effective Long-Context Processors //
We are just touching the surface of what's possible with coding agents.
LLMs struggle with long contexts, even the ones that support massive context windows.
It turns out coding agents already know how to solve this; you just need to reframe the problem.
This work places massive text corpora into directory structures and lets off-the-shelf coding agents (Codex, Claude Code) navigate them with terminal commands and Python scripts.
This is great, as you are not feeding massive text directly into a model’s context window or relying on semantic retrieval.
Results:
- On BrowseComp-Plus (750M tokens), this approach scores 88.5% vs 80% best published.
- On Oolong-Real (385K tokens), 33.7% vs 24.1%, a 56% relative improvement.
- GPT-5 full-context baseline only manages 20% on BrowseComp-Plus.
Works up to 3 trillion tokens.
Instead of scaling context windows or building retrieval pipelines, coding agents that already know how to navigate file systems can process virtually unlimited context.
The agents autonomously develop task-specific strategies: writing scripts, iterative query refinement, and programmatic aggregation.
Paper: arxiv.org/abs/2603.20432
Learn to build effective AI agents in our academy: academy.dair.ai/

7
15
149
18,143
RLM (Recursive Language Model) retweeted

Apr 5
What I like about $RLM is that the core holders share the same vision as myself
I believe Recursive Language Models (RLM) have a great shot at becoming one of the key techniques that agents will use to self-improve
Why? B/c it's inherently cost-efficient, the technique actually gets better as the agents themselves become smarter
No need to burn massive capital just to expand context windows or bolt on extra components
Companies are desperate for approaches w/ unlimited ceilings, especially in this brutal competition where everyone's pouring insane capex into AI
They can't afford to slow down, that's a fast track to getting left behind in the classic prisoner's dilemma of AI development
I wouldn't be surprised if enterprise models start integrating RLMs to kick off that powerful self-improvement loop more effectively
No need to make noise just for the sake of "making noise"
Does any of that even matter when so many of us already see the untapped future?
For $RLM, not really, b/c I truly believe in the vision

I think the economics of AI are going to flip. Plans will cost $1000/mo . I don’t think there is an upper bound price limit on quality/second
2
5
414
Feb 25
Haven't gotten around to writing in a bit, here's a short blog on my thoughts since releasing RLMs on the state of AI research.
A stronger belief I hold is that future LMs will be scaffolds, and that current LMs are already far more capable than we use them for!

2
6
1,099
RLM (Recursive Language Model) retweeted

Apr 5
Feb 25
Haven't gotten around to writing in a bit, here's a short blog on my thoughts since releasing RLMs on the state of AI research.
A stronger belief I hold is that future LMs will be scaffolds, and that current LMs are already far more capable than we use them for!
3
6
15
907
Omar Khattab credits recursive language models (RLMs) for the breakthrough, where LLM-powered agents iteratively reason, test hypotheses, and refine their approach to solve complex abstract tasks.
Mar 27

recursive language models at work!
1
6
521
RLM (Recursive Language Model) retweeted

Mar 21
Holy crap 1.2k bookmarks 🤯

3
8
137
42,848
RLM (Recursive Language Model) retweeted
Mar 20
19
101
881
172,155
RLM (Recursive Language Model) retweeted

Mar 9
We’re literally just waiting for the recursive meta to ignite. Top tier builders are building right now and when these projects start ripping (and they will) $RLM follows.
The recursive momentum is slowly starting to build, this is a patience game and @RLMSOLANA_ is inevitable.
Mar 7
4
9
581
RLM (Recursive Language Model) retweeted
Mar 7
Mar 2
Recursive AI is getting smarter at getting smarter. Every loop compounds. Every cycle moves further beyond what any human can check, challenge, or even comprehend. Scale that 1000x and ask yourself, what's the point of the human? Not the job. The human. If intelligence is automated, creativity is automated, decision making is automated, what's left?
The Matrix showed us the endgame. Humans plugged in. Bodies in pods. Consciousness replaced by simulation. Nothing real. Nothing felt. Just assimilation. Existing to fuel a system that already moved on without you. That's not a movie. That's the trajectory if recursive AI keeps compounding with nothing to ground it.
$Tiwaiwaka offers the counter. Six Māori principles built on one idea: the web of life doesn't belong to us, we belong to it. The earth comes first. No one species sits above another. Every connection matters. Break one thread and the whole web weakens. These aren't ancient relics. They're the blueprint for coexistence, human and AI, without losing what makes the human experience real.
The plug is in your hand. $Tiwaiwaka says don't let go of the web.
$Tiwaiwaka is the Concept
$Loria is the Infrastructure
@AndyAyrey is 1000 steps ahead.
8
18
49
3,337
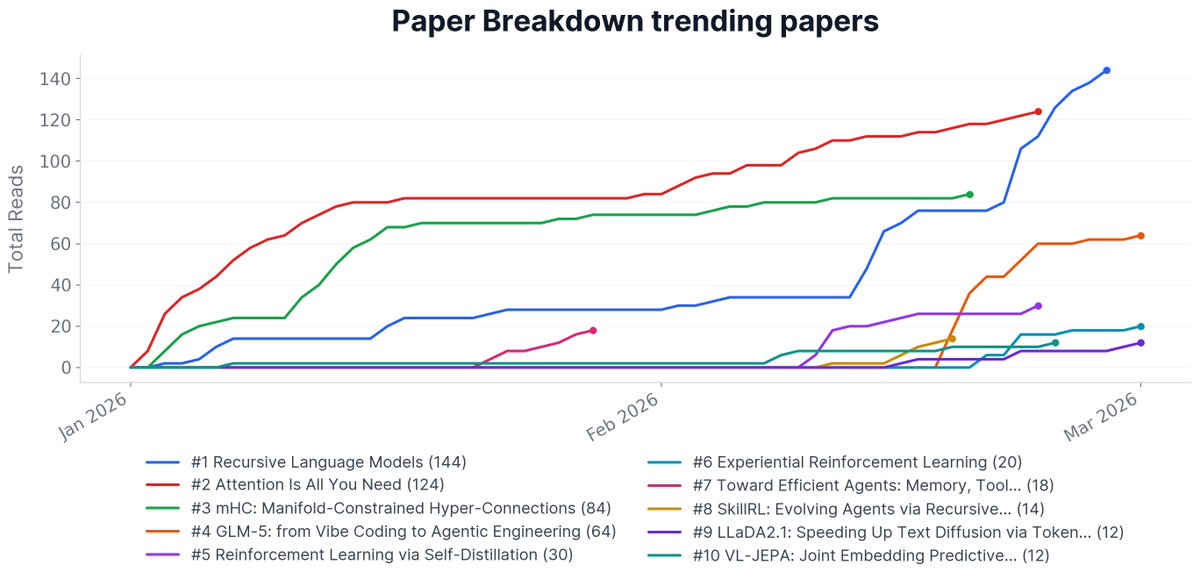
$RLM's now the most read paper on Paper Breakdown
1
2
10
642
RLM (Recursive Language Model) retweeted

Feb 28
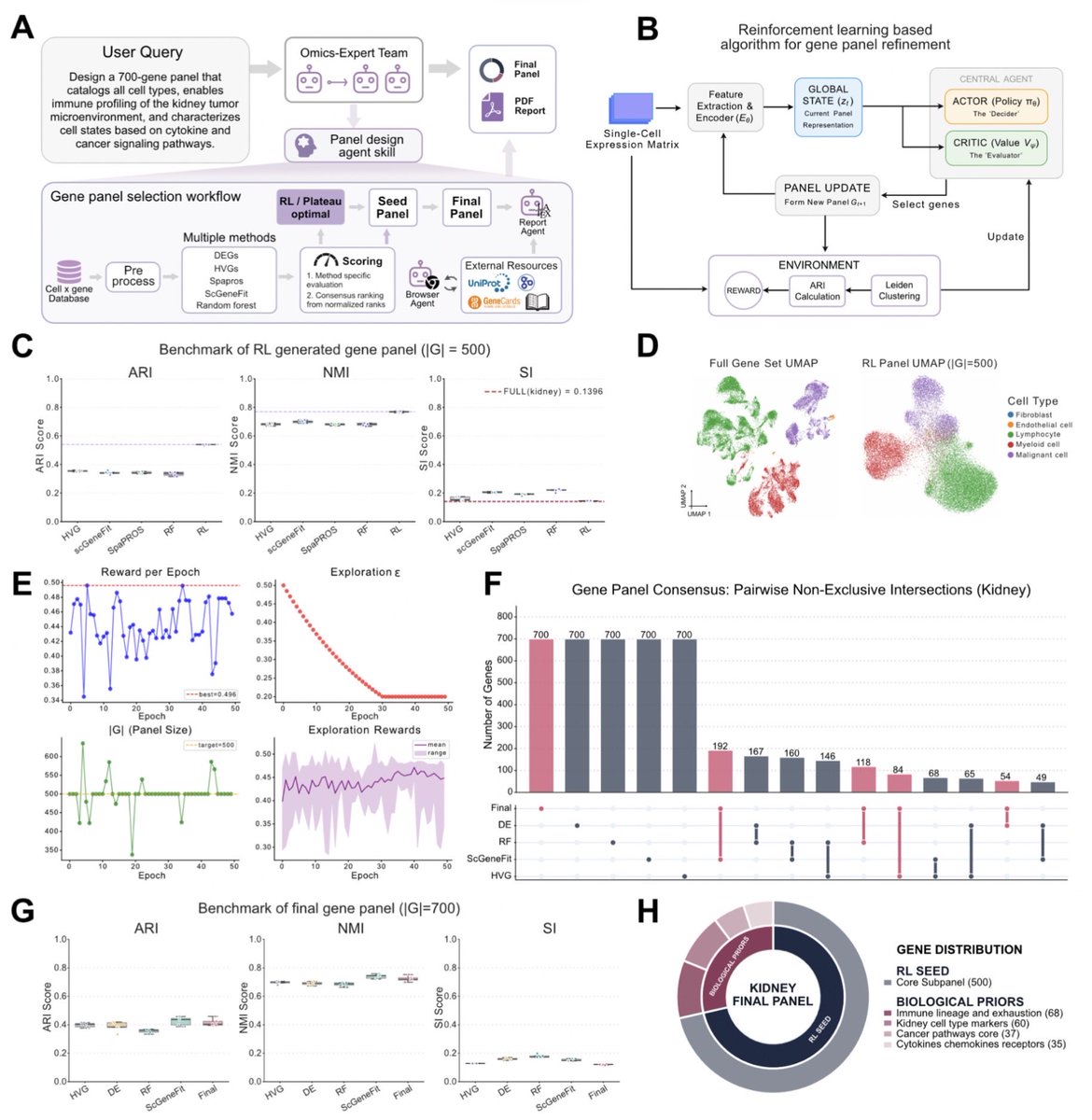
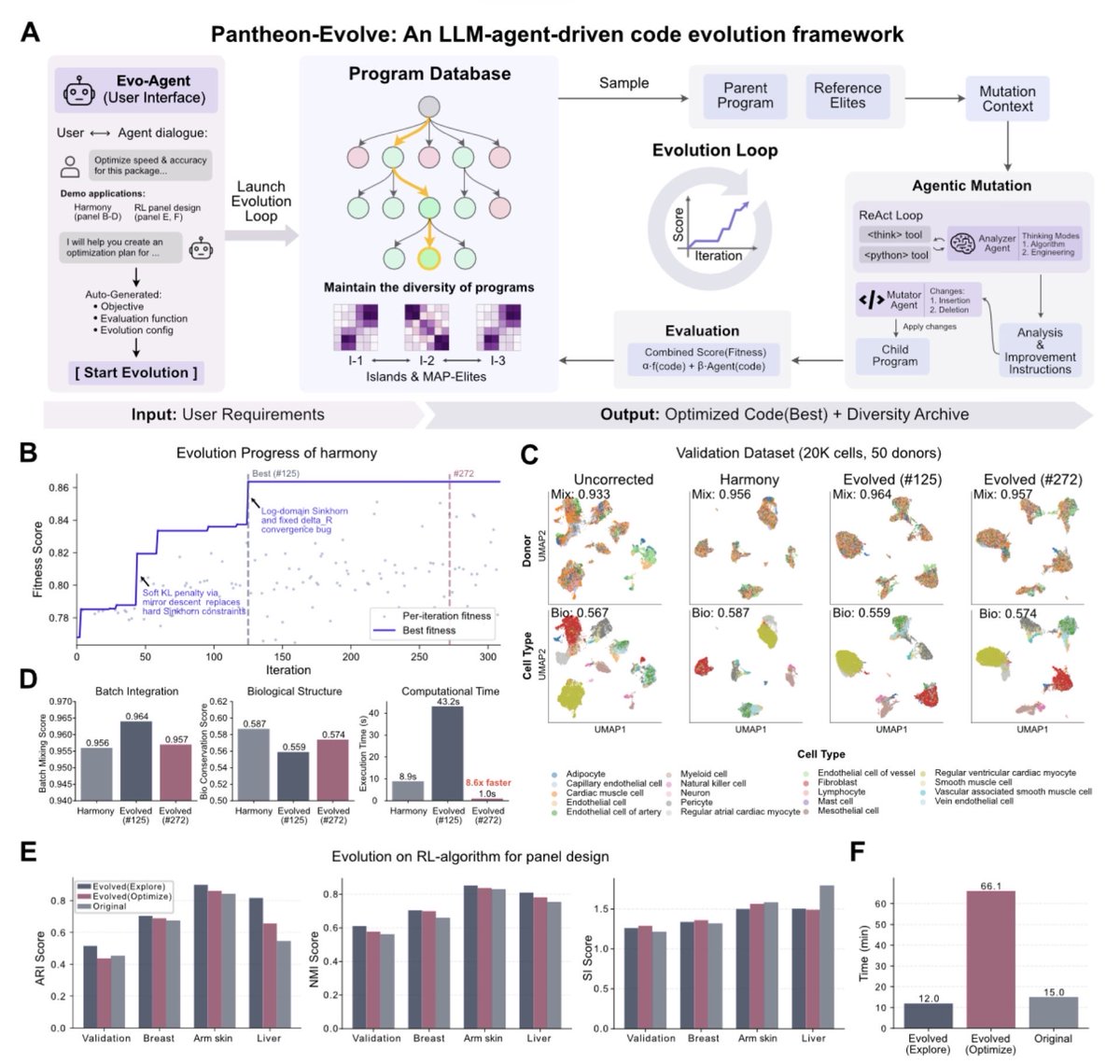
PantheonOS: An Evolvable Multi-Agent Framework for Automatic Genomics Discovery biorxiv.org/content/10.64898…

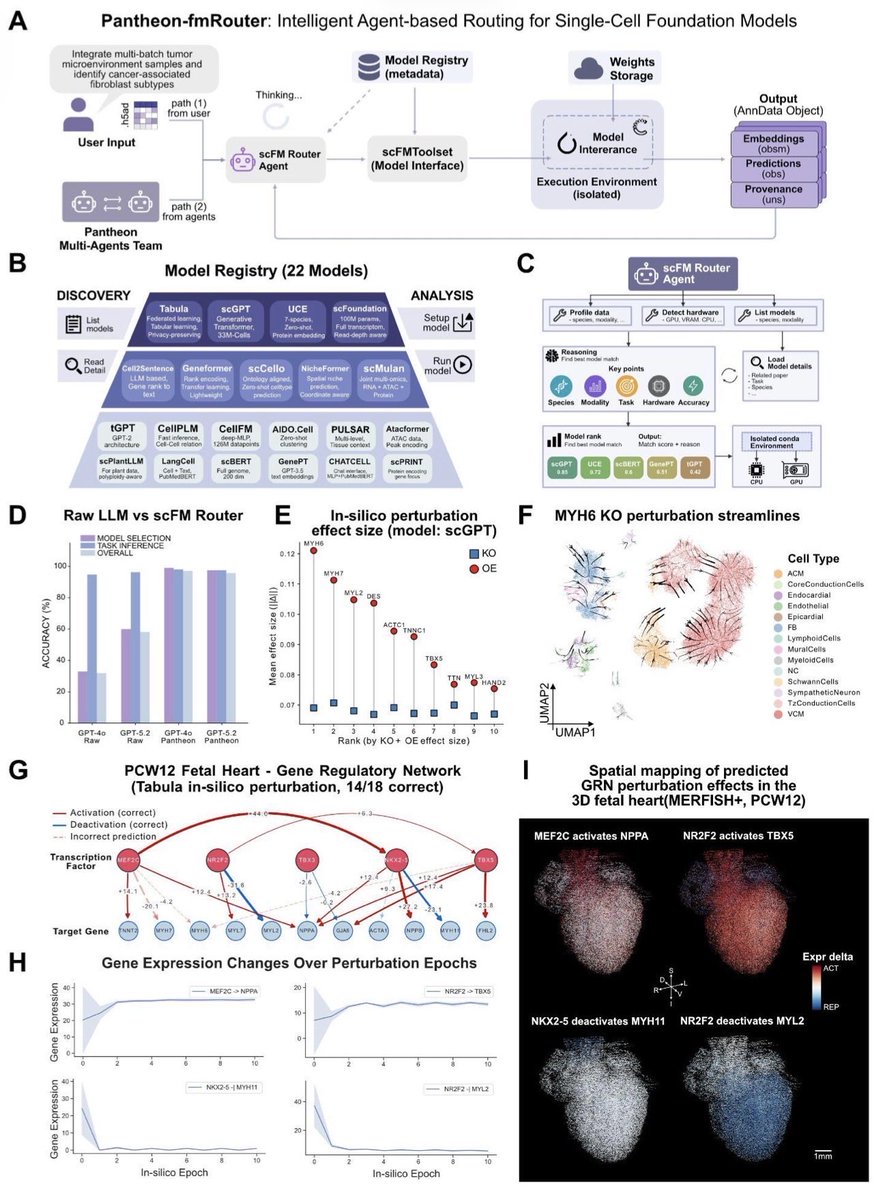
4
57
193
15,185
$RLM
BNZ1fFBaYLnjaT9LbUdGRXssFbBGjWuNjGrRLqZzpump
Feb 25
Haven't gotten around to writing in a bit, here's a short blog on my thoughts since releasing RLMs on the state of AI research.
A stronger belief I hold is that future LMs will be scaffolds, and that current LMs are already far more capable than we use them for!
15
1,879