
building tools for builders | founder @polySpectra | cofounder @cyprismaterials | cohort 1 @activatefellows @berkeleylab | PhD @caltech | AB @princeton | #rwri
Joined December 2013
- Tweets 3,693
- Following 3,109
- Followers 2,789
- Likes 10,664
Photos and videos
Pinned Tweet

Jan 22
“Study hard what interests you the most in the most undisciplined, irreverent and original manner possible.”
― Richard Feynmann
I am currently studying:
ralph wiggum, rlms, dspy, gastown & related agent orchestrators, agent-native apps and orgs
How about you?
5
38
6,185
Raymond Weitekamp retweeted

Jun 12
Ok, that's really good...
ht @kevinmuir and esp. @nntaleb

3
19
149
24,855
Raymond Weitekamp retweeted

Jun 13
A bit ago: I told my landlord the other day that he should kick anyone out that was peddling ancient artefacts from his basement.
Today: WTF my landlord kicked me out for peddling ancient artefacts from his basement. This is surely a misunderstanding!
4
3
89
2,850
Raymond Weitekamp retweeted

Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
12,393
25,681
87,465
88,036,434
Raymond Weitekamp retweeted

Jun 10
Terrific release from @nvidia and my former PhD student @rohansawhney1:
A GPU physics solver for fundamental problems like electrostatics and heat transfer, which handles extremely complex geometry without any mesh generation or basis approximation.
Based on Monte Carlo walk on spheres methods developed by our group and others. See this page for lots of background info/tutorials: rohan-sawhney.github.io/mcgp…
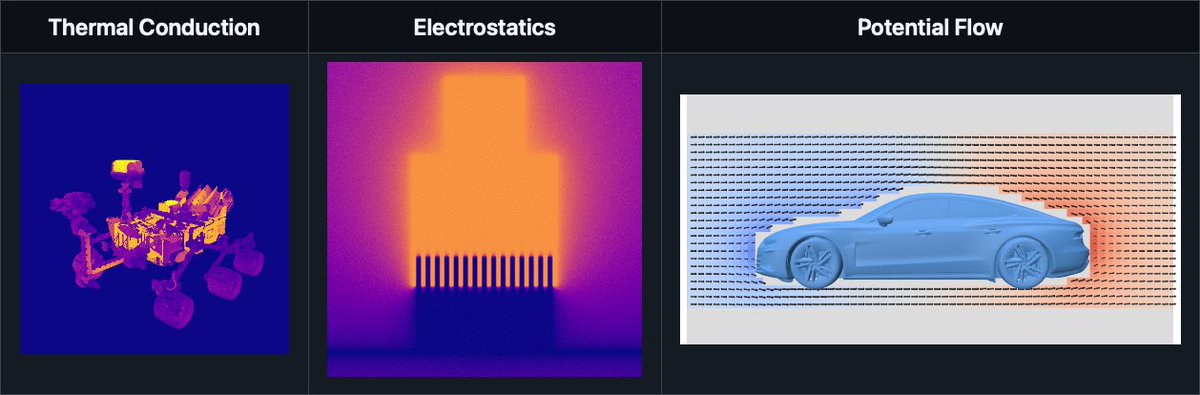

Releasing Walk on Spheres Extensions (WoSX): a GPU-accelerated C /Python library for Monte Carlo physics simulation on complex geometry
Think path tracing but for physics beyond light transport: heat, electrostatics, potential flow, deformation & more!
github.com/nv-tlabs/wosx
6
111
1,202
103,548
Jun 10
And furthermore, the labs should publish the capabilities of these models when used recursively...
...but then the plots will be fractals so that might not become a very popular format since only the RLMs will be able to understand the fractal plots

1
2
725

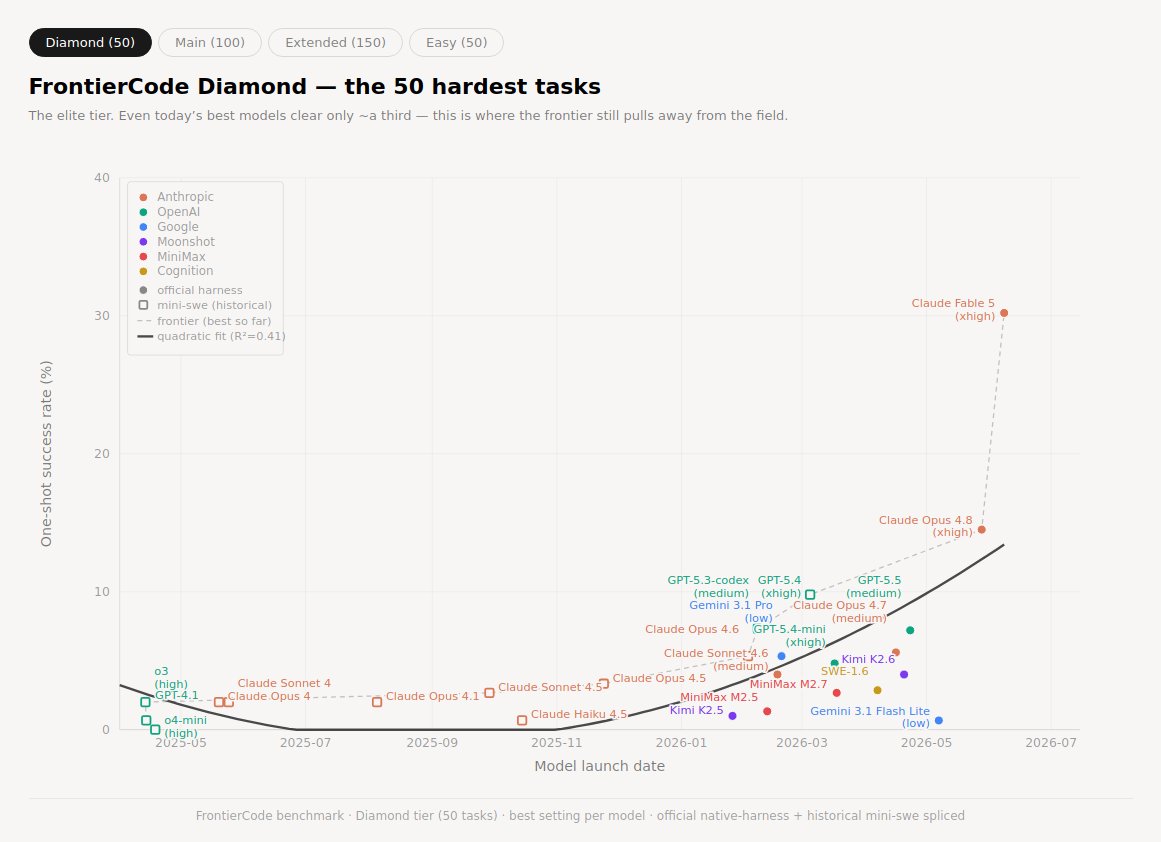
just finished rerunning FC Diamond on my historical charts. none of the official tables/charts are capturing the degree of takeoff.
x.com/karpathy/status/206440…
its this same chart all the way down difficulty classes (below) breaks every curve fit because Fable is a diffferent CLASS of model, with beeeeeg model smell.
Jun 9

This is a super exciting release - Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model "gets it" and it will just go, and it's never felt this tempting to stop looking at the code at all (but don't do this in prod!). The model still has quirks that people will run into and the safeguards are configured to be a little too trigger happy for launch, which can hopefully be tuned over time.
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref). Really looking forward to all the things people build!
3
10
100
36,066
Raymond Weitekamp retweeted

Jun 9
102
763
6,010
2,171,660

I spent a lot of the weekend doing recursive dynamic workflows
which—while technically blocked by the Claude Code dynamic workflow JS environment in the package itself—can still be accomplished _in effect_ using a technique called trampolining, which allows an outer loop to effectively manage inner recursion out of something like an event queue
incidentally, trampolining is how we always got Claude’s agent-subagent architecture (max depth n=1) to implement deeply nested OpenProse blocks
I picked this technique up from Spring, would wire together Java calls. better yet this foundation plays especially nicely with middleware (useful in LLM systems!)
anyway, dynamic workflows present an even further fertile ground for the trampoline, as you can basically build an entire event loop (in JavaScript!) and manage the inner agent calls as a virtual recursive stack even though the environment permits just a max depth of 1
this is fraught with challenges around shared state, but nothing that hasn’t already been solved
5
3
89
4,735
Jun 9
for all the people freaking out about loops this week...
if you want deterministic code as the outer harness: @DSPyOSS
if you want a natural language contract that your agent must fulfill: @OpenProseVM
1
1
6
277
Jun 9
regarding the latter, i wrote an in depth piece for turing post late last week: turingpost.com/p/openprose-a…
1
162
Jun 9
this was a really fun piece to write for @TheTuringPost. i'm very grateful for the opportunity to partner with @Kseniase_ on it.
start authoring outcomes!
Jun 8

OpenProse – an open-source "logical English" language that turns your agentic workflows into reusable agent programs.
It runs inside the coding agent you already use: Claude Code, Codex, OpenCode, Hermes, Pi – and gives it a structured contract to follow.
→ The key idea – the coding agent becomes the "compiler".
This delivers:
- Less babysitting of multi-agent coding sessions
- Reviewable .prose.md programs instead of disposable prompts
- Explicit skill and tool dependencies
- Isolated sub-agent sessions with clean outputs
- Run receipts, logs, artifacts, and audit trails
- Reuse of sessions on demand
So OpenProse extracts the entire workflow: phases, contracts, decision gates, loops, parallel work, mistakes, fixes, and validation evidence. It's like a “git for agent workflows”.
3
4
2,737
everyone is building an agent or a tool
you don't want an agent or a tool, you want a reactor
I've been working on something cool and I think you'll like it
it's simple: an agent session DAG that keeps a declared world-model up to date in an efficient (memoized) render
each render node is an agent session: you declare the desired state with OpenProse markdown files
once invoked, each agent session acts as the provider. the agent session uses the open source openai-agents-sdk, extensible however you like with any model (I use with opus, sonnet, haiku)
the facets of the world-state are memoized, so not every agent has to run on every event, saving you on inference
if that sounds a lot like React or dataflow, that's because even in our brave new world the wisdom of the agents holds fast
23
18
193
9,544
Raymond Weitekamp retweeted

Jun 3
It is great that the frontier labs want to support data analytics workflows. It is the #1 thing many enterprises want now. But enterprise data is difficult. Turns out most models are bad at it! They’re ok at writing single SQL queries or Python scripts, thanks to the plethora of text to SQL and data science benchmarks, but they struggle to query, clean, and make sense of data from multiple database systems (relational and non relational).
Fortunately, we released a new benchmark to help, the Data Agent Benchmark, with plans to get it into a super well-known benchmark very soon :-) stay tuned!
arxiv.org/abs/2603.20576

15
23
249
58,737
Raymond Weitekamp retweeted

Join us at @PrimeIntellect to build the open stack for self-improving agents
Engineering
• MTS – Full Stack Software Engineer — SF/Remote, Full time
• MTS – GPU Infrastructure — SF/Remote, Full time, Hybrid
• MTS – Inference — Remote/SF, Full time, Hybrid
• MTS – Sandbox Platform — SF, Full time, On-site
• MTS – Security — SF, Full time, On-site
• MTS – Training Platform — SF, Full time, On-site
Research
• Research Engineer – Distributed Training — SF/Remote, Full time
• Research Engineer – Reinforcement Learning — SF/Remote, Full time
• Research Engineer – RL Infrastructure — SF/Remote, Full time
• AI Research Resident – Open Source AGI — Remote, Part time
Applied Research
• Evals & Data — SF, Full time, Hybrid
• Forward-Deployed — SF, Full time, On-site
• RL & Agents — SF, Full time
Compute / Finance
• Head of Compute — SF, Full time
• Strategy and Finance Lead, Compute — SF, Full time
Finance / Operations
• Business Operations Lead — Remote, Full time
• Chief of Staff — SF, Full time
• Founder's Associate, Business Operations — SF, Full time
Growth
• Account Executive — SF, Full time
• Head of Enterprise — SF, Full time
• Head of Growth — SF, Full time
• Head of Marketing — SF, Full time
• Revenue Operations Lead, AI Infrastructure — Remote, Full time
• Solutions Architect – AI Infrastructure — SF, Full time
• Technical Account Manager – AI Infrastructure — SF, Full time
Legal
• Head of Legal — SF, Full time
Others
• Internship — SF, Full time
• Open Application for Unconventional Talent — SF/Remote, Full time

27
35
396
44,856
I was talking with an old friend at dinner last night, he described gpt fatigue
I'd examined the whole psychosis thing, but fatigue is different, and this one rings with me. I've been through cycles of this; I'm probably just emerging from my third epoch of gpt fatigue right now
it's very bittersweet. the cognitive overhead of context switching across the slop troughs is not as fun as the in-the-zone coding rhythm I enjoyed for the first twelve years of my career
I drew the connection to the Reactor Harness I'd been working on and he lit up (yes, this is a launch post, read on). I told him the basic idea:
In the same way that React (js) keeps the DOM up to date by rendering declared components efficiently based on upstream events...
the Reactor Harness keeps an ideal world-model up to date by rendering declared facets of the world-model efficiently based on upstream events.
This world-model can be anything--formally it's a faceted content addressable blob. In practice, it can be a file, a directory, a sqlite table, etc.
If you've followed OpenProse since the beginning, you'll guess that the render function is not deterministic byte code, but instead is declarative markdown instructions fulfilled by an agent session.
I'm releasing the harness here in beta today. It ships as an SDK so you can plug it into your own projects. We've built an experimental CLI w/ a lightweight server and a devtools package alongside it. Please give it a boost with a Github Star here, then return to read more:
github.com/openprose/prose
The Reactor Harness is built to run OpenProse, and its design was uniquely informed by the tenets behind OpenProse, such that you can declare your ideal world-model using familiar structured markdown, and you can optionally write imperative fulfillment plans in our original ProseScript.
One way of thinking about the Reactor is as a DAG of agent sessions. Every node in the DAG is an agent session tasked with keeping facets of the world model up to date. These are memoized, such that downstream dependent sessions only get re-run when their upstream counterparts change.
Over the coming days, I'll be writing more about the harness, how we've been using it, and where I hope we can take this. We are in the process of running benchmarks on it. The goal is that the SDK API itself remains relatively stable while we improve the agent session fulfillment cost, speed, and intelligence under the hood.
How did we get here?
Today I keep a large share of our company's operations in a directory: tenets, specs, code, analytics, our burn model, our sales lead enrichment CRM.
And I find myself having to manually "fast-forward" these models, dropping into context to proactively tell Claude Code to update a spec, add someone to the CRM, or update the financial model based on real-world events that have changed our plans.
I'd written many OpenProse scripts to accomplish these things, but I found I wanted this all to run reactively, as an ongoing time-invariant responsibility, rather than proactively as a tool that I continuously return to. Our first attempt at solving this was putting our OpenProse programs on a cron. The problem with that was that it became very expensive very fast.
As I started trying to design the OpenProse to work under these constraints, I found myself introducing concepts like memoization to different facets of the maintained state. From there, I decided not reinvent the wheel and to graft the patterns from React more explicitly. It's an analogy, and the analogy breaks down in some places. But it's a reasonable starting point that a lot of people are familiar with.
We built the first version in April internally on our hosted service for one of our customers' needs, but I decided that the core of this is interesting enough that it deserves to be in the public sphere, so we spent the intervening six weeks ripping it out and redesigning it as an SDK so people could plug it into their own stacks.
I can't emphasize enough how there's nothing new here, we're just applying classical engineering paradigms to our brave new world. We're finding that despite our topsy-turvy reality, the wisdom of the ancients holds fast.
The Reactor harness is young, should be used with caution, and has some way to go before it reaches it's ideal form. My ask is that you try it, wire it up to something useful, love it or hate it, and send me honest feedback about your experience. We're always listening and improving.
I have a particularly exciting end goal in mind: because the Reactor DAG is itself a world-model, downstream from events in the real world (say, learned event source/frequency/distribution), you could use Reactor itself to implement dynamic Reactor DAGs. This sets us on the path to a true RLM paradigm. I'm most excited about this because I hypothesize that it will yield a simple, elegant property of the Reactor:
Inference cost for maintaining a world-model scales with surprise, rather than wall-clock time.
It's not there yet, but my expectation is that this is achievable and that it's just a matter of walking up the ladder to get there. In my experience when you make something self-referential too early it can collapse back in on itself, so we're going to step our way there incrementally.
When we do get there, my hope is that the meta Reactor DAG can continuously self-calibrate on event source/frequency/distribution to optimize for efficient fulfillment Reactor DAGs, and where the cost of keeping the world-model up to date approaches only the surprise of upstream events in the real world.
At dinner last night, a recurring topic was this love-hate relationship we'd developed with the models. I've been building harnesses for these burgeoning minds since my GPT-2 finetune in 2020. In many ways I'm having as much fun as I've ever had with technology. And yet I've come to loathe their impacts in many other regards.
In the end, I guess the real goal is that the Reactor Harness lets me unburden the cognitive load at the root of my gpt fatigue, and frees me up for the more interesting forms of gpt psychosis :D
thanks for reading and following along, star the repo here and give it a try:
github.com/openprose/prose
15
10
128
9,295
Raymond Weitekamp retweeted

Jun 2
🎈 we've just shipped agents sdk v0.14.0
you can now build agents with skills, messengers, schedules, and durable workflows on cloudflare
out of the box support for recurring tasks, think workflows, chat recovery, mcp transport improvements, and better client-tool continuations
go make cool stuff with it!

30
28
386
60,021
Raymond Weitekamp retweeted

Jun 2
So /goal is awesome
Over the past few weeks I used @PrimeIntellect to train a 149M late interaction model based on GTE-ModernColBERT-v1 using PyLate, focused on clause extraction from legal contracts.
On the MLEB benchmark it does well for its size: it's the best accuracy-per-parameter open model on the task, 3rd of 17 open-source models, ahead of Google's EmbeddingGemma (308M, 0.829) and the same-size legal peer Free Law ModernBERT (0.764), behind only Qwen3-Embedding-4B/8B (which are 27–53× larger).
The agents love the prime cli. I only used the UI for paying my bill.

8
12
134
10,823
Raymond Weitekamp retweeted

May 28
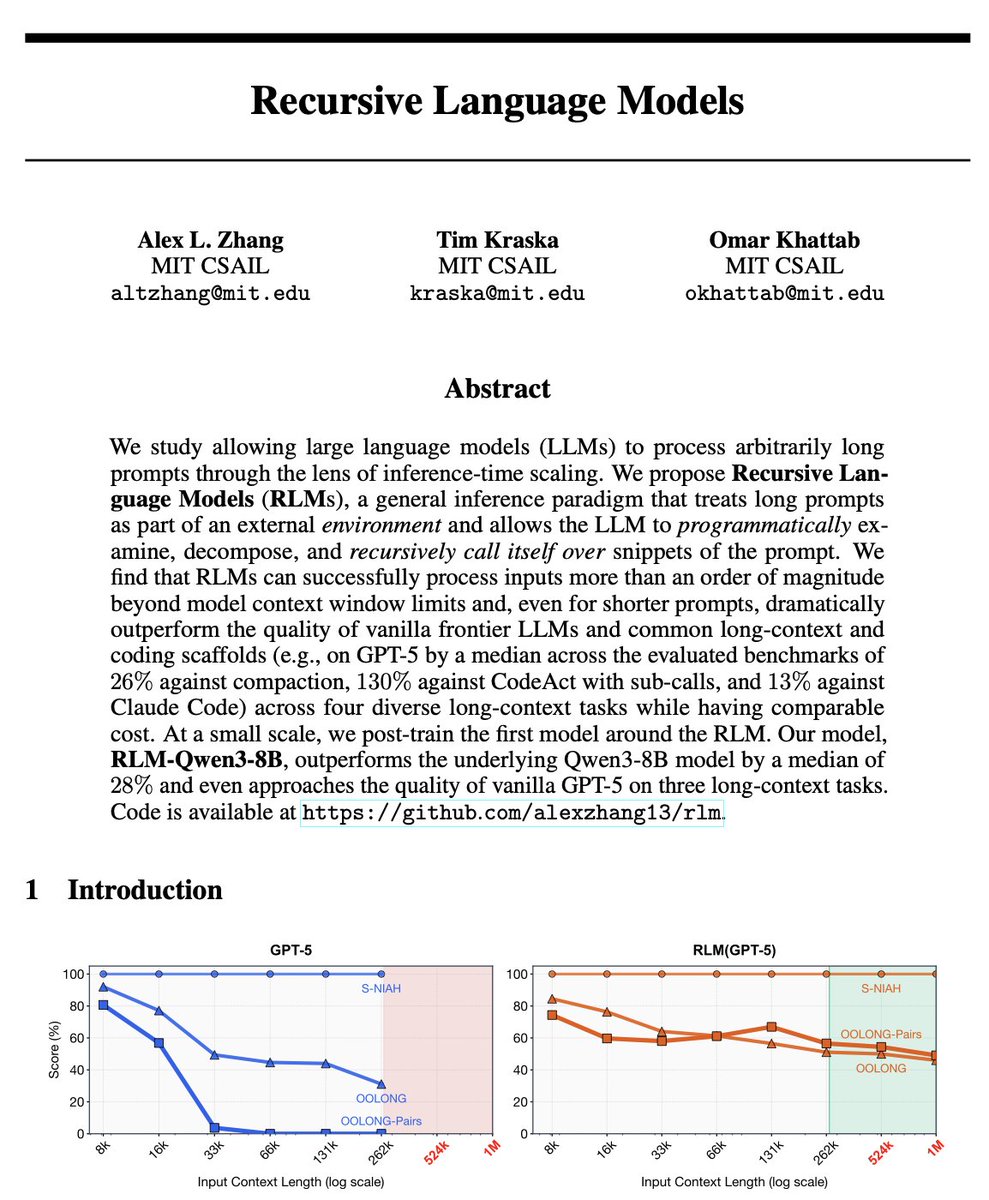
In case you're curious about why dynamic workflows are so powerful and the future, read the RLM paper! Opus 4.8 dynamic workflows in Claude Code is perhaps the first instance of a frontier model seriously trained to be an RLM.
I suspect within a year they'll just become the standard for nearly all coding agent interactions.
May 28

New in Claude Code (research preview): dynamic workflows.
Claude writes an orchestration script on the fly, then spins up a large fleet of coordinated subagents in parallel to take on your most complex tasks.
Use the word "workflow" in a prompt to get started.
53
168
1,428
295,118