
Computer Sciences PhD student at the University of Wisconsin-Madison
Joined June 2020
- Tweets 28
- Following 25
- Followers 81
- Likes 23
2 Photos and videos


Roger Waleffe retweeted

15 Dec 2025
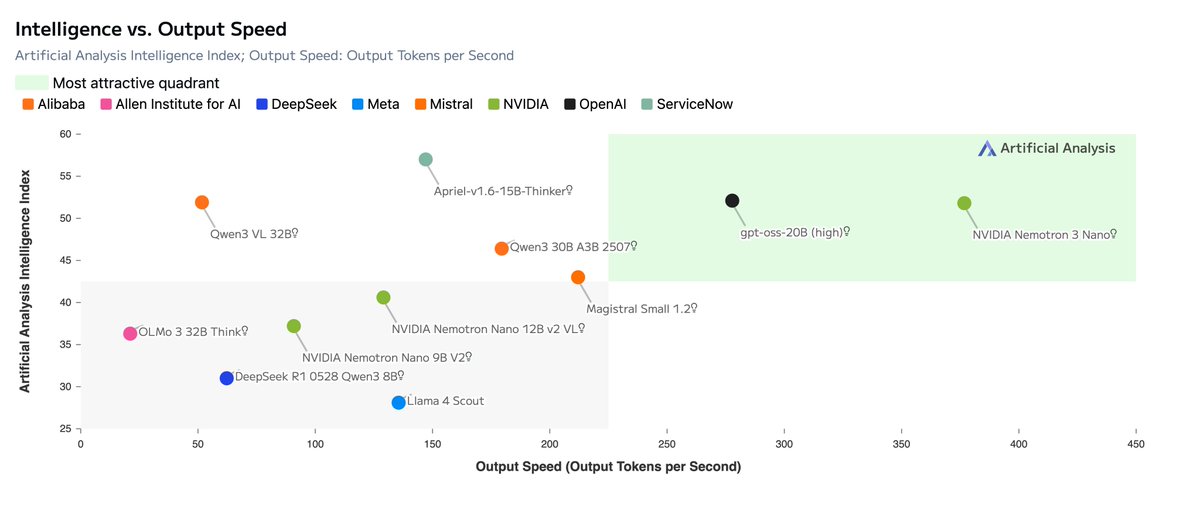
Today, @NVIDIA is launching the open Nemotron 3 model family, starting with Nano (30B-3A), which pushes the frontier of accuracy and inference efficiency with a novel hybrid SSM Mixture of Experts architecture. Super and Ultra are coming in the next few months.
41
221
1,238
505,699
Roger Waleffe retweeted
18 Aug 2025
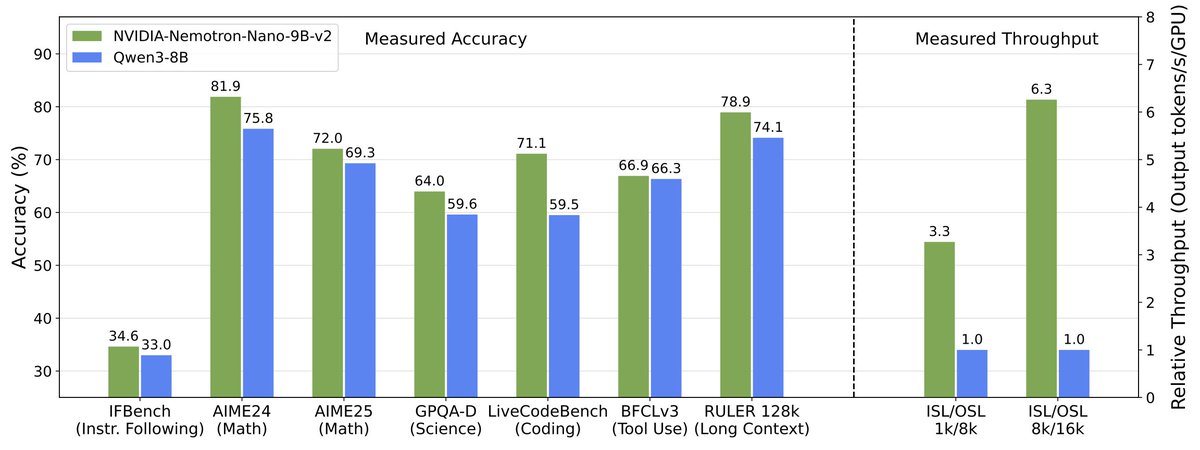
Today we're releasing NVIDIA Nemotron Nano v2 - a 9B hybrid SSM that is 6X faster than similarly sized models, while also being more accurate.
Along with this model, we are also releasing most of the data we used to create it, including the pretraining corpus.
Links to the models, datasets, and tech report are here:
research.nvidia.com/labs/adl…
37
230
1,383
276,145
Roger Waleffe retweeted
21 Mar 2025
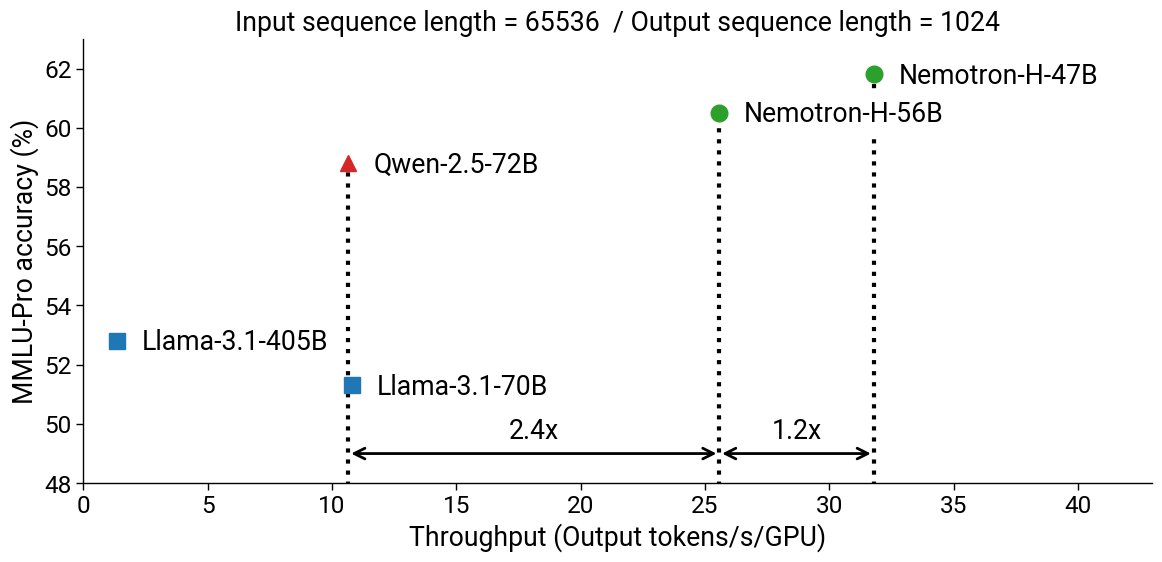
Nemotron-H: A family of Hybrid Mamba-Transformer LLMs.
* Hybrid architecture means up to 3X faster at the same accuracy
* Trained in FP8
* Great for VLMs
* Weights and instruct versions to come soon.
research.nvidia.com/labs/adl…
18
100
627
201,140
Roger Waleffe retweeted
13 Jun 2024
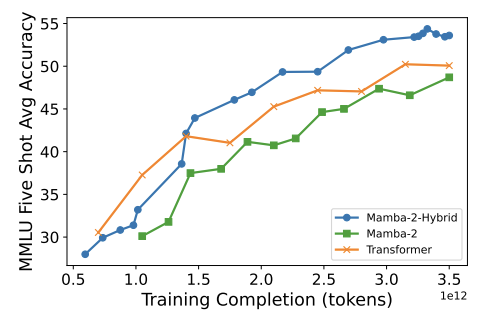
A 8B-3.5T hybrid SSM model gets better accuracy than an 8B-3.5T transformer trained on the same dataset:
* 7% attention, the rest is Mamba2
* MMLU jumps from 50 to 53.6%
* Training efficiency is the same
* Inference cost is much less
arxiv.org/pdf/2406.07887
17
77
434
118,893
Roger Waleffe retweeted

9 May 2024
Data pruning to reduce pertaining costs is hot, but fancy pruning can take just as long to select data as to train on all of it! Patrik, @Rwaleffe, and @vmageirakos's work at #ICLR2024 tomorrow shows how a simple, low-cost tweak to random sampling outperforms trendy methods!
1 Jun 2023

Not convinced about using random sampling for data pruning? Consider twice! In our recent work, we introduce Repeated Sampling of Random Subsets: arxiv.org/abs/2305.18424, where we sample a subset of data at each epoch of training instead of only once at the beginning!
2
4
15
2,450
Roger Waleffe retweeted

🚨 "MariusGNN: Resource-Efficient Out-of-Core Training of Graph Neural Networks" with @RWaleffe is available now!
🎧 Listen on Spotify ➡️ open.spotify.com/show/6IQIF9…
☕️ Support the podcast ➡️ buymeacoffee.com/disseminate
1
2
4
887

1 Jun 2023
Not convinced about using random sampling for data pruning? Consider twice! In our recent work, we introduce Repeated Sampling of Random Subsets: arxiv.org/abs/2305.18424, where we sample a subset of data at each epoch of training instead of only once at the beginning!
3
8
40
19,043
1 Jun 2023
See the preprint here: arxiv.org/pdf/2305.18424.pdf for extensive evaluations together with the convergence analysis and discussion on its generalization.
2
4
694
1 Jun 2023
Joint work with Patrik Okanovic @vmageirakos Kostis Nikolakakis @aminkarbasi @DKalogerias @nmervegurel @thodrek
1
5
666
Roger Waleffe retweeted
7 Sep 2022
Marius, another amazing KGE (and more) library is now auto-formatting its code with black as of github.com/marius-team/mariu… 🚀
@JasonMohoney @RWaleffe nice job :)
2
2
Roger Waleffe retweeted

5 May 2022
Roger Waleffe (@RWaleffe) from @wiscdb introduces the Marius system!
Check out the talk: youtu.be/BVDQauRb4gQ
@WisconsinCS #CornellDBseminar #Databases #GraphData #ML #AI #DataScience #BigData #DataAnalysis
2
2
4
Roger Waleffe retweeted
2 May 2022
Roger Waleffe (@RWaleffe) shows how to train over billion-scale graphs on a single machine!
Join us at 1 PM ET via Zoom!
Link: tinyurl.com/2p8uv2j8
Details: itrummer.github.io/cornelldb…
@wiscdb @WisconsinCS @thodrek #ML #AI #Databases #GraphData #CornellDBseminar

1
2
5
Roger Waleffe retweeted
8 Feb 2022
Scalability is a key factor limiting the use of Graph Neural Networks (GNNs) over large graphs; w/ @RWaleffe, @JasonMohoney , and Shiv, we introduce Marius (arxiv.org/abs/2202.02365), a system for *out-of-core* GNN mini-batch training over billion-scale graphs. (1/5)
2
5
33
Roger Waleffe retweeted
12 Mar 2021
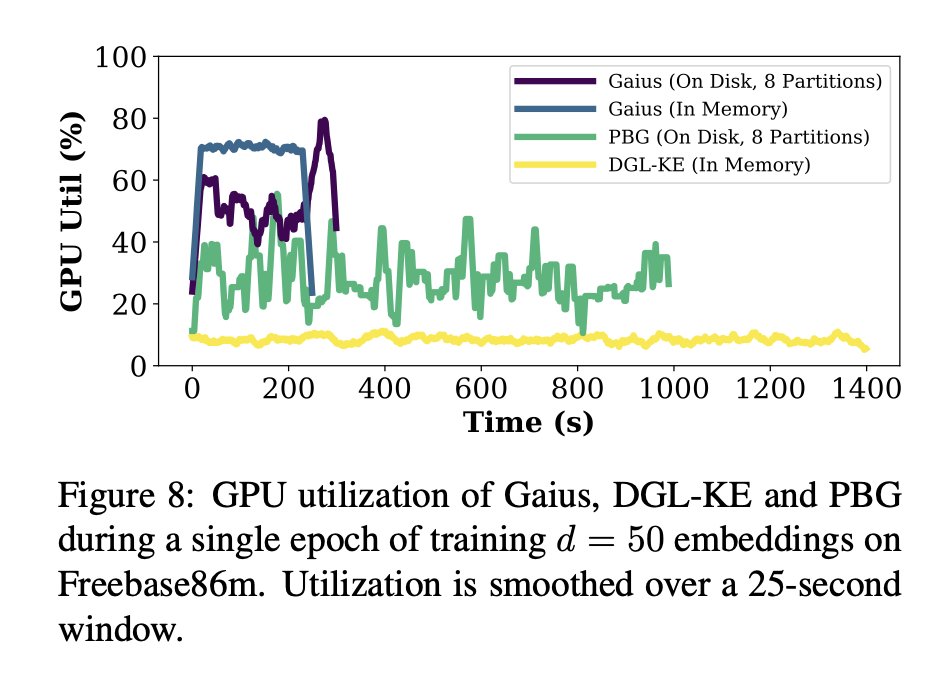
Accepted to #OSDI21: @JasonMohoney & @RWaleffe show how to train massive graph embeddings in a 𝘀𝗶𝗻𝗴𝗹𝗲 𝗺𝗮𝗰𝗵𝗶𝗻𝗲; don't burn $$$$ on cloud providers. 1/n works on graph learning w. the amazing Shivaram Venkataraman. open-sourcing soon #marius arxiv.org/abs/2101.08358
7
48
Roger Waleffe retweeted

25 Jun 2020
Principal Component Networks: Parameter Reduction Early in Training. (arXiv:2006.13347v1 [cs.LG]) ift.tt/2VdFEXG
2
16
Roger Waleffe retweeted
25 Jun 2020
3/3 We term these networks Principal Component Networks (PCNs). Practical results: We show that converting wide networks to their equivalent PCN outperforms deeper networks. For example, we find that Wide ResNet-50 PCN outperforms ResNet-152 on ImageNet.
1
2
Roger Waleffe retweeted
25 Jun 2020
2/3 The secret sauce: Hidden layer activations in wide networks live in small subspaces! Train your wide-net for a few epochs, run PCA on the activations, project the weights on the PCA basis, and continue training to find your new state-of-the-art subnetwork.
1
1
1
Roger Waleffe retweeted
25 Jun 2020
1/3 Super exciting new result by Roger (@RWaleffe) on how to find small networks that exhibit the same performance as overparameterized networks!
We show that no expensive iterative pruning is needed to find lottery tickets x.com/StatMLPapers/status/12…
25 Jun 2020

Principal Component Networks: Parameter Reduction Early in Training. (arXiv:2006.13347v1 [cs.LG]) ift.tt/2VdFEXG
1
5
32