
Machine Learning Systems, Data Management & Knowledge Graphs @Apple; Ex-Professor @ETH & @UWMadison; Co-founder of inductiv (acquired by @Apple)
Joined February 2015
- Tweets 748
- Following 381
- Followers 1,719
- Likes 2,355
20 Photos and videos








Pinned Tweet

8 Feb 2022
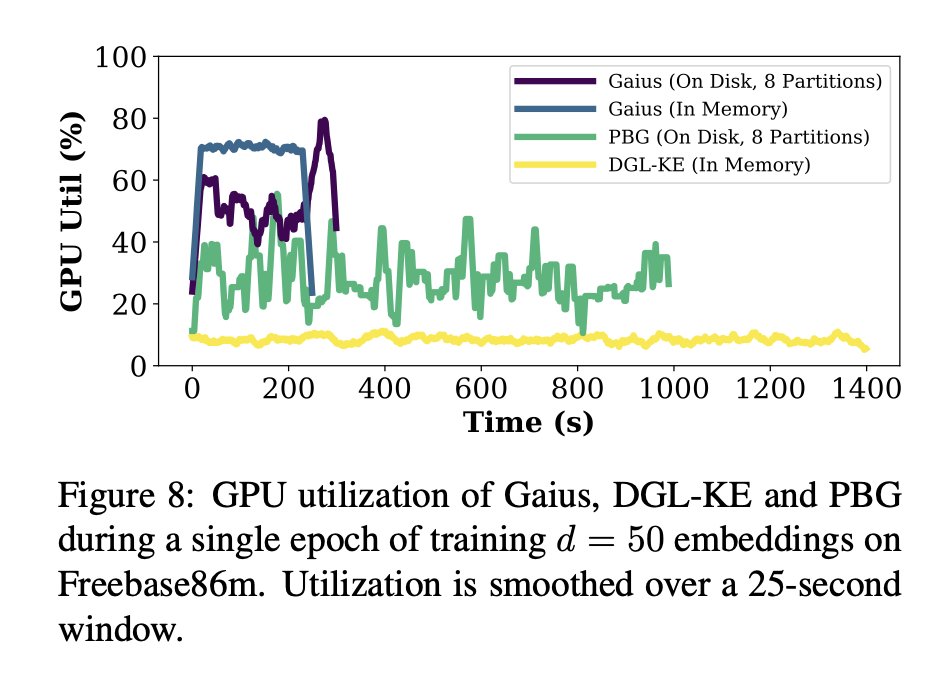
Scalability is a key factor limiting the use of Graph Neural Networks (GNNs) over large graphs; w/ @RWaleffe, @JasonMohoney , and Shiv, we introduce Marius (arxiv.org/abs/2202.02365), a system for *out-of-core* GNN mini-batch training over billion-scale graphs. (1/5)
2
5
33
Theo Rekatsinas retweeted

13 Sep 2024
Announcing a deadline extension for the ATTRIB workshop! Submissions are now due September 25th, with an option to submit October 4th if at least one paper author volunteers to be an emergency reviewer. More info here: attrib-workshop.cc
1
5
24
7,225
Theo Rekatsinas retweeted

We had a great @dagstuhl seminar this week gathering to discuss resource-efficient ML. Many thanks to my co-organizers (@ppietzuch, @matthiasboehm7, @anaklimovic, @oanabalmau) and all the participants!

2
5
52
4,117
30 Jun 2024
Time for #AI and real-time analytics to take the fun out of cycling cyclingweekly.com/racing/vis…
3
395
13 Jun 2024
Very cool work @RWaleffe !!
13 Jun 2024

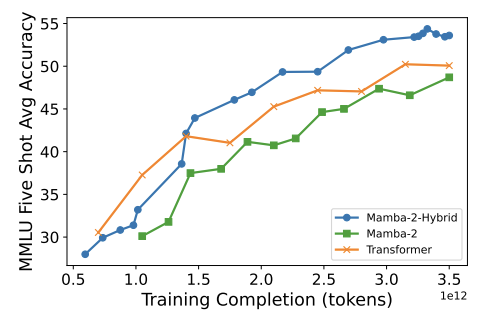
A 8B-3.5T hybrid SSM model gets better accuracy than an 8B-3.5T transformer trained on the same dataset:
* 7% attention, the rest is Mamba2
* MMLU jumps from 50 to 53.6%
* Training efficiency is the same
* Inference cost is much less
arxiv.org/pdf/2406.07887
2
16
4,034
Theo Rekatsinas retweeted

29 May 2024
Aurora is an AI foundation model that flexibly achieves SoTA 5-day air pollution, 10-day global weather, and other forecasts. More importantly, it shows evidence of good scaling properties and adaptation to new atmospheric tasks. Excited to see scale up. microsoft.com/en-us/research…
5
16
53
12,499
26 May 2024
5
887
9 May 2024
Data pruning to reduce pertaining costs is hot, but fancy pruning can take just as long to select data as to train on all of it! Patrik, @Rwaleffe, and @vmageirakos's work at #ICLR2024 tomorrow shows how a simple, low-cost tweak to random sampling outperforms trendy methods!
1 Jun 2023

Not convinced about using random sampling for data pruning? Consider twice! In our recent work, we introduce Repeated Sampling of Random Subsets: arxiv.org/abs/2305.18424, where we sample a subset of data at each epoch of training instead of only once at the beginning!
2
4
15
2,450
9 May 2024
You can find all our comparisons against 30 importance-based data pruning and selections methods at our paper: arxiv.org/abs/2305.18424 Turns out that sophisticated pruning might be a mirage for pre-training...
1
409
Theo Rekatsinas retweeted

7 May 2024
New job post looking for senior ML Engineers in Model Evaluation and Understanding. If you are at #ICLR2024, come talk to our group at the Microsoft Booth tomorrow at 9:30 am. Link for application: jobs.careers.microsoft.com/g…
1
7
22
4,410
Theo Rekatsinas retweeted

25 Mar 2024
We sadly found out our CTM paper (ICLR24) was plagiarized by TCD! It's unbelievable😢—they not only stole our idea of trajectory consistency but also comitted "verbatim plagiarism," literally copying our proofs word for word! Please help me spread this.

45
191
951
347,155
Theo Rekatsinas retweeted

19 Jan 2024
How we feed the data has a significant effect on time-to-accuracy. This work will appear in #ICLR2024. We got mixed bag reviews. Some loved it and some pretty much hated it. I guess these are the sort of papers we would like to have in a conference as they initiate discussions.
3
11
4,477
Theo Rekatsinas retweeted

11 Jan 2024
We are thrilled to announce the Together Embeddings endpoint! 🚀
Higher quality than OpenAI or Cohere in the MTEB benchmark. ✅
State of the art M2-Retrieval models with up to 32k context length. ✅
Up to 4x lower price. ✅
together.ai/blog/embeddings-…
Details👇

21
55
327
133,640
Theo Rekatsinas retweeted

8 Jan 2024
The first round of SIGMOD 2025 abstract deadlines is this Wednesday, January 10, at 23:59 AoE. Full paper due one week later. Please send your best work!
There are a number of procedural changes this year, please have a close look at the CfP: 2025.sigmod.org/calls_papers…
1/2
1
10
24
4,536
Theo Rekatsinas retweeted

20 Dec 2023
I highly recommend this thoughtful blog by @deliprao, painting the academic paper game in a bigger picture.

2
3
23
4,040
Theo Rekatsinas retweeted

14 Dec 2023
If you’d like to join Microsoft Research New England as a researcher in AI / ML / statistics, please apply here: jobs.careers.microsoft.com/g… @MSFTResearch @MSRNE
1
24
129
23,200

Play with it and please give us feedback how we can do better!
12 Dec 2023

Transitioning from OpenAI to Mixtral? Simply add your TOGETHER_API_KEY, change the base URL to api.together.xyz, and swap the model name.
Oh, and Mixtral Instruct v0.1 is now live on Together API 🙌

2
12
2,123
Theo Rekatsinas retweeted

8 Dec 2023
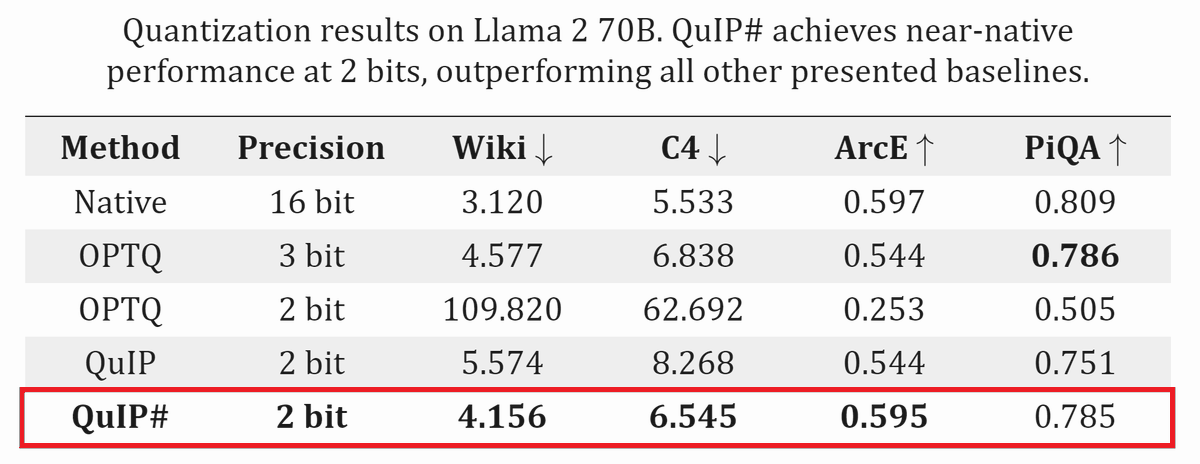
🧵 (1/n)
👉 Introducing QuIP#, a new SOTA LLM quantization method that uses incoherence processing from QuIP & lattices to achieve 2 bit LLMs with near-fp16 performance! Now you can run LLaMA 2 70B on a 24G GPU w/out offloading!
💻 cornell-relaxml.github.io/qu…
24
197
1,001
363,359
Theo Rekatsinas retweeted

1 Dec 2023
It was really fun giving this talk. I am truly excited about the evolution of Amazon Redshift and where we are going with Analytics at AWS.
The most rewarding aspect of it, is to have very demanding customers, such as Klarna, who in this talk talked about how all the hard work the Redshift team has put into the past years has positively impacted his day to day worklife.
#amazon #redshift
youtube.com/watch?v=1tWwkmWO…
4
23
4,978
Theo Rekatsinas retweeted

1 Dec 2023
In the context of this grant, I have openings for postdocs with interests and background in mathematical foundations of trustworthy machine learning @CSatETH - if interested, write an email or talk to me @NeurIPSConf in NOLA!
21 Nov 2023

👏Big congratulations to our professors Niao He, @anaklimovic, Rasmus Kyng, and @FannyYangETH on receiving an SNSF Starting Grant for their respective research projects. The grant is awarded by the Swiss National Science Foundation @snsf_ch.
bit.ly/49Gl9aF
@ETH
1
6
37
9,722
Theo Rekatsinas retweeted

29 Nov 2023
Microsoft's Eagle system is #3 on the top-500 list of fastest supercomputers but it's only a fraction of the actual installed compute capability for (Open)#AI (and #HPC).
Trains #GPT-3 on 4 mins - much more to come soon!
Azure's @markrussinovich in youtube.com/watch?v=c4SUhWBy…


7
16
77
21,513