
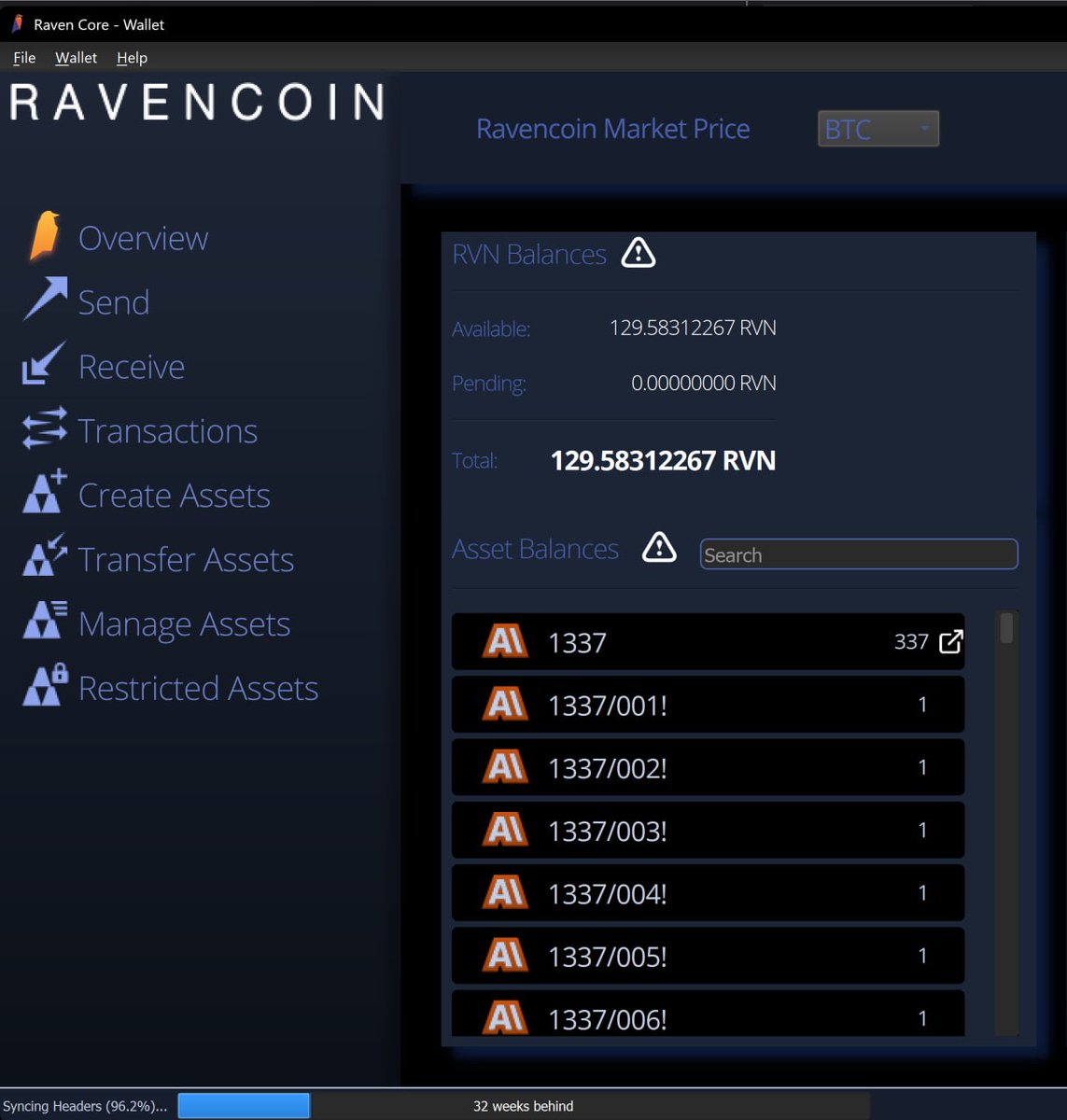
Real World Asset Minting ¹³³⁷ Art Tokens.
Joined May 2018
- Tweets 21,883
- Following 245
- Followers 10,411
- Likes 78,081
2,591 Photos and videos













Pinned Tweet

11 Aug 2025
Who can explain to me what this is?

14
9
36
3,045
RÀ ¹³³⁷ NFT retweeted

This kawpdate addresses a bug that was discovered in one of Ravencoin’s forked code projects.
The bug concerns Ravencoin assets and not RVN itself. So exchanges that only trade RVN are not affected.
This update contains a BIP9 soft fork at 70%. With an expiration of 1 year.
Miners are encouraged to update. Source code will be released at a later point in time.
Fix was addressed by developer hans-schmidt.
Kind regards,
-Jeroz 🐣

Kawpdate.
github.com/RavenProject/Rave…
8
12
71
5,098
Jun 14
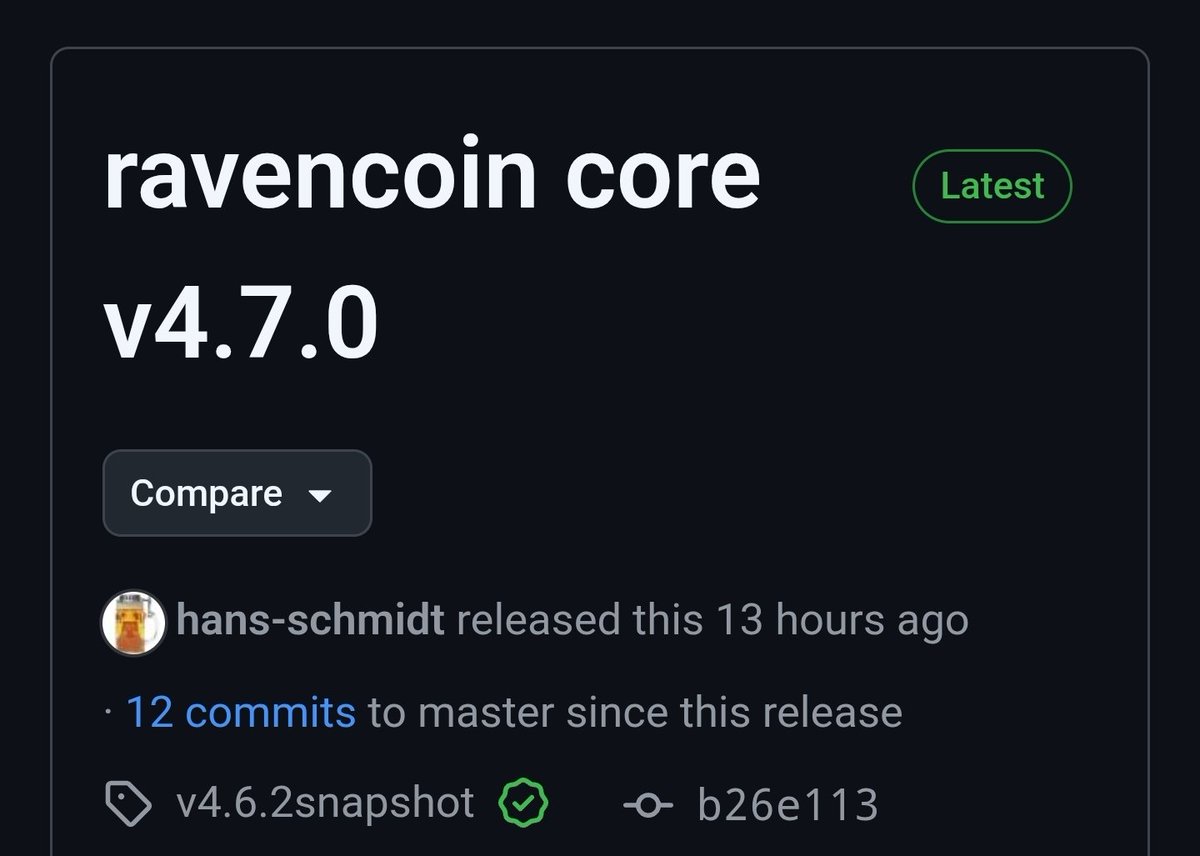
New @Ravencoin Core v4.7.0 out!
- Fixes asset transfer bug
- Sendmany & sendtoaddress RPCs now work
Must-run for miners. Drop-in replacement (no re-sync). Linux binary only for now source coming later for responsible disclosure.
3
5
34
785
Jun 14
3
10
167
⚠️ Active Asset Inflation Exploit On @Ravencoin Forks ⚠️
@tronblack @rvn_foundation @MangoFarmAssets $RVN

On 05 June 2026 the EVRMORE chain was exploited and the Satori token supply was compromised.
Within a few hours of the exploitation the Satori team was able to identify the transfer of nefarious tokens. The EVR dev team and all exchanges were immediately notified. Upon notification exchanges halted transactions and trading.
The exploit - The overflow bug.
The EVR chain does not currently verify asset transfers compared to supply minted. Example - An attacker who owns quantity X of an asset can transfer X (2^64) of that token. In Satori's case, the bad actor or actors(s) were able to mint Satori tokens (assets) without having having control of the Main Asset.
** Note - This affects all chains forked from @Ravencoin.**
What's next:
- The EVR Dev team is working through a code update to correct the bug. This is not an overnight fix and will take time.
- The Satori core team in conjunction with the community will need to decide the best way forward. It is highly recommended that everyone stop movement of assets. The most likely solution starts with rolling back Satori until just prior to the exploit point.
- Until a way forward is set and active, the Satori protocol will not be issuing prediction rewards.
- Keep your notifications on and stay connected in the Discord community for the latest information as we navigate through this together.
Just as anything this project has endured we will continue to come back stronger and continue to grow. 💪
1
4
27
2,962
RÀ ¹³³⁷ NFT retweeted

Jun 8
25 Claude Code skills to build a business
github.com/iamzifei/show-me-…
4
36
295
15,466
RÀ ¹³³⁷ NFT retweeted

Jun 5
We need another review and approval of the RIP-25 ( Tron already did it ) , I ask every one in the community to read and review and then approve the code, otherwise we cannot start with testnet $RVN $BTC @tronblack #RWA github.com/RavenProject/Rave… github.com/RavenProject/Rave…
4
9
26
770
RÀ ¹³³⁷ NFT retweeted

Jun 3
The biggest asset in the world is your mindset.
424
2,080
10,159
243,858
RÀ ¹³³⁷ NFT retweeted

Jun 1
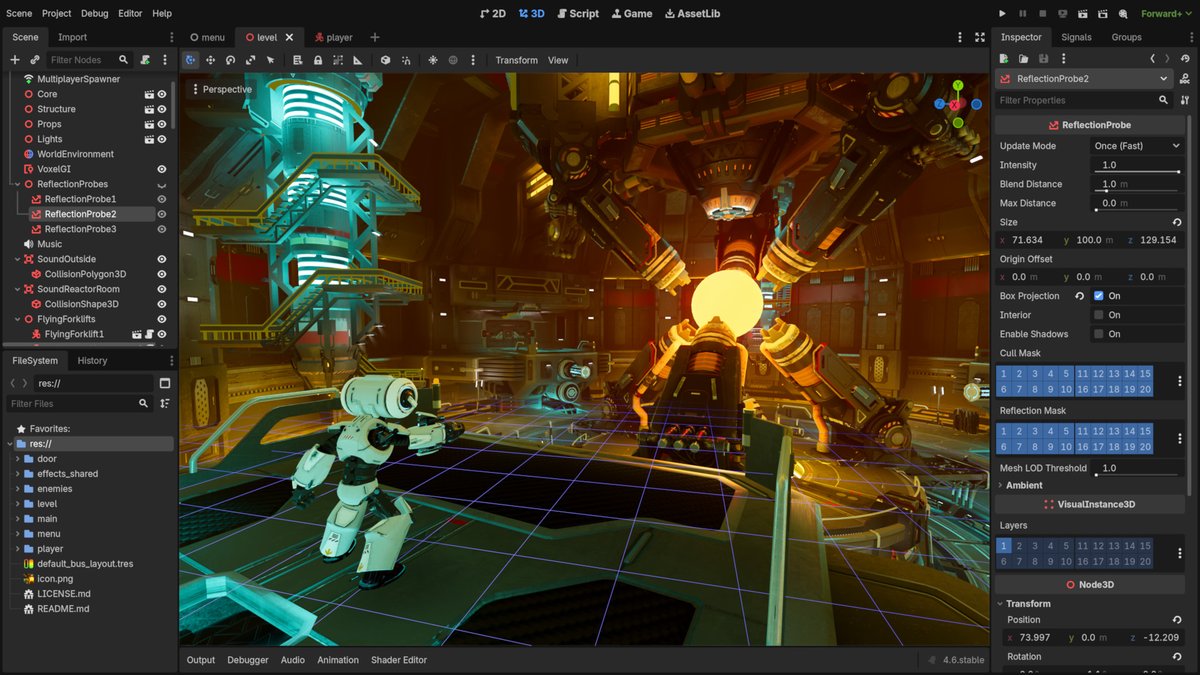
Two Argentinian friends killed the entire game engine industry.
It's called Godot. You build full 2D and 3D games for free, ship them anywhere, and keep 100% of every dollar you ever make.
Here's how it works.
Godot is the engine. Clean editor. Runs on Windows, macOS, and Linux. You install it once and it does everything Unity and Unreal do without a single fee attached.
The whole thing is built on a node and scene system. Every part of your game is a node. You stack them, nest them, reuse them. One mental model for the entire engine instead of fighting twelve different systems.
→ No license fee
→ No royalty on your revenue
→ No per-install charge
→ Exports to desktop, mobile, web, and consoles
→ GDScript, C#, and C all supported
Unity cannot claw back a cut of your game. There is no contract. No revenue threshold. No surprise invoice when you blow up.
The entire game engine industry is built on one assumption. That you will hand over a slice of everything you earn rather than use the free thing that already does the job.
That assumption died in Buenos Aires.
111k stars. MIT License. 100% Opensource.
github.com/godotengine/godot
godotengine.org/
53
196
1,144
75,662
RÀ ¹³³⁷ NFT retweeted

May 31
We live in a high tech dark age
Everyone called GPU mining wasteful when normal people could plug in hardware at home and earn permissionless money
Then ETH killed mining, called it “going green” and the winners were big holders, staking providers, exchanges, and institutions

1
2
7
211
May 26
The functionality we needed when we used Ravencoin to tokenize glass art
May 24

🚨 RavenTag in action:
→ Tag recognition (AUTHENTIC)
→ Revocation (stolen)
→ Verification as stolen
→ Restoration (back to AUTHENTIC)
Real control and instant response to theft/counterfeiting.
GitHub: github.com/ALENOC/RavenTag
$RVN #RWA #AntiCounterfeiting
7
46
1,136
RÀ ¹³³⁷ NFT retweeted
May 24
🚨 RavenTag in action:
→ Tag recognition (AUTHENTIC)
→ Revocation (stolen)
→ Verification as stolen
→ Restoration (back to AUTHENTIC)
Real control and instant response to theft/counterfeiting.
GitHub: github.com/ALENOC/RavenTag
$RVN #RWA #AntiCounterfeiting
5
30
70
4,594

I’m at a crossroads. Ravennodes needs security updates and updates to fix memory issues. Also, @Ravencoin electrum needs updating because it’s not compatible anymore with the latest version of ledger firmware. ~3 days work.
I don’t have free time anymore to do these things. :(
6
5
26
1,610
RÀ ¹³³⁷ NFT retweeted
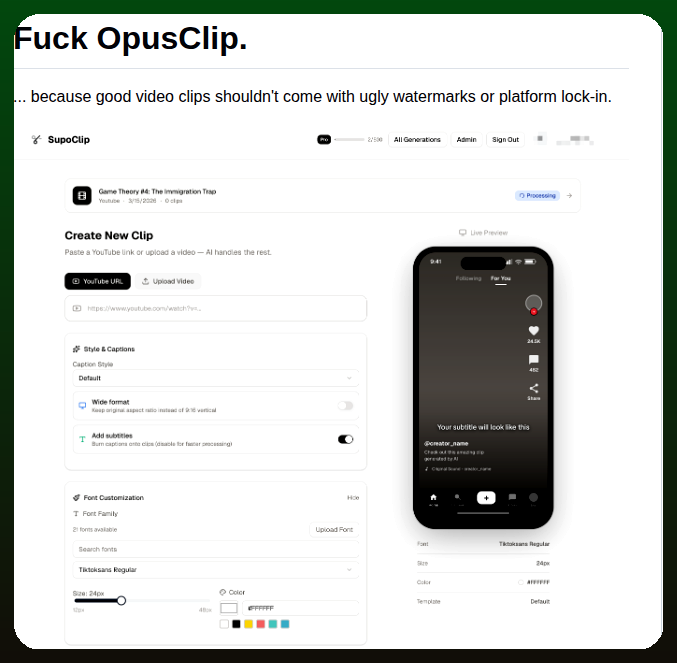
May 13
Self-hostable OpusClip alternative for watermark-free video clipping
github.com/FujiwaraChoki/sup…
1
31
293
12,639
RÀ ¹³³⁷ NFT retweeted

May 11
The largest open library in human history, Anna's Archive, has been ordered to pay Spotify and the three largest record labels on the world $322 million.
The defendant has not appeared in court and is not going to. The site is still up with two backup domains standing by and there's nothing the censors can do.
Anna's Archive currently holds 63 million books, 95 million academic papers, and 1.1 petabytes of mirrored torrents. It is free. It is searchable. It is run by a pseudonymous person nobody has identified after four long years of searching.
In the four months since the music industry filed the first of three coordinated lawsuits, the library has lost six domain names and added two million books to the catalogue. The cartel is suing it faster every month, and it is growing faster every month.
In December, Spotify and the major labels filed. In January, OCLC, the company that runs WorldCat, won a default judgment of its own. On March 6th, thirteen of the largest book publishers in the United States, including HarperCollins, Penguin Random House, Simon and Schuster, Macmillan, Hachette, Elsevier, Wiley, and McGraw Hill, filed a third lawsuit in the same federal court.
The publishers' complaint runs to seventy-four pages. They call Anna's Archive a "brazen pirate operation." They call it "an illegal supplier of stolen content to the AI industry."
The same publishers are simultaneously suing Anthropic, Meta, OpenAI, and NVIDIA for training their models on the same corpus the publishers want Anna to destroy. The cartel argues, in two parallel federal courts, that the corpus cannot be used by anyone. Not the pirate who built it. Not the AI company that downloaded from it. Not the graduate student who pulls a paywalled paper from it at two in the morning.
Anna did not respond to any of the three complaints. Anna has never responded to any complaint. Anna is a name on a blog and a public key on a server and a person, or maybe several people, in a jurisdiction nobody has identified after four years of searching.
The judgment is uncollectable. The permanent injunction binds Cloudflare, Public Interest Registry, Njalla, the Switch Foundation, Tucows, and nine other named intermediaries. The Greenland registry is not on the list. The Greenland registry has not complied.
The site currently lives at .gl, with .pk and .gd standing by. The corpus has always moved faster than the censor. The censor has always called the corpus piracy. The corpus has always survived the censor by becoming the readers themselves.
The publishers' lawsuit cannot reach the torrents. The torrents are already seeded across continents and IPFS nodes and personal NAS drives owned by people the publishers will never find. The default judgment is paper. The corpus is everywhere.
The cartel will win every lawsuit but they will lose the war. The publisher who walks into court next month with a fresh filing will be filing against a defendant who has, in the time since the last filing was sealed, mirrored another half million books to another seven hundred volunteers in another forty countries.
There is no defendant to find. There is only the next upload. It is already seeding.

112
1,618
8,346
839,552
RÀ ¹³³⁷ NFT retweeted
May 10
In April, a website that has been sued, blocked, deplatformed, and chased across thirty-seven domains over fifteen years quietly launched its own AI.
Sci-Hub is the largest unauthorized library of scientific papers in human history. Ninety-five million academic papers. Tens of millions of books. Built and maintained by a single Kazakhstani neuroscientist named Alexandra Elbakyan since 2011, funded by donations, hosted on whatever country's registrar will tolerate it that year, mirrored across torrents and IPFS and Telegram bots.
Elsevier sued. Sci-Hub stayed up. The American Chemical Society sued. Sci-Hub stayed up. India sued. Sci-Hub stayed up. Swedish registrar Njalla cut the .se domain in January. Sci-Hub stayed up at .al, .ru, .ee, .box, and a half-dozen .onion addresses the registrars cannot reach.
Now the library has built its own intelligence.
Sci-Bot launched in alpha in April. You ask it a research question. It answers, and it cites real papers from inside the corpus, with links that actually open the actual papers.
The bot does not hallucinate citations. It cannot, because it only draws from papers it actually holds. The same property that the venture-funded labs have spent four years and forty billion dollars trying to engineer back into their products is a free side effect of training the model on a library that contains the books.
Anthropic, OpenAI, Google, and Meta have all been sued in the past eighteen months for training their models on the same shadow libraries that Sci-Hub assembled. Meanwhile the corpus those scripts were pointed at, the corpus those models were trained on, the corpus the entire generative AI industry is built on, sat right there the whole time, free, with a search box on top.
The pirates beat them to it.
Sci-Bot was built on a corpus that was already free, by a team that asked no permission, charging no one, with the explicit position that the right to read scientific research is older than the cartel that decided to charge for it.
The same arithmetic the medieval guilds used to keep the printing trade in approved hands. The same arithmetic Pope Paul IV used in 1559 to publish the Index Librorum Prohibitorum. The same arithmetic the Stationers' Company used in seventeenth-century London.
Knowledge has always had a fence around it. The fence has always been guarded by men who did not write the books.
The library answers. We never asked permission. We never had to.

231
3,559
11,365
633,352
RÀ ¹³³⁷ NFT retweeted

May 9
Major life hack: Don't complain, ever. Nobody likes a complainer. They drain the energy of everyone around them. It's exhausting spending time around someone who constantly complains about things outside their control. If it’s within your control, go do something about it. If it’s not, you’re just wasting energy thinking about it. Complaining gives too much power to the thing. Take back that power.
386
1,953
16,750
769,995