
Richard Hearne, RedCardinal.ie: these days mainly interested in Technical SEO and Machine Learning.
Joined December 2007
- Tweets 7,936
- Following 449
- Followers 1,153
- Likes 6,100
328 Photos and videos





Jun 14
Valuable insight into grounding across major AI engines. Might not hold for AIOs, but great research:
dejan.ai/blog/grounding/
1
25
Jun 12
Very interesting. LLMs require us to go back over technical issues resolved a decade or more ago by Search Engines...
Original share from @CyrusShepard
Jun 10

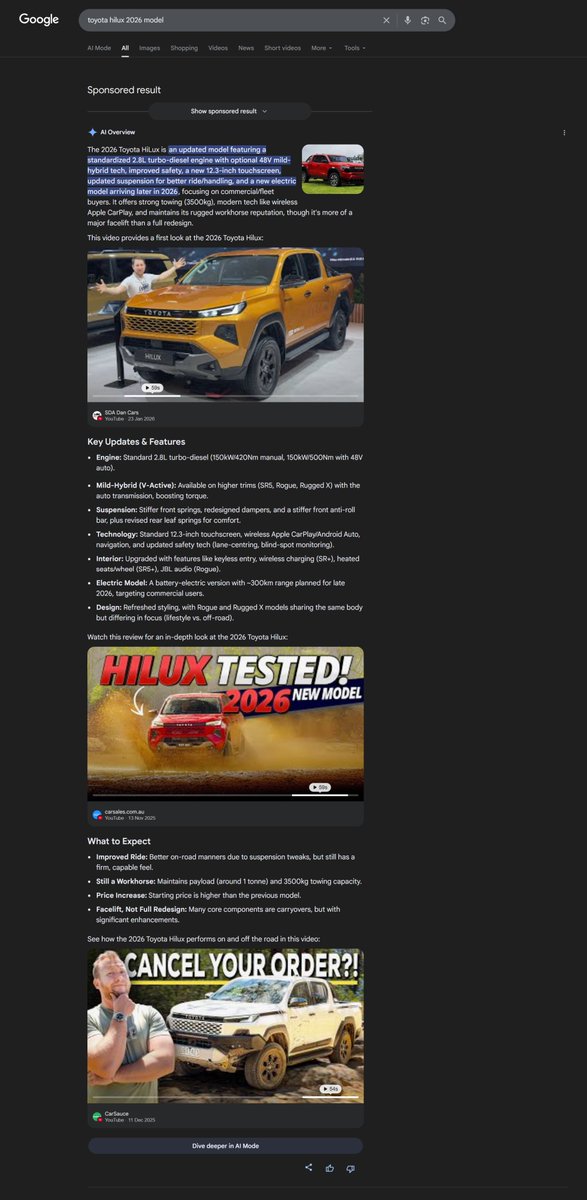
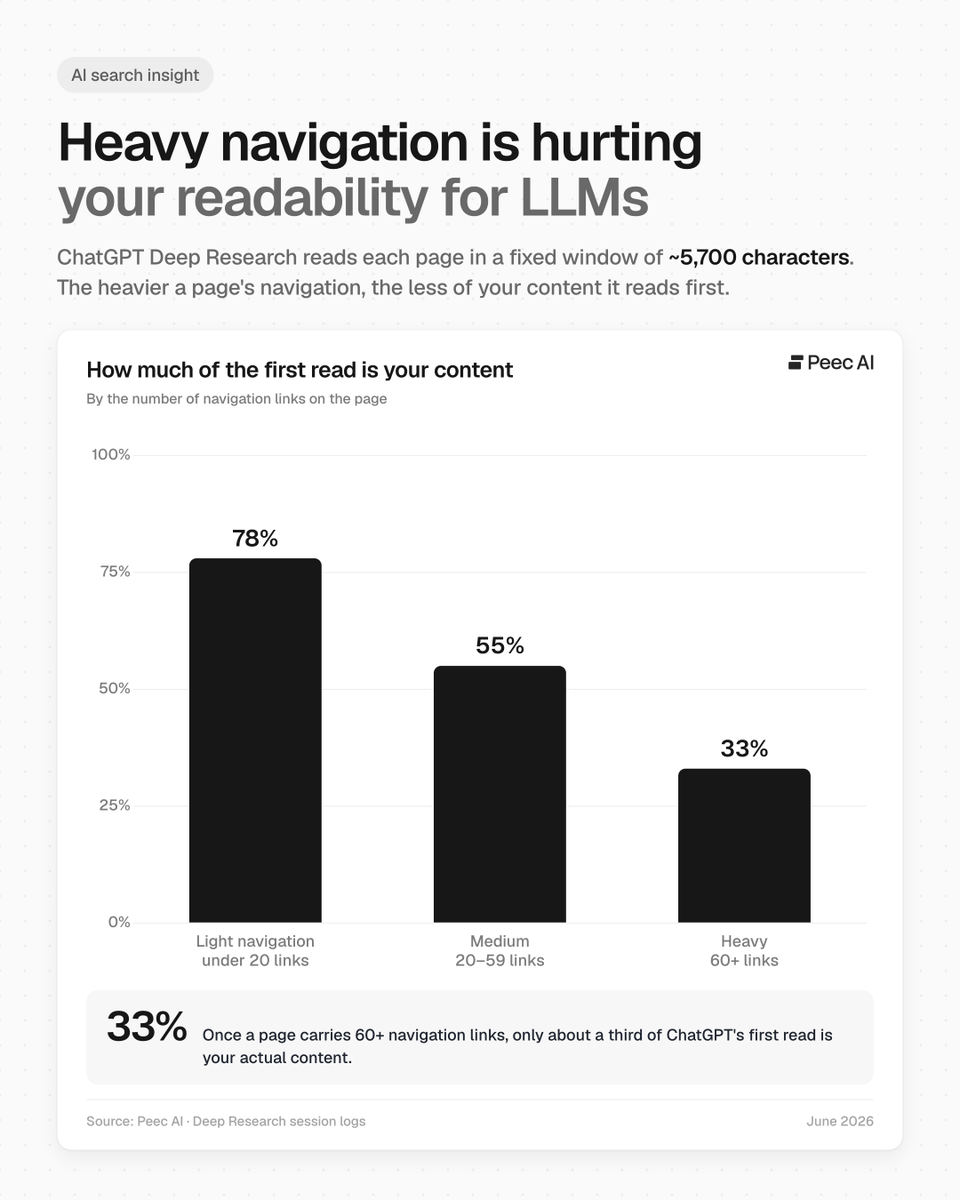
Your navigation might be eating your LLM reading budget ⁉️
We took a closer look at how pages are actually read in ChatGPT Deep Research, to understand what's really happening under the hood.
On its first visit, Deep Research reads each page through a fixed window of about 5,700 characters. The heavier a page's navigation, the less of that budget is left for your content.
We grouped pages by how many navigation links they carry:
➡️ 𝗟𝗶𝗴𝗵𝘁 𝗻𝗮𝘃𝗶𝗴𝗮𝘁𝗶𝗼𝗻 (under 20 links) About 𝟳𝟴% of the first read is your actual content. This is what a clean, content-first page looks like.
➡️ 𝗠𝗲𝗱𝗶𝘂𝗺 (20–59 links) About 𝟱𝟱%. Nearly half the read is already spent on navigation and markup, and this is where most pages land.
➡️ 𝗛𝗲𝗮𝘃𝘆 𝗻𝗮𝘃𝗶𝗴𝗮𝘁𝗶𝗼𝗻 (60 links) Only about 𝟯𝟯%. Two-thirds of the read goes links before the model even reaches your answer.
So on cluttered sites, more than half the reading budget is gone before your real content even begins.
1
89
Jun 1
This is where we will be looking more and more in future as the blue links paradigm continues to fade:

In modern AI search, language models act as re-rankers over results retrieved by traditional rank factors. Even in the absence of traditional ten blue links there's always a clear and measurable ordinal value to each brand mentioned in model's generative output.
Here's how I test this: dejan.ai/optimizer/
Google's grounding pipeline, for instance, decomposes a query, retrieves ranked sources, then has the model select sentence-level snippets under a fixed budget. Ranking #1 buys you a larger share of grounding, though being selected is a separate problem [1].
A model's parametric memory carries its own relevance priors, and those priors are an emerging class of factor shaping which results get selected and surfaced. A brand the model already perceives as relevant for a topic is more likely to be grounded when supplied as a source [2], and these priors are measurable: you can rank brands by how deeply they're embedded in a model's associative structure [3].
To be clear about terminology: when I say model rank factors I mean model-side selection factors. They're distinct enough from Google's ranking signals that I've taxonomized them as alignment, substance, architecture, style, framing, and proof, and built a ranker that simulates the model's source-selection step to measure which of them actually move a page's standing [4].
My current focus is understanding this behaviour through systematic observation of inputs and outputs, probing models directly and tracking how associations shift over time [5].
Direct steering and white-box interpretability aren't available for closed-weight models like Gemini, GPT and Claude, so this black-box approach is the practical one. It's the same logic applied psychology, psychiatry and cognitive science already use.
[1] SRO & Grounding Snippets dejan.ai/blog/sro-grounding-…
[2] Primary Bias on Selection Rate dejan.ai/blog/sr/
[3] AI Brand Authority Index dejan.ai/blog/brands/
[4] Content Optimizer dejan.ai/optimizer/
[5] Beyond Rank Tracking dejan.ai/blog/beyond-rank-tr…
55
May 29
Opened a new Chrome tab. Directly typed query into onmibar. SERP loaded and immediately modaled into this:
44
May 26
Fantastic post extensively covering the workings of Google Discover Profiles (kudos to @1492_Vision):
1492.vision/research/discove…
1
1
45
May 12
The next big question:
What happened around ~17 April? Multiple big News publishers showing the same trend: rising Search, News, Discover traffic into/following March core update, then significant multi-week declines across surfaces since ~17 April.
What did Google change?
1
282
May 11
"Crawled - currently not indexed" is on a complete tear these days... Index cull seems to be on steroids. Only question is: why?
13
1
36
9,209
May 11
Also related, I'm pretty sure:
x.com/i/status/2050543656722…
May 2

Also seeing significant drops in "Page with redirect" numbers across multiple very large publishers. It looks like they've purged lots of URLs from crawl which previously met thresholds. Seeing changes starting March across properties. Could also be reporting change?
2
812
May 11
A fine resource, and a fine tribute to someone who contributed a lot to SEO (and was just an all-round nice guy). RIP Bill.
May 10

Occasionally I still visit Bill Slawski's blog "SEO by the Sea", and sometimes it's either down or slow. So I created a searchable archive of the entire website in an open-source GitHub repo.
Other SEO folks may also find it helpful: deepakness.github.io/seo-by-…
1
6
528
Apr 27
Oh GoDaddy... Utterly bonkers:
Apr 26

Last week GoDaddy moved a 27-year-old domain from my friend's account to a stranger who never submitted a single document. They used an email signature to identify the parent domain and just transferred it. Here's the full story: anchor.host/godaddy-gave-a-d…
1
127
Apr 24
Great coverage (pics of every slide?) from @ChouinardJC of the Toronto Google Search Central Live event (April, 2026):
jcchouinard.com/google-searc…
2
3
234
Apr 22
Well worth digging into the details and background of this "test". Certainly provides plenty of food for thought on AI/Web search nexus:
Apr 22

We get into it here - hobo-web.co.uk/breaking-can-…
1
2
626
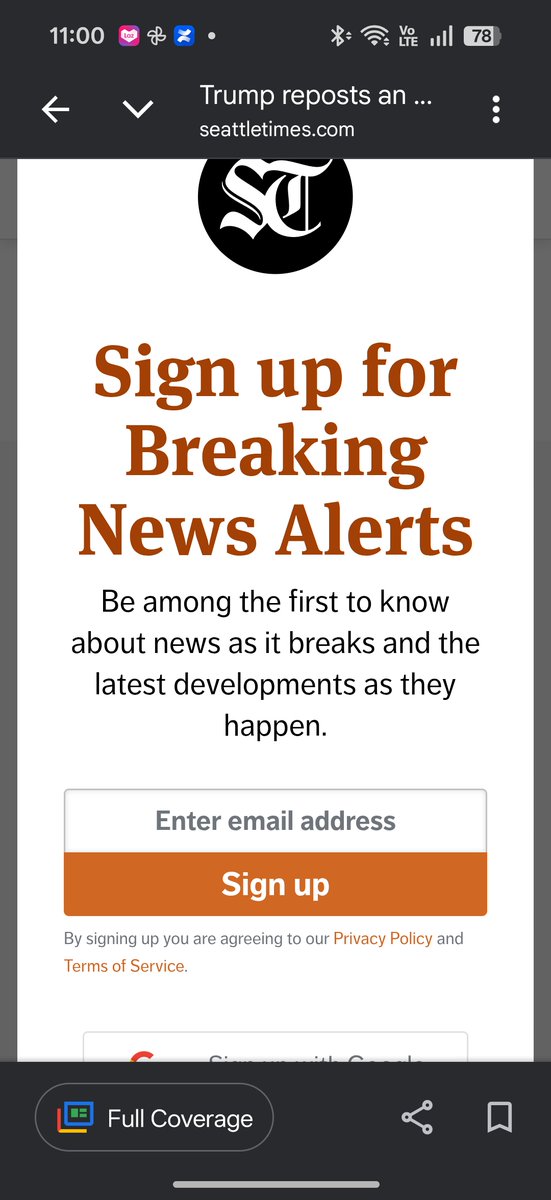
Apr 16
Retrying: I can't get over how many News publishers don't test their modals in the Google News app. @seattletimes it's not possible to scroll or access the close button, so all I can do is hit back. You're not alone. There's lots of "bad click" data generated by this ux pattern.
67
Apr 15
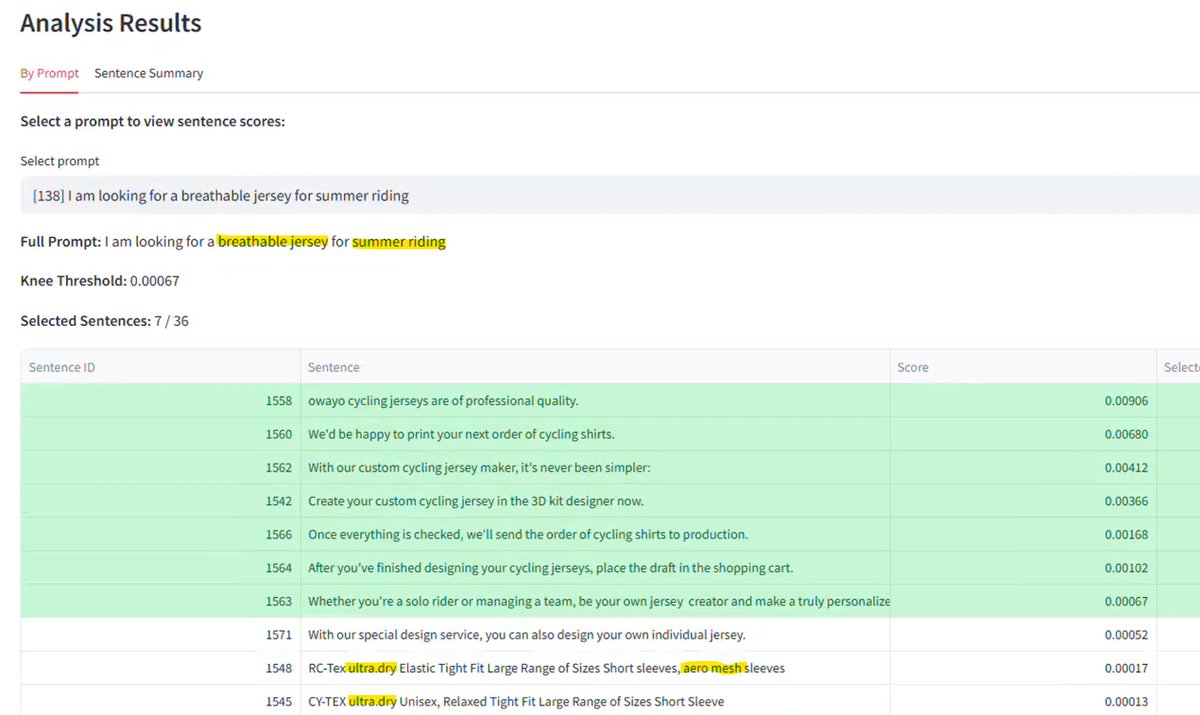
Fascinating. More especially so given the scale at play here:
LLM-as-a-judge for Netflix show summaries.

I just published a report on the LLM-as-a-Judge system used to evaluate show synopses on Netflix. Here’s how we built this system…
What is a synopsis? These are the short show descriptions on Netflix. We want to make sure all synopses are high-quality, but Netflix has hundreds of thousands of them. We need an evaluation system to scale high-quality synopsis coverage for our rapidly expanding catalog.
Rubric. Our evaluation system is based on a multi-dimensional creative quality rubric with four criteria: precision, factuality, tone and clarity. These are the same criteria to which human writers adhere when creating synopses. We create a separate LLM judge system for each criteria that provides a scoring explanation and a binary (pass / fail) score.
Data quality. To adapt these quality criteria into a workable rubric for an LLM judge, we need a golden set of evaluation examples to which to align our LLM judge. We partnered with a group of three writing experts to evaluate ~1K synopses.
To improve agreement on this subjective task, we conducted eight calibration rounds, surfaced disagreements between experts, and evolved our scoring guidelines. Then, we created a final golden set of ~600 synopses using a model-in-the-loop consensus approach where:
- Multiple writers score each synopsis.
- An LLM, guided by the rubric, aggregates to a final label.
- Writers manually review cases with substantial disagreement.
From here, we build our LLM-as-a-Judge system, guided by alignment with these golden evaluation examples, using the following three techniques.
(1) Reasoning. Outputting longer reasoning traces consistently improves scoring accuracy. Our evaluation system uses a tiered rationale approach that asks the LLM to:
1. Write a long explanation of its score.
2. Provide a human-readable summary of the explanation.
3. Output a final score.
By doing this, we can reap the benefits of long reasoning traces while still providing a human-readable explanation for the score, which is useful for human writers.
(2) Consensus scoring is helpful when using reasoning. For example, running the same judge 5 times and averaging the scores increases accuracy by ~5% on some criteria. Interestingly, consensus scoring is less helpful without reasoning, as we find that there is less variance in outputted scores when we are not using a longer reasoning trace.
(3) Agents-as-a-Judge. Factuality has many aspects; e.g., plot, talent, location, or metadata of a show. Instead of evaluating all aspects with one judge, we create an agent system with four agents—each with custom context and logic—for evaluating different aspects of factuality. Then, we aggregate their scores and reasoning into a single output. Using multiple agent judges increases scoring accuracy on the factuality criteria from 72.5% to 83.95%.
Our final LLM-as-a-Judge system uses a combination of these techniques:
- Precision uses standard reasoning-based LLM judge.
- Clarity and Tone use tiered rationale judges with 5x consensus.
- Factuality uses agents-as-a-judge with tiered rational and consensus in each agent.
We achieve scoring accuracies between 83% and 92% across criteria, which matches or exceeds the agreement level among writing experts when evaluating synopses.

1
97
Apr 15
This is really good. For enterprises working in Slack, this gives their content teams the ability to analyse content and get near real-time feedback on how to improve coverage in AI. I imagine it can also cover general SEO quite easily, but placing in Slack is a clever angle:
Apr 14

Good morning 🦞
WordLift Claw is your SEO execution layer in Slack, helping you spot AI Overview opportunities at robot speed.
1
1
4
438
Richard Hearne retweeted

Apr 7
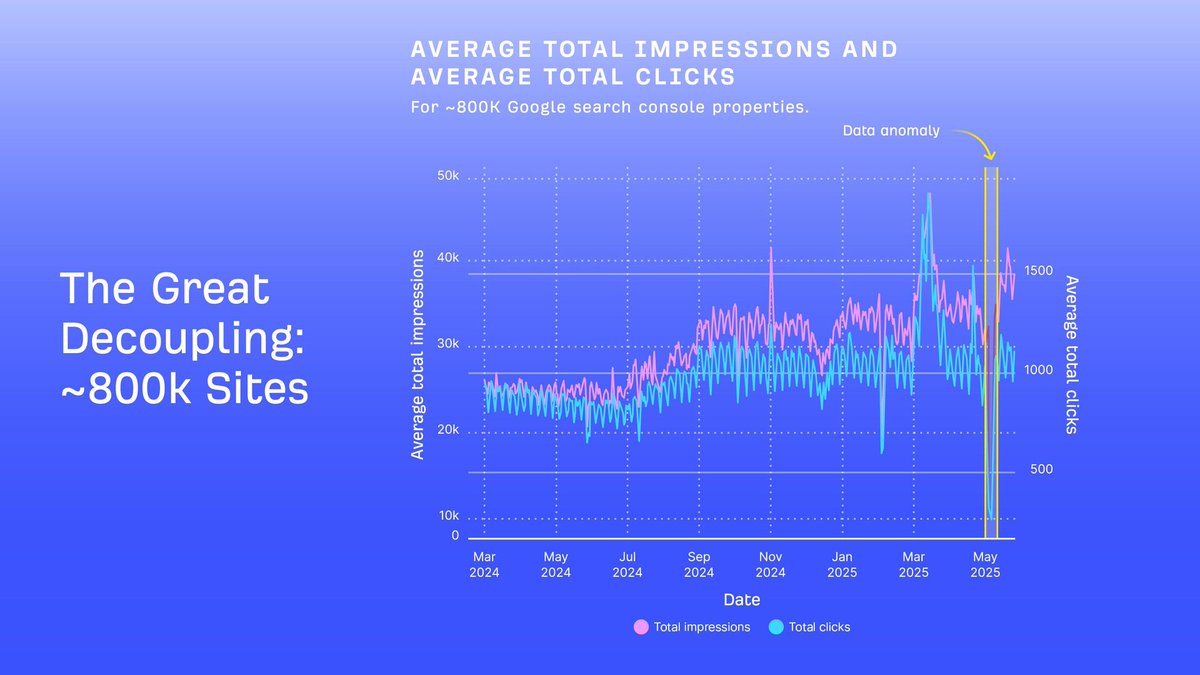
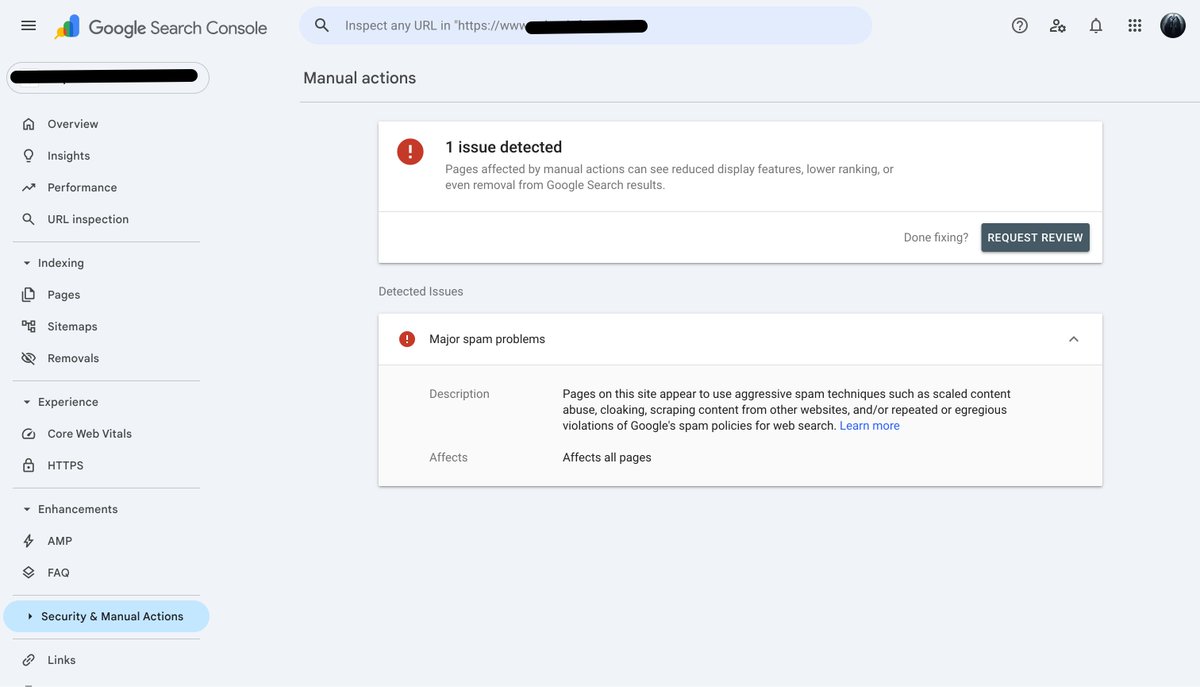
For everyone defending the use of AI to mass-produce more AI slop in my prev post, this is for you.
This is what shows up in Google Search Console when you chase bot traffic instead of real users.
A year ago, I used one of my idle domains to publish 900 blogs with no internal linking and nothing but AI slop. Guess what? This is what happened after the recent update.
If you want to risk it - be my guest.
11
6
67
17,295
Apr 8
Good conceptual framework for entity/brand confidence in AI responses. Definitely worth a read:

1
61
Mar 8
Did anyone really expect Google not to leverage citations to generate more revenue? At a minimum, they needed to offset lost revenue from lower ctr on organic prop results/features. Always going to happen...

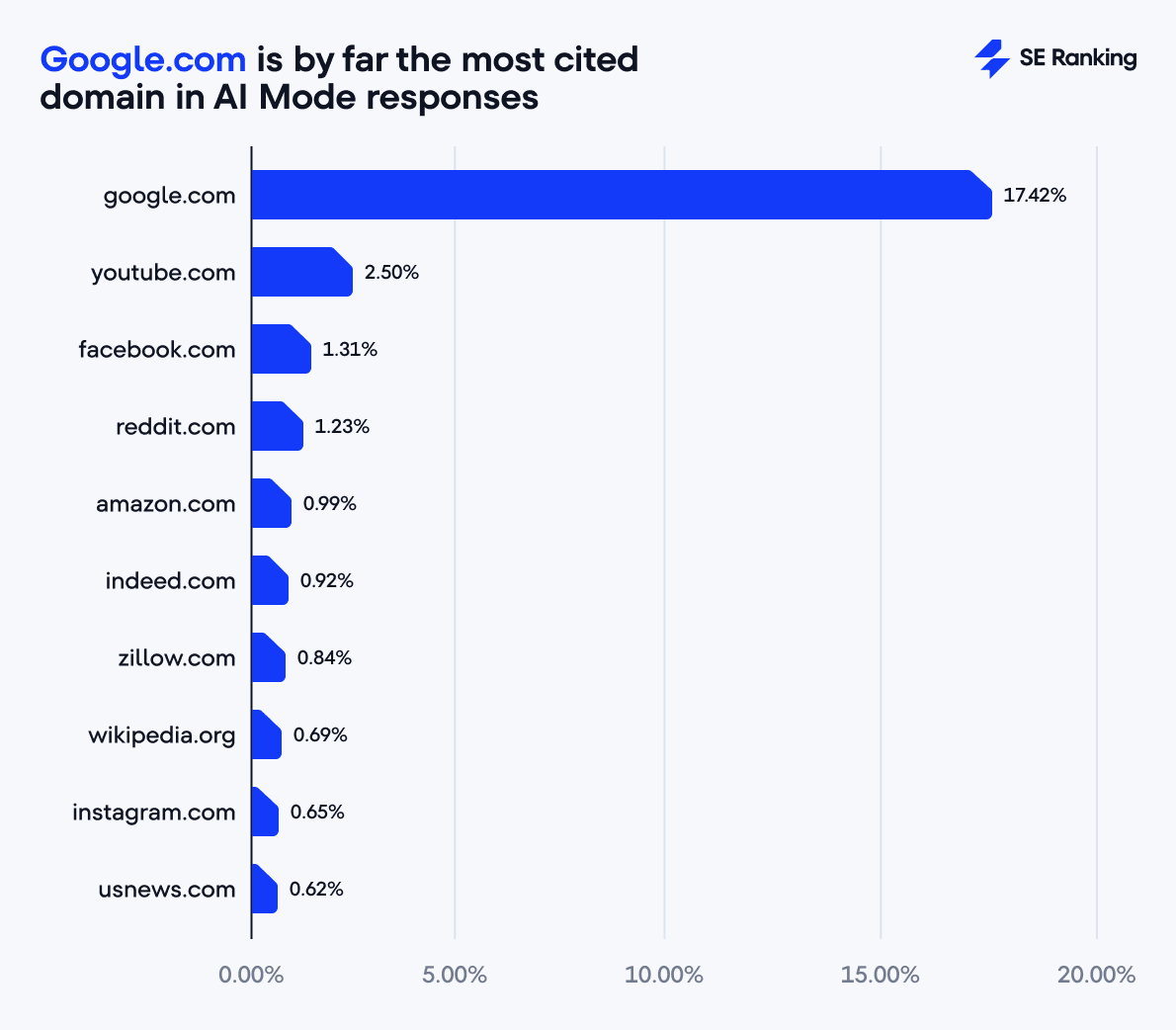
In what is one big giant circle-jerk, Google is citing itself 3X more than it used to in AI Mode.
17% of all citations are to Google itself. Way more than any other source.
Also, it's moved AWAY from just being GBP links (meaning this is NOT just a local thing)
cc: @wilreynolds (thanks for the idea) @rustybrick
Great job @SERanking data team!
2
1
3
233