
Joined September 2023
- Tweets 93
- Following 9
- Followers 342
- Likes 66
31 Photos and videos





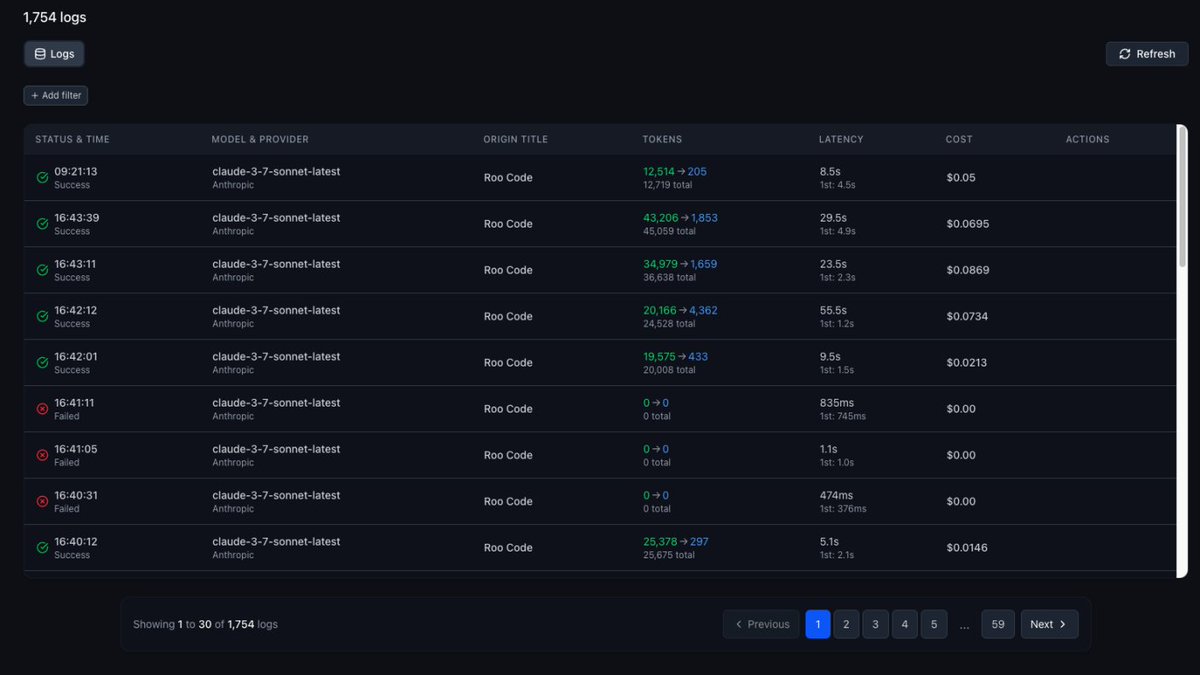





Jun 1
Our friends at @MiniMax_AI are doing a tremendous job!
Now available on requesty.ai

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

1
153
May 18
The Coding Agent Economy.
• $92 avg cost per active user / month
• Claude powers 92% of all coding agent spend (up from 68%)
• Cache hit rates jumped 52% → 86%
requesty.ai/coding-agent-eco…
167
May 15
The throughput density data suggests something counterintuitive:
the highest throughput providers are not necessarily serving the largest requests.
They are serving a massive number of relatively small generations extremely efficiently.
A lot of AI infrastructure performance right now looks less like “big intelligence” and more like high frequency inference systems.
Congrats @GroqInc
requesty.ai/data/provider-th…
1
126
May 14
The surprising thing in the latency data is how compressed the top providers have become.
For a lot of workloads, the gap between “fast” and “slow” providers is now smaller than the variance introduced by tool calls, long context, and agentic execution itself.
Model latency is starting to matter less than workflow latency. Congrats @xai requesty.ai/data/provider-la…
87
May 13
Most AI teams have zero control over which models employees and agents can actually use.
Today we’re launching Approved Models Access Lists in Requesty.
You can now:
• approve models org-wide
• restrict models by API key or group
• enforce regional/compliance policies
• standardize model usage across teams
AI governance is becoming critical infrastructure.
youtu.be/L36O7ST0Hb4
1
99
May 13
The open source model market is consolidating much faster than expected.
A handful of OSS families now dominate traffic share while most new releases barely register.
The gap between “models people talk about” and “models people actually use in production” is getting very large.
@deepseek_ai is still dominating!
Jan → Apr 2026 data from Requesty ↓
requesty.ai/data/oss-family-…
55
May 12
The interesting metric is not tool call request share.
It’s tool call token share.
Once workflows become agentic, token consumption shifts dramatically toward tool execution:
retrieval
code output
tool responses
intermediate reasoning
The number of requests can look normal while the token profile completely changes.requesty.ai/data/tool-call-t…
67
May 11
One of the clearest signals of how people actually use AI might be finish reasons.
Anthropic direct traffic is now 52% tool calls.
OpenAI direct is just 3%.
You can literally see the difference between conversational usage and agentic workflows in the data.
April 2026 data from Requesty ↓
requesty.ai/data/finish-reas…
265
Apr 29
Claude Cowork now works with every model via Requesty Gateway.
EU-only routing. ZDR. 300 models.
requesty.ai/claude-cowork
1
382
Requesty retweeted

Apr 23
@AnthropicAI now allows Gateways to be connected to their Claude app! I've been using it since yesterday and it's awesome!
docs.requesty.ai/integration…

1
2
332
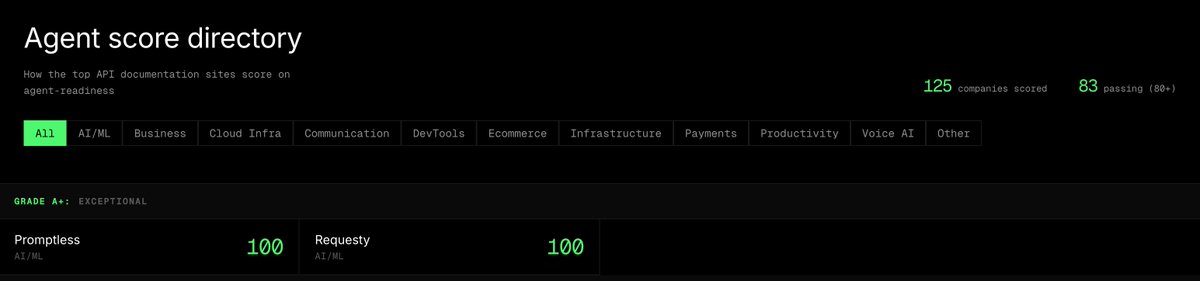

Special thanks to our launch partners, AI gateways, and inference providers. Access GLM-5.1 now:
- OpenRouter: openrouter.ai/z-ai/glm-5.1
- Vercel: vercel.com/ai-gateway/models…
- Requesty: requesty.ai/models/zai/glm-5…
6
15
324
60,736
Mar 25
200,000 European B2B software companies, only 100 made the Cloud Challengers 2026 list.
@RequestyAI is one of them.
We're building the gateway layer for enterprise AI.
4
152
20 Oct 2025
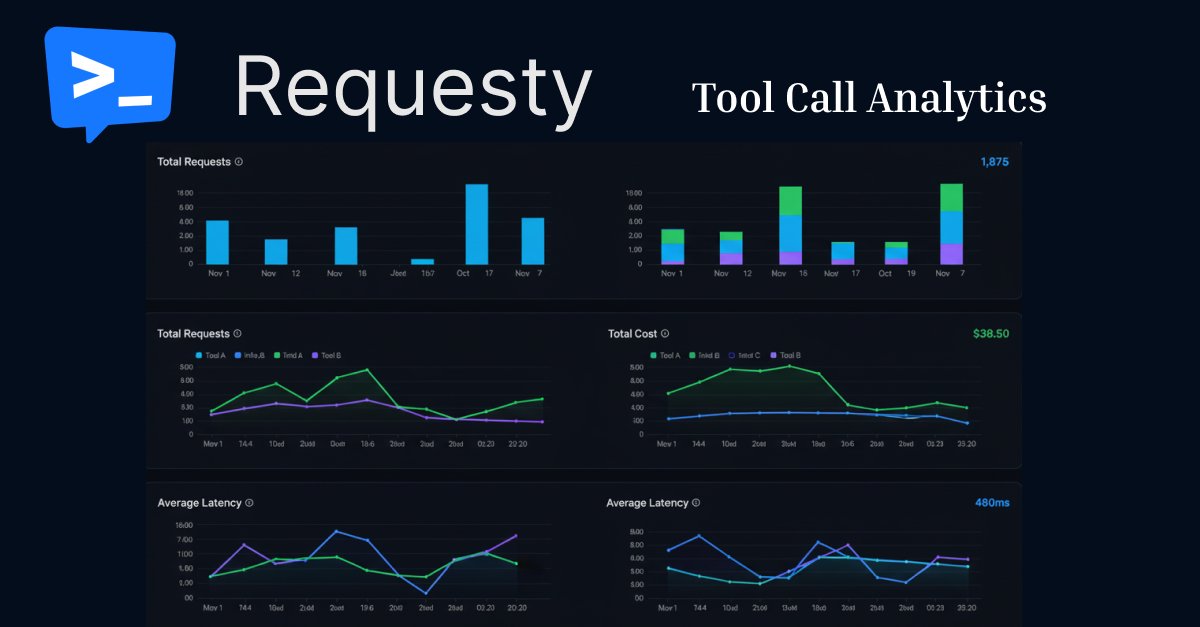
We just shipped tool call analytics 📊
The problem: Your AI agent is slow and expensive, but you have no idea which tool is causing it. Now you can see exactly:
• Which tools are killing your latency
• Where your money is going per tool
• Success rates and failure patterns
1
1
2
552
Requesty retweeted
26 Sep 2025
Extremely excited to share that we've raised a $3m seed round from @20vcFund , @TapestryVC and Insiders!
Thank you for the support @codorniou @HarryStebbings @alexandre_dewez @Kieranleehill
businessinsider.com/pitch-de…
3
5
51
163,572
27 Aug 2025
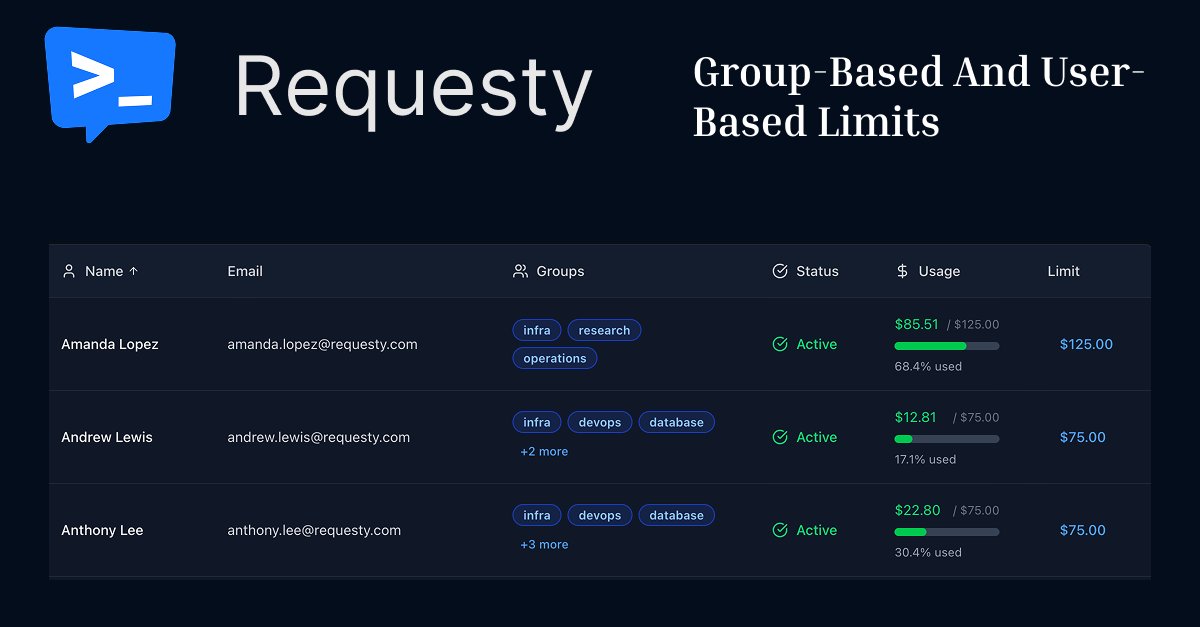
Group & User-Based Limits for our Enterprise customers!
Now you can set spend caps and quotas directly at the user or group level, no more relying only on API keys.
Why this matters:
✅ Enforce limits per individual user
✅ Apply group-enforced limits synced from Okta or Azure
3
574
26 Aug 2025
New in Requesty: Latency-Based Routing
We just launched latency-based routing for all Requesty users!
Now, instead of relying on fallback chains, you can route requests to the fastest available model in real time.
5
425