
32 Photos and videos







Blazing fast training kernels and blazing fast (sometimes beating GPU in my exp.) CPU indices?
Never been a better time to be a late interactor.
Jun 11

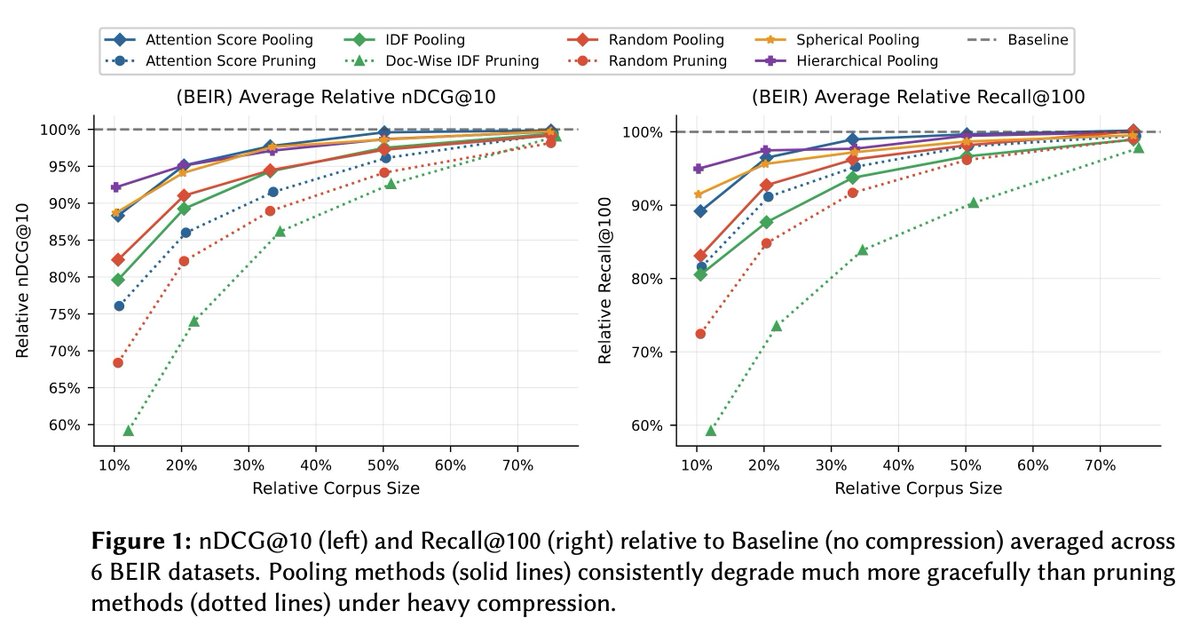
Whether you are GPU poor or GPU rich, today's release of PyLate has something for you!
GPU maxxers: MaxSim kernels greatly speed up training while lowering the memory requirements
CPU enjoyers: TACHIOM enables lightning fast multi-vector indexing and search directly on CPU

1
2
22
1,399
Rohan Jha retweeted

Jun 8
SlimSearcher: Training Efficiency-Aware Web Agents via Adaptive Reward Gating
Introduces a training framework using Pareto-efficient trajectory filtering and Adaptive Reward Gating to make deep research agents more efficient.
📝arxiv.org/abs/2606.07074
👨🏽💻github.com/AQ-MedAI/AntAFu-D…
1
4
18
923
Rohan Jha retweeted
Jun 5
ColBERTSaR: Sparsified ColBERT Index via Product Quantization
@EYangTW et al. present an embedding quantization method that turns a ColBERT index into a true inverted index, yielding an index 50-70% smaller than 1-bit PLAID.
📝 arxiv.org/abs/2606.05568
👨🏽💻 github.com/hltcoe/ColBERTSaR
14
57
4,691
Symbolic tool use can be a useful affordance for reasoners of all sorts - most recently Deontic (permission and rule interpretation & application) Reasoning!
I wonder how much a symbolic semantic search tool would mitigate the losses on the weaker / further improve stronger
Jun 4

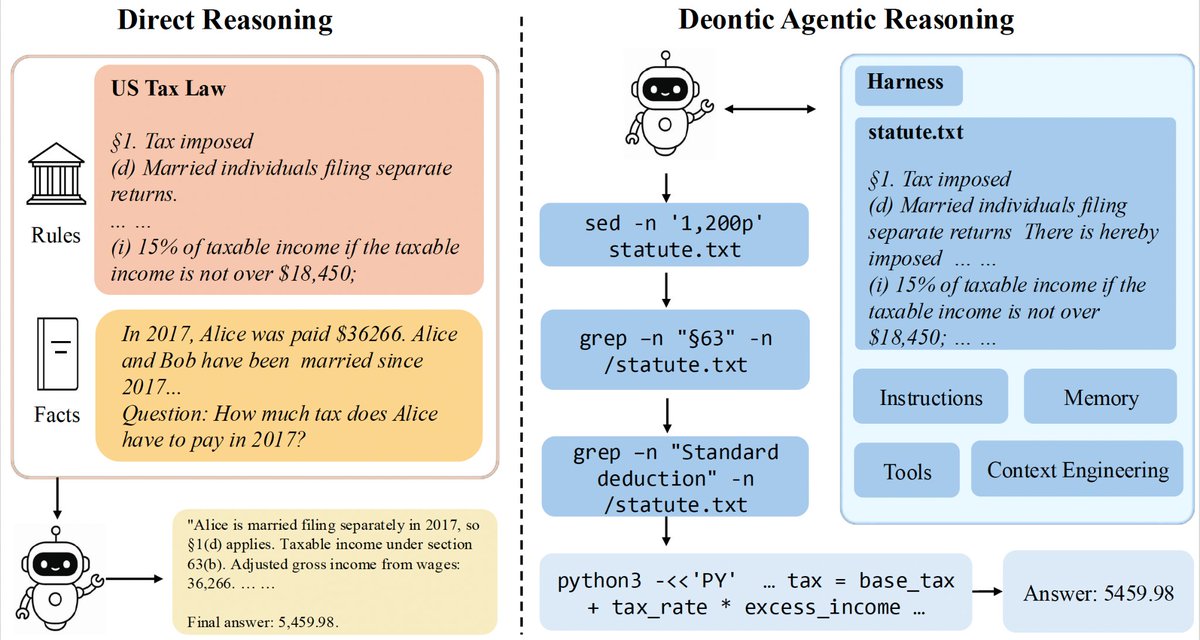
🚨 New paper: Deontic Reasoning with Agentic Harnesses
Can LLMs reason better over long statutes if they interact with rules on demand?
We study Deontic Agentic Reasoning (DAR): models use tools like grep, sed to inspect rules and answer rule-grounded questions.
1
2
9
1,019
Rohan Jha retweeted

Jun 2
RAGTIME is coming back for the 2nd edition!
Come join us to evaluate your search agents!
We once again feature multilingual and fully human evaluation
This is the ultimate way to know whether your systems are doing better

🚨 Every major AI lab is racing to build better "deep research" agents — systems that search, synthesize, and report across the web.
But how do we actually *benchmark* them?
Introducing 🧵 TREC RAGTIME — the shared task for rigorous RAG evaluation.
trec-ragtime.github.io/
1
5
8
793
Rohan Jha retweeted

Jun 3
did someone say late interaction?
it’s getting serious now

7
2
27
4,052
Please consider this my announcement / shill warning. Super excited to be @mixedbreadai 🍞 this summer!
Lots of cool stuff to be done in the first-stage / agentic retrieval areas!

4
2
41
2,735
The more Zipfian distribution of these terms can't be understated.
That means this tiny SAE adapter enables decades of BM25 index optimizations, rather than having to step into the new set of (also great) manifold-hypothesis-driven LSR engines designed for SPLADE.
Jun 2

By now, everyone knows that single-vector embedding models are hugely limiting for modern workflows.
But they contain than you think: you can extract sparse Latent Terms from them.
And it turns out that BM25 is all you need to turn this vocabulary into a strong retriever.
3
30
3,371
Rohan Jha retweeted

May 30
Very excited to finally share this one after sitting on it for far too long! It's very topical now. Blog post coming very soon :)
May 29

Latent Terms: Dense Retrievers Contain Trivially Extractable BM25-ready Zipfian Vocabularies
@bclavie et al. extract indexable, BM25-ready sparse features from frozen dense retrievers using reconstruction-trained Sparse Autoencoders.
📝 arxiv.org/abs/2605.29384
9
15
88
13,247
Anisotropy seems to be the quality-giver (at least confounder) but efficiency-killer. @topk_io identified it as a blocker to SMVE and I'm finding it to block TACHIOM too.
Would love to know what the ISO FT consists of @matospiso 🧐
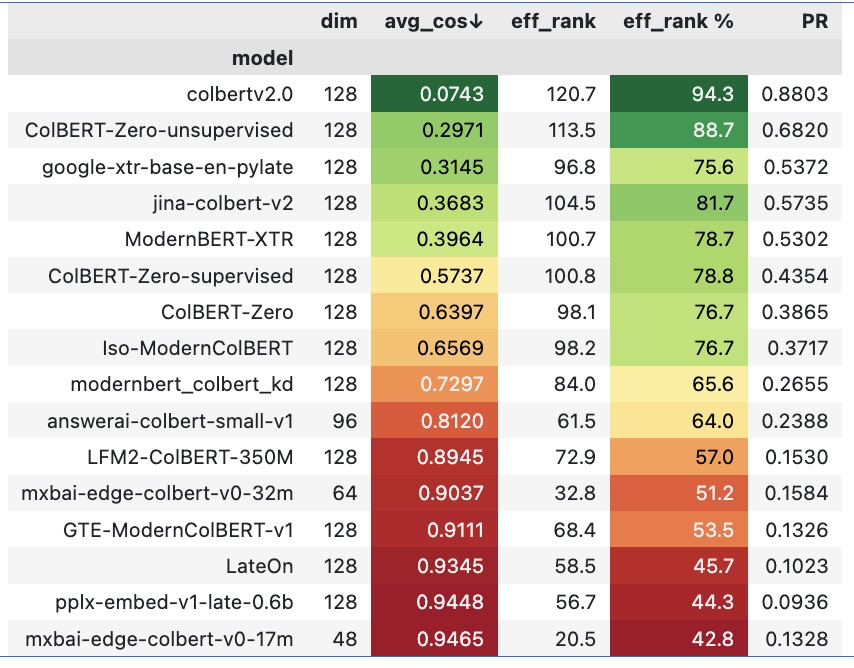

Even strong multi-vector models may break down when optimized for low-latency and high-QPS inference in production. But this can be fixed.
We're open-sourcing Iso-ModernColBERT, a late interaction model built for efficient inference and scalable retrieval.
🧵 (1/6)
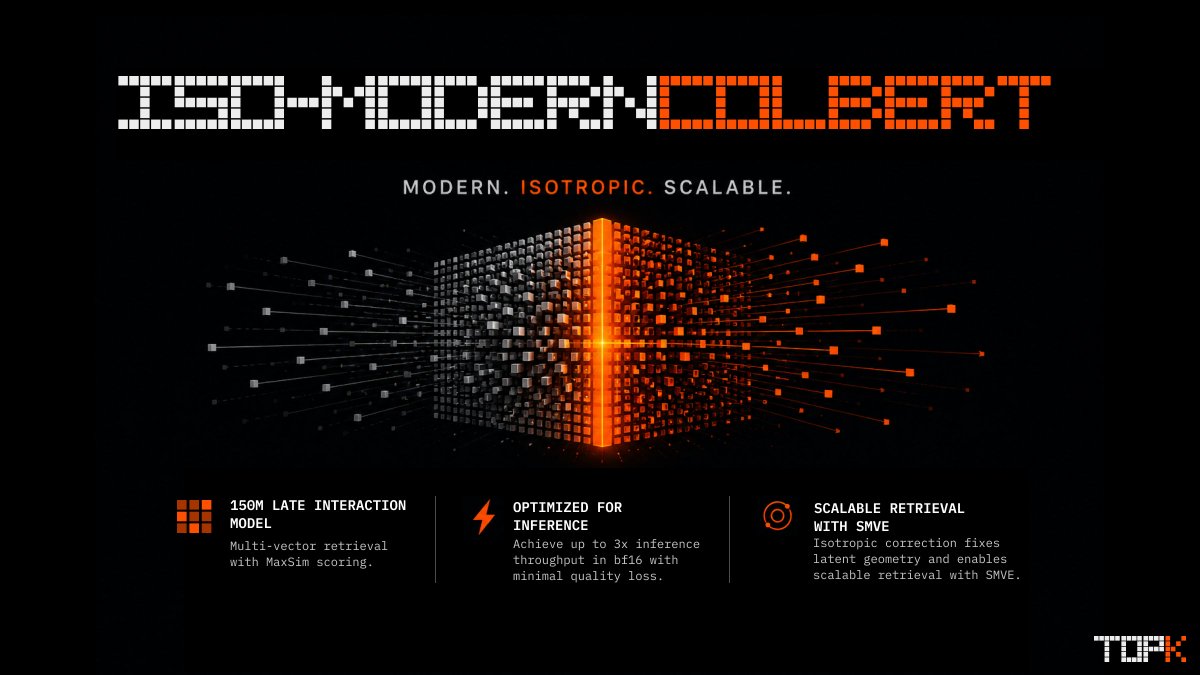
5
11
2,066
Shameless plug that XTR training mitigates anisotropism/degen score distributions!
See modernbert_colbert_kd -> ModernBERT-XTR: same exact training except for XTR vs ColBERT training.
Discussed here: arxiv.org/abs/2605.00646
1
1
6
154
Rohan Jha retweeted
May 29
Latent Terms: Dense Retrievers Contain Trivially Extractable BM25-ready Zipfian Vocabularies
@bclavie et al. extract indexable, BM25-ready sparse features from frozen dense retrievers using reconstruction-trained Sparse Autoencoders.
📝 arxiv.org/abs/2605.29384
1
14
92
22,829
ICYMI: @raphaelsrty just added index.freeze() to FastPlaid v1.4.7 which halves your size on disk if you know you won’t modify the index 🥶
Reversible with index.unfreeze() 🔥

The halving of the size of FastPlaid indexes for analytical read-only workloads is real!
github.com/lightonai/fast-pl…
1
3
16
1,275
PLAID's residual gather for full MaxSim is (theoretically) bandwidth limited, not IOPs limited. A single doc's residuals occupy >1 page.
So you can't expect to save much time with a clever ordering of document embedding bundles according to token-centroid co-occurrence.
2
16
1,143
This is why 1) XTR/WARP win big by skipping this load entirely 2) CPU-only versions of PLAID/TACHIOM indices can perform so well, and 3) VecFlow-Chamfer wins by saturating and parallelizing memory reads over its new 900 GB/s GH interconnect, not even needing to compress
2
6
198
linear search over sublinear centroids -> sublinear search over (small) linear centroids 📈
May 28

this is such an impressive result: search over ~600,000,000 colbert vectors in 10 milliseconds, with a *single* CPU core.
and since this algorithm has sub-linear latency, there’s no excuse for anyone up to tens of billions of tokens
8
391
Rohan Jha retweeted

Late-interaction retrieval is incredibly powerful, but scaling it is computationally challenging. k-means is a huge bottleneck.
Our new architecture, TACHIOM, is fully open-source and tackles this problem: up to 247x faster clustering and 9.8x faster retrieval. ⚡ 🧵👇
3
23
120
8,340
Rohan Jha retweeted

@ben_vandurme and I are recruiting multiple postdoc fellows at JHU. We're looking for candidates w/ strong record in language models, reasoning, coding agents, and/or AI for science.
Interested candidates should send their CV and a brief summary of their research interests to danielk@jhu.edu / vandurme@jhu.edu.
Please reshare for visibility. 🙏
22
36
8,924