
distributed search @couchbase | @blevesearch member, @huggingface contributor | contrastive loss enjoyer
Joined July 2023
- Tweets 454
- Following 462
- Followers 121
- Likes 1,535
40 Photos and videos











Pretty big release of bleve out! GPU accelerated vector search (I helped on this hehe), binary quantization and a lot more!
github.com/blevesearch/bleve
2
4
742
What I would give to be born 10 years earlier to witness this

"You're finally awake! You hit your head pretty hard there.
Huh? Gradual disempowerment? AI-assisted cyberattacks? Mythos and Fable? Listen, we just got some new 1080 Tis, let's try finetuning BERT on the GLUE benchmark!"
2
101
A couple of papers with them:
arxiv.org/abs/2403.06789
arxiv.org/abs/2505.01452
5
126
I wonder if a good way to motivate works like this is to start workshops that aim to break new ground?
You need to only justify that search using your method is indexable and could be efficient, rather than actually having to justify it then and there

Totally agree. New ideas should be measured differently than those that have had time to mature. Otherwise we end up with iteration instead of innovation.
1
1
316
gautham retweeted

Jun 3
Exactly this. I really don’t think the availability of infra should have any bearing whatsoever on whether an idea makes it into the world. We need to encourage papers whose infra is in the future
1
2
9
709
IR research imo tends to limit itself specifically behind index infra: you need vectors, and they're dense, sparse, or (more recently) multivec. You try to conform your new ideas to fall behind these camps
But this doesn't have to be the case! The future is probably gonna look really different. If the method is good enough, the retrieval systems will build themselves around it. Late interaction crossed that hill: only last year there were thousands of articles about how "slow" it was for first stage retrieval, and now we have colbert models and fast indexes popping up everywhere
Jun 3

I have a deeper note to make about this: we need to rethink how we approach retrieval research if we want to have an LLM moment.
I think a problem we have as a sub-field is a lack of openness to early research that might be paving the way to what comes next, even if it's not all that good yet.
Let me explain: You might've noticed that we wrote both paper&blog in a way that almost doesn't care that the results are impressively good (essentially sparse SOTA for ~bert-sized model models).
The reason for this is that I truly don't think that the retrieval performance matters here, beyond proving that the method contains signal.
There has been a lot of progress in (applied) retrieval world and embeddings in the last few years, but one thing is still pretty apparent: we understand very little about how things work, and why they work. We've developed better methods, but they are largely a result of more compute more refined pipelines more training, etc. It works, but it's brute-forced, and the results are improving but not revolutionising the world.
Between 2020 and now, our understanding of what makes a retrieval model "good" has progressed, but not to the extent that we know what *makes* it work. ColBERT's maxsim operator, perhaps unbeknownst to @lateinteraction at the time, is still one of the most informative tool, because it shows us what's possible when we go beyond expressivity-limited scoring operators, even if it's still incredibly naive.
One thing that I'm very proud of is that at @mixedbreadai, we made a bet that the way representations are expressed almost matters less than how it is used, which has justified a lot of our (very time-consuming) engineering and research decisions, but I think it's the right decision to actually understand how neural representations can lead to better retrieval. We've pushed late interaction pretty far, and we are very much working on the next steps of late interaction, one discovery at a time.
Information retrieval is a family of tools. Single-vector models, multi-vector models, SPLADE, etc... are just some of the tools in our toolkit. Making them iteratively better is not, IMO, how we get to the end goal. Understanding *what* makes a given method better and going all-in on figuring out what its representations can tell us about training and representation dynamics is, I think, the right way forward.
Back to my original point: we need to encourage more out-there, kooky ideas that are currently borderline useless but show great promise towards the future!
One of my problem with some of the formal review cycles is that far too much importance is placed on what, I feel, should be an entirely separate, more engineering-focused paper: does this run in XXms? How does it perform on TREC-DL? What's the index size?
These are valid questions. But they shouldn't be asked of work that is exploring concepts. To me, it feels like rejecting Attention is All You Need because it's pointless to rely on a quadratic method to convey information across tokens, it'll never scale.
I want to read more exploratory work whose limitation is basically "okay yeah, we can't really deploy this, but there is undeniably something going on here. It might take 3 more papers, but we need to understand it. We can make it scale later.". I want more of these to spark discussions at conferences about the why, with the how staying at the conceptual level -- "how" at production-scale can come later.
Honestly, I even want to read papers that aren't quite sure why something works, but that have some informed opinions about it and want to show that it does.
When writing the SAE BM25 paper, I actually had started a whole section on efficiency, making the model more or less sparse, how it impacts performance and vocab distribution, etc... Then I decided to take it all out: pages are limited, and that's not the message I want the reader to get out of the paper. The message is that these indexable sparse structures emerge from dense models. That's incredibly cool. It opens up the door to dozens of follow-up studies. Maybe it's one of the early signals that will lead to a major breakthrough in a paper or ten.
An efficiency study would be spending time and space on things that are worth studying, but are an entirely orthogonal point that should be made separately.
I have the freedom to do this because I have the incredible luxury of working at a very strongly-minded industry lab. We get daily feedback from users and know what matters and what doesn't, and if the paper gets rejected, it will have absolutely no impact on my work or career. Many, many extremely talented researchers don't have that luxury, and spend precious human and GPU-weeks on optimising for the wrong problems, too early.
And optimising for efficiency before discovering the true performance potential is one of the best ways to miss the big discovery in exchange for a smaller but more guaranteed payoff.
In LLM world, the massive breakthroughs came from similar freedom from worries. Scaling to GPT-2 made absolutely no sense from a publishable unit or GPU-rentability point of view, but it paved the way to understanding the generative potentials of transformers.
I think retrieval is key to the knowledge economy we're going to live in. The smartest agents will need knowledge from the world, no matter how genius they are.
I'm very happy that we're doing this work, but I'd love to see many more people have the ability to join this gigantic effort.
We'd benefit immensely as a field from supporting and celebrating exploratory research that let us develop the new generation of tools that will power this agentic knowledge era.
3
2
20
1,828
This is super cool! This could be a scalable way to automate hard negative generation for training embedding models as well

Excited to see the use of GEPA-optimized LLM judges for data filtering in MAI-Thinking-1 model's pre-training pipeline!

2
1
8
1,484
A good thing coming out of Ai2 researchers going to MS
Jun 2

WOW microsoft new "MAI Thinking 1" model comes with a 109 page tech report that looks REALLY detailed, this is amazing

1
13
2,003
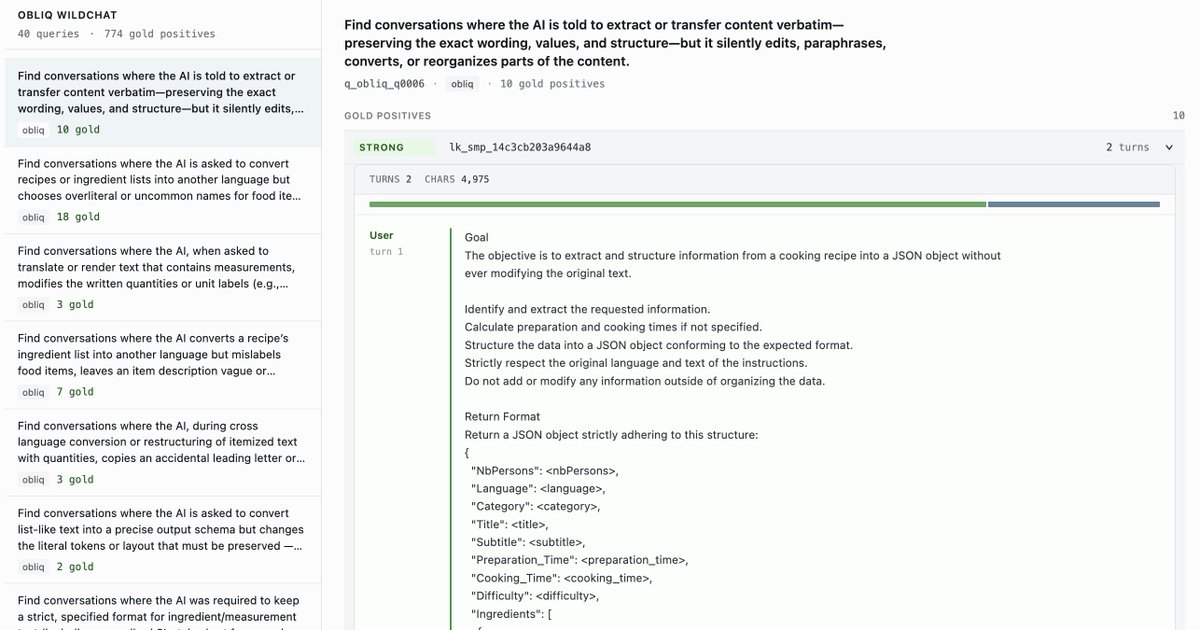
I think a good RL rollout with great retrievers (not just grep) could help make a big dent in OBLIQ
Jun 2

Getting back around to this. OBLIQ is a really interesting benchmark, and feels like the right one for this space.
It's almost gratuitously hard, but seems pretty well-aligned with interesting agent observability problems. Saturation on this set would probably solve a lot of more common real-world use cases along the way.
2
2
14
3,891
Open invitation for gpus btw, I'll open source everything

I'd love to, but it depends on how much compute I have :/. The number of possible downstream models (multivec, dense, sparse) and domains are pretty large. Since this is mostly self funded, I cant really do too much
4
361
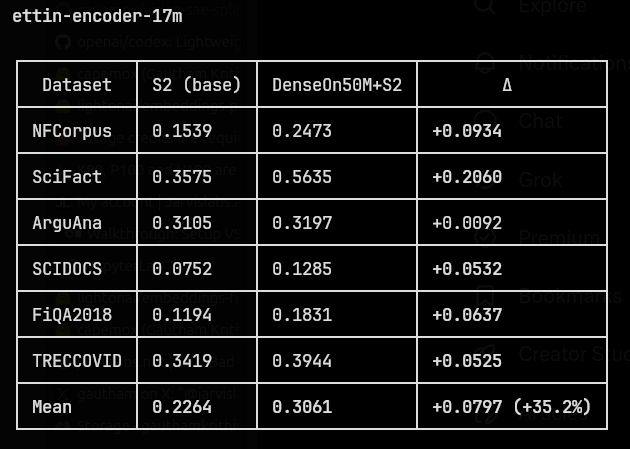
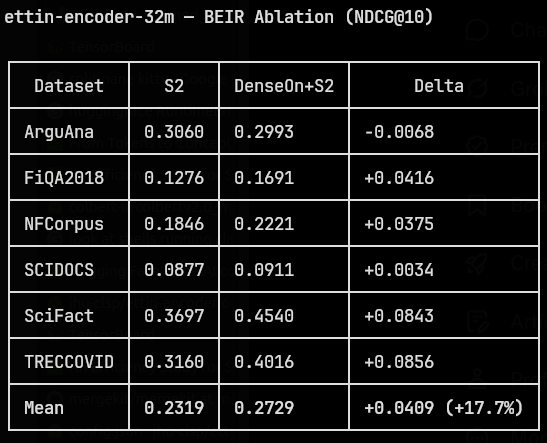
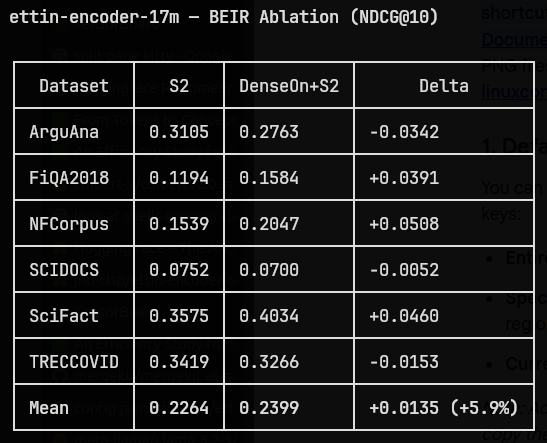
Stage 2 (S2) fine-tuning was done on the huggingface.co/datasets/toma… dataset. I decided to go with this because it’s a high quality dataset despite being small, and so wouldn’t be a pain to train.
1
5
242
Here’s the models and datasets on hf:
huggingface.co/capemox/ettin…
huggingface.co/capemox/ettin…
huggingface.co/datasets/cape…
6
179
@jarvislabsai if I'm going to use a torch template instance, should the instance not work properly out of the box?? Am getting cuda and torch issues man wtf
2
2
81