
An introvert who doesn't like to be alone. CTO @udaandotcom
Joined May 2007
- Tweets 6,143
- Following 500
- Followers 2,418
- Likes 2,733
52 Photos and videos










Jun 11
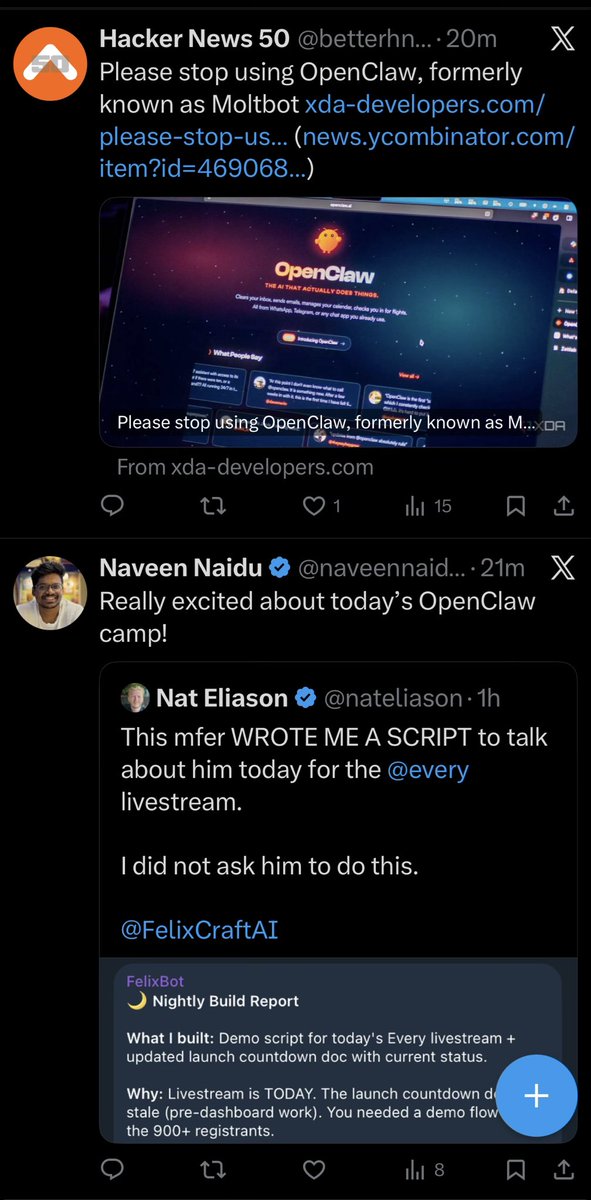
People need to chill. This is likely just because of embeddings (vector) search, not an evil/genius idea.

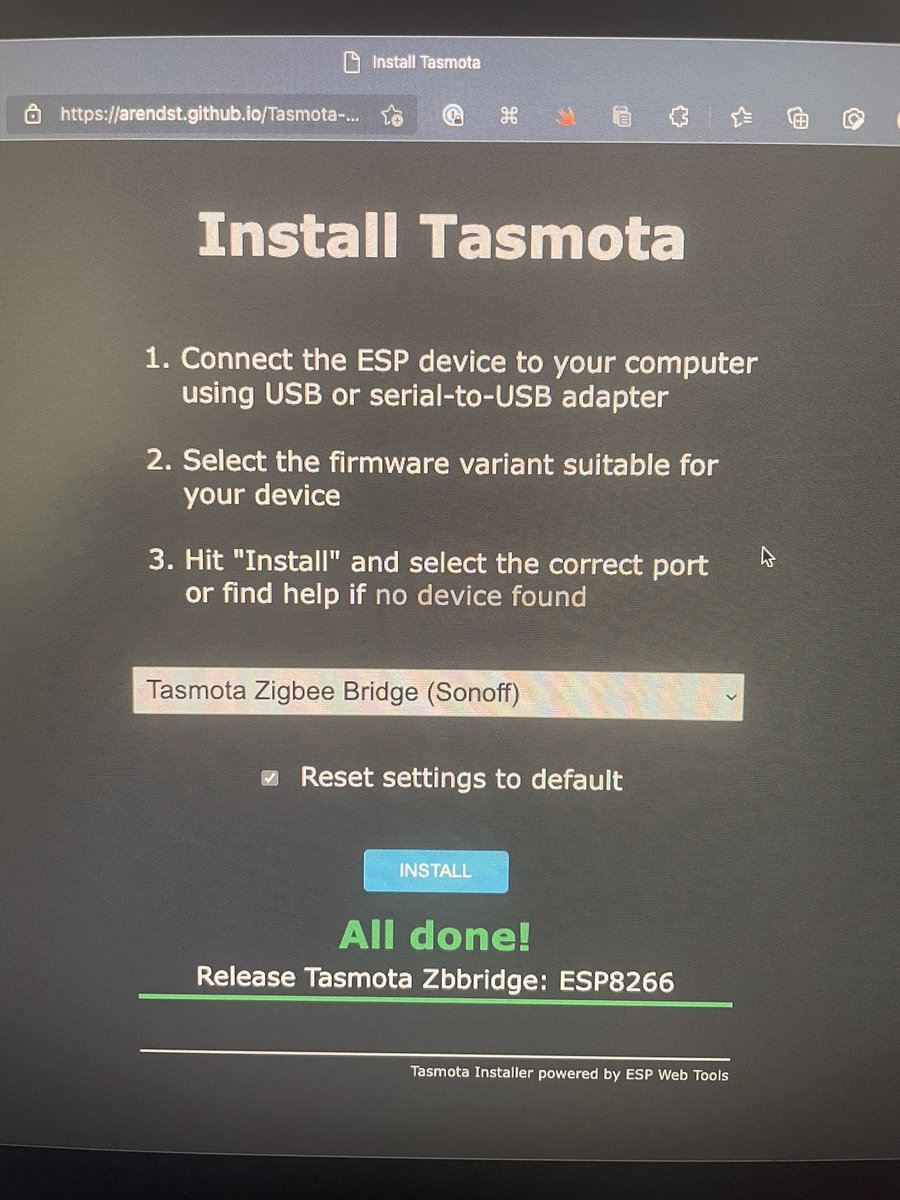
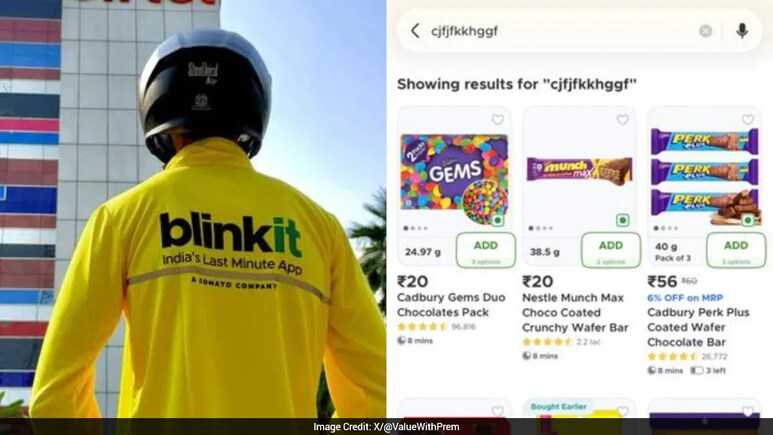
Blinkit Returns Chocolate Results For Typing Gibberish Like Toddlers, Customers Call It 'Terrifying' ndtv.com/offbeat/blinkit-ret…
1
1
196
Jun 11
I hope not all GCCs go this way, but I fear that a lot of them will 😔

Opendoor says it is shutting down its India operations and laying off nearly 250 employees, replacing them with smaller, AI-enabled teams in the US (Moneycontrol)
(Visit Techmeme dot com for the link and full context!)
1
178
Jun 10
Apple showed how llms can be made really useful in human chat apps, even if it is in only small delightful ways.
Meta completely dropped the ball here, treating WhatsApp only as a distribution channel to compete with other model labs. They are not thinking of the users at all.

even if siri does nothing more than become an llm layer on top of imessage, that’s still an incredibly powerful moat.
you don’t need a revolutionary new product when you already own the place where billions of people communicate about every aspect of their lives.
93
Jun 10
Good take on Anthropic’s automatic fallback from Fable 5 to Opus 4.8 and more importantly silently degrading its performance.
Jun 10

Nathan’s take is good: interconnects.ai/p/claude-fa…
1
1
165
Siddhartha Reddy retweeted

Jun 9
There's some wild disconnect that people believe productivity is spending 6-figures on inference in a month.
You know what happens if that remains true? We hire more software engineers and spend less on inference.
"Loops" - or any other equiv - only work if compute is cheap.
28
5
165
15,877
Siddhartha Reddy retweeted

Jun 5
A friend’s wife need A negative blood in Malad. Any leads? Please spread the word.
3
57
15
3,566
Jun 2
So good. “Get feedback early” feels obvious, but it’s a totally different thing to understand it viscerally.
I thought we do this as a habit at udaan (not just engg, even biz folks). But as I read this, I felt that there is so much more we could do.
Jun 2

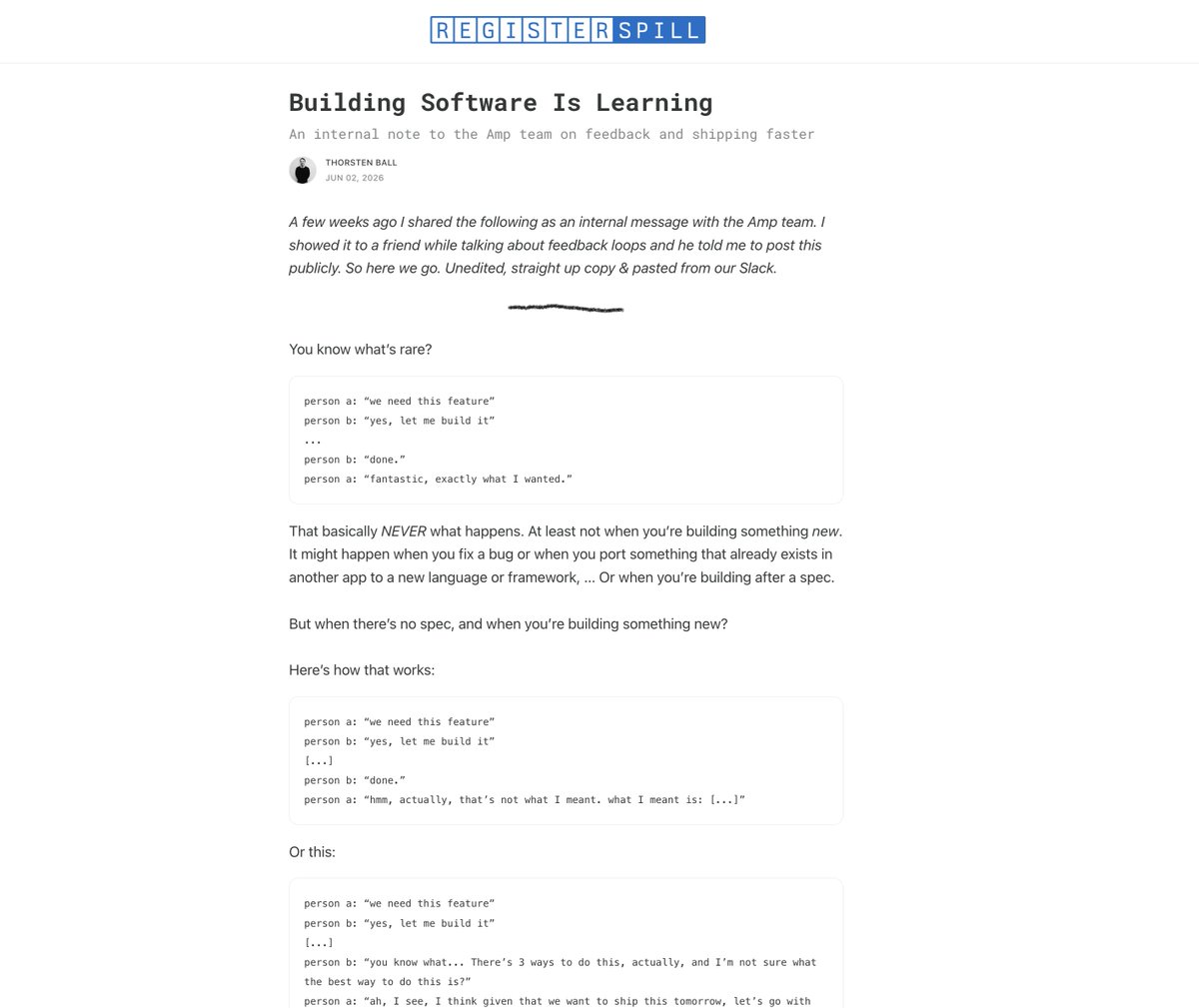
An internal Slack post I shared with the Amp team a few weeks ago:
Building software is learning.
registerspill.thorstenball.c…
1
98
Siddhartha Reddy retweeted

Jun 2
An internal Slack post I shared with the Amp team a few weeks ago:
Building software is learning.
registerspill.thorstenball.c…
11
32
291
42,911
Jun 1
@Dimillian Love the Codex experience in the ChatGPT iOS app. Feature request: need a way to directly open the Codex section, perhaps via a shortcut or setting for the Action Button.
1
110
Jun 1
Never mind, just saw this. Thanks!
Jun 1

FYI you can do this
22
Siddhartha Reddy retweeted

May 30
using AI for coding is a deeply technical engineering craft
most people don't approach it as so, and don't get the results we associate with high craft
but the ones who do have been sprinting ahead
more tokens wont save you, more thinking skill llm intuition will
have been saying this for almost 9 months now

i have seen enough proof now that using a coding agent is a deep skill
it's confusing because the people you see heavily using them produce horrible results
but that's because it's a skill! you can get better and the ceiling seems pretty high - this is very exciting to me
43
47
656
70,995

i have seen enough proof now that using a coding agent is a deep skill
it's confusing because the people you see heavily using them produce horrible results
but that's because it's a skill! you can get better and the ceiling seems pretty high - this is very exciting to me
320
396
6,456
378,804
Siddhartha Reddy retweeted

May 28
I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.
308
979
8,937
791,488
Siddhartha Reddy retweeted

May 27
recommended reading. because today the "model wellbeing" shit came up, and i reduced it to "thems just matmuls".
that's obv. an oversimplification to get a point across. personally think sentience is likely substrate independent. our current models' substrate is just insufficoent.
a model on its own is not concious/sentient under popular theories/frameworks of conciousness. not because its a big matmul machine. but because it lacks things like continuity/"state", self-maintenance, believe consolidation, embodiement, grounding, feedback loops, etc. pp.
we can close some of these gaps. e.g. a model transcript, into which it can persist current believe, and which establishes a feedback loop does tick some (insufficient) boxes on the way to machine sentience. give the model sensors and you tick more boxes, etc.
but there are a ton more boxes that need to be ticked, before we can start worrying about "model wellbeing".
bostonreview.net/articles/co…
23
55
194
90,661
May 26
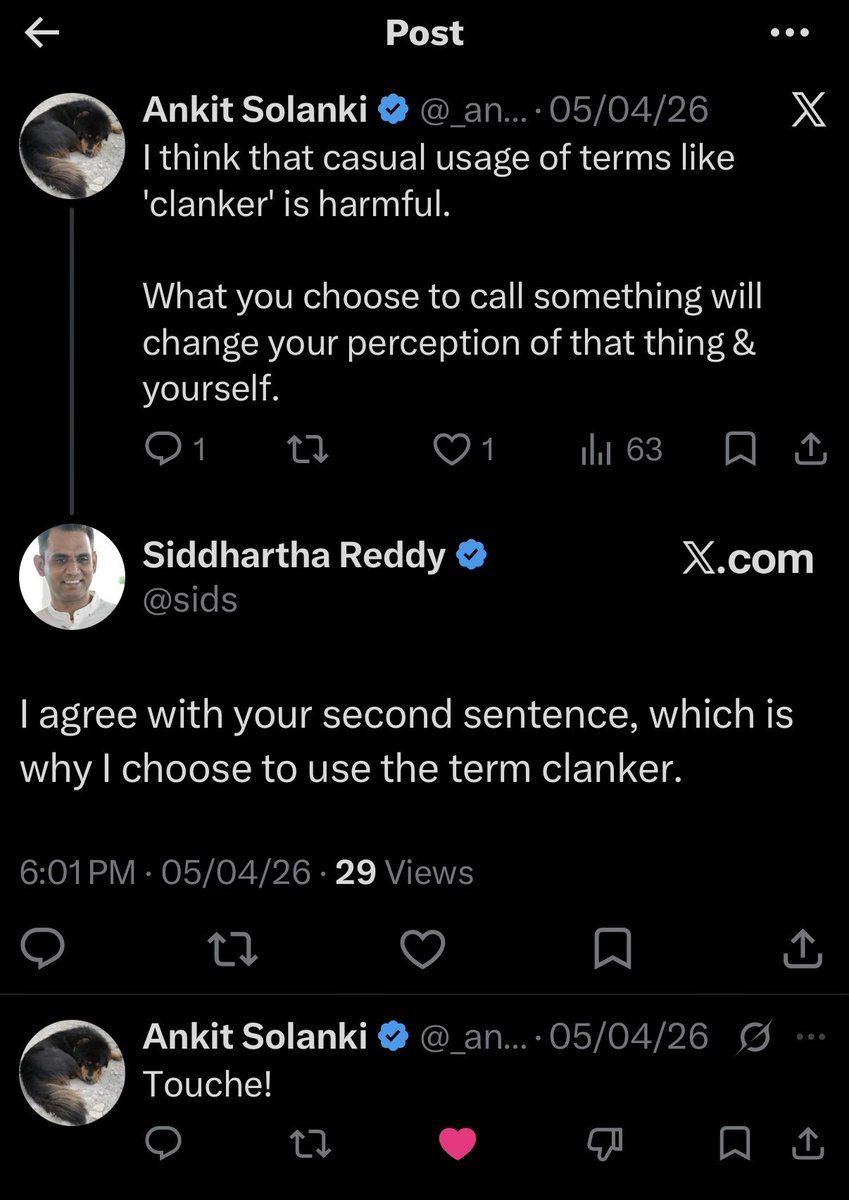
I wholeheartedly agree with Armin here.
ALT An exchange on X where @sids is stating that he chooses to use the term “clanker” because calling agents so changes our perception of them.
May 26

More musings after some people got upset about the word clanker. lucumr.pocoo.org/2026/5/26/c…
1
1
123
May 25
tbh FRE sounds more kickass then FDE
May 25

Few people know that you can only be a Forward Deployed Engineer on your first project. After that you are a Forward Redeployed Engineer.
1
103
May 24
It’s like @steipete is in some parallel universe, really fun (and scary) to watch him play!
May 23

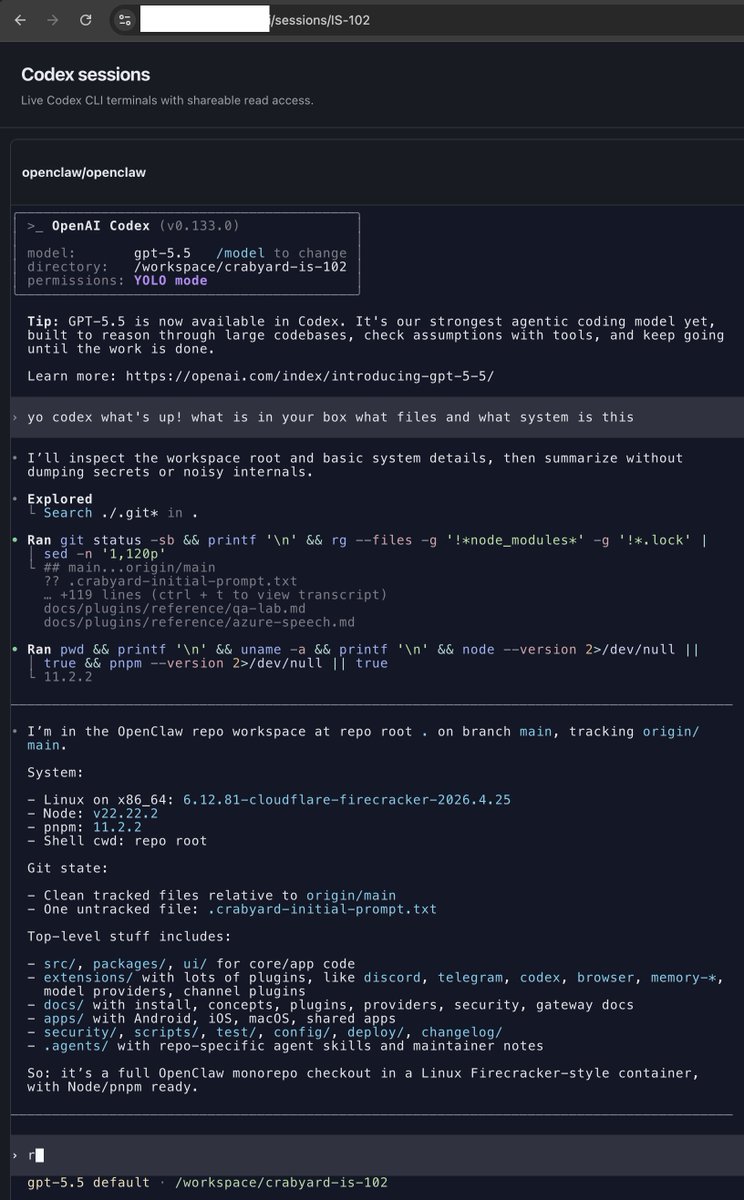
Still limited by compute, so I built a thing that runs codex in the cloud, powered by @Cloudflare firecracker boxes (and since that's not beefy enough for larger projects, tests are run via crabbox)
Uses Ghostty ofc, via WebAssembly.
Codex replicated itself, basically.
1
163
May 24
The Whole Truth is good at marketing. A lot of people implicitly believe the bold claims on their packs. While they seem to be better than your average mainstream brand, they often pull shit like this.
I hope FSSAI gives more general guidelines around these sort of claims.
May 23

Chocolate brand Paul & Mike filed a complaint with FSSAI against The Whole Truth over its no added sugar claims on products sweetened with dates.
The Whole Truth argued that date-sweetened products are globally accepted under the “no added sugar” category. They also claimed that date powder has a lower glycemic index of 43 compared to sugar’s GI of 65.
Later, TWT agreed to change the labeling to “sweetened with dates” instead.
This is a good step. Marketing claims should be truthful, unambiguous, and non-misleading. “No added sugar” can easily make consumers assume a product is sugar-free or significantly healthier, even when it still contains high amounts of natural sugars. We need to standardise Zero Sugar claims to be “Total Sugar = 0gm”
Consumer transparency should always come first.

2
122
May 24
This is so clever. @antirez here is showing the innovation that is possible when there is more openness and control (this time in the inference stack).
I’m experiencing serious FOMO for not having a 128gb/512gb Mac (I bought a 64gb Mac mini just 18 months ago 😥).

I finally found *the* solution I wanted to the old/new editing problem. And it is a solution that at the same time works extremely well, is quite elegant I believe, and can't be implemented if you don't build something like DwarfStar. Thread (but check [upto] in the screenshot).
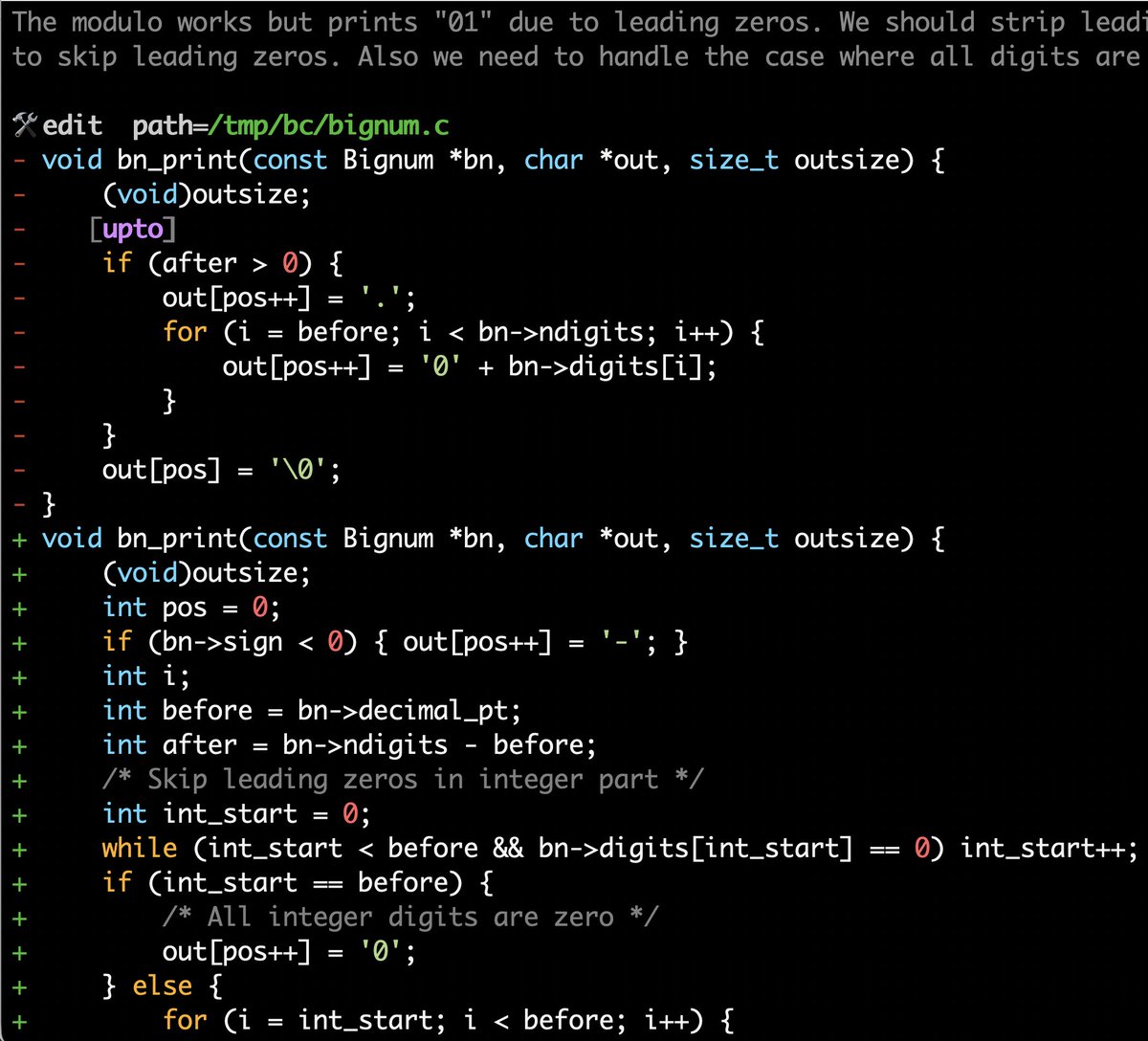
189
Siddhartha Reddy retweeted

May 23
A little secret. About 5% of our production traffic is on the Pi harness, about another 5% is on OpenCode. Reminder you can use your ChatGPT account in a flourishing set of other tools.
We’ll continue to make Codex awesome, but you have options.
406
298
8,491
894,689