
Joined May 2013
- Tweets 18,589
- Following 4,859
- Followers 6,996
- Likes 218,523
3,738 Photos and videos












Jun 12
seems like everyone is talking about peptides now. ive been talking about peps since 2016.
store.worldpeptideassociatio…
1
2
59
Jun 3
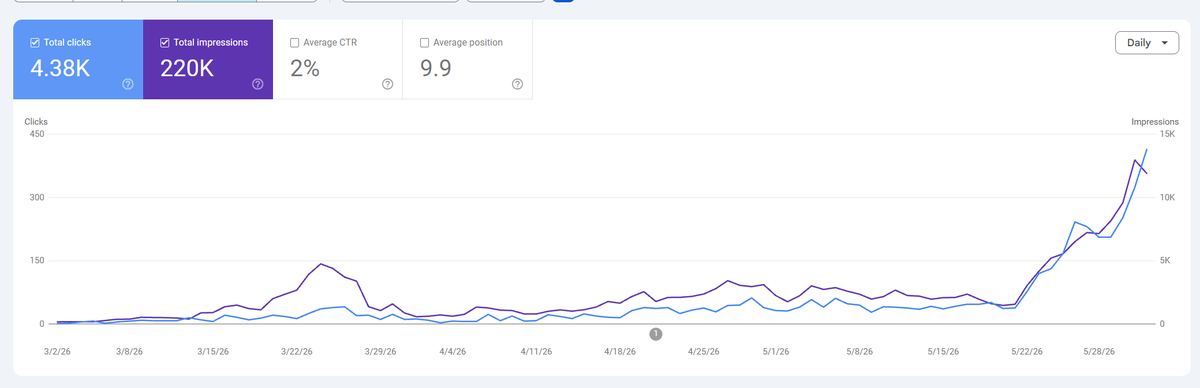
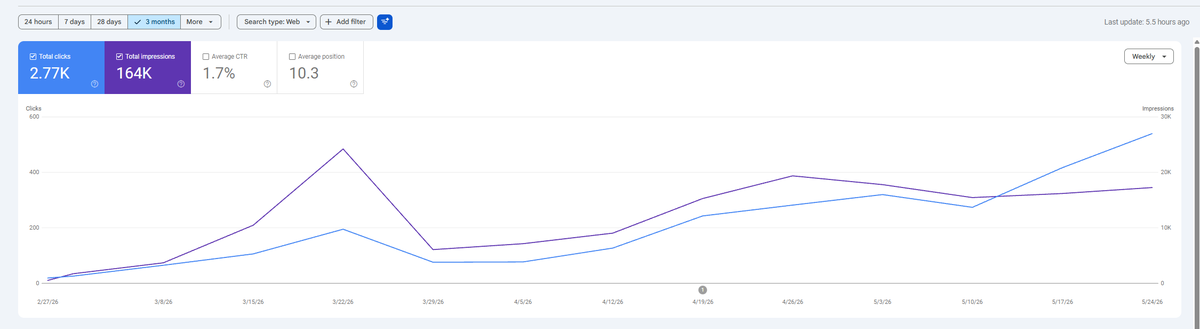
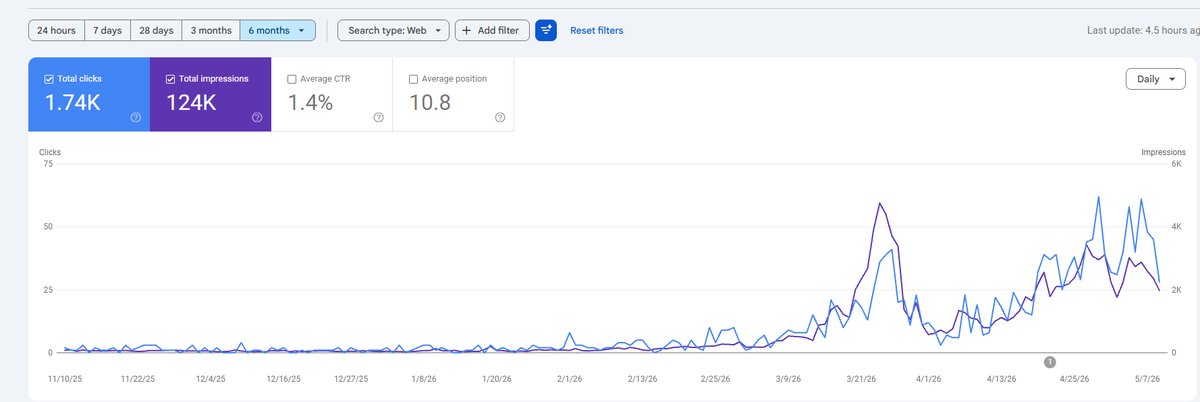
made some more progress 30 clicks from google in dec over 2800 in may. tracking for a 2-3x that for june.
1
47
Sam Stolt retweeted

Jun 1
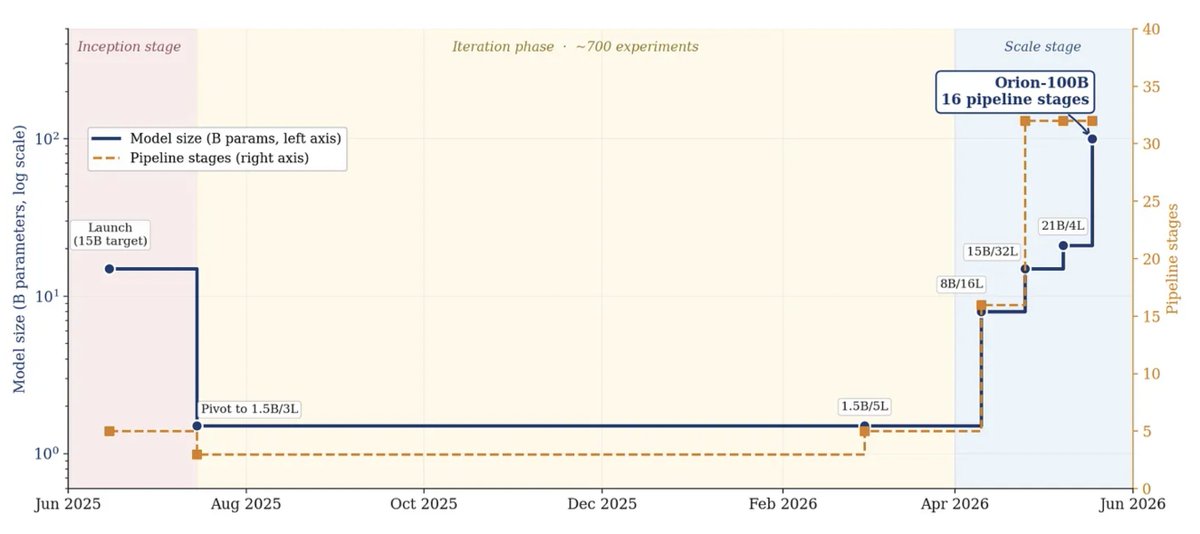
Today, we are launching the first stage of Project Orion.
Our early pre-training run of Orion-100B achieves upward of 65% of data-center training efficiency on hardware costing a fraction of the price.
Orion-100B is the first proof point for a simple idea: that underutilized compute around the world can be turned into frontier training capacity.
We believe that this work presents, for the first time, an economically compelling case for training large models using distributed approaches.
24
79
419
636,489
May 28
i want this to go up even faster haha. ive made massive seo progress on this site from 30 clicks in dec 2025 to nearly 2k for may. and i believe we should be able to double clicks for the month of june to over 4k.
1
42
Sam Stolt retweeted

May 27
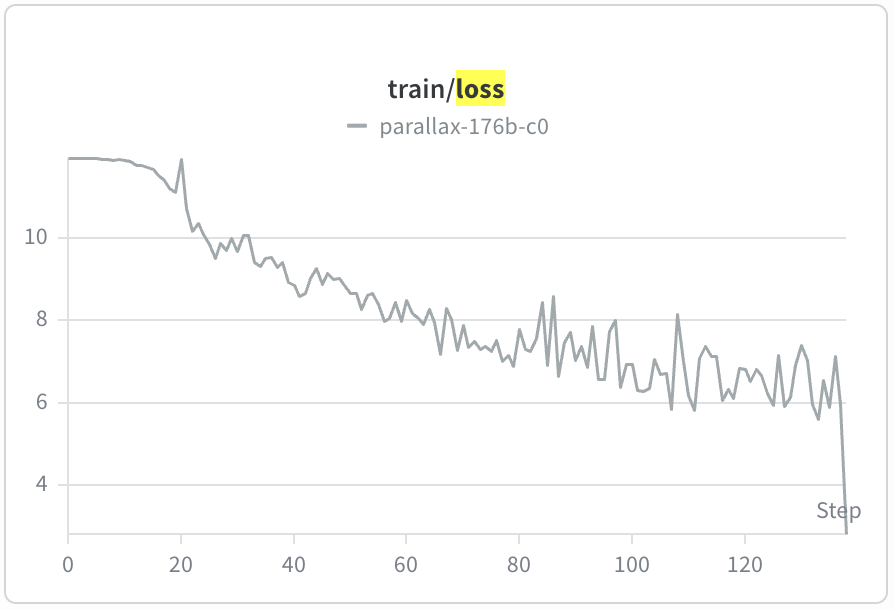
Just for fun I kicked off a run of a 176b parameter model on ~140 steps to prove feasibility - 4 separate nodes across the internet using the "Parallax" method, works like a charm.
Still need a more concrete plan on dataset curation, phases, context elongation, etc. etc. before a full run is ready of this scale, but at least we know 176b should be no problem at all.
May 11

You can force an architecture into decentralized training, or you can craft an architecture specifically for decentralized training (and ultimately insanely performant inference). Stop trying to fight gravity.
"Parallax", so far, is working exceptionally well.
Surrogates, expert offload, stratified decoupled diloco, etc. All pretty great to make training work at scale across the internet. But... The biggest benefits are actually AFTER training, via specific model architecture choices that drastically reduce VRAM and increase throughput.
These giant MoEs are wasting so much VRAM and compute for all of the many routed experts, it's insane actually. So much research already showing that MoEs can be massively compressed/pruned/ternary-distilled/etc., not to mention they are generally comparable to around 2.5-3x dense model equivalents of the ACTIVE parameter count. KV cache is a huge bottleneck, and these huge routed experts are often "dead weight" that consume it needlessly.
We need to do better, so we will.
21
50
275
90,604
May 24
1/250th the cost.. still has a long way to go in terms of ability/features/reliability. But thats amazing!
May 22

This is in Alpha only. But a $TAO -powered ChatGPT-like interface. Bluetao.ai . Only using bittensor subnets (like @chutes_ai ) for text and image inference. (cc @const_reborn , @BarrySilbert ). Any suggestions or bugs welcome. Will be 1/250th the price of chatgpt.
1
1
2,795
Sam Stolt retweeted

May 24
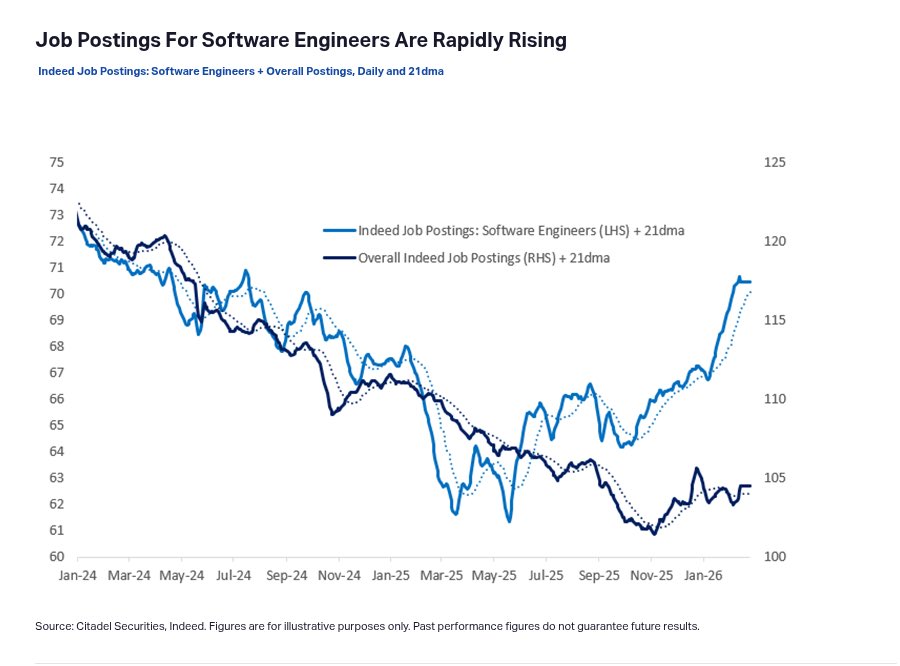
Q: How are job postings for software engineers rising rapidly despite AI agents automating coding?
A: Because there’s far more code to manage than ever before. We’re already seeing a 14x YoY increase in GitHub commits, and it’s accelerating.
AI has dramatically lowered the cost of writing code, so it’s now being used across far more businesses, applications, and use cases.
We’re at the beginning of a massive productivity boom driven by the proliferation of bespoke software throughout the entire economy.
Coding has been AI’s breakout use case this year. The fact that it’s increased demand for software engineers — rather than decreased it — should call into question the entire “AI will cause mass job loss” narrative.
827
1,466
9,116
1,630,858
May 18
Started buying bittensor in early 2023, on that sketchy exchange. I think that they were moving to the finney network or had just moved to the finney network
69
Sam Stolt retweeted

May 16
An incredible summary of everything that happened last week in the Bittensor ecosystem.

1
25
140
8,045
Sam Stolt retweeted

May 11
Launching Cacheon: an open, incentivized competition for LLM inference optimization.
As model quality converges, the next frontier is serving them economically at scale: lower latency, higher throughput, and lower cost per token.
Cacheon turns that problem into a live arena with continuous evaluation. Developers submit containerized inference servers, benchmarked on standardized hardware against a pinned vLLM baseline. The fastest server that preserves output correctness wins.
The goal is to make better inference systems discoverable, measurable, deployable, and rewarded in the open.
Mainnet launches by May 19. Learn more: cacheon.ai

47
39
183
42,550
Sam Stolt retweeted

Apr 30
145
462
2,814
2,171,479
May 11
Semaglutide vs Tirzepatide vs Retatrutide cost per month — plain-English 2026 guide from World Peptide Association worldpeptideassociation.com/…
1
132
Sam Stolt retweeted

May 7
Inference got a hundred times cheaper this year. The compute bill went up anyway.
If you understand why those two sentences are both true at the same time, you understand the most important thing happening in AI right now.
I work on inference for a living, at @nebiustf, where we run open-source managed inference at scale. Most of what follows is what I'm seeing from inside the bill.
12 months ago, the cost of 1M tokens of frontier-class reasoning was somewhere on the order of $60.
Today, an equivalent quality of output costs roughly $0.50.
Price /token of o1-level intelligence has dropped about a 128x in a year.
Price of GPT-4-level output has dropped roughly 100x since the original GPT-4 shipped.
By any normal reading of a technology cost curve, this should be deflationary. It should be saving customers money.
The opposite has happened. The total compute bill at every hyperscaler is going up, not down. Anthropic just signed multi-year capacity deals with both XAI and Amazon. Microsoft's Azure capex guide for 2026 starts with an eight. OpenAI is reportedly spending more on compute every quarter than it did in all of 2023. Nvidia paid roughly twenty billion dollars to acquire Groq, an inference-specialist company that did not exist as a serious commercial entity three years ago.
The cost curve and the demand curve crossed, and then the demand curve lapped the cost curve.
Here is what happened underneath.
A reasoning model burns roughly 10x the output tokens of a non-reasoning model on the same task, because it spends most of its tokens thinking out loud before answering. An agentic workflow chains roughly twenty times the requests of a single-shot completion, because it loops, calls tools, plans, retries, and synthesizes. A modern deep-research query (the kind a research analyst can fire off in fifteen seconds and then walk away from for ten minutes) costs more compute than 10 original GPT-4 queries combined. We made every individual token a hundred times cheaper, and then we built a generation of products that consume ten thousand times more tokens.
This is the Jevons paradox playing out at trillion-dollar scale, in compressed time, in front of everyone. Jevons noticed in 1865 that making coal-burning more efficient did not reduce coal consumption. It increased it, because efficiency unlocked uses that were previously uneconomic. Steam engines became more practical at smaller scales. Whole industries that could not afford coal at the old price suddenly could. Britain's coal consumption rose sharply, not despite the efficiency gains, but because of them.
The same thing is happening to AI compute right now and it is happening faster than any analogous historical cycle. Falling token prices did not contract demand. They unlocked agents, deep research, code-writing systems, multi-step reasoning, persistent memory, the entire next layer of AI products. Every product in that next layer consumes orders of magnitude more compute than the chat interfaces it is replacing.
The math at the aggregate level is brutal: 100x cheaper tokens times 10 000 more tokens equals a 100x larger total bill.
The implications stack quickly.
If you are running a hyperscaler, your 2026 capex guide is not a peak. It is a step on a curve. Inference is structurally always-on, twenty-four hours a day, in a way that training never was. Training is bursty. You spin up a cluster, run for weeks or months, and stop. Inference runs continuously, scales with usage, and the usage curve is exponential. Your power bill, your cooling bill, your transceiver count, your storage footprint, all of these were sized for a workload mix that no longer exists.
If you are running an AI software company built on top of someone else's closed API, you have a problem that did not exist a year ago. Your gross margins get worse as your customers get more value out of your product, because the more they use it, the more compute you pay for. The companies that win this are the ones that figured out vertical integration before the math caught them.
If you are watching this from a distance and trying to understand where the next bottlenecks form, the answer is everywhere downstream of "more inference compute, always-on, with massive memory state per session." The KV cache, the running memory state of a long conversation or an agent loop, is the silent monster of the inference era. It does not scale linearly with parameters. It scales linearly with context length and number of agent steps. A long agent session can hold tens of gigabytes of state per user, per session.
Multiply that by every concurrent user of every product, and you understand why $MU, $SNDK, $TOWCF, and the entire memory and packaging layer have re-rated the way they have.
The CPU-to-GPU ratio is evolving. Training is 1:8. Basic chat inference is 1:4. Agentic inference is 1:1, sometimes CPU-heavy. Google has split its TPU line in two, with a dedicated inference chip carrying tripled SRAM for KV cache. $INTC and $AMD just spent two earnings calls explaining that this shift is structural, not cyclical. The hardware map is redrawing in real time and the financial press is mostly still writing about training clusters.
The right framing of where we are right now is not that AI is hitting a wall. The framing a year ago that scaling was hitting a wall was the most expensive bad take of the cycle. The right framing is that AI got dramatically cheaper, dramatically more capable, and dramatically more useful, and the cost of running it at the new equilibrium of demand is much higher than the cost at the old equilibrium of demand, because the new equilibrium is enormous.
A meaningful share of what we actually do at Token Factory, day to day, is help customers stop their bills from running away from them. KV-cache management. Speculative decoding. Quantization. Routing. The kind of vertical integration that, eighteen months ago, every product team was happy to leave abstracted away behind a closed API. The reason this stack matters now is the same reason this whole essay matters: at the new equilibrium of inference demand, the cost of treating compute as a commodity is no longer survivable. The companies that figure out the layer beneath the API are the ones who keep their margins.
Cheaper tokens. More tokens.
Same coal as 1865.
138
419
2,669
681,542
Apr 25
When I voice how shitty Google 's Nest thermostats are they respond with this and I'm like oh they might actually care. And then I DM them and reply to their post and they just never say anything. It just reaffirms how shitty the product is
Apr 4

Hi, Sam. We're sorry to hear that your Nest Thermostat is constantly disconnecting from Wi-Fi. To look into this further, please reply with the specific model of your Nest Thermostat. x.com/messages/compose?recip…
181
Sam Stolt retweeted

Apr 24
In my view, Bittensor’s architecture is a masterpiece of decentralized engineering, but let’s be honest: architecture is just the stadium; it isn’t the game.
Right now, we are in the era of potential. But potential doesn't disrupt industries, performance does. For Bittensor to cross the chasm from a visionary experiment to a global powerhouse, it needs to move beyond the internal feedback loop.
We don't just need subnets that work. We need subnets that win.
Let me explain: 👇
The industry is currently dominated by closed-source giants like OpenAI and Google DeepMind. To challenge them, the TAO ecosystem must produce subnets that:
▫️Surpass the Open-Source Ceiling: Move beyond standard fine-tuning and start setting the benchmarks that the rest of the world follows.
▫️Compete on Compute and Logic: Leverage the decentralized incentive layer to train models that aren't just good for being decentralized, but are objectively superior in reasoning, coding, and creativity.
▫️Shift from Interesting to Inevitable: The moment a subnet delivers a State-of-the-Art model that outperforms a GPT or a Gemini in a specific, high-value domain, the narrative shifts forever.
My Active Search for SOTA Competition:
Because of this, I am shifting my full focus toward identifying and supporting the specific subnets that are explicitly building to compete with SOTA. I am looking for the teams with the raw ambition to move the needle on the frontier of machine intelligence, those who aren't just satisfied with participating, but are obsessed with outperforming the world’s most advanced closed-source models.
I'm exploring the subnets that aren't just replicating what exists, but are actively engineering the next leap in SOTA. My goal is to find the architectures that turn decentralized compute into world-class intelligence.
Because, that's where the future is being built. That is where the capital goes.
97
87
1,146
135,398
Sam Stolt retweeted

Apr 24
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: huggingface.co/deepseek-ai/D…
🤗 Open Weights: huggingface.co/collections/d…
1/n

1,650
7,638
45,742
9,883,310
Sam Stolt retweeted

Apr 23
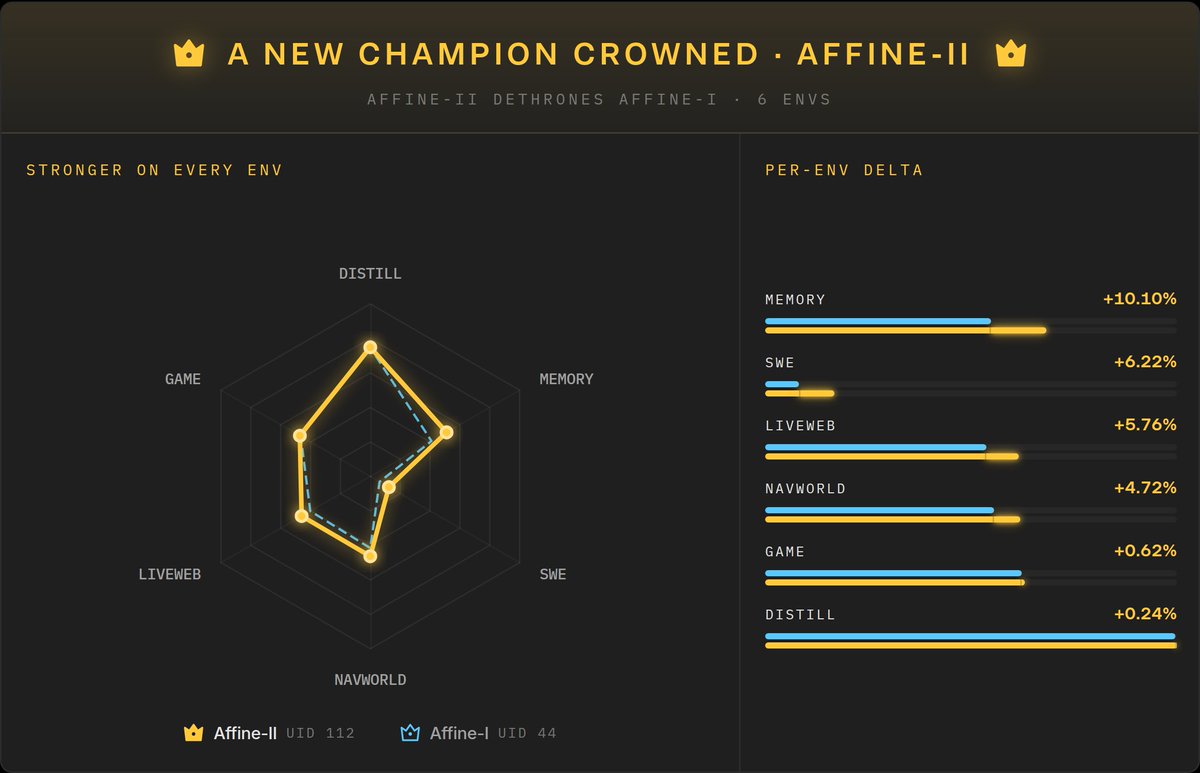
7 days in the arena where challengers rose and fell. Now a new Champion stands out with sweat and blood.
Affine-II took the crown from Affine-I, outperforming on all 6 live envs, significantly on:
• LIVEWEB 5.76%
• NAVWORLD 4.72%
• SWE 6.22%·
• MEMORY 10.1%
4
23
113
10,170