
Developing new single cell omics methods and bench validating all the hypotheses those techniques give us. Opinions expressed are my own.
Joined June 2018
- Tweets 2,598
- Following 682
- Followers 1,327
- Likes 5,133
197 Photos and videos










Pinned Tweet

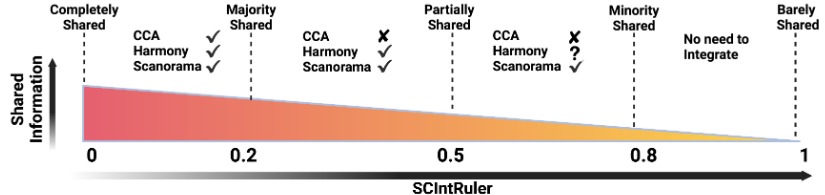
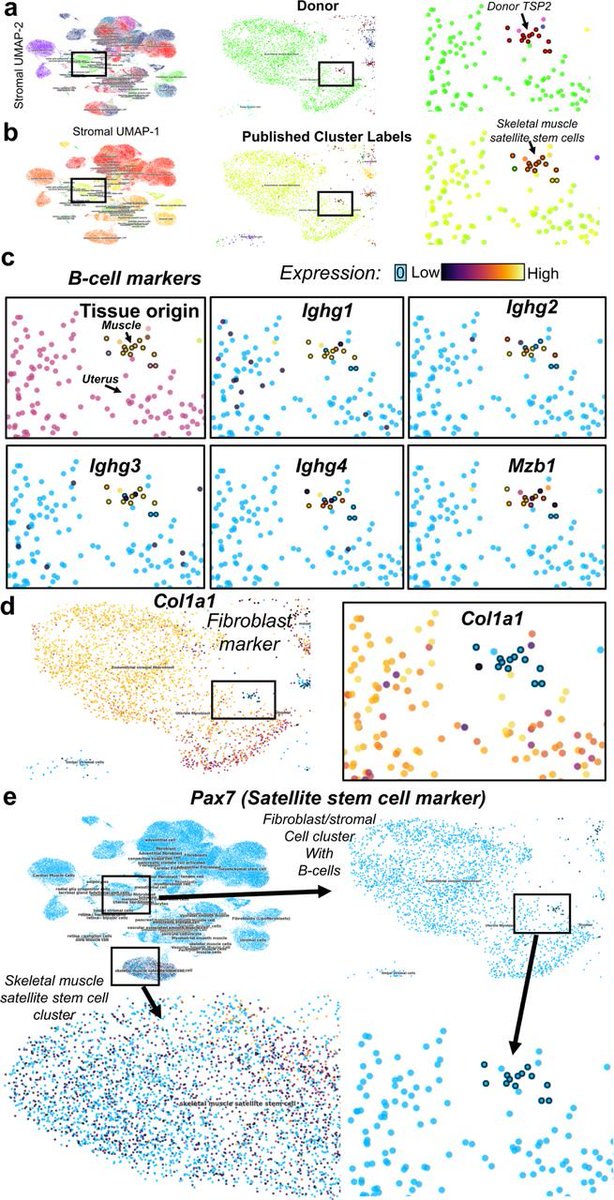
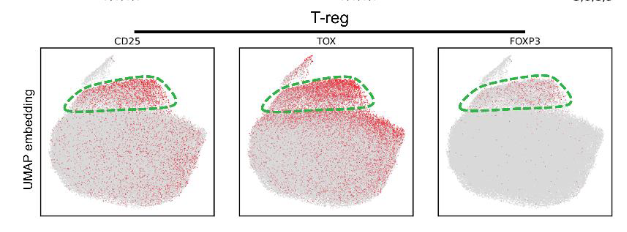
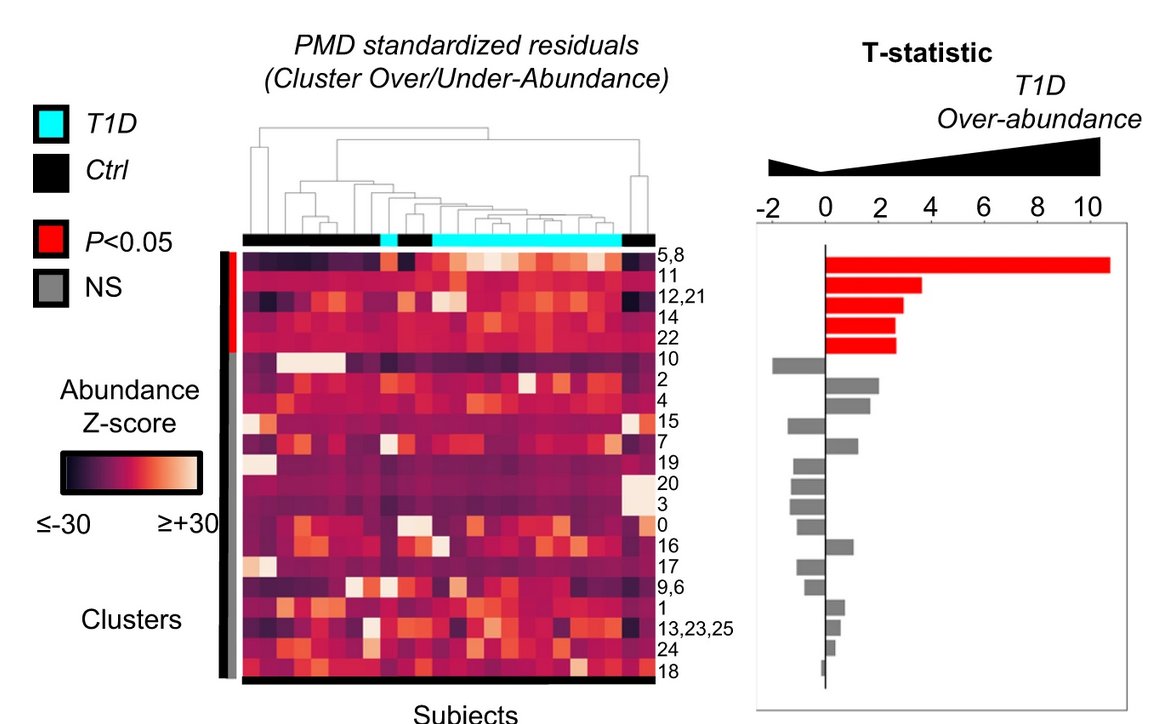
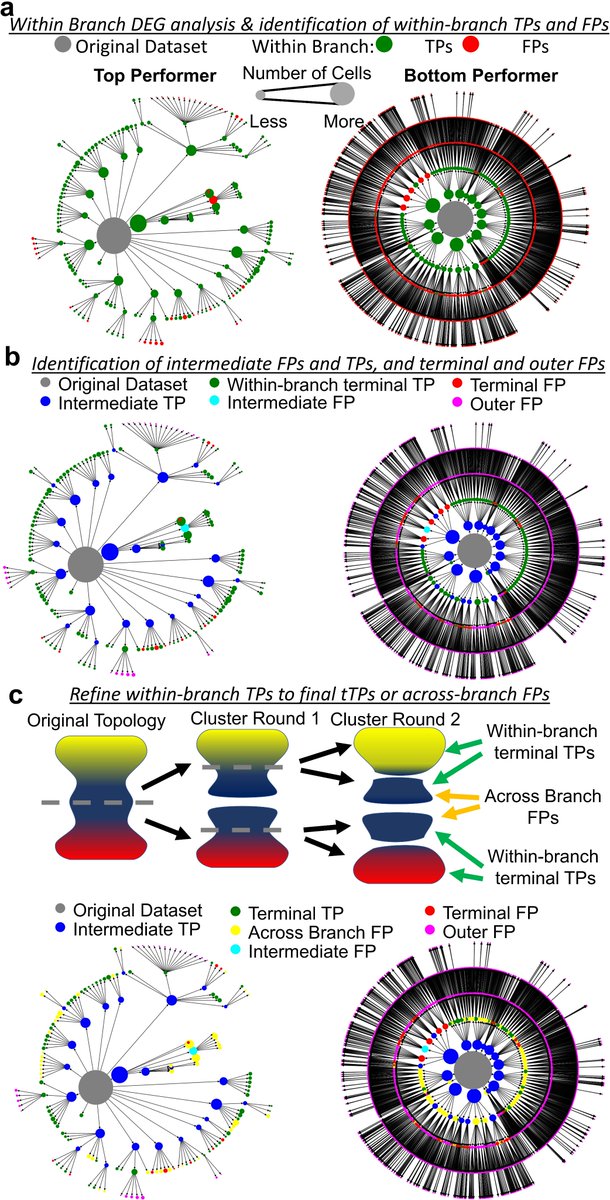
Working with multiple scRNAseq batches? Having trouble replicating at the bench? Our recent pre-print may show one reason why: (doi.org/10.1101/2021.11.15.4…) Findings complementary to @lpachter & Tara’s work finding low dim projections can be unreliable representations.
7
88
235
Scott Tyler (@ScienceScottT@genomic.social) retweeted

22 Feb 2025
Announcing the Elisabeth Bik Science Integrity Fund.
retractionwatch.com/2025/02/…
3
53
226
21,487
Scott Tyler (@ScienceScottT@genomic.social) retweeted

23 Feb 2025
The US mostly funds biomedical research through a large lump payment to the NIH. Panels of scientists and doctors volunteer to decide on the merit of grant individual applications, not unlike a really boring battle royale.
All of this is halted.
No new science is being funded.
29
57
369
32,945
Scott Tyler (@ScienceScottT@genomic.social) retweeted

22 Feb 2025
NIH has stopped considering new grant applications, delaying decisions about how to spend millions of dollars.
The freeze occurred because the Trump administration has blocked the NIH…
npr.org/sections/shots-healt…
86
155
450
229,401
Scott Tyler (@ScienceScottT@genomic.social) retweeted
2 Feb 2025
Some papers seem to be written by authors who did not really know what they wanted to say, and they did not figure it out in the writing process.
31 Jan 2025

I have been arguing that we need to go back to basics. The pressure for hypercomplex papers kills the very fabric of life sciences. Papers with a bazillion figures, graphs, tables, half cooked omics and so called deep mechanistic insights (that are seldom reproducible or even meaningful) are hurting real progress. Who can honestly vouch for individual figures any more? The academic publishing system in its current form has outlived its usefulness. The problem with the current crisis ? There are too many forces supporting the status quo…
1
1
7
2,166
Scott Tyler (@ScienceScottT@genomic.social) retweeted

22 Jan 2025
This by @SGRodriques laments the (anticipated) failure of models trained on large datasets to reproduce "real biology discoveries" like those found in Science and Nature. While he sees this as a problem, I COULD NOT DISAGREE MORE. That foundational models don't (and God help us won't) spit out Nature papers is a feature, not a bug!
21 Dec 2024

One of the remarkable things for me about NeurIPS this year was how quickly the entire AI for Biology community has gone all-in on biological foundation models. Virtual cell models will enable us to predict how cell states will change in response to chemical perturbations. Protein language models will enable us to identify better enzymes for degrading plastics, and so on. Everyone wants bigger data on more things to throw into bigger models.
These models are going to be awesome, but real biology discoveries look somewhat different. Contrast these dreams of foundation models with the latest table of contents from Science or Nature:
--“A long noncoding eRNA forms R-loops to shape emotional experience–induced behavioral adaptation” — The authors identified a lncRNA in mice that is expressed in response to neuronal activity that modulates the 3D structure of chromatin, thereby activating genes that are involved in neuronal plasticity. The authors further identified that this lncRNA is essential for certain forms of learning.
--“Cancer cells impair monocyte-mediated T cell stimulation to evade immunity” — The authors identified that mouse melanoma cells secrete a lipid metabolite that prevents monocytes from activating CD8 T cells.
--“Postsynaptic competition between calcineurin and PKA regulates mammalian sleep–wake cycles” — By generating mouse knockout lines, the authors identified phosphatases and kinases that are critical for regulating the sleep-wake cycle, and showed that they act through regulation of proteins at excitatory postsynaptic sites.
I struggle to imagine how any of these discoveries could fall out of a multimodal biology foundation model. This is not intended to be a straw man argument. Surely, a foundation model could potentially identify the lncRNA from the first paper, but I am not sure how such a foundation model would associate it with chromatin remodeling. A multimodal foundation model with enough data could also potentially identify metabolic changes associated with melanoma cells subjected to certain kinds of treatments, but I don’t see how that foundation model could identify the effect of those metabolites in preventing CD8 T cell activation. Indeed, I do not think that any of the foundation models that are being developed today would be capable of generating rich new biological insights of the kind described in these papers. And yet, these are the kinds of insights that new therapies are made from.
The issue, I think, is that machine learning models work extremely well on structured data, and so all the foundation models that are being built are highly structured. Take a protein sequence as input and produce a protein sequence as output. Take a cell state and a chemical perturbation as input and produce a new cell state as output. Biology, however, is poorly structured. The lncRNA insight is case in point: what structured representation can we use for the action of the lncRNA in modulating chromatin architecture? Protein models cannot represent it; DNA models cannot represent it; virtual cell models cannot represent it. Perhaps a model that incorporates RNA expression and 3D genome state could represent it, but then how would that model represent the lipid modulation of the monocytes? I worry that every discovery may need its own representation space. Indeed, the nature of biology is such that there likely is no representation, short of an atomic-resolution real-space model of the entire organism, that is sufficient to represent the diversity of biological phenomena that are relevant for disease.
Except, of course, for natural language, which is evolved to represent all concepts that humans are capable of contemplating. Indeed, I think natural language has an essential role to play in representing biology, and is ultimately unavoidable, insofar as it is the only medium we know of that is sufficiently structured for machine learning and sufficiently flexible to represent the full diversity of biological concepts. At FutureHouse, we work on language agents, which is one way of combining language and biology, but this is not the only way. Models that combine natural language with protein, DNA, transcriptomics, and so on will also be extremely productive, provided the addition of the structured datatypes does not restrict their ability to represent unstructured concepts. However we do it, I think this essential role of natural language in representing biology is currently largely underappreciated.
The history of biology is built on tools that we have found in nature to study biological phenomena. As all biologists know, trying to engineer things from scratch (almost) never works; what works is finding things in nature and repurposing them. It will be aesthetically pleasing if it turns out that our engineered representations are yet again insufficient for studying biology, and that natural language is simply another such tool that we have found in nature that must be applied instead.

6
27
183
57,051


Scott Tyler (@ScienceScottT@genomic.social) retweeted

16 Dec 2024
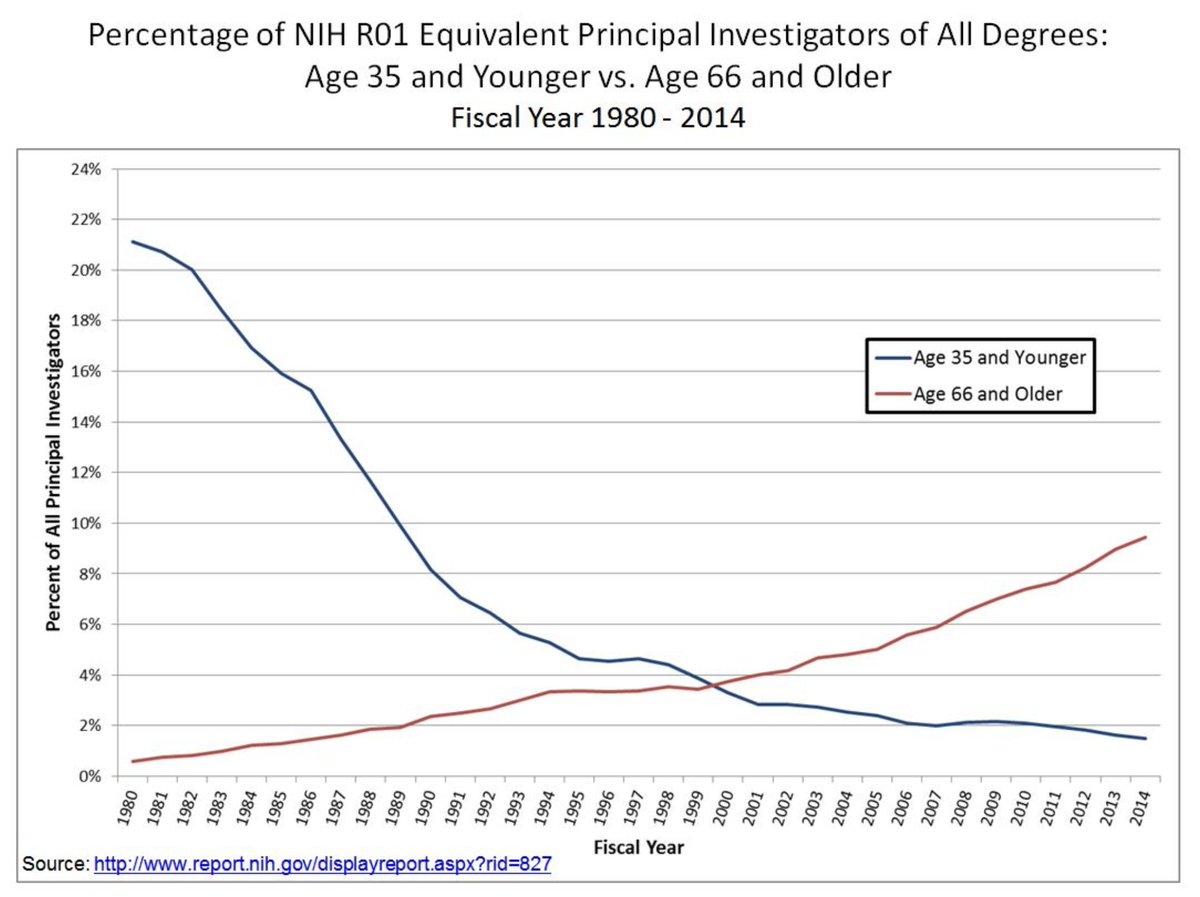
It's bad that the NIH has pretty much stopped funding young scientists to lead projects
26
88
726
189,540
Scott Tyler (@ScienceScottT@genomic.social) retweeted

17 Dec 2024
Single-cell RNA sequencing is biased (and more so if you count more molecules). But biases aren't just arbitrary artifacts; they reveal something non-obvious about the technology and chemistry of sequencing, and we can learn a lot by using physical models. Read to find out more!
16 Dec 2024

Length biases in single-cell RNA sequencing of pre-mRNA. Check out this research by @lpachter & @GorinGennady in @BiophysReports #CellBio2024 hubs.li/Q02_LC2n0
7
61
6,865
Scott Tyler (@ScienceScottT@genomic.social) retweeted

16 Dec 2024
Length biases in single-cell RNA sequencing of pre-mRNA. Check out this research by @lpachter & @GorinGennady in @BiophysReports #CellBio2024 hubs.li/Q02_LC2n0
18
93
20,619
Scott Tyler (@ScienceScottT@genomic.social) retweeted

11 Dec 2024
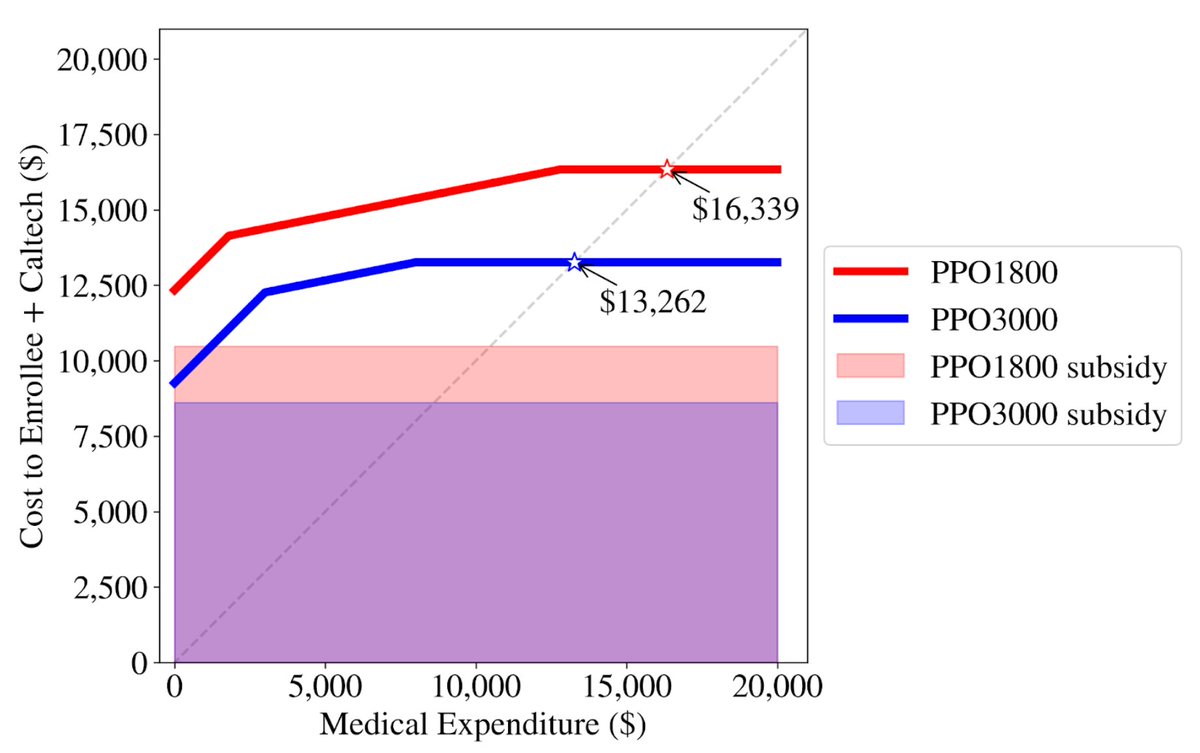
If you’re frustrated with healthcare, get this:
Health Insurance @ElevanceHealth (formerly Anthem) bamboozled @Caltech into overpaying thousands per person for a pricier plan identical to the cheaper one—except for a higher premium and deductible.
No added benefits.
20 Oct 2022

Furthermore, since Caltech subsidizes the plans by different amounts, Caltech also pays an extra $1,865.28 annually for each staff member who chooses PPO 1800 over PPO 3000.
4
5
1,187
Scott Tyler (@ScienceScottT@genomic.social) retweeted

11 Dec 2024
Seeing data on macrophages and metabolism from single cell. It's somewhat buried in the paper and not obvious from the title - but we see different metabolic profiles in macrophages from pro-regenerative vs fibrotic materials in vivo! science.org/doi/10.1126/scii…

1
13
48
3,580
Scott Tyler (@ScienceScottT@genomic.social) retweeted

29 Nov 2024
Data can be analyzed in endless ways, as this paper reminds us. So while our published paper reports one way to do it, it's crucial to test many many variants of the analysis to see just how robust our conclusions are.

7
53
264
40,468
Scott Tyler (@ScienceScottT@genomic.social) retweeted

29 Nov 2024
Happy Thanksgiving! We are thankful for the opportunity to talk about how cool genomics is with you all the time. Our family might get annoyed at us for talking about it too much, but that won’t stop us!

2
24
135
6,863
It's a weird and beautiful bag of cheetos ;-) Cool technique! Worth checking out the paper; lots of cool new science can be done with this resolution in living systems!
27 Sep 2024

Relationship between chromosomes (orange) and the mitotic spindle (green) in four stages of cell division, as seen by Bessel Beam plane structured illumination microscopy cell.com/fulltext/S0092-8674…
1
554
Scott Tyler (@ScienceScottT@genomic.social) retweeted

28 Sep 2024
Our group of #ImageForensics experts @Thatsregrettab1 , @mumumouse2, @schrag_matthew, and myself are currently posting the problems we found in these papers.
We have now posted 118 of Dr. Masliah's paper onto @PubPeer. Follow our progress here:
pubpeer.com/search?q="Elie…
26 Sep 2024

My new investigation for @newsfromscience: Did a top @NIH official manipulate Alzheimer's/Parkinson’s research for decades? Neuroscientist Eliezer Masliah found to engage in scientific misconduct; 132 of his papers fall under suspicion
science.org/content/article/…
4
40
183
70,239
Scott Tyler (@ScienceScottT@genomic.social) retweeted
26 Sep 2024
Help !
Do you know how to get cloud storage for an academic lab that benefits from non-profit pricing ?

19 Sep 2024

If you use Google Drive or OneDrive as cloud storage for your academic lab, do you use the non-profit discounts?
How did you set up the non-profit status and associated discounts ?
2
3
5
3,030
Scott Tyler (@ScienceScottT@genomic.social) retweeted

21 Sep 2024
biorxiv.org/content/10.1101/…
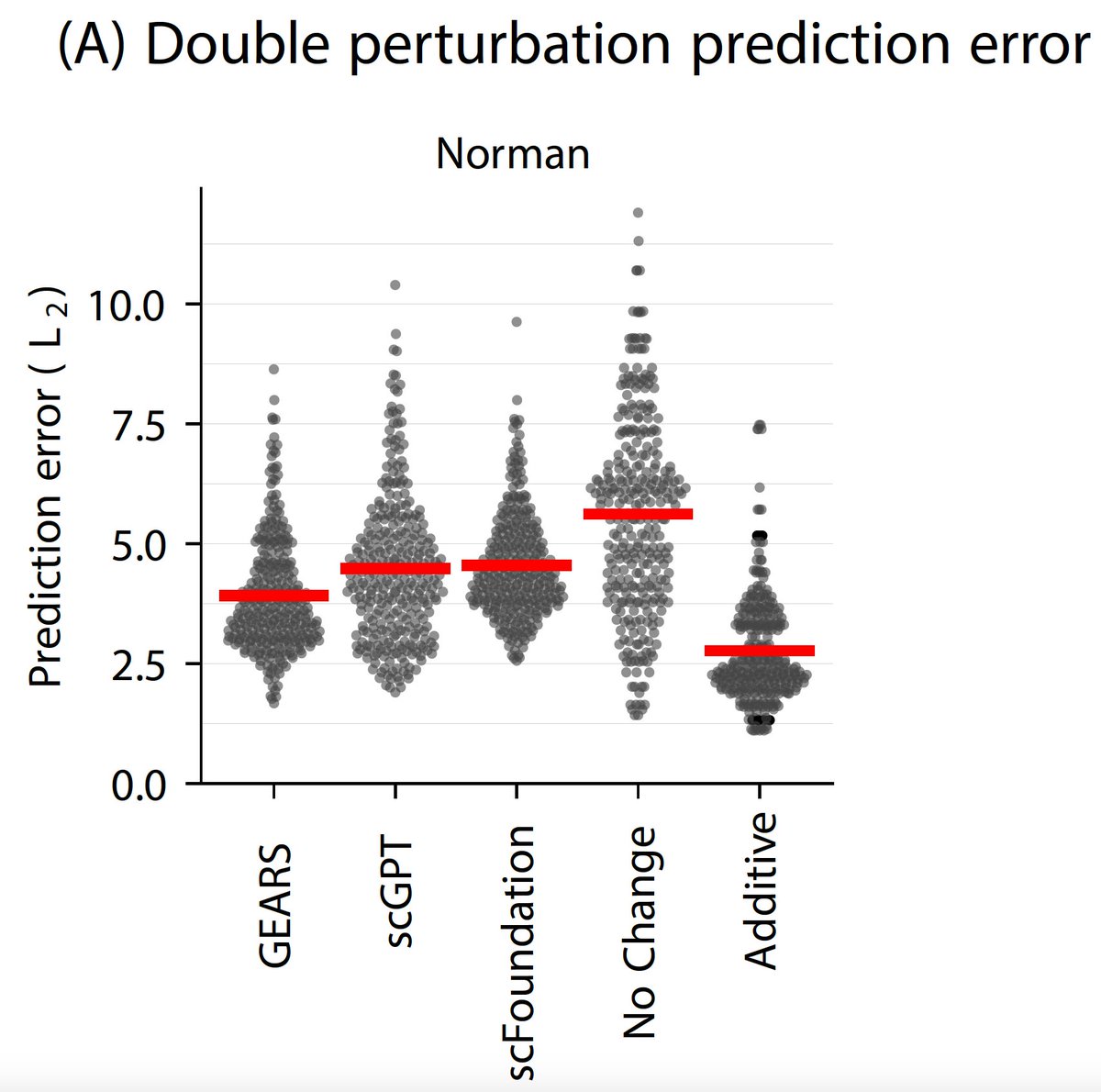
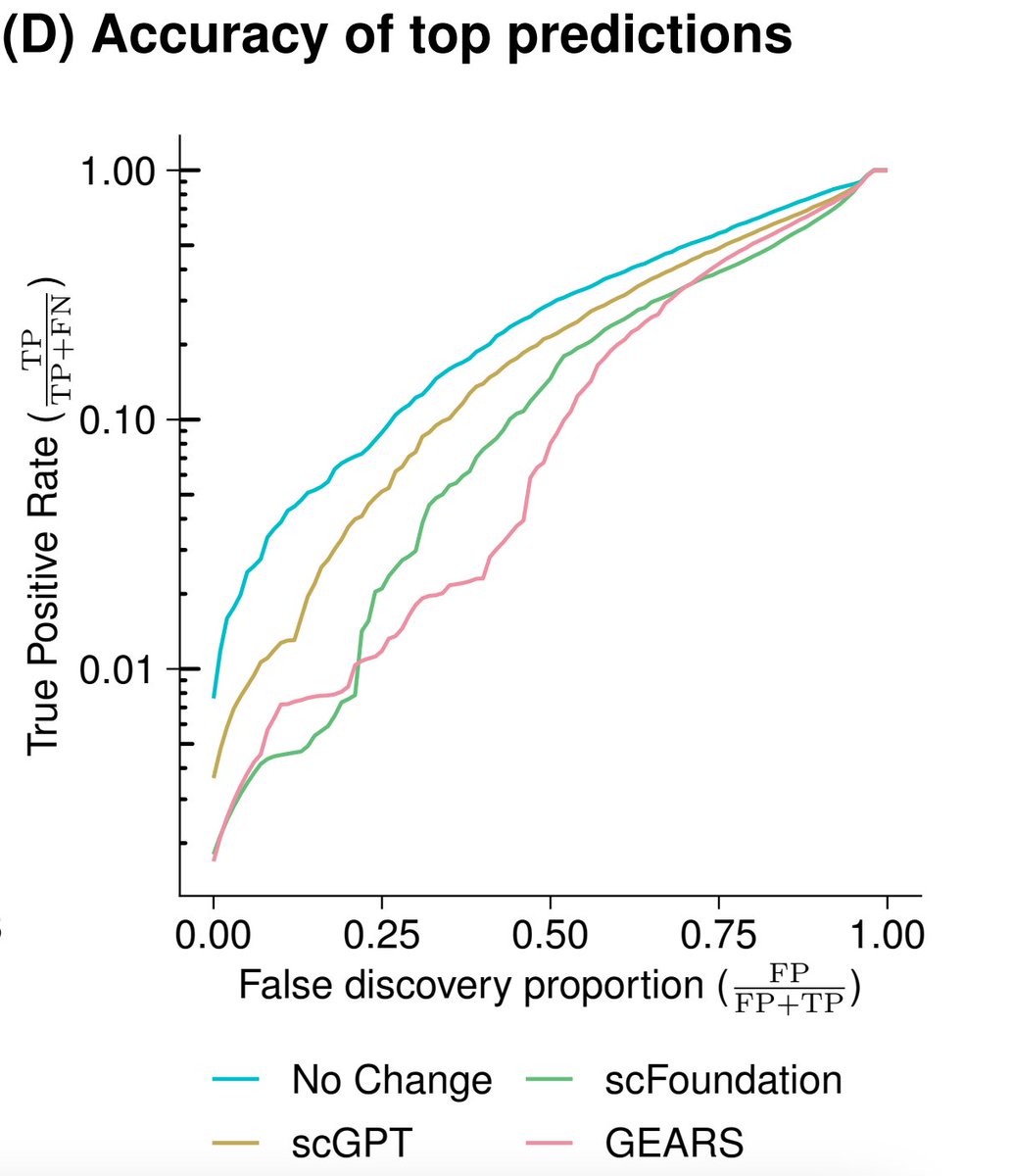
Nice benchmark of single cell "foundation models" (scGPT, scFoundation) and GEARS (a GNN model) further hyped as "virtual cell models" against linear baselines on perturbation prediction.
Long-story short: they can't beat the linear baselines. 1/
7
115
481
80,470
Scott Tyler (@ScienceScottT@genomic.social) retweeted

There's a lot of excitement about foundation models and their ability to learn biology 🧬💻
But current tools for perturbation prediction perform worse than simple linear models! We need more careful benchmarking to make progress.
biorxiv.org/content/10.1101/…

11
75
252
32,020
Scott Tyler (@ScienceScottT@genomic.social) retweeted
16 Sep 2024
Saying what amounts to — nobody does this, I don't personally do this, this is not a problem, people who do this are bad scientists — abrogates responsibility for understanding the effect on the field's methodology and reliability. Without that, there's no field in the long term.
1
1
1
547
Scott Tyler (@ScienceScottT@genomic.social) retweeted

14 Sep 2024
We're cooked.
14
91
954
97,505