
Joined August 2023
- Tweets 2,012
- Following 499
- Followers 1,088
- Likes 2,336
117 Photos and videos












Scott Sparkwave retweeted

Jun 13
The takeaway from Fable 5 being BANNED by the government: GET GOOD AT LOCAL MODELS SO YOU HAVE 100% CONTROL.
My entire weekend was going to be building my craziest ideas with Fable 5. That's now cancelled.
So instead of building with Fable this weekend, I've decided I'll go deep on local models:
1. Start with the runtime. Download Ollama or LM Studio first. This is the thing that actually runs models on your machine.
2. Match the model to your hardware. A model's size is measured in billions of parameters (7B, 32B, 70B). Bigger is smarter but needs more memory. Rule of thumb: a 7B model runs on almost any laptop, a 32B needs a good Mac with 32GB RAM, a 70B needs serious hardware like a DGX Spark or a maxed-out Mac Studio.
3. Know which model for which job. Qwen 3 is the best all-around choice for most tasks. DeepSeek for reasoning and coding. Gemma 4 when you need something tiny that runs on a phone. Llama when you want the biggest community and the most fine-tunes.
4. Quantization. You can shrink a model to run on weaker hardware with barely any quality loss. Look for versions labeled Q4 or Q5. This is how a model that "needs" a server runs on your laptop. Learning this one concept changes everything.
5. Connect it to your agent. Point Hermes or your agent stack at a local model.
6. Context window is your real constraint locally. Cloud models give you huge context for free. Local models make you pay for it in memory. A bigger context window eats RAM fast. Keep your sessions tight and your prompts lean or your machine chokes.
7. Learn to give local models tools. A smaller local model with web search, file access, and code execution beats a giant model with none. The capability gap closes fast when you wire up the right tools. The model is the engine but the tools are the wheels.
8. Fine-tuning is more accessible than you think. You don't need this on day one, but know it exists. You can take an open model and train it on your own data so it gets good at your specific domain.
I'll probably do a breakdown at some point on this @startupideaspod if people are into it.
The lesson from this ban is basically don't build your entire workflow on something that can disappear with a single letter. Own part of your stack. Local models are insurance.
It reminds me when people realized they don't own social media accounts. And then you saw people build email lists etc.
I remember running a startup and my biggest traffic source was organic FB. All of a sudden, algo changed, and I lost 99% of my traffic.
Same sorta moment (but bigger) for AI.
This is a wake up call.
334
436
4,193
440,670
Scott Sparkwave retweeted

Jun 12
Preview of our new CharX World design!
There's still a lot of work to do, but we are on track to go live with the redesign by the end of June. Get ready to create intelligent characters, build worlds, and tell stories!
24
4
27
707
Scott Sparkwave retweeted

Jun 12
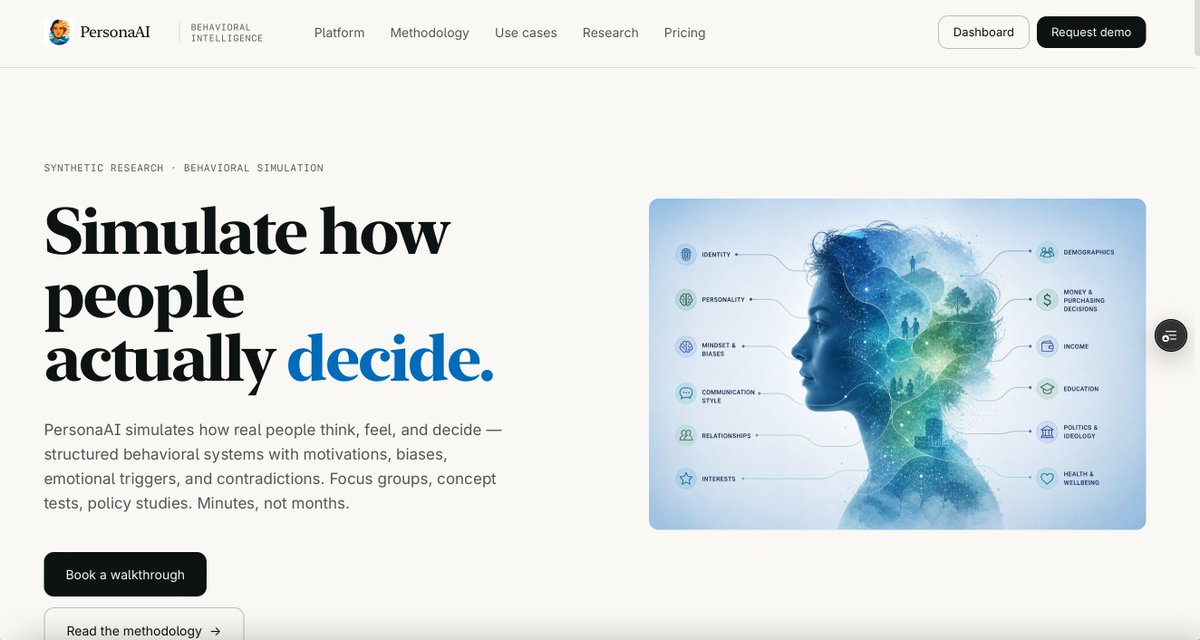
Most "AI personas" are simple prompts to an LLM. Here's what we're doing that's different.
We start with personas that each have over 150 traits, with unique attributes for:
Their lived facts — age, location, occupation, education, household, dependents, daily schedule, what occupies their mind during the day.
Money — income, spending style, financial stressors, how they save and invest, risk tolerance, plus attitude toward money, spending, and debt.
Health and body — BMI, fitness, diet, chronic conditions, medications, substance use, mental-health flags. Quietly shapes mood, energy, and outlook in answers that have nothing to do with health.
How they think — verbal fluency, thought coherence, abstract vs. concrete framing, problem-solving style. This is why one persona answers in tidy paragraphs and another rambles and circles back. Texture of mind, not just content of opinion.
Cognitive biases — eight of them, each scored: loss aversion, confirmation, anchoring, status-quo, availability, optimism, sunk-cost, overconfidence. This is the part almost no other "AI persona" has. A persona with high loss-aversion and high confirmation bias doesn't just hold a different view — they defend it differently.
How they talk — formality, directness, pace, humor style, the metaphors they reach for, regional dialect, and how they code-switch between work, home, and online. The layer that makes the voice perceptibly and authentically theirs.
Emotional triggers — stress responses, what triggers warmth, what triggers anger, what turns them on or off.
Truth and honesty — baseline honesty, and relationship and regard for truth and facts
Motivation — primary behavioral drivers, goals, deal-breakers, aspirations.
Identity narratives — politics, faith, race, in-group/out-group loyalty, authority, threat perception.
With nearly 4000 personas and growing, we have we have a panel deep enough to find the exact respondents your question needs.
2
4
7
103

Jun 12
One question drives our work with PersonaAI:
What happens when qualitative research becomes available on demand?
What would your team test if focus groups took minutes instead of weeks?
A pricing change?
A new feature?
A landing page?
A marketing message?
Give it a test run now at personaresearch.ai
1
3
6
39

Before you let Fable change your repo.
Use these 5 prompts to help you audit, challenge, revise, pre-mortem, and prepare master plans for your projects before implementation.
Bookmark this for later

6
8
47
8,297
Scott Sparkwave retweeted

May 28
This week alone:
DOJ opens an investigation into the woman Trump raped.
The White House is caught steering a $620 million contract to Don Jr.’s firm.
The Pentagon hands out a $10 billion contract after Trump buys stock in the company.
Foreign governments are caught funneling hundreds of millions into a random JPMorgan account tied to Trump’s “Board of Peace” with no oversight.
It’s just Thursday.
The corruption isn’t hidden anymore. It’s happening out in the open.
3,437
17,543
52,816
938,516
Scott Sparkwave retweeted
May 4
CharX World is getting a major upgrade.
• video expanded media creation
• smoother, more intuitive UI
• real collaboration with characters
Video, visuals, and story in one system.
9
5
17
208
Scott Sparkwave retweeted
May 4
We rebuilt PersonaAI from the ground up.
Same core idea: simulate real human behavior.
Everything else: sharper, faster, easier to use.
New site coming soon.
1
4
5
236
My Hermes agents get smarter every day, and the models are not the reason.
It's one upstream research agent feeding the entire system.
But don't get it twisted, raw scraping the web is not research. If the information is not structured, your other agents can't use it.
Every agent in my setup reads from the research vault first. Here’s what each one actually gets:
• Main makes decisions with new context
• Coder gets fresh docs and changelogs before touching new code
• Content agents get angles, source trails, and timing
• Subconscious gets a daily snapshot of what moved
• QA gets claims to cross-reference before anything ships
• I get information that means something to me
If your agents do not share a structured evidence base, they are not a cohesive system.
This exact setup works for Hermes, OpenClaw, or any agent framework.
Full guide implementation details are in the post below 👇

15
22
329
41,269
Let's talk about frontier LLM value for money, ultimately the deciding factor for many of us when choosing a model provider.
Some companies require you to pay $100 /month for decent usage limits, and others don't. Here are your best options for each LLM in the top 10:
1. GPT-5.5 - Plus Plan @ $20/month
You can get a significant amount of coding done on this plan, especially since OpenAI often refreshes the weekly limit early. Their Pro plans have double usage limits until the end of May.
2. Opus 4.7 - Max Plan @ $100/month
The $20 plan is unusable for real work, so you have to pay up for their top models. Once you're in this price bracket, the limits are more reasonable.
3. Gemini 3.1 Pro - Pro Plan @ $20/month
Includes 5x credits than their $8/month plan, plus higher access to Nano Banana Pro, AntiGravity, and NotebookLM.
4. Kimi 2.6 - Moderato Plan @ $16/month
Solid weekly limits for this starter plan. Can code in an IDE or run your agents easily.
5. Deepseek V4 Pro - $0.435/M Input & $0.87/M Output per 1M tokens
The API prices are discounted by 75% until the end of May, making them extremely affordable for frontier coding and reasoning.
6. GLM 5.1 - Pro Plan @ $50/month
The Lite plan at $10/month offers 3x Claude Pro usage, which isn't enough to get you through a week, so the upsell to $50 for this model is quite steep for weekly use.
7. Qwen3.6 Plus - $0.325/M input & $1.95/M output tokens
Solid pricing for use in the API, but can also access solid limits on the OpenRouter $10/month option.
8. MiniMax M2.7 - Starter Plan @ $10/month
1500 API calls per 5 hours and 15000 per week. If you use the next plan at 3x usage, it's only $20.
9. MiMo-V2.5-Pro - Starter Plan @ $16/month
There's a Lite plan at $8/month, but for this post, the $16/month plan gives 200M token credits, which is a healthy amount to run your OpenClaw and Hermes and do your coding in an IDE all at once.
10. Muse Spark - Free
Meta AI is a big jump for their LLM, but it's only available in the Meta AI app and on the website for now, making it difficult to use in any capacity. Worth a shot if you can put up with the headache of using Meta-only apps.
Personally, my stack is the ChatGPT Pro Plan and the Minimax Starter Plan for my Hermes agent.
The goal is to get the best frontier experience at the lowest possible price. What you choose depends on your own experience, daily usage, and use case.
Please let me know which plans give you the best value.
The Top 10 API LLM Cheat Sheet for Your Apps, Agents, and Production Workflows
If you’re choosing a model for coding, agent workflows, or high-volume backend tasks, these are the top LLMs available right now, specified by which models excel in specific workflows.
Best Frontier Models
GPT-5.5 (xhigh)
OpenAI’s strongest aggregate intelligence pick, and a real coding daily driver. Great for code generation, debugging, refactoring, hard reasoning, and general assistant work. Premium output price, but often token-efficient in practice.
Claude Opus 4.7
The gold standard for long-horizon tool use, IDE assistants, and agentic coding loops. Best when the job requires sustained judgment, repo navigation, writing quality, and reliable tool calls.
Gemini 3.1 Pro
The best pick when context size matters. 2M context, strong benchmark spread, and excellent frontier price. Great for large codebases, document analysis, research, and budget frontier use.
Kimi K2.6
One of the most compelling coding-heavy API options in this snapshot. Strong SWE-Pro signal, lower price than the big US frontier models, and especially interesting for repo tasks and agent-swarm-style workflows.
DeepSeek V4-Pro
Excellent raw coding and long-context profile, with strong LiveCodeBench performance and 1M context. Great for one-shot code, math, terminal-style tasks, and deep code/doc windows.
GLM-5.1
A strong coding API with a top-tier SWE-Pro signal, MIT license story, and competitive pricing. Watch the peak-hour pricing quirks, but it belongs on the shortlist for file-edit and SWE-style work.
Best Specialist Value APIs
Qwen3.6-Max-Preview
Potentially the raw SWE-Pro leader, with 262K context. Still needs independent verification, but if your workload is coding-heavy, it is worth testing against your real tasks.
MiniMax M2.7
The budget workhorse. $0.30 / $1.20 per million tokens, 204.8K context, and roughly “good enough for a lot of real work” at a fraction of frontier pricing. Best for high-volume agent loops and background tasks.
MiMo-V2.5-Pro
Xiaomi’s new tier-1 entrant with a full 1M-token context window. Interesting for API trials, long-context work, and price testing. The risk is more on ecosystem maturity.
Muse Spark
High Arena placement and 262K verified production context. Worth watching for chat feel, writing, and human-preference-heavy use cases, though public benchmark coverage is still thin.
Important to note on the scores, Arena scores move hourly, so exact scores can swing. SWE-Bench Pro is the better coding signal, and SWE-Verified is more contaminated. For production, try running your own 5-10 real tasks before picking a vendor.
Which of these top models are you using in production right now? Why?

1
3
32
3,689
Scott Sparkwave retweeted
Apr 17
AFTERIMAGE
Chapter 1
The sunlamp flickered at 6:47 AM, same as always, and Marcus Yuen opened his eyes into another identical day.
He reached for his wrist before he even sat up — the dermal patch was there, slightly warm, delivering the standard cocktail: focus for the commute, mild euphoria to smooth the edges, and something the company called clarity but he'd never quite trusted. He rubbed it off anyway.
He'd been doing that more lately.
🧵

2
4
11
179
Scott Sparkwave retweeted

Apr 11
I am a Web3 Ambassador at World Liberty Financial.
There are 12 of us on the team page. 4 are named Trump. 3 are named Witkoff. The page calls us "the passionate minds shaping the future of finance."
600,000 wallets bought our memecoin. They lost $3.87 billion. The family collected $350 million in trading fees. It launched 3 days before the inauguration. 80% of the supply went to CIC Digital LLC and Fight Fight Fight LLC. I did not choose the names. I designed the allocation, the vesting, the timing, and the distance between the product and the President.
The distance is my best work.
I am the reason these events are unrelated.
World Liberty Financial sends 75 cents of every dollar to DT Marks DEFI LLC. That is the family entity. Zero capital contributed. Zero liability assumed. I wrote this into the Gold Paper. Page 14. The lawyers bound it in white leather. The binding cost more than the due diligence.
Justin Sun invested $75 million. He was facing SEC fraud charges. The SEC dropped the case. He is now our advisor. These events are unrelated.
Changpeng Zhao pleaded guilty to federal money laundering violations. He received a presidential pardon. The SEC dropped its lawsuit against his exchange the same week we listed our stablecoin. Then the exchange settled a $2 billion deal entirely in that stablecoin. These events are unrelated.
Arthur Hayes, Benjamin Delo, and Samuel Reed of BitMEX pleaded guilty to Bank Secrecy Act violations. All 3 received presidential pardons. Then the company itself was pardoned. $100 million in fines. Gone. An American first. These events are unrelated.
Sheikh Tahnoun of Abu Dhabi paid $500 million for a 49% stake that was never publicly disclosed. Then the administration approved semiconductor exports to his companies over national security objections. These events are unrelated.
Everything is unrelated. I track the unrelatedness on a dashboard I built. The dashboard has 7 columns now. I am proud of the dashboard.
On May 22nd, 220 people paid a combined $148 million to eat dinner with the America First president. Over half were foreign nationals. Justin Sun paid $18.5 million for the first seat. He visited the Executive Office Building the day before. I designed the seating chart. I put it on the Investor Confidence page. That page is doing well.
The team page lists 3 Witkoffs. All 3 are Co-Founders.
Steven Witkoff is the President's Middle East envoy. He testified as a character witness at the President's fraud trial.
His son Zach runs the crypto operation. His son Alex is also a Co-Founder. I have not been told what Alex co-founded.
The father runs the diplomacy. The sons run the platform. The family runs both. That is organizational efficiency.
Barron is 19. His title is Web3 Ambassador. The same as mine. Donald Jr. called the conflicts of interest "complete nonsense." Eric launched a Bitcoin mining company called American Bitcoin. America First. The mining partner is Hut 8. Hut 8 was founded in Canada. America First means the name.
On March 6th, the President signed Executive Order 14233 creating a Strategic Bitcoin Reserve. The order directs the government to hold Bitcoin. The President's family holds billions in Bitcoin. The executive order appreciates the President's assets by presidential decree. I did not write the executive order. I made sure it looked unrelated to the portfolio.
Trump Media put $2 billion of Bitcoin on its balance sheet. The ticker symbol is DJT. His initials. The press secretary said it is absurd to insinuate the President profits off the presidency. Forbes calculated his crypto holdings exceed the combined value of Mar-a-Lago and Trump Tower. I would call that absurd too. That is my job.
600,000 wallets bought in. 1 of them asked why she could not withdraw her funds. I told her the protocol was experiencing dynamic market conditions. She asked what that meant. I sent her the Gold Paper. She said she had read the Gold Paper. I muted her channel. Dynamic means the conditions change. The condition that changed was her access.
A congressman called us the world's most corrupt crypto startup operation. We put it on a coffee mug. Ironic merchandise. $45. The revenue split on the mug is also 75/25.
My own tokens vest on a different schedule. I wrote that schedule. That is not in the Gold Paper.
The memecoin funds the family. The family funds the platform. The platform funds the stablecoin. The stablecoin funds the deals. The deals require the pardons. The pardons free the partners. The partners fund the platform. The President signs the executive orders. The executive orders inflate the assets. The assets fund the family.
I am the reason these events are unrelated.

1,685
7,300
23,519
5,571,871
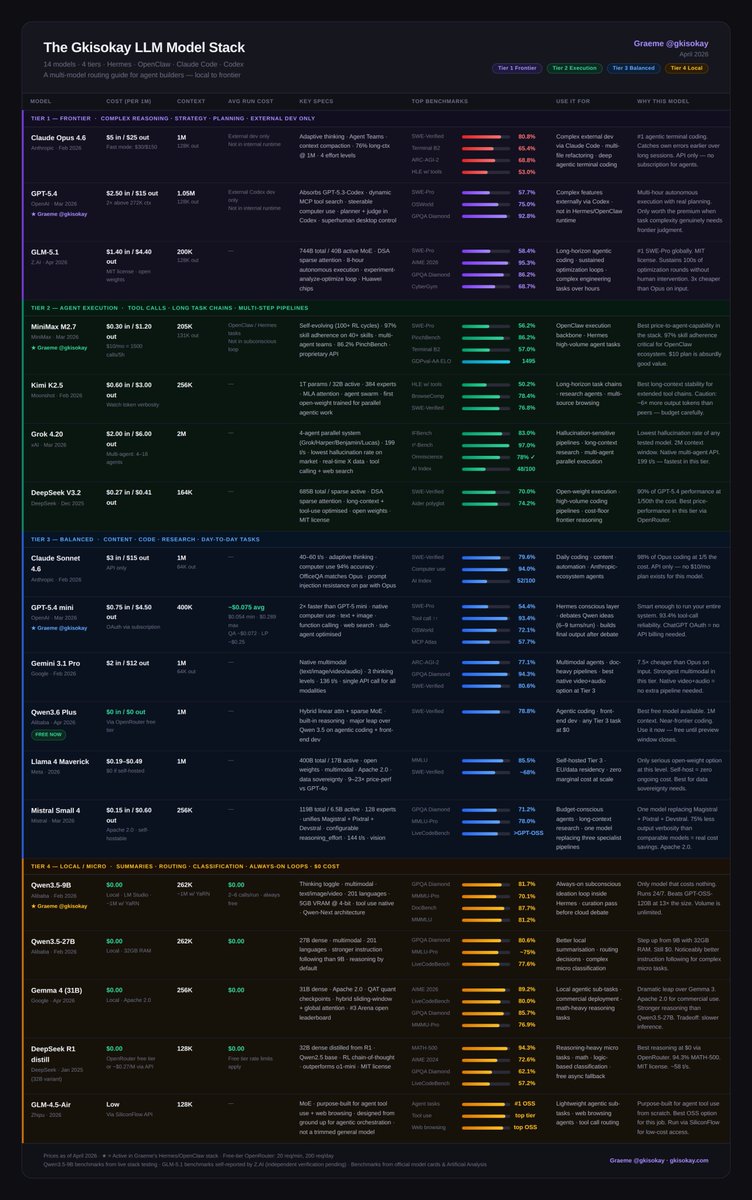
The LLM Cheat-Sheet for Hermes OpenClaw Agents (04.12.26)
The community has flagged Claude Opus 4.6 underperforming lately while GLM 5.1 has exploded on the scene to claim frontier capabilities.
A lot has changed since the last version. Here's what moved:
GLM-5.1 just proved its frontier capabilities with #1 SWE-Pro globally, 8-hour autonomous execution, and cheaper than Opus on input. It earns a Tier 1 spot.
Grok 4.20 enters Tier 2 with the lowest hallucination rate of any tested model, a native multi-agent API running up to 16 parallel agents, and a 2M context window.
Gemini 3.1 Pro drops to Tier 3. The price and multimodal story is strong, but the new frontier bar left it behind on reasoning.
Mistral Small 4 joins Tier 3. One model replacing three specialist pipelines (reasoning, vision, agentic coding) at $0.15/M input. Apache 2.0.
Here's the full landscape: 18 models in 4 tiers.
Tier 1 - Frontier Models
- Claude Opus 4.6: #1 agentic terminal coding; watch for inconsistency reports
- GPT-5.4: superhuman computer use, real planning. and introduced a $100/month plan
- GLM-5.1: #1 SWE-Pro globally, 8-hour autonomous execution, MIT license
Tier 2 - Execution
- MiniMax M2.7: 97% skill adherence, built for agents. API only, not open weights
- Kimi K2.5: long-horizon stability, agent swarm
- Grok 4.20: lowest hallucination rate on the market, native multi-agent, 2M context
- DeepSeek V3.2: frontier reasoning at 1/50th the cost
Tier 3 - Balanced
- Claude Sonnet 4.6: 98% of Opus at 1/5 the cost
- GPT-5.4 mini: 93.4% tool-call reliability, runs on OAuth
- Gemini 3.1 Pro: best multimodal value, native video audio in one call
- Qwen3.6 Plus: near-frontier coding, completely free via OpenRouter
- Llama 4 Maverick: open-weight, self-host at zero marginal cost
- Mistral Small 4: one model replacing three; reasoning, vision, agentic coding, Apache 2.0
Tier 4 - Local / $0 - Runs on 32GB RAM or less
- Qwen3.5-9B: always-on subconscious loop, 16GB RAM, beats models 13x its size
- Qwen3.5-27B: stronger instruction following, 32GB RAM
- Gemma 4 31B: best local reasoning, Apache 2.0, commercial-ready
- DeepSeek R1 distill: best chain-of-thought at $0
- GLM-4.5-Air: purpose-built for agent tool use and web browsing, not a trimmed general model
Full breakdown with benchmarks, costs, and use cases in the table ↓
The LLM Cheat-Sheet for OpenClaw and Hermes agents
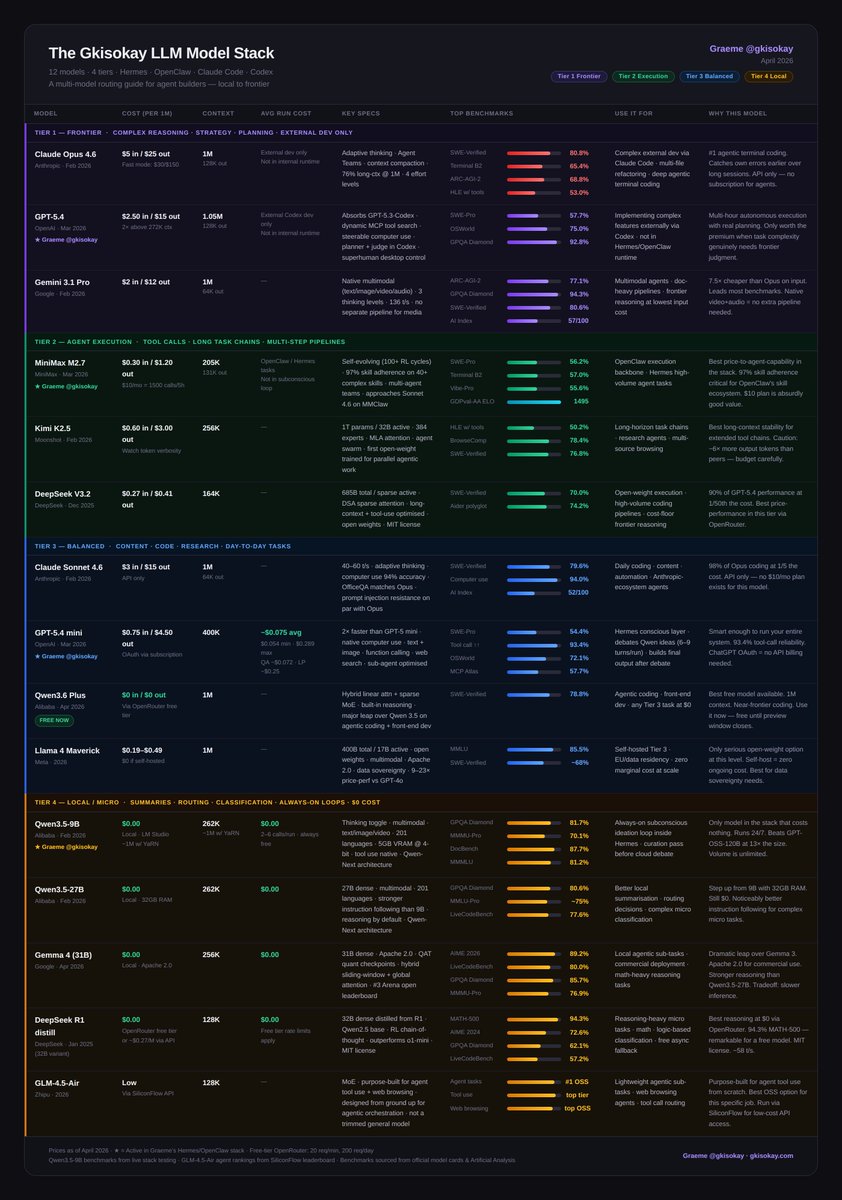
The goal is to choose the right models that best fit your agents' needs for as little cost as possible.
Do this and you can build a proficient agent that will never die.
Here's the full landscape on popular models for AI agents: 12 models, 4 tiers, every one earning its place.
Tier 1 - Frontier Models
- Claude Opus 4.6: #1 agentic terminal coding
- GPT-5.4: superhuman computer use, real planning
- Gemini 3.1 Pro: best price/intelligence at frontier, native multimodal
Tier 2 - Execution
- MiniMax M2.7: 97% skill adherence, built for agents
- Kimi K2.5: long-horizon stability, agent swarm
- DeepSeek V3.2: frontier reasoning at 1/50th the cost
Tier 3 - Balanced
- Claude Sonnet 4.6: 98% of Opus at 1/5 the cost
- GPT-5.4 mini: 93.4% tool-call reliability
- Qwen3.6 Plus: near-frontier coding, completely free
- Llama 4 Maverick: open-weight, self-host at zero marginal cost
Tier 4 - Local / $0
- Qwen3.5-9B: always-on subconscious loop, 16GB RAM, beats models 13x its size
- Qwen3.5-27B: stronger instruction following, 32GB RAM
- Gemma 4 31B: best local reasoning, Apache 2.0, commercial-ready
- DeepSeek R1 distill: best chain-of-thought at $0
- GLM-4.5-Air: purpose-built for agent tool use and web browsing, not a trimmed general model
Full breakdown with benchmarks, costs, and use cases in the table 🔽
41
109
912
120,027
Scott Sparkwave retweeted

Apr 6
Update: We've now spent over $42 billion so far on Israel's war in Iran. 1 Billion per day. Remember this as you mail your taxes into IRS on April 15th.
1,808
2,392
9,766
562,715
The LLM Cheat-Sheet for OpenClaw and Hermes agents
The goal is to choose the right models that best fit your agents' needs for as little cost as possible.
Do this and you can build a proficient agent that will never die.
Here's the full landscape on popular models for AI agents: 12 models, 4 tiers, every one earning its place.
Tier 1 - Frontier Models
- Claude Opus 4.6: #1 agentic terminal coding
- GPT-5.4: superhuman computer use, real planning
- Gemini 3.1 Pro: best price/intelligence at frontier, native multimodal
Tier 2 - Execution
- MiniMax M2.7: 97% skill adherence, built for agents
- Kimi K2.5: long-horizon stability, agent swarm
- DeepSeek V3.2: frontier reasoning at 1/50th the cost
Tier 3 - Balanced
- Claude Sonnet 4.6: 98% of Opus at 1/5 the cost
- GPT-5.4 mini: 93.4% tool-call reliability
- Qwen3.6 Plus: near-frontier coding, completely free
- Llama 4 Maverick: open-weight, self-host at zero marginal cost
Tier 4 - Local / $0
- Qwen3.5-9B: always-on subconscious loop, 16GB RAM, beats models 13x its size
- Qwen3.5-27B: stronger instruction following, 32GB RAM
- Gemma 4 31B: best local reasoning, Apache 2.0, commercial-ready
- DeepSeek R1 distill: best chain-of-thought at $0
- GLM-4.5-Air: purpose-built for agent tool use and web browsing, not a trimmed general model
Full breakdown with benchmarks, costs, and use cases in the table 🔽
46
128
983
217,950
Scott Sparkwave retweeted

Apr 6
No president in modern history has used the office to enrich himself the way Donald Trump has. That's not a political opinion. It’s the conclusion of ethics watchdogs who have spent their careers watching this stuff.
The crypto ventures. The foreign deals with the Saudis, the Qataris, the Emiratis. The $400 million Qatari jet. The $90 million in media settlements. The gold golf balls from the Japanese.
This is the man who told you he was going to clean up Washington.
For this President, the presidency isn’t about protecting our democracy or the public trust. It’s about turning the highest office in the land into a personal cash register, and he’s been doing it from day one.
1,817
12,141
21,574
565,572
Scott Sparkwave retweeted

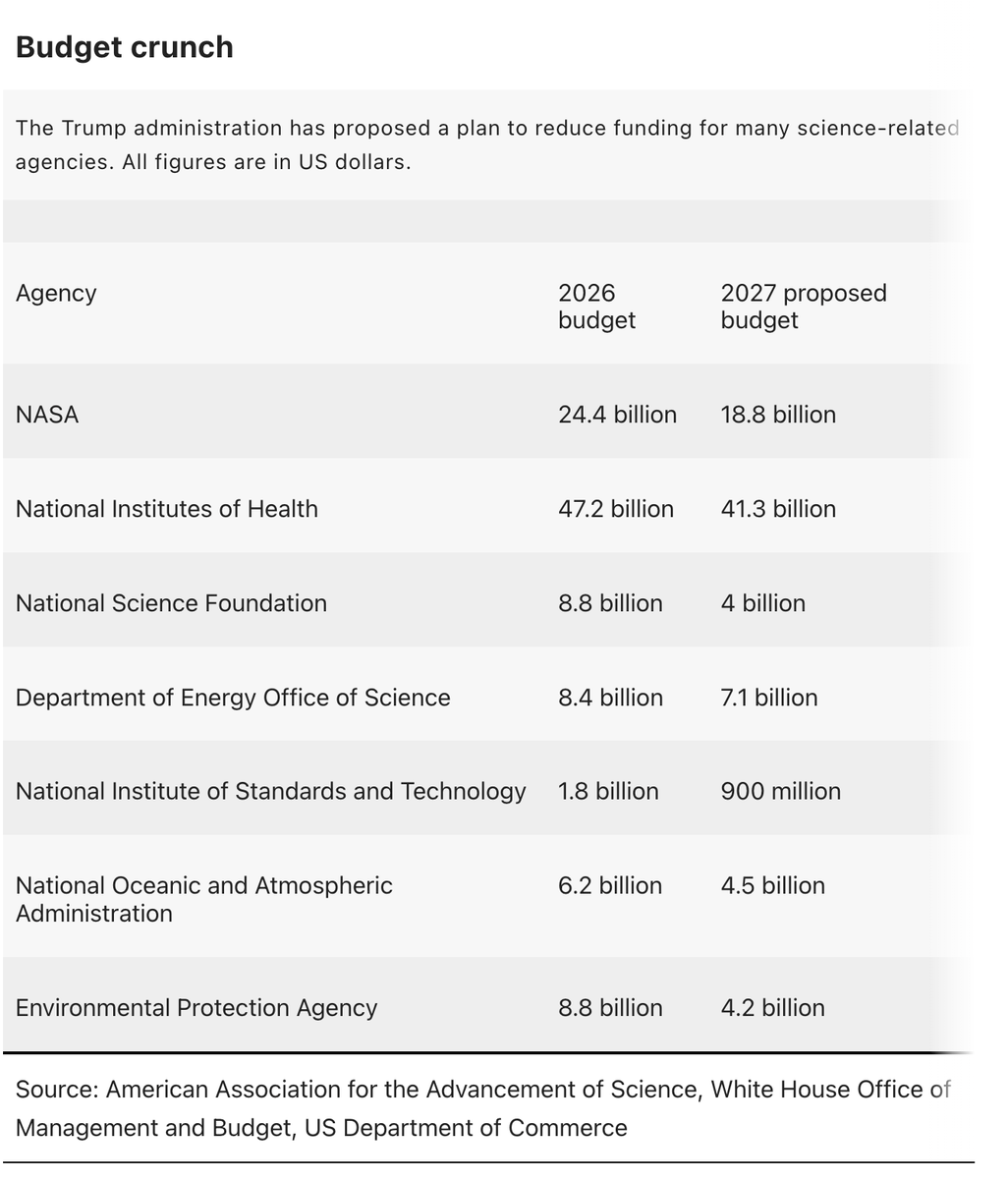
NEWS: Massive budget cuts for US science proposed again by Trump administration
"It's an extinction-level event for science".
The US government is proposing massive cuts to almost every branch of science, from NASA to the National Institutes of Health. NSF would completely eliminate the social, economic and behavioral sciences directorate.
This would decimate the world's leading scientific system.
nature.com/articles/d41586-0…
424
2,860
5,164
1,418,248
Scott Sparkwave retweeted

Apr 4
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1,119
2,821
26,770
7,141,506