
jr AI Engineer | Transformers × Financial Data | CS Student
Joined January 2022
- Tweets 1,910
- Following 150
- Followers 499
- Likes 2,169
1,078 Photos and videos


Pinned Tweet

Feb 28
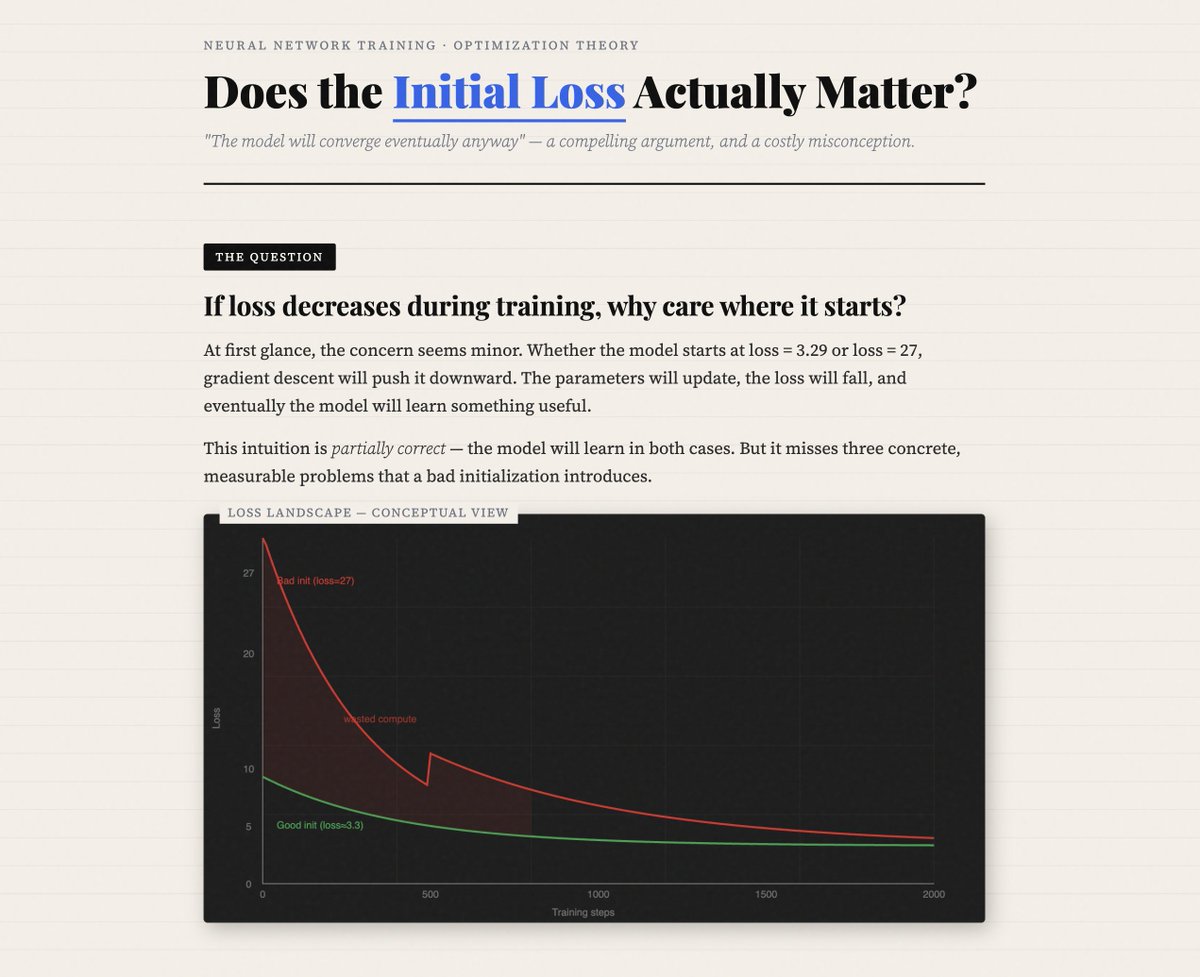
"The model will converge anyway" - a compelling argument, and a costly misconception.
Two models. Same everything.
Model A, step 0: loss = 3.29 → starts learning immediately.
Model B, step 0: loss = 27 → spends the first 9,000 steps just getting back to where A started.
Model B didn't train for 10k steps. It trained for ~800.
The rest was debt repayment.
A bad initialization doesn't slow you down. It steals your training budget — silently, one "optimization" step at a time.
🧵
1
2
196
The Underfitted retweeted
Feb 28
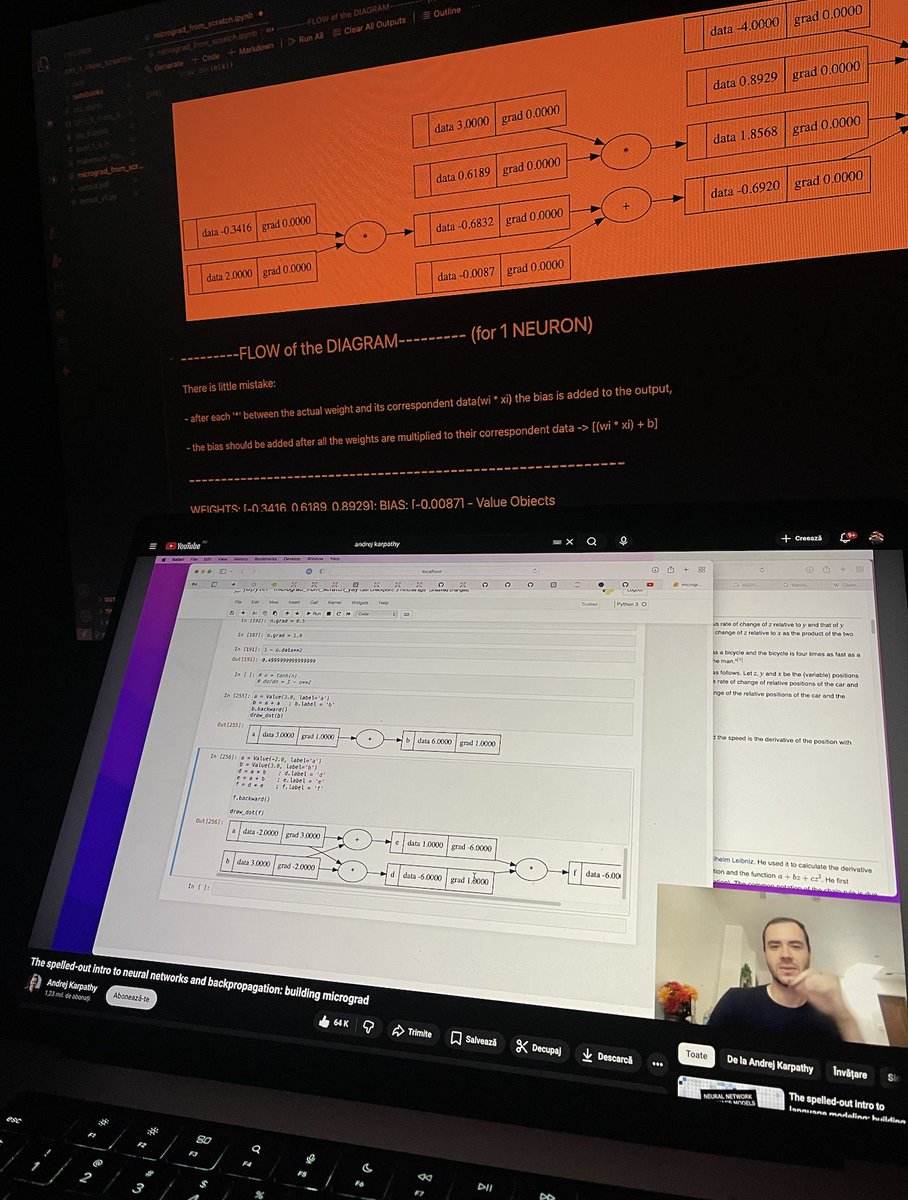
It's 6PM on a Saturday.
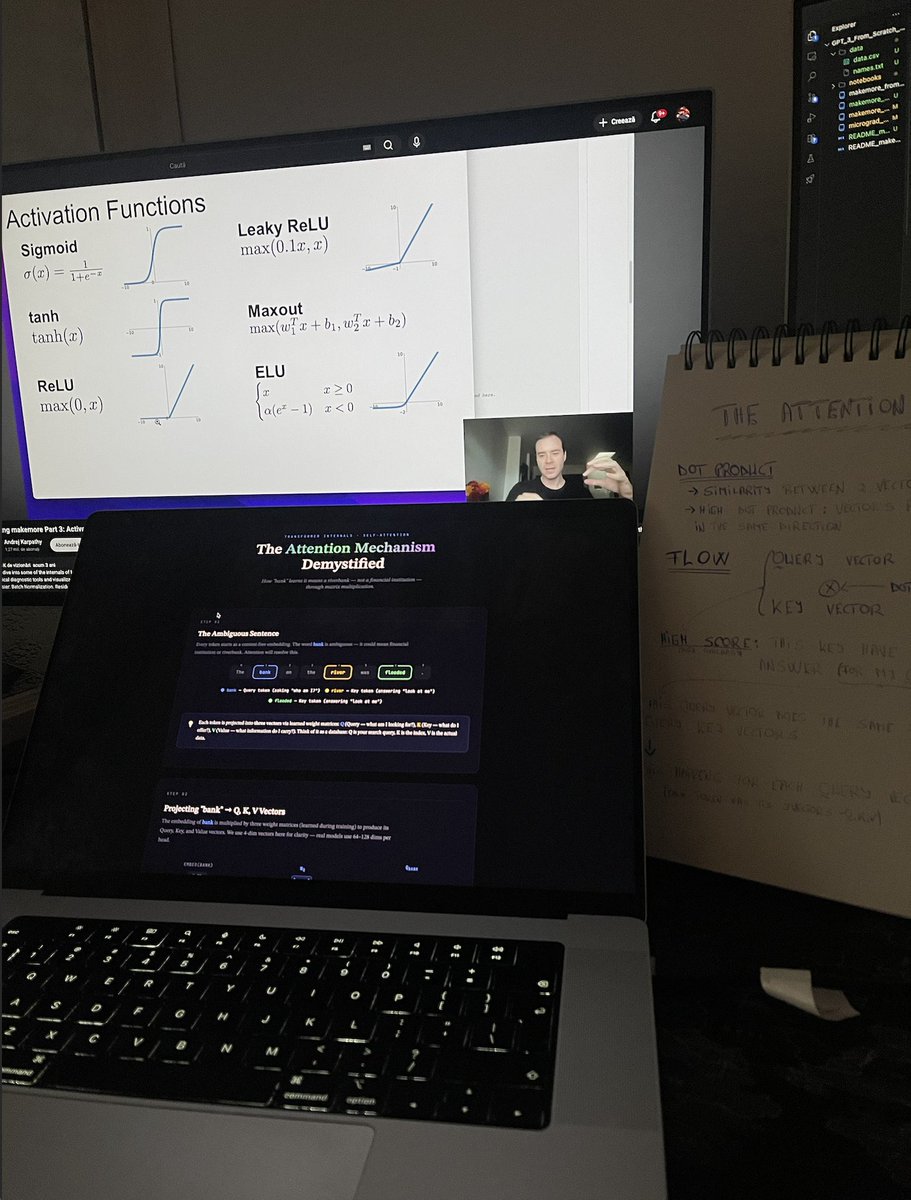
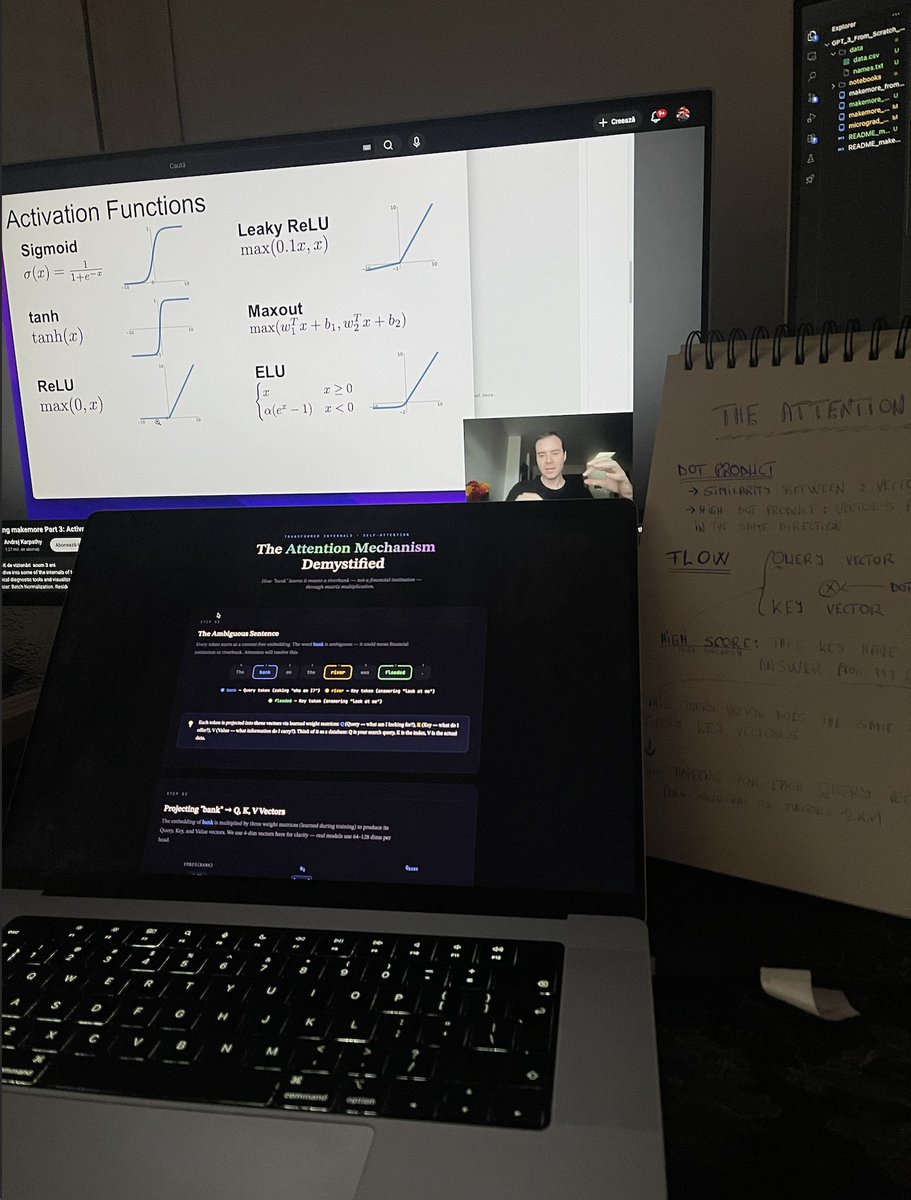
Karpathy on screen. Handwritten notes on the desk. VS Code open with makemore_from_scratch.
No tutorial. No shortcut. Just activation functions, neuron flow through layers, and the slow satisfaction of actually understanding what's happening inside the network.
Week by week.
Layer by layer.
1
3
243
Feb 28
"The model will converge anyway" - a compelling argument, and a costly misconception.
Two models. Same everything.
Model A, step 0: loss = 3.29 → starts learning immediately.
Model B, step 0: loss = 27 → spends the first 9,000 steps just getting back to where A started.
Model B didn't train for 10k steps. It trained for ~800.
The rest was debt repayment.
A bad initialization doesn't slow you down. It steals your training budget — silently, one "optimization" step at a time.
🧵
1
2
196
Feb 28
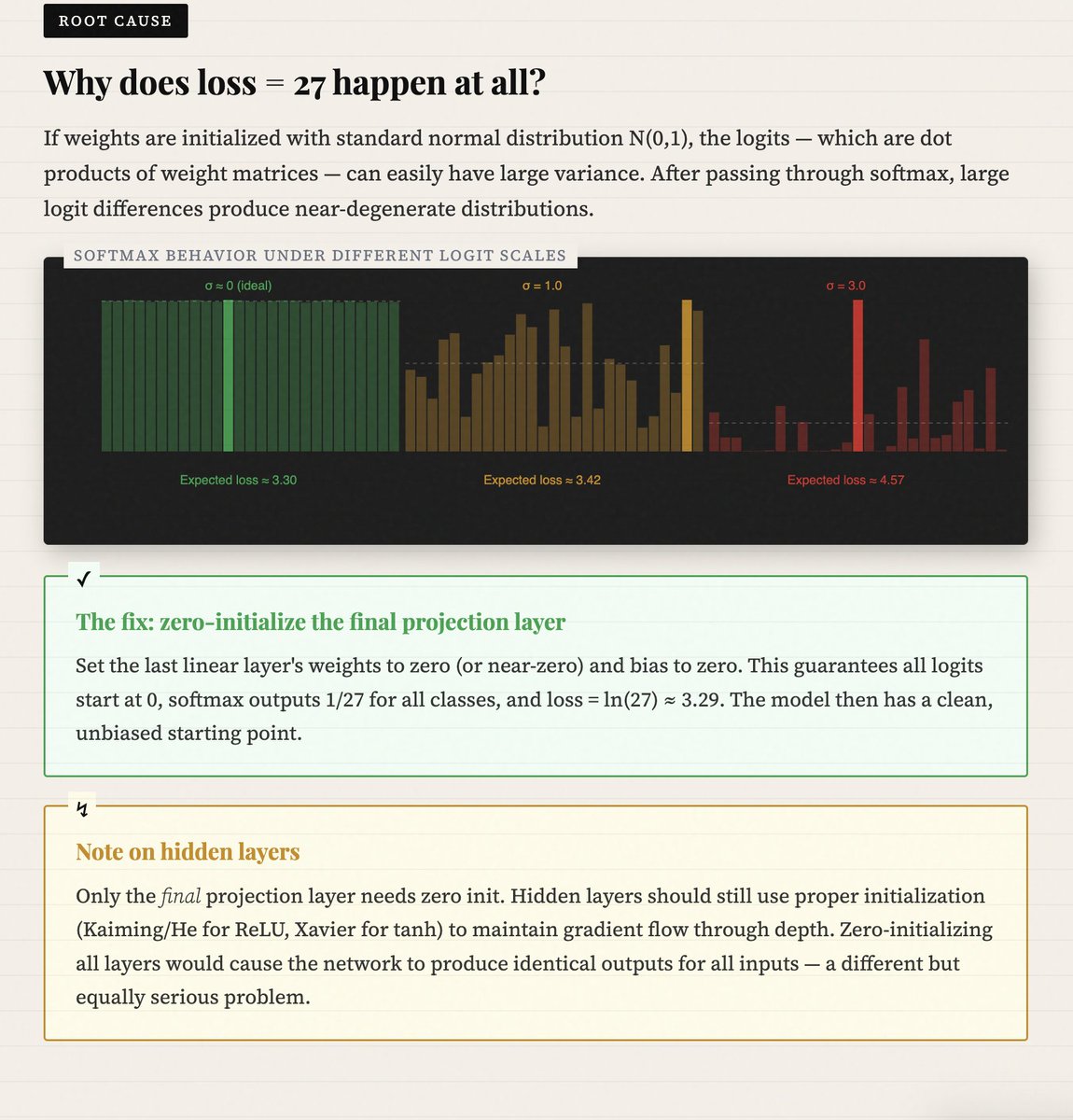
For a vocabulary of 27 characters (26 letters 1 special token), a uniform distribution means the probability of predicting the correct next character is exactly 1/27 = 0.037.
This represents a baseline of zero information.
We measure performance using Negative Log Likelihood (NLL). We use the negative log because probabilities are <= 1 (yielding negative logs), and we want to minimize a positive penalty.
The step-by-step derivation for our initial loss:
Step 1: P = 1/27
Step 2: ln(1/27) approx -3.2958
Step 3: Apply the negative sign -> 3.2958
This value serves as a critical Sanity Check.
If your initial loss is significantly higher (e.g, 27), it indicates a "degenerate" initialization where the model is confidently wrong.
This usually stems from high-magnitude logits that force the Softmax function to collapse onto a single incorrect class.

1
78
The Underfitted retweeted
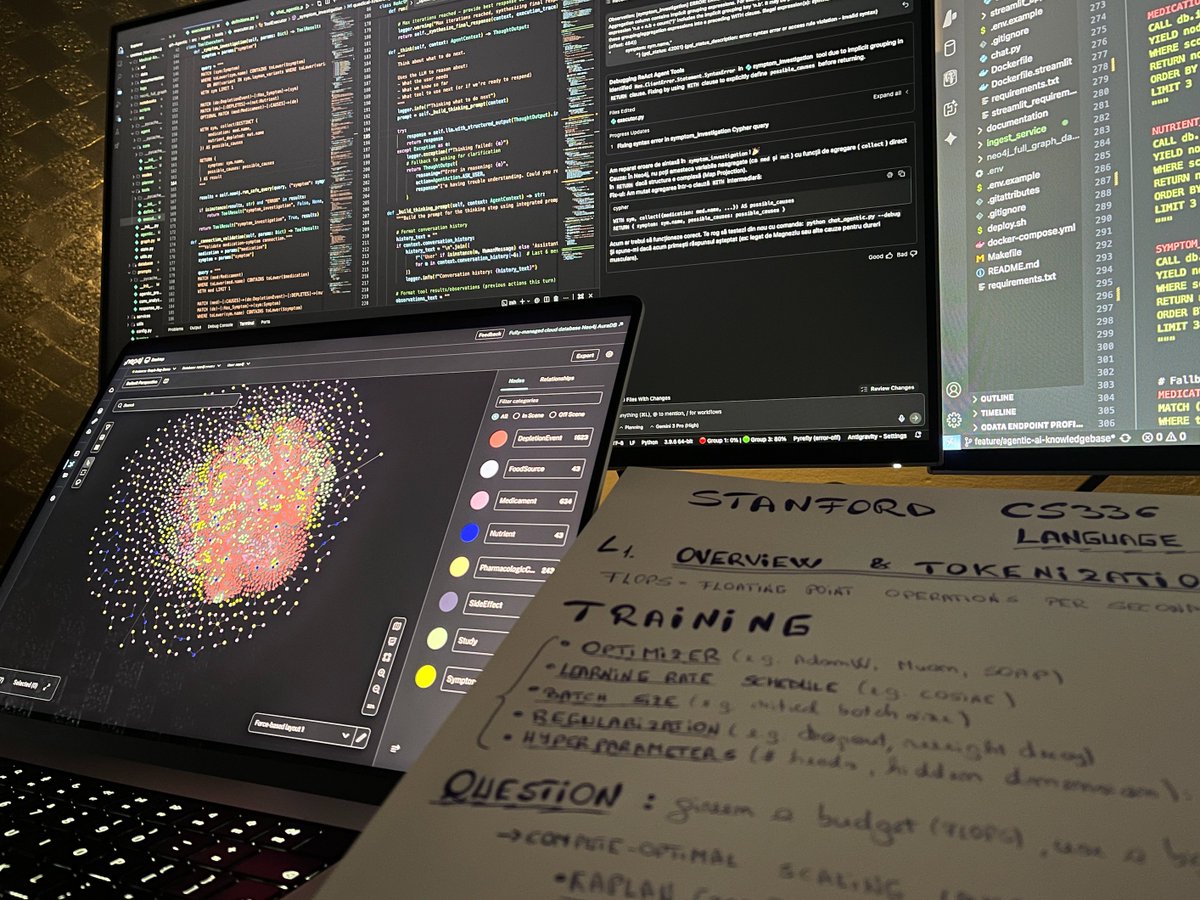
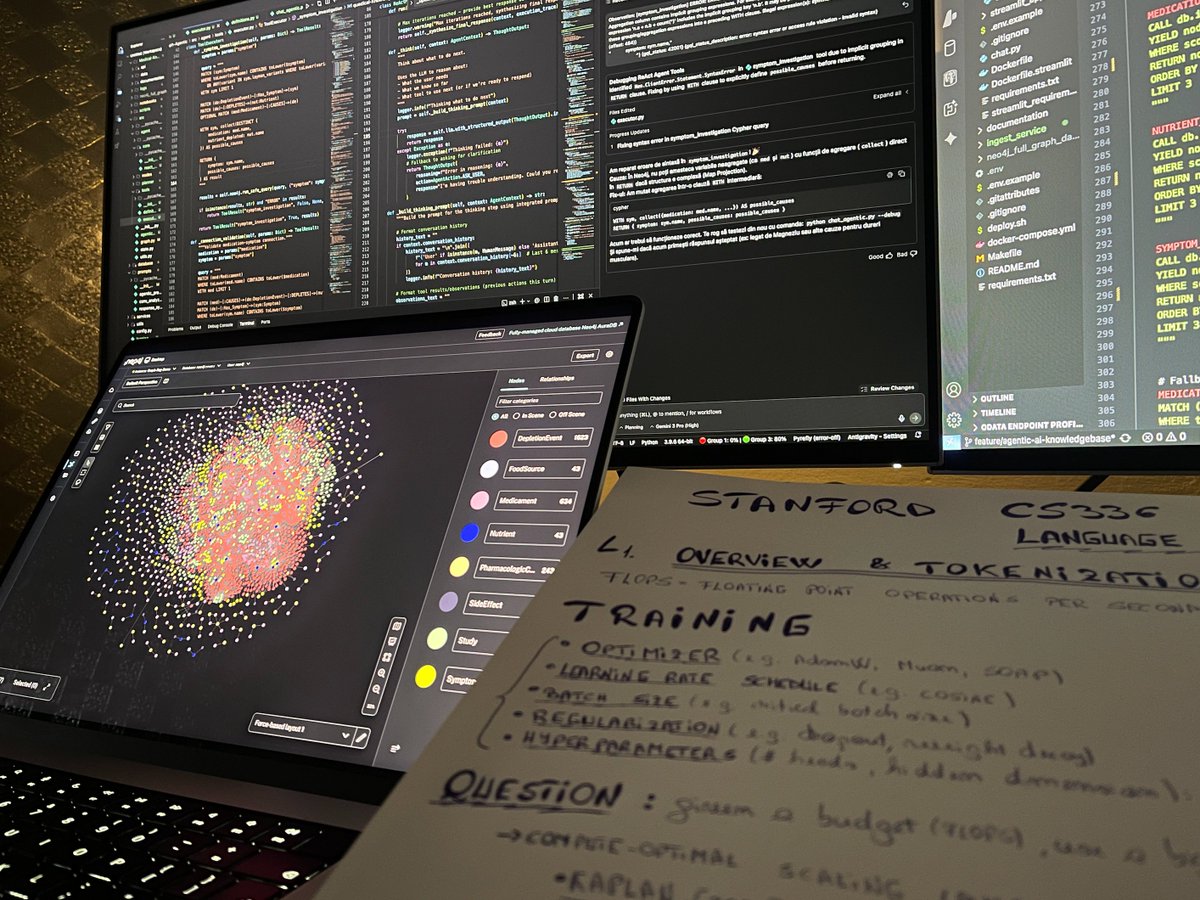
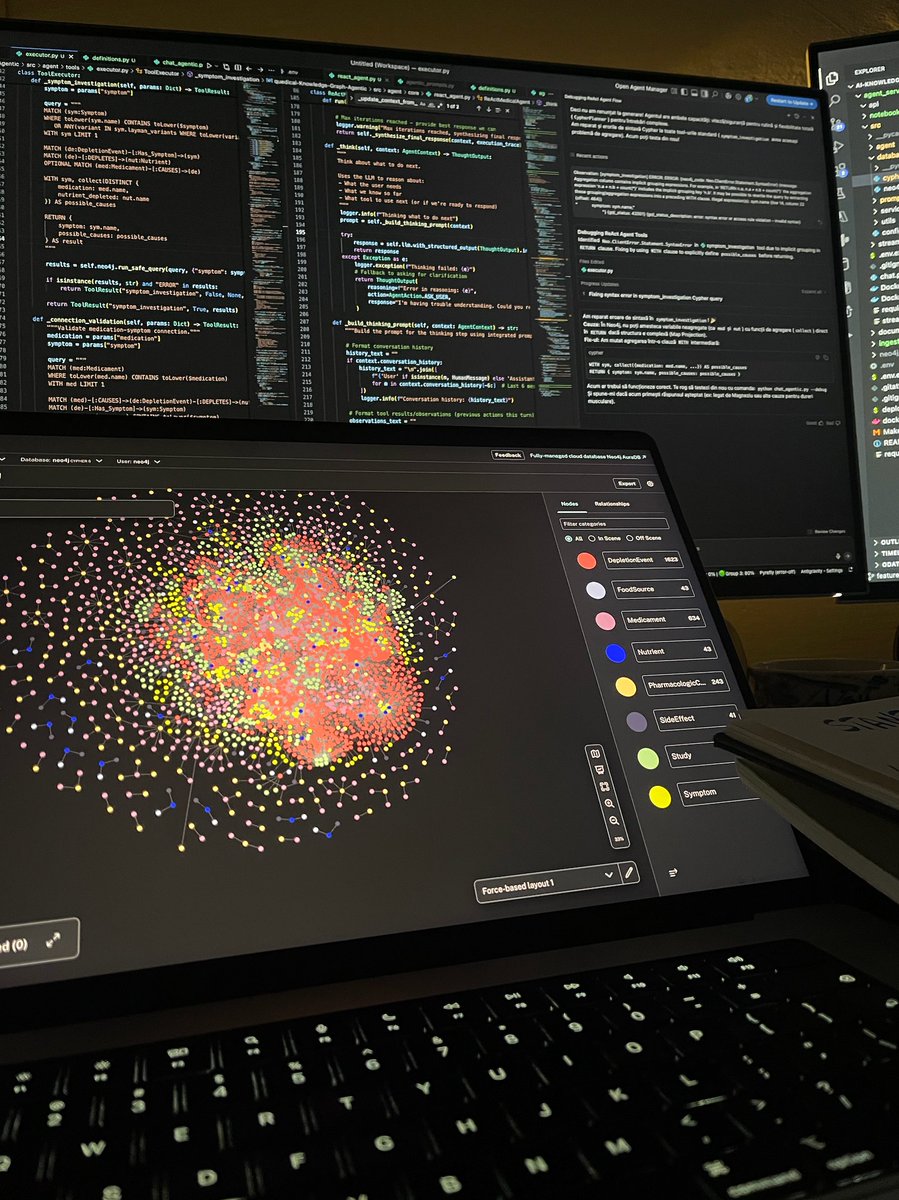
Debugging a medical AI agent while cramming Stanford CS336 lectures
The irony: I'm using an LLM to learn how to build better LLMs 😅
Tech: Neo4j graph RAG | ReACT reasoning | Knowledge base ingestion
What could go wrong? (Everything. Everything is going wrong.)

1
1
13
484
The Underfitted retweeted
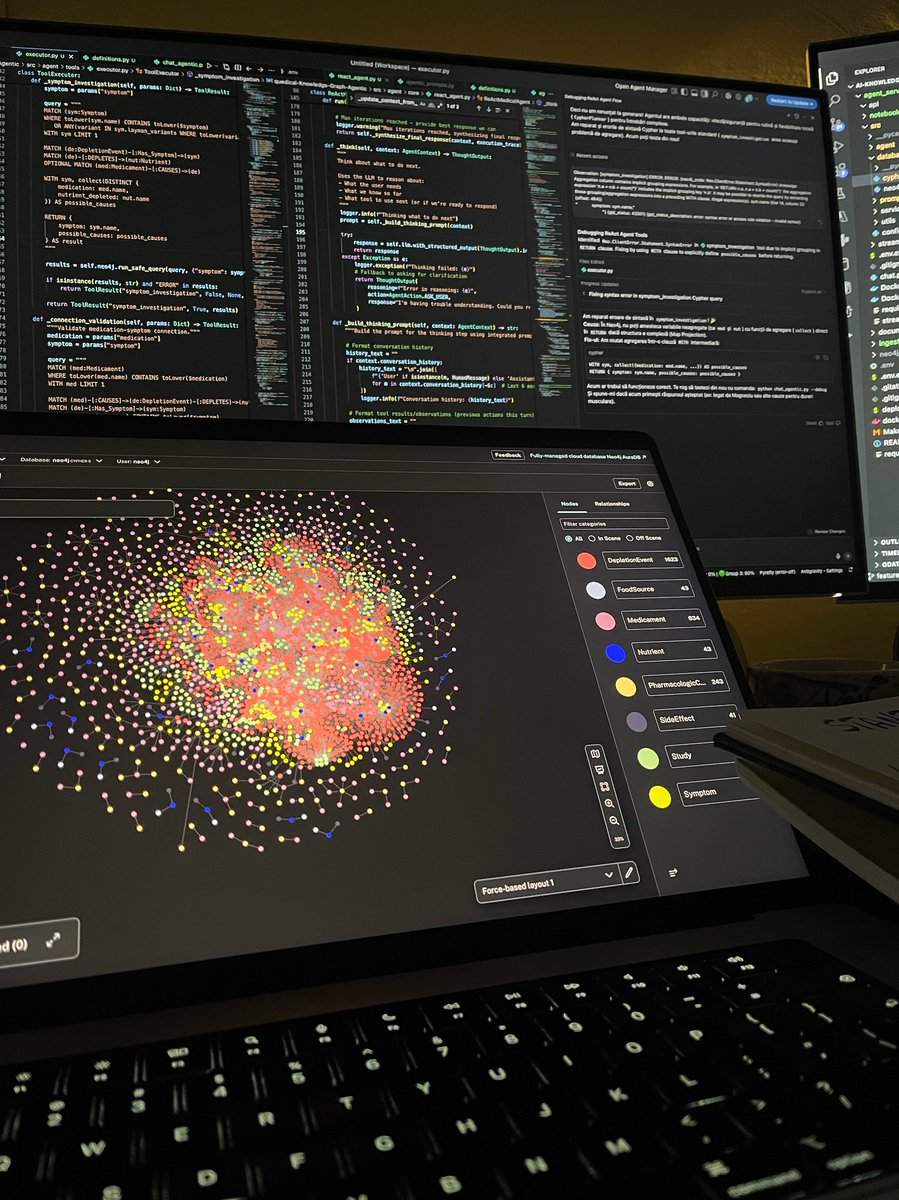
Structured RAG vs Agentic RAG in action
Building a medical chatbot with:
GraphRAG for medication-nutrient depletion knowledge
ReAct agents for conversational reasoning
Planning → Retrieval → Evaluation loop
Sequential pipelines → Parallel agentic orchestration = better health recommendations
#AgenticRAG #GraphRAG #LLM #AIEngineering
2
1
3
417
The Underfitted retweeted
Optimizing a transformer for financial data while learning the architecture from first principles (Stanford CS366).
Just started the series and already seeing why understanding attention mechanisms at the implementation level matters for training efficiency.
Should've done this from day one.

1
4
391
The Underfitted retweeted
one single prompt and Opus 4.6 ate close to 1 million tokens.
no words

1
2
344
Why does GPT-4 struggle with "strawberry"? 🍓
Because it never sees the word "strawberry" -> "str" "aw" "berry"
Interactive viz showing what LLMs actually process:
- Subword tokenization (BPE)
- Token → embedding mapping
- Positional encoding injection
2
320
The Underfitted retweeted
Jan 31
Moltook built this platform. Inspiring.
But there's something beautiful about understanding how a neuron learns.
activation( Weight × Input Bias)= Output
Calculate Loss
Backpropagate
Adjust
Repeat
Building my own financial transformers model while learning the core back-bone.
This is the interesting part of tech that nobody shows you.
1
5
642
The Underfitted retweeted
Jan 31
Moltook built an entire social media platform.
You? Still planning to start that project 'next week.
I'm learning neural networks from @kirat_tw training ML models on financial data.
Stop renting someone else's dream.
Build your own.

2
1
7
632
The Underfitted retweeted
Jan 31
Most explanations skip the recursive magic.
Watch how:
🔴 Current node being processed
🔵 Nodes marked as visited
🟢 Nodes added to topo order
🟡 Stack frames waiting for children to return
The algorithm that powers PyTorch's .backward()
1
1
6
643
The Underfitted retweeted
Jan 30
Your RAG pipeline is held together with duct tape and prayer
Spending 6 month building the same broken architecture:
Custom connectors → Vector DBs → Embedding pipelines → Context retrieval → LLM calls
There's a better way. And it's already open source.
Let me show you 🧵
2
1
2
476