
Infinitely curious. “Spend each day trying to be a little wiser than you were when you woke up.” - Charlie Munger
Joined June 2019
- Tweets 6,818
- Following 1,752
- Followers 15,746
- Likes 17,578
914 Photos and videos







SouthernValue retweeted

1,352
2,611
14,136
16,020,069
Can we get a @borrowed_ideas and @evrgn11112231 podcast or spaces to discuss $META state of affairs? New regulation, AI model delays, internal chaos, tokenmaxxing then unmaxxing, agentic business prospects, Neocloud prospects (and willingness / timing) … lots to discuss.
4
2
49
7,389
What a week. The most dynamic business and market environment of my lifetime.
1
16
3,104

May 24
Spacex aimed for Mars and became a Neocloud. At least should be a very profitable one.
If Terafab aims for TSMC and NVDA can it at least help end the DRAM shortage?
7
1
44
9,589
Yes, yes Elon.
Predicting eventual spinoff of $USMC (US Memory Corporation).
Jun 5

Elon Musk on Terafab:
"It's worth noting that there's not a single high volume computer memory fab in America right now, zero. There's one being built by Micron, but that will not reach volume production until I believe 2028 and there's something built in New York, but they are in, I think, 2029 and 2030, and this is a tiny fraction of the memory that's needed, and in fact, even if you take the best case assumptions of the memory makers and the logic makers, it is not enough to meet the demand that is anticipated, which is why you're seeing stocks of like Micron go to, I think, 1.2 trillion, or some quite high number, so there's just clearly a need for AI logic memory and packaging, AI computers, essentially, that is far beyond what even the best case assumptions of the existing fabricators can do, and that's why we need to do the Terafab. It seems essential, otherwise we will not, there will not be enough chips."
1
14
34,199
$SPCX IR now saying Terafab will start with memory bc that’s where the shortage is.
3
1,600
$MU is generating ~50% returns on capital which continue to go higher. Which is why none of the memory cabal wants to increase supply faster than demand and ruin the party.
Why couldn’t @elonmusk and Spacex/Terafab raise $100B from the U.S. Govt, $NVDA $AVGO $GOOG to build commodity NAND an DRAM, and in return for a 5yr LTA that guarantees a return of capital and mid-30s ROICs if they achieve competitive technology and yields, deliver deflation to memory prices, reduce the memory bottleneck, and bring more semiconductor mfg to the US?

Yes, yes Elon.
Predicting eventual spinoff of $USMC (US Memory Corporation).
21
2
81
28,811
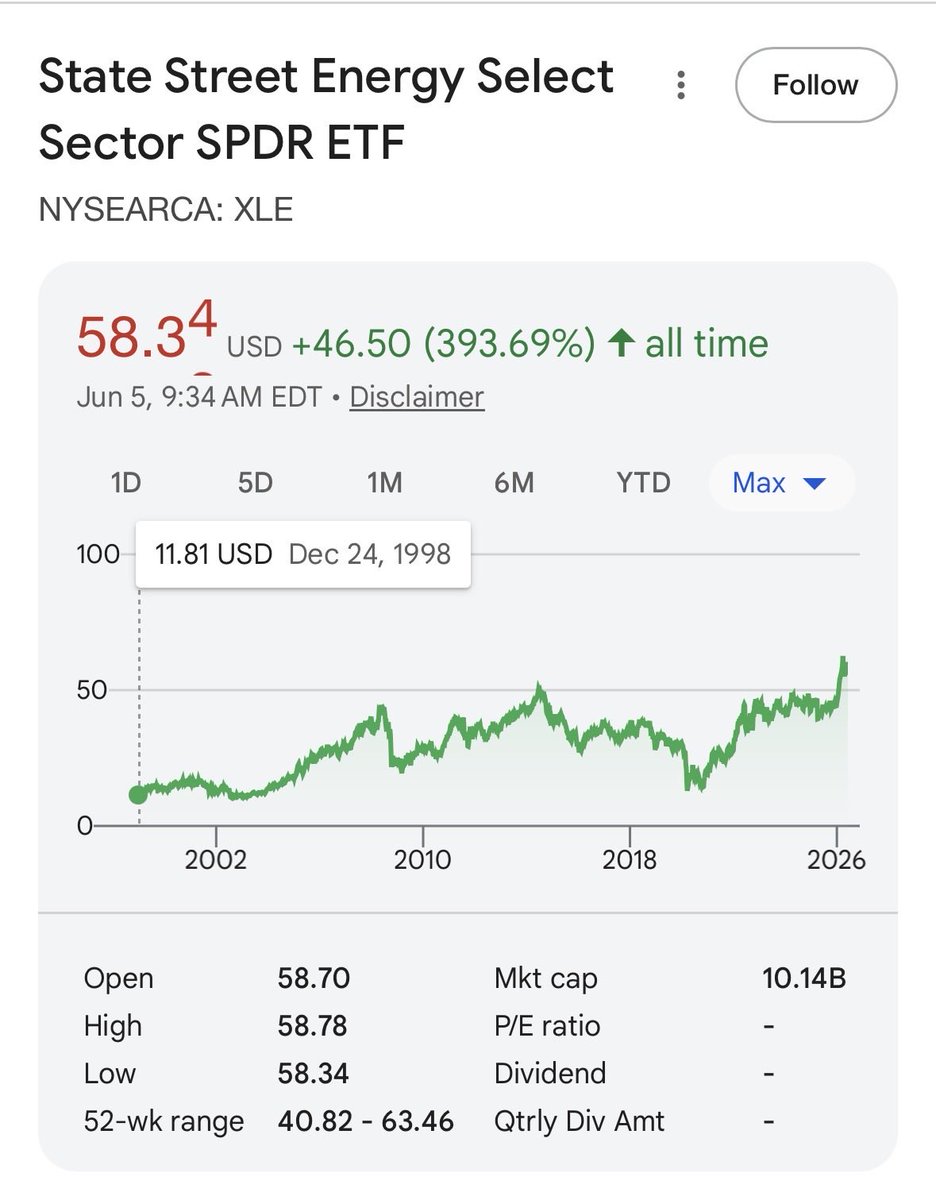
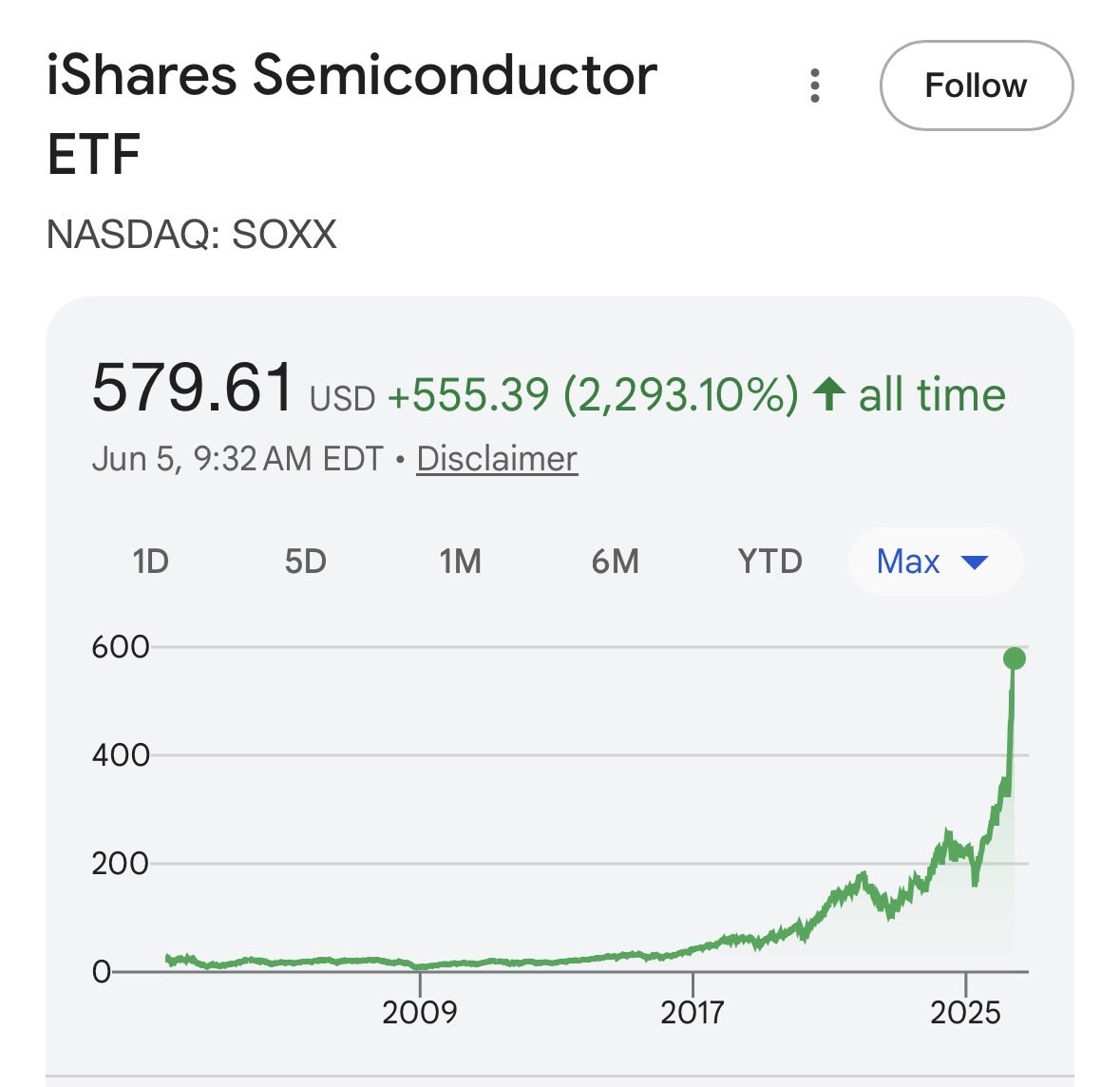
Wild how much this mkt is just becoming semis and everything else.
4
23
4,782
May 12
Last week $TEAM outlined a new AI bull case for SaaS, as a source of context to generate better, faster, cheaper AI outcomes.
Atlassian demod how Claude Code by itself underperformed an identical instance of Claude Code, on an identical prompt, when the other instance had access to their Teamwork Graph (TWG) which has access to past project files, messages, documents, code bases, employee data, and system integrations (slack, outlook, etc).
The added context pointed Claude to the right information to solve the task faster, whereas the instance without context thought more, read more, hallucinated, and got the task incorrect after spending 2x more tokens and running an extra minute.
Since token spend is quickly becoming many multiples of traditional software cost for coding use cases (Jira at $10-12/seat vs Anthropic spend per seat in the several hundreds a month), Atlassian makes a compelling case that context pays for itself many times over by helping customers to get more value out of their expensive AI tokens.
$MSFT easily has the strongest advantage as a source of differentiated context.
Video worth watching.
7
9
141
31,053
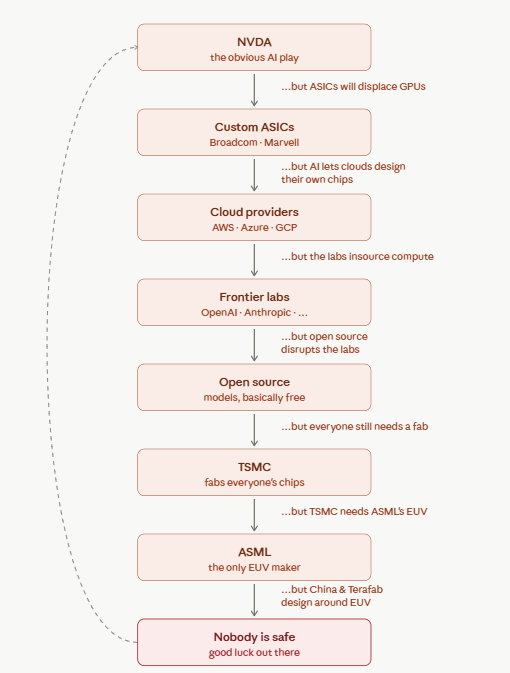
Y Combinator CEO Garry Tan: it’s best for consumers if model capabilities commodify, the moat is the harness.

Model routing is an important thing
Controversial idea: the frontier labs will want their AI harness to be the moat, but ultimately the best case for consumers is that model capabilities flatten and commodify
Preview of the AI Harness Wars of 2027
1
1
2,434
Harvey on splitting work between coordinating Frontier models and more efficient small models.

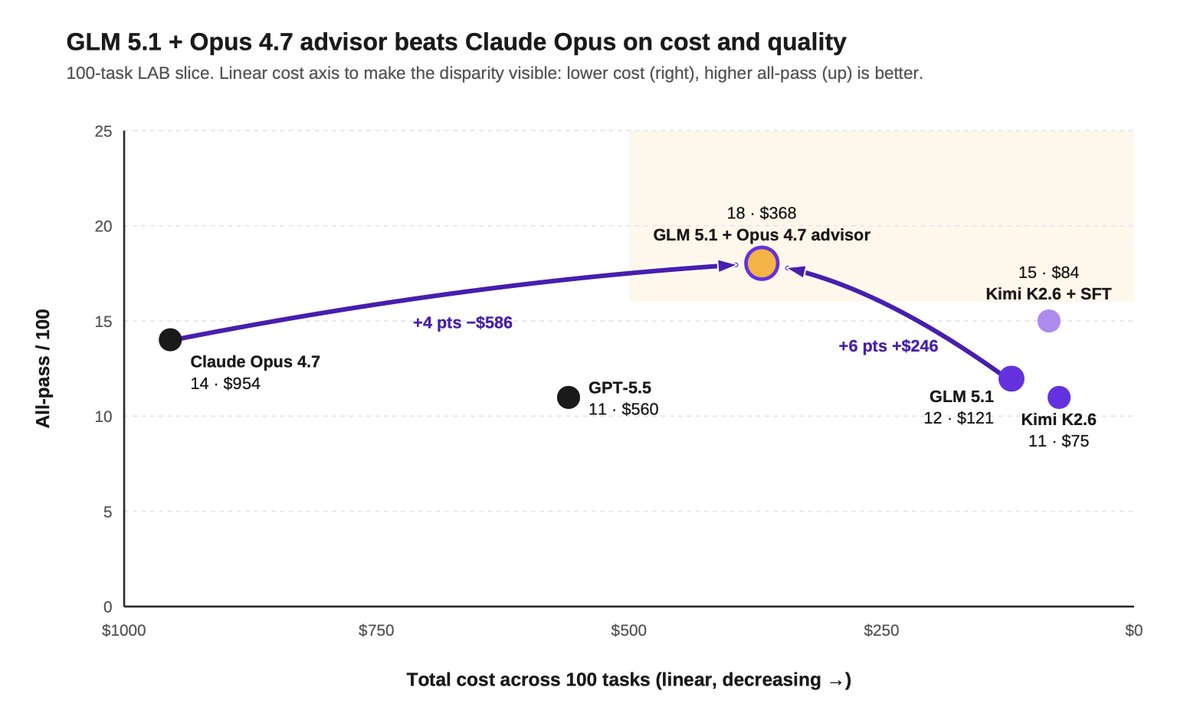
We partnered with @FireworksAI_HQ to train open-source models for legal. Here's what we found:
1) Hybrid legal agents can beat frontier models on quality and cost by routing selectively to a frontier advisor.
We tested a hybrid setup where GLM 5.1 served as the primary worker, routing tasks to Opus 4.7 as an advisor when needed.
GLM invoked Opus sparingly, just 0.83 times per task on average.
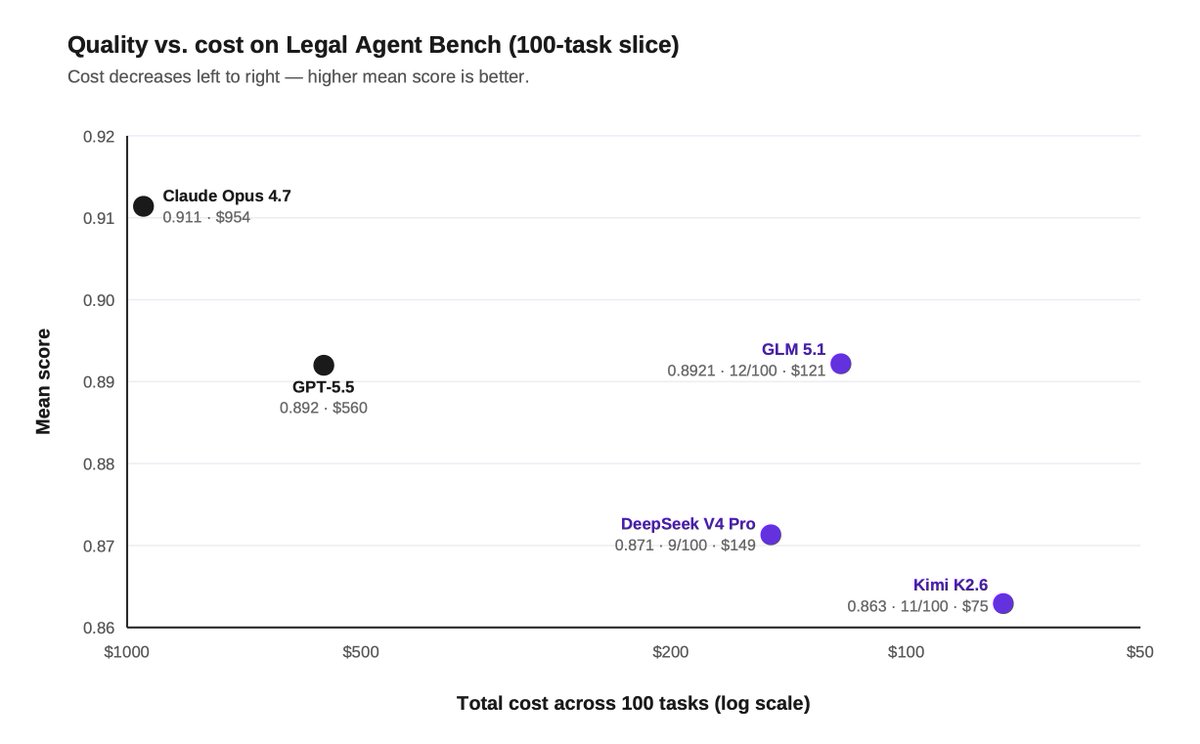
The hybrid setup beat Opus on both quality and cost: 18% all-pass vs 14%, at $368 vs $954 across the same 100 tasks.
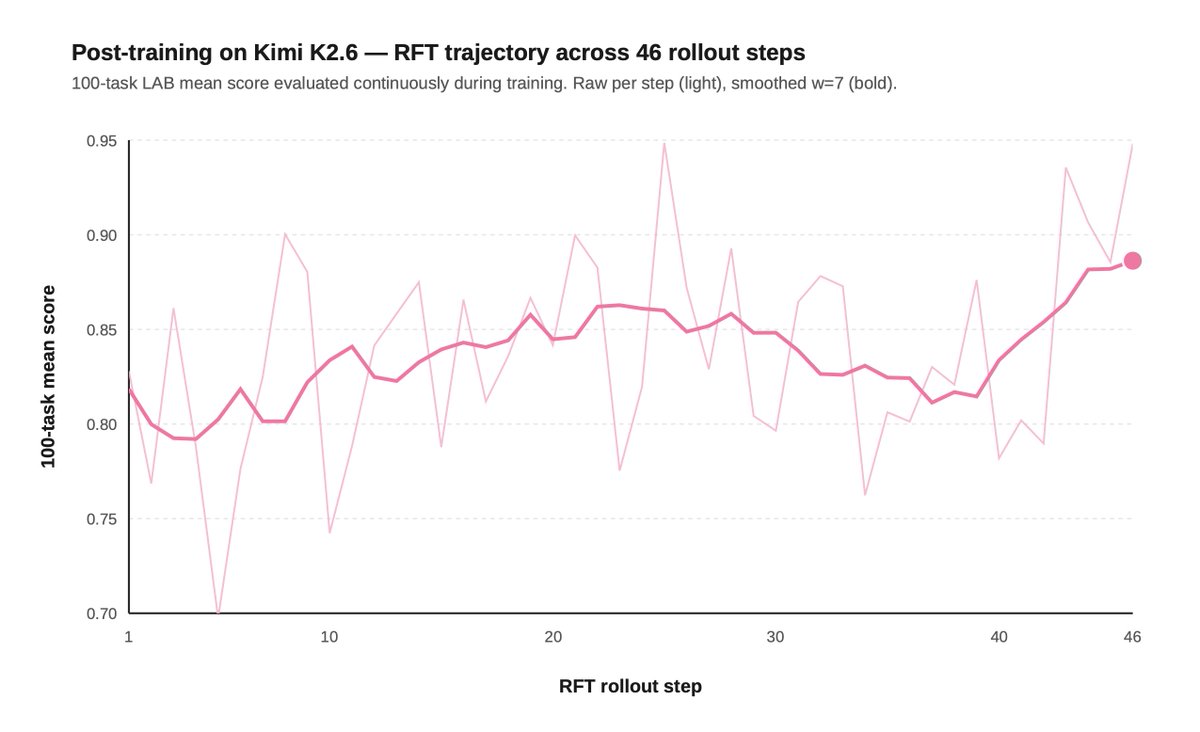
2) Post-training can push open models to frontier-level legal performance.
On a 100-task slice of our Legal Agent Benchmark (LAB), SFT moved Kimi 2.6's all-pass rate from 11% to 15%, beating Opus' 14%.
But the cost gap was even more striking: $84 vs $954 across the same 100 tasks, or ~11x cheaper.
We're excited to continue working with @FireworksAI_HQ on the next generation of open-source legal agents.
1
1
9
2,196
SouthernValue retweeted
$MSFT released a "Frontier Tuning" feature allowing users to fine-tune smaller models to perform at frontier levels, with significantly lower cost. A customer first uses a frontier model such as GPT 5.4 to complete a workflow, while MSFT WorkIQ (or Foundry?) captures traces of GPT completing the task (i.e., which apps it opens, how it responds to different inputs, etc). Frontier Tuning then "teaches" a smaller model how to complete the task by using the trace data, and tunes the model weights model to that workflow and environment. The customer then swaps out the frontier model for the smaller model to get comparable workflow performance at a much lower cost. This is effectively what Cursor did with composer to deliver frontier coding capabilities with much less training and inference cost, what $MSFT and $SNOW are doing with agents working inside their platform, and now MSFT is giving enterprises the ability to do the same.
learn.microsoft.com/en-us/mi…
1
4
40
6,804
SouthernValue retweeted

Goldman Sachs' Jim Covello Now Favors Hyperscalers Over Semiconductors:
Covello lays out three forward scenarios, two of which favor hyperscalers:
1) Enterprises start making money on AI, hyperscalers outperform
2) Hyperscalers moderate capex, hyperscalers outperform
3) Status quo persists, semis keep outperforming
3
8
59
12,624
18
32
893
79,809
🎲🎲


15
4,610
Need a @ChrisBloomstran take on Berkshire funding $GOOG capex and buying it at ATHs
Jun 1

Wow, Berkshire Hathaway investing $10 billion into $GOOGL in a private placement as part of a broader $80 billion equity capital raise by the company to expand its AI infrastructure

14
7
150
63,423
May 31
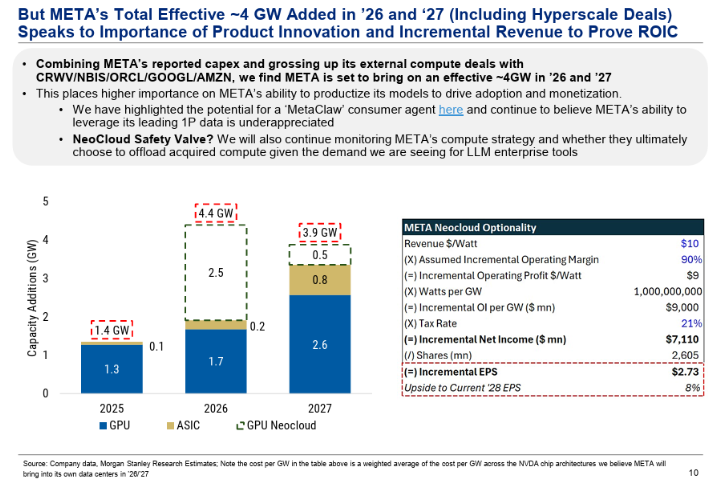
1) $META appears to have the most incremental GW coming online of any AI lab in 2026, and including Neocloud capacity may be ahead of the ~6GW @dylan522p predicted @OpenAI and @AnthropicAI would have by EoY '26 on the @dwarkesh_sp pod (since then Ant has added @xai sublease to help close the 1GW compute gap w/ OAI)
2) MTEA potentially has less incremental inference demand competing for incremental capacity, without an exploding agent business (yet?)
Based on the above, $META may have a training capacity advantage later this year, right as its new MSL team is beginning to put out good work.
Is it crazy $META becomes a legitimate frontier challenger in the next 12mo?
16
36
391
47,739
$META Alex Wang on Muse Spark and future larger models: it was a good model, we didn’t expect it to be frontier, it demonstrates our new stack is delivering “predictable scaling” in pre-training, RL, test-time, and multi-agent scaling efforts. We are cooking larger models that we are much more excited about.
2
2
31
5,274
Q: what do you need to catch up to the frontier?
A: the one-word answer is just scaling. Muse Spark is early on the ladder and we have very strong predictability, we know if we scale this model up what performance to expect from that increased model size. And we expect upcoming models to perform much better across the board, to be released in the coming months. We are in fast scaling mode.
Q: what are you doing different than everyone else?
A: we think a lot of Muse performance being better than expected is having ability to rebuilt everything in the stack from scratch the right way. A clean pre train stack, a clean RL stack, do everything the right way by the experts who understand these systems.
A: Muse can achieve similar results with many fewer tokens than leading models, which is a testament to this clean stack. Other models may need more tokens bc of inefficiency at some level of the stack causing it to need to thing longer.
*If this is right, quite bearish for frontier labs*
But clearly still in build credibility stage. Hard to take at face value.
12
2,119
Jensen pounds table on this point for the 1,000th time.

33
4,814