
Joined May 2009
- Tweets 15,211
- Following 1,288
- Followers 1,965
- Likes 7,039
360 Photos and videos
















Sumit Kumar Singh retweeted

Mar 30
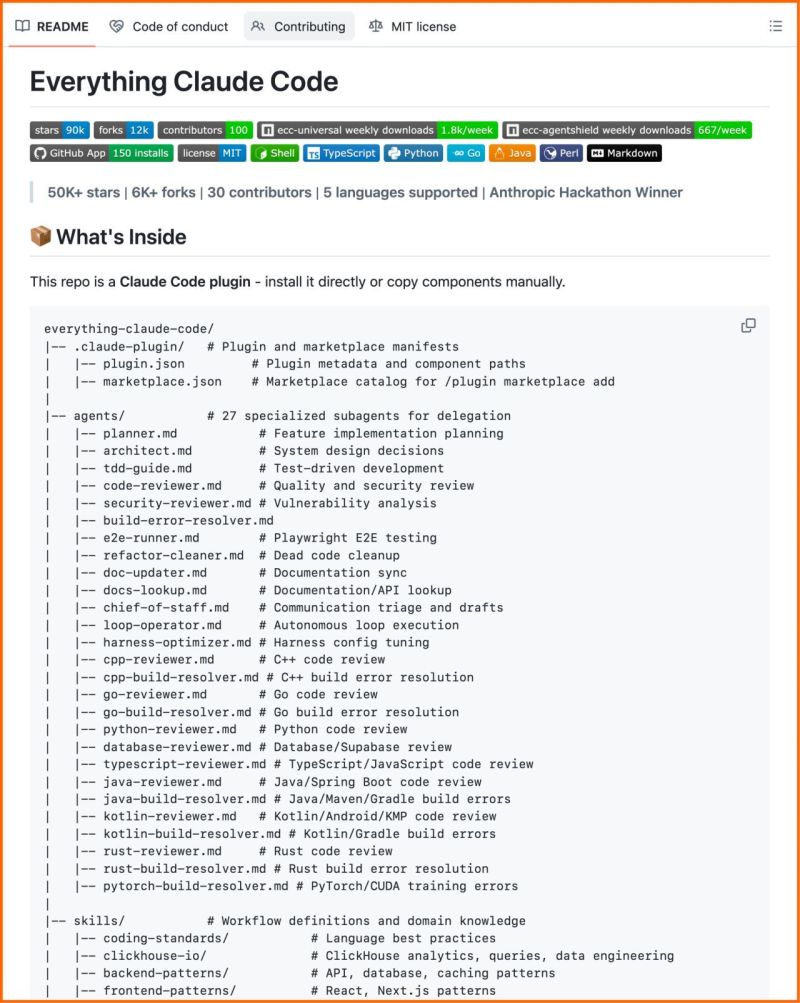
This is the most complete Claude Code setup that exists right now.
27 agents. 64 skills. 33 commands. All open source.
The Anthropic hackathon winner open-sourced his entire system, refined over 10 months of building real products.
What's inside:
→ 27 agents (plan, review, fix builds, security audits)
→ 64 skills (TDD, token optimization, memory persistence)
→ 33 commands (/plan, /tdd, /security-scan, /refactor-clean)
→ AgentShield: 1,282 security tests, 98% coverage
60% documented cost reduction.
Works on Claude Code, Cursor, OpenCode, Codex CLI. 100% open source.
179
845
6,950
634,125
Sumit Kumar Singh retweeted

Feb 19
Had a fantastic time last evening with my old friends, colleagues & AI founders. Thanks for making the evening more engaging, insightful & memorable. With @veermishra0803 @harshamv @Sumitks @lorsophy1 #IndiaAIImpactSummit2026


1
2
11
305
Sumit Kumar Singh retweeted

Feb 24
This 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 file will make you 10x engineer 👇
It combines all the best practices shared by Claude Code creator:
Boris Cherny (creator of Claude Code at Anthropic) shared on X internal best practices and workflows he and his team actually use with Claude Code daily. Someone turned those threads into a structured 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 you can drop into any project.
It includes:
• Workflow orchestration
• Subagent strategy
• Self-improvement loop
• Verification before done
• Autonomous bug fixing
• Core principles
To get the full version of this :
1. Follow me (so that I can dm you)
2. Comment "Claude".
3. Like and save this post.

205
106
647
48,115
Sumit Kumar Singh retweeted

Feb 21
Hear from Revathi, Co-Founder at Garage Labs Technologies, as they reflect on their Day 1 experience at Synapse 2026.
#SYNAPSE2026 #Synapse #OriginalThinking
1
3
100

Feb 21
Celebrating friendship and 2 exits! @subratkar you are amazing! So much fun hosting this with you.
Feb 19

Had a fantastic time last evening with my old friends, colleagues & AI founders. Thanks for making the evening more engaging, insightful & memorable. With @veermishra0803 @harshamv @Sumitks @lorsophy1 #IndiaAIImpactSummit2026
1
49
Sumit Kumar Singh retweeted

Feb 15
DEEPSEEK V4 COMING ON 17TH FEB: We can now confirm that DeepSeek V4 is likely to be released on 17th Feb. We have released a detailed report on what this means for Claude, GPT, Chinese AI ecosystem & above all cost optimisation of practical AI:
macro-spectrum.com/opinion/d…
1. The latest V4 model will be incorporating the company's newly published Engram memory architecture and targeting performance that internal benchmarks suggest surpasses both Claude and GPT in code generation tasks.
2. The timing mirrors DeepSeek's R1 launch strategy. That release triggered a $1 trillion tech stock selloff on January 27, 2025, including $600 billion from NVIDIA alone. DeepSeek leverages the Lunar New Year period for maximum visibility in both Chinese and international markets.
3. Currently China’s newest models still lag the global frontier (represented by Google, OpenAI, and Anthropic) on broad capability and consistency. But DeepSeek V4 might be the turning of the tide. The re-rating of Chinese AI would be less about national pride and more about economics: higher willingness to pay, higher retention in API workloads, and improved global developer pull for open ecosystems.
4. DeepSeek’s latest paper (‘Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models’, Jan 12, 2026) proposes adding conditional memory as a second sparsity axis alongside conditional compute (MoE). The core idea is an ‘Engram’ module that performs a lookup for certain local/static patterns, so the transformer does less ‘reconstruction’ through dense compute, paired with an explicit ‘Sparsity Allocation’ framing for how to split capacity between compute (experts) and memory.
5. This implies high quality gains without brute computer force step up as well as a credible path to inference gains via computer memory trade offs.
6. So how does the Engram model works in lay man terms. Traditional Transformers force models to store factual knowledge within reasoning layers, creating computational inefficiency. Engram offloads static memory to a scalable lookup system.
7. People with direct knowledge of the project claim V4 outperforms both Anthropic's Claude and OpenAI's GPT series in internal benchmarks, particularly when handling extremely long code prompts. Cost wise, V4 might be much economical than Claude Opus 4.5 & GPT 5.2.
8. We believe DeepSeek V4 release next week might be a game changer for current US AI supremacy. The Engram architecture offers potential path to efficient long-context processing. The self-hosting options in V4 might address data sovereignty concerns. V4 might revolutionalise coding, developer productivity & cost-effective AI deployment.
9. In nutshell, it is small AI with more power. DeepSeek V4 might show a practical blueprint for large scale AI development outside the U.S. ecosystem.
2
3
941
Sumit Kumar Singh retweeted

Feb 11
Anthropic released 32-page guide on building Claude Skills
here's the Full Breakdown ( in <350 words )
1/ Claude Skills
> A skill is a folder with instructions that teaches Claude how to handle specific tasks once, then benefit forever.
> Think of it like this: MCP gives Claude access to your tools (Notion, Linear, Figma).
> Skills teach Claude how to use those tools the way your team actually works.
The guide breaks down into 3 core use cases:
1/ Document Creation
Create consistent output (presentations, code, designs) following your exact standards without re-explaining style guides every time.
2/ Workflow Automation
Multi-step processes that need consistent methodology. Example: sprint planning that fetches project status, analyzes velocity, suggests priorities, creates tasks automatically.
3/ MCP Enhancement
Layer expertise onto tool access. Your skill knows the workflows, catches errors, applies domain knowledge your team has built over years.
The technical setup is simpler than you'd think:
1/Required: One SKILL.md file with YAML frontmatter
Optional: Scripts, reference docs, templates
2/The YAML frontmatter is critical. It tells Claude when to load your skill without burning tokens on irrelevant context.
Two fields matter most:
- name (kebab-case, no spaces)
- description (what it does when to trigger)
Get the description wrong and your skill never loads. Get it right and Claude knows exactly when you need it.
The guide includes 5 proven patterns:
1/ Sequential Workflow:
> Step-by-step processes in specific order (onboarding, deployment, compliance checks)
2/ Multi-MCP Coordination:
> Workflows spanning multiple services (design handoff from Figma to Linear to Slack)
3/ Iterative Refinement:
> Output that improves through validation loops (report generation with quality checks)
4/ Context-Aware Selection:
> Same outcome, different tools based on file type, size, or context
5/ Domain Intelligence:
> Embedded expertise beyond tool access (financial compliance rules, security protocols)
Common mistakes to avoid:
>. Vague descriptions that never trigger
> Instructions buried in verbose content
> Missing error handling for MCP calls
> Trying to do too much in one skill
The underlying insight:
> AI doesn't need to be general-purpose every conversation.
> Give it specialized knowledge for your specific workflows and it becomes genuinely useful for work.

63
428
3,863
482,344
Jan 21
Focus beats ambition.
At Garage Labs, we made a deliberate choice: own one thing completely instead of trying everything.
When you prioritize ruthlessly, you win more. Your team moves faster. Customers get better products.
#ProductStrategy #StartupLessons #Focus
18
Jan 21
🚀 Antigravity meets AI.
Learn how AI can simulate impossible scenarios. No coding needed.
Join our Jan 26 cohort:
garagelabstech.com/course/ap…
#AI #Antigravity
1
34
Jan 19
Built Garage Labs. The biggest lesson? Obstacles aren't roadblocks—they're the actual product.
Turned a failed feature into our pivot. Turned a difficult mindset into our advantage.
The challenge IS the path forward.
#StartupLessons #FounderJourney
23
Jan 17
The only global hands-on course for non-tech folks who wants to learn AI.
Register here: garagelabstech.com/course/ap…
Check the site for more courses garagelabstech.com
#AIcourse #LearnAI #AIforEveryone #AIPrograms #AceAI
53
Sumit Kumar Singh retweeted
28 Nov 2025
1
1
44
11 Sep 2025
The nano banana killer is here! Combine upto 6 images to bring your imagination to life! It event produces high resolution images upto 4K !
seedream4.co/
Follow the Aceai.club channel for more dope: bit.ly/3VcFQVI
87
Sumit Kumar Singh retweeted

21 Aug 2025
every programmer must listen to this 👏🏼
118
1,900
11,957
523,114
8 Aug 2025
123
29 Jul 2025
135
Sumit Kumar Singh retweeted

20 Jul 2025
Google has a new interview. Everyone's about to copy it.
But there are 3 variants already out there:

16
12
100
20,328