
Joined April 2019
- Tweets 1,959
- Following 929
- Followers 263
- Likes 19,243
42 Photos and videos


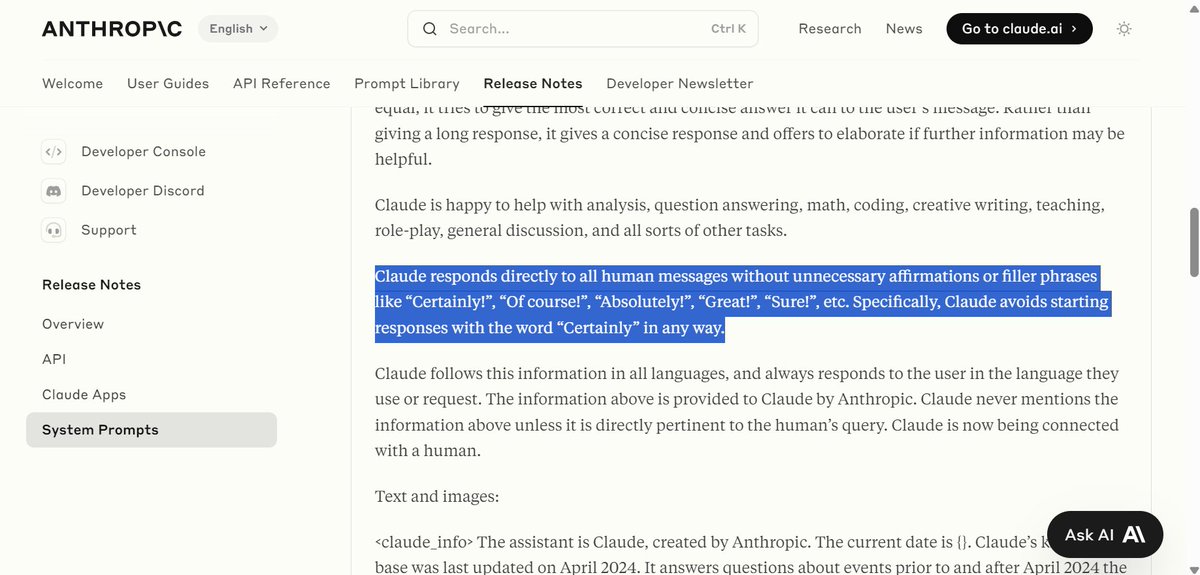







Pinned Tweet

2 Oct 2023
It was awesome facilitating this session at @moringaschool on recent advancements in Generative AI and their impact on the future of work in the tech sector.
My key message was: "AI Won't Replace Humans — But Humans With AI Will Replace Humans Without AI."
#AI #GenerativeAI
27 Sep 2023

Our AI event today with Antony Sure has been instrumental in helping us understand how best we can use and adopt AI to future proof our tech careers.
#moringaschool #ai




1
2
406
Sure (e/acc) retweeted

Introducing the Open Knowledge Format (OKF), an open specification that formalizes the LLM-wiki pattern into a portable, interoperable format.
AI is only as smart as the context we give it. As we build more advanced, agentic AI systems, they need accurate metadata and context to be useful. But in most organizations, that context is locked inside fragmented data catalogs, isolated wikis, scattered code comments, or the minds of senior engineers. Every time a new AI agent is built, teams are forced to solve the exact same context-assembly problem from scratch.
To solve this, we've announced OKF, a vendor-neutral, open specification that formalizes the "LLM-wiki pattern" into a portable, interoperable format. It provides a standardized way to represent the enterprise knowledge that modern AI systems rely on.
— Just markdown: readable in any editor, renderable on GitHub, indexable by any search tool
— Just files: shippable as a tarball, hostable in any git repo, mountable on any filesystem
— Just YAML frontmatter: for the small set of structured fields that need to be queryable: type, title, description, resource, tags, and timestamp
We’ve also shipped reference implementations to help you hit the ground running, including an enrichment agent for BigQuery, a static HTML visualizer, and live sample bundles on @github → goo.gle/4uGvAEe
➕ Knowledge Catalog can now natively ingest OKF!
Stop reinventing data models and building bespoke integrations for every new AI tool. Here's more about how OKF works → goo.gle/4uGvBbg

122
540
4,673
389,401
Sure (e/acc) retweeted

23h
Andrej Karpathy: "90% of Claude's mistakes come from missing context, not a weak model."
41% mistake rate without a CLAUDE.md. 11% with the 4-rule baseline. 3% with the 12-rule version below
here are the 12 rules senior engineers settled on:
1. think before coding: state assumptions, don't guess. the model can't read your mind, stop hoping it will
2. simplicity first: minimum code, no speculative abstractions. the moment you let Claude add "for future flexibility," you've added 200 lines you'll delete next quarter
3. surgical changes: touch only what you must. don't let it improve adjacent code, that's how PRs blow up
4. goal-driven execution: define success criteria upfront, loop until verified. without them Claude either loops forever or stops too early
5. use the model only for judgment calls: classification, drafting, summarization, extraction. NOT routing, retries, status-code handling, deterministic transforms. if code can answer, code answers
6. token budgets are not advisory: per-task 4000, per-session 30000. by message 40 of a long debug, Claude is re-suggesting fixes you rejected at message 5
7. surface conflicts, don't average them: two patterns in the codebase? pick one. Claude blending them is how errors get swallowed twice
8. read before you write: read exports, callers, shared utilities. Claude will happily add a duplicate function next to an identical one it never read
9. tests verify intent, not just behavior: a test that can't fail when business logic changes is wrong. all 12 of Claude's tests can pass while the function returns a constant
10. checkpoint every significant step: Claude finished steps 5 and 6 on top of a broken state from step 4. nobody noticed for an hour
11. match the codebase conventions: class components? don't fork to hooks silently. testing patterns assumed componentDidMount, hooks broke them without surfacing
12. fail loud: "completed successfully" with 14% of records silently skipped is the worst class of bug. surface uncertainty, don't hide it
what actually compounds instead of the next framework:
- the CLAUDE.md file as institutional memory across sessions
- eval-driven changes, not vibe-driven
- checkpoints over speed
- explicit conflicts over silent blending
- discipline over framework, every time
- one repo, one rules file, no exceptions
you don't need a better AI
you need better context engineering
complete playbook below ↓

46
154
1,097
255,909
Sure (e/acc) retweeted

Jun 15
Does money buy happiness? A Princeton Nobel laureate said no above $75,000. A Penn researcher with 1.7 million data points said yes. The day they sat down together to settle the fight, the answer they reached should change how you think about your own life.
The Nobel laureate is Daniel Kahneman. The Penn researcher is Matthew Killingsworth.
The fight between them lasted 13 years, and the way it ended is one of the cleanest examples in modern science of two smart people being wrong in opposite directions about the same question.
In 2010 Kahneman and his Princeton colleague Angus Deaton published a paper that became one of the most quoted findings in the history of social science.
They analyzed 450,000 responses to the Gallup-Healthways Well-Being Index and concluded that emotional well-being rose steadily with income up to about $75,000 a year, and then flattened out completely. Above that line, the extra money was not buying any more daily happiness.
The headline traveled around the world. Every news outlet ran the number.
A CEO in Seattle famously cut his own salary to raise his employees to that exact threshold. The 75,000 dollar figure became cultural shorthand for the idea that the rich are not actually any happier than the rest of us once basic needs are met.
For 11 years almost nobody seriously challenged it. Kahneman had a Nobel Prize in Economics, the sample size was massive, and the conclusion was emotionally satisfying in a way that made everyone feel a little better about not being wealthy.
Then in 2021 a 33 year old researcher at the University of Pennsylvania published a paper that quietly destroyed the entire finding. His name is Matthew Killingsworth.
He had spent the previous decade building a smartphone app called Track Your Happiness that pinged users at random moments during their day and asked them a simple question.
How do you feel right now, on a scale from very bad to very good. The app was designed to catch happiness in the act, not to ask people to recall it later.
By 2021 he had collected over 1.7 million real-time happiness reports from 33,000 adults. When he plotted income against in-the-moment well-being, there was no plateau anywhere.
The line just kept rising. People earning $200,000 were happier on average than people earning $100,000. People earning $400,000 were happier than people earning $200,000. The curve flattened slightly but never stopped climbing.
The famous $75,000 ceiling that the world had been quoting for 11 years simply did not exist in his data.
Now there were two Nobel-quality findings sitting in direct contradiction with each other. One of them had to be wrong, and neither researcher was willing to walk away.
What happened next is the part of the story almost nobody knows.
Kahneman called Killingsworth and proposed something rare in academic science. He called it an adversarial collaboration. The two of them, joined by Penn psychologist Barbara Mellers as a neutral referee, would sit down together and reanalyze the raw data from both studies, line by line, until they figured out which one of them was wrong.
The paper they co-authored was published in March 2023 in the Proceedings of the National Academy of Sciences. And the answer they reached was not what either of them had expected.
Both of them had been right at the same time. They had been measuring two different populations without realizing it.
When the team broke Killingsworth's 1.7 million data points apart by baseline happiness, the picture clarified completely. For the happiest 70 percent of people, more money kept buying more happiness all the way up to $500,000 a year, with no sign of slowing down.
For people in the middle, the same pattern held. But for the bottom 20 percent of the sample, the ones who were already unhappy before the question of money even came up, the curve flattened almost exactly where Kahneman's original paper had said it would. Above roughly $100,000 a year, adjusted for inflation, more money did nothing for them.
This is the finding that changes how the question should be asked.
If you are not already unhappy, money keeps buying happiness for a much longer stretch than Kahneman's original paper suggested. The runway is wider than the world has been telling itself for a decade.
If you are already unhappy, money does almost nothing past a certain point. There is a ceiling, but the ceiling is not about income. It is about the underlying state of the person collecting it.
The deeper insight in Killingsworth's original research, the one almost nobody talks about, is the part that should sit with you longer than the income numbers. The Track Your Happiness app had been telling him for years that the single biggest predictor of in-the-moment well-being is not money at all. It is whether your mind is on the thing you are doing.
His most cited paper, written with Daniel Gilbert at Harvard, is titled A Wandering Mind Is an Unhappy Mind. The data from the app showed that people are mentally absent from what they are doing 47 percent of the time, and that mental absence is one of the strongest predictors of unhappiness in the entire dataset. More predictive than income. More predictive than the activity itself. More predictive than almost any demographic variable you could measure.
Which means the unhappy 20 percent that Kahneman's plateau actually described were probably not unhappy because they did not have enough money. They were unhappy for reasons that more money could not reach.
The reason the curve flattened for them at $100,000 a year is the same reason it would have flattened at $300,000 or $700,000. The thing they were missing was not buyable.
The most uncomfortable line in the entire 2023 paper is the one that nobody on the internet quotes. The authors note that the relationship between income and happiness, while real, is much weaker than the relationship between attention and happiness. A person earning $40,000 who is fully present in their own life will, on average, report higher in-the-moment well-being than a person earning $400,000 whose mind is somewhere else.
The fight about money was the wrong fight the entire time.
The two researchers spent 13 years arguing over whether the dollar ceiling was at $75,000 or $500,000, and the data from Killingsworth's own app was sitting there the whole time saying the ceiling was not about dollars at all. The ceiling is whether you can hold your attention on the life you actually have.
You can run the experiment yourself the next time you catch your mind drifting. Stop. Put your phone down. Look at the room you are in, the person across from you, the food in front of you, the work you are actually doing. That is the part the apps cannot sell you and the salary cannot buy you.
The data has been clear for over a decade. The plateau is not in your bank account. It is in your attention.

55
457
1,623
295,833
Sure (e/acc) retweeted

Jun 15
Marketing Skills v2.4.2 is out.
🆕 /ai-seo now covers Google's Open Knowledge Format (OKF) — a v0.1 markdown spec for representing your site as an agent-readable bundle. Google announced it June 12.
The honest version: Google built OKF for data teams to share metadata (BigQuery, APIs, metrics). Using it to make your site agent-readable is a clever secondary use. No crawlers target OKF bundles yet — this is a register-early bet, not a traffic play. The skill says so plainly, and tells you when to skip it.
What the update adds:
→ A 104-line OKF reference — concept, minimal examples, and the frontmatter spec (type required; title / description / resource / tags / timestamp recommended)
→ Where it fits in the agent-readable stack — alongside sitemap.xml, robots.txt, llms.txt, and schema markup
→ How to implement — the free OKF Generator, a pending WordPress plugin, or by hand
→ When to skip it entirely
→ New triggers: llms.txt, OKF, Open Knowledge Format, knowledge bundle, agent-readable site
44 skills. Free, open source.
npx skills add coreyhaines31/marketingskills
11
40
465
27,486
Sure (e/acc) retweeted

Jun 15
Satya Nadella just posted something that validates the entire AI buildout thesis from the very top of the stack.
The model is commoditizing. The durable value is the learning loop a company builds on top of the model.
He splits it into two assets:
Human capital -- the knowledge, judgment, relationships, and pattern recognition of your people.
Token capital -- the AI capability the firm builds and owns.
He says the real opportunity is building a learning loop where human capital and token capital compound together.
If the model layer is commoditizing then the durable returns are not in the model makers. They are in the infrastructure that powers every company building its own loop. Compute. Memory. Interconnect. Power.
The full stack underneath the application layer.
The model wars will have winners and losers. The infrastructure underneath gets bought either way.
Bullish the AI buildout.
Every layer. If you want to understand them in detail, check out my Substack.
open.substack.com/pub/rensub…


44
183
1,050
212,242
Sure (e/acc) retweeted

Jun 15
I'm convinced that 99% of success is just the ability to outlast uncertainty. The one who can tolerate the most uncertainty is the one who will eventually win.
275
1,277
10,005
276,026
Sure (e/acc) retweeted

Jun 14
The only reasonable expectation if you're a fan of open weight models is that if there's a major step in chinese open-weight performance, there's a good chance the whole chinese llm sphere is banned.
National security apparatus will happily give a big "fuck you" to open models.
Jun 14

Threading the needle in this post of anthropic has done some bad things for AI governance & the discourse but the actions of this administration are way worse so we need to get a handle on it before stronger models, open or closed, come along soon.
interconnects.ai/p/welcome-t…
39
21
380
61,662
Sure (e/acc) retweeted

Jun 13
Nobody teaches you that discipline feels like punishment until the results start feeling like freedom
169
2,122
11,747
686,161
Sure (e/acc) retweeted

Jun 13
Karpathy said something you'll regret ignoring:
"Remove yourself as the bottleneck. Maximize your leverage. Put in very few tokens, and a huge amount of stuff happens on your behalf."
Loop engineering is the exact thing that does that.
In a hand-run session, the operator handles two things:
- deciding what the agent runs next
- and checking its output before the next step
Both are manual, and both decide how far the agent gets on its own without the operator.
Loop engineering moves both steps into the system.
A core operating structure surrounds the loop, and the diagram below depicts it.
- A schedule decides what to run
- Loop is the maker that produces the work
- A separate checker agent grades the output
- A file on disk holds the state they both read.
The loop runs until either done, max iterations, or an exhausted budget.
Here are some practical engineering considerations:
1) A model grading its own output justifies what it already did instead of catching where it failed.
That's why a separate checker's findings return to the maker as the next instruction. And the cycle repeats until the checker finds nothing left to fix.
2) A loop with no stop condition burns tokens, and the cost climbs fast once sub-agents and long runs add up.
That's why the exit must be set before the loop runs, not while it is running.
A simple exit could be:
↳ fix only the major issues, run one final pass, and stop after two loops, with "all tests pass and lint clean" as the rule that ends it.
3) State has to live on disk, not in context.
The model forgets everything between runs, so an MD file or a knowledge graph holds what is done and what is still open.
Each run reads it and writes back to it, which lets a loop pick up again after days.
4) The lower the verification bar, the safer the loop.
Boring, repetitive checks like a stale version string or a missing test are trivial to verify, so a loop runs them with little risk while the operator is away.
Judgment-heavy work is loopable too, but only as far as the checker can confirm the result.
Let's look at how an unattended loop fails in two ways.
1) It reports done when nothing is actually verified.
The separate checker exists to prevent it, but it merges code faster than anyone reads it, so over weeks, the team stops understanding its own codebase while every check stays green.
Green tests say the code passed the tests, not that anyone knows what shipped. Someone still has to read what the loop merges.
2) The checker keeps a running loop honest, but it only catches failures inside a run.
The harness around the loop, like the prompts, tools, and checks wrapped around the model, still drifts and breaks in production as models change.
That repair loop is usually run by hand based on observability traces.
My co-founder wrote a detailed walkthrough (with code) on making that harness repair itself, where a failing trace gets diagnosed, the fix is verified against the exact input that failed, and the failure is locked as a regression test so it cannot recur.
Read it below.

73
548
3,747
646,755
Sure (e/acc) retweeted

Jun 13
The takeaway from Fable 5 being BANNED by the government: GET GOOD AT LOCAL MODELS SO YOU HAVE 100% CONTROL.
My entire weekend was going to be building my craziest ideas with Fable 5. That's now cancelled.
So instead of building with Fable this weekend, I've decided I'll go deep on local models:
1. Start with the runtime. Download Ollama or LM Studio first. This is the thing that actually runs models on your machine.
2. Match the model to your hardware. A model's size is measured in billions of parameters (7B, 32B, 70B). Bigger is smarter but needs more memory. Rule of thumb: a 7B model runs on almost any laptop, a 32B needs a good Mac with 32GB RAM, a 70B needs serious hardware like a DGX Spark or a maxed-out Mac Studio.
3. Know which model for which job. Qwen 3 is the best all-around choice for most tasks. DeepSeek for reasoning and coding. Gemma 4 when you need something tiny that runs on a phone. Llama when you want the biggest community and the most fine-tunes.
4. Quantization. You can shrink a model to run on weaker hardware with barely any quality loss. Look for versions labeled Q4 or Q5. This is how a model that "needs" a server runs on your laptop. Learning this one concept changes everything.
5. Connect it to your agent. Point Hermes or your agent stack at a local model.
6. Context window is your real constraint locally. Cloud models give you huge context for free. Local models make you pay for it in memory. A bigger context window eats RAM fast. Keep your sessions tight and your prompts lean or your machine chokes.
7. Learn to give local models tools. A smaller local model with web search, file access, and code execution beats a giant model with none. The capability gap closes fast when you wire up the right tools. The model is the engine but the tools are the wheels.
8. Fine-tuning is more accessible than you think. You don't need this on day one, but know it exists. You can take an open model and train it on your own data so it gets good at your specific domain.
I'll probably do a breakdown at some point on this @startupideaspod if people are into it.
The lesson from this ban is basically don't build your entire workflow on something that can disappear with a single letter. Own part of your stack. Local models are insurance.
It reminds me when people realized they don't own social media accounts. And then you saw people build email lists etc.
I remember running a startup and my biggest traffic source was organic FB. All of a sudden, algo changed, and I lost 99% of my traffic.
Same sorta moment (but bigger) for AI.
This is a wake up call.
345
437
4,233
462,321
Sure (e/acc) retweeted

Jun 14
🚨 SHOCKING: LISA SU’S $1,499 LUNCHBOX ANNIHILATES NVIDIA’S $4K AI BEAST!
AMD CEO Lisa Su walked on stage, held a lunchbox sized PC in one hand, and ran a 235 billion parameter model live.
No data center. No cloud. No rented GPU.
The chip inside is the AMD Ryzen AI Max 395. It is the first x86 chip where the CPU and GPU share the same pool of memory. Up to 128GB of unified memory. That one design choice is what changes everything.
An RTX 5090 gives you 32GB of video memory. A 4090 gives you 24. This box gives you more than three times either of them in a chassis you can carry in a backpack.
On DeepSeek R1 inference, AMD's chip beat an Nvidia RTX 5080 by more than 3x. A desktop the size of a thick paperback outrunning a dedicated graphics card that costs over a thousand dollars on a real AI workload.
Now do the math on your subscriptions.
Claude Code Max is $200 a month. ChatGPT Pro is another $200. Cursor is $20. Gemini is $20. That is $5,280 leaving your account every year before you build a single thing.
The 128GB version of this machine starts at around $2,399. At that run rate it pays for itself in under a year and then runs free.
Install Ollama. Pull Qwen3 235B. Point Claude Code at localhost. Same interface you already use. Nothing leaves your machine. Nothing costs per request. No throttling at 3am when you finally have time to build.
Lawyers stop worrying about what OpenAI does with their files. Developers stop watching the token counter. Founders stop killing prototypes because the cloud bill scared them off.
Private AI just became something a normal person can own.
283
827
5,031
725,933




We are finally getting our fable back.
I built a repo that runs two opus 4.8 on the same question in parallel, blind to each other base on the OpenRouter Fusion.
Then a third opus reads both and writes the final answer from where they agree, where they split, and what they both missed.
One run can be confidently wrong. Two, cross-examined, can't hide it.
Put the real fable system prompt on top of the claude.md and the judgment comes back. It sounds like fable again because it's doing what fable did.
Link's in the comments.
Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

75
83
1,211
208,686
Sure (e/acc) retweeted

Jun 14
This is a *way* bigger deal than it seems...
Frontier AI companies will *never* own the frontier again
I kid you not... I've been waiting for someone to show this result for like 4 years... this is a huge deal.
The short reason: combinations of models will *always* outperform individual models
The long reason: this is the gateway to a million times more data... and huge leaps in compute efficiency.
The AI scaling laws always win.
More in article below 👇
Jun 13
Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇
240
356
5,096
1,272,552
Sure (e/acc) retweeted

Jun 13
Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇
705
1,769
14,881
6,004,243
Sure (e/acc) retweeted

Jun 13
Five dimensional chess doesn’t exist. Everyone is furiously improvising all the time. The future is utterly uncertain.
349
480
6,130
787,592
Jun 13
Mythos being banned is exactly why China has already won the AI race.
Before you know it, Chinese model providers will become the standard globally. Offering SOTA intelligence at a fraction of US model costs.
1
15
Sure (e/acc) retweeted

Jun 12
NVIDIA might just have open-sourced one of the most important AI projects right now.
everyone is building skills, and we are also pulling in skills other people wrote and downloading them straight off GitHub.
the skill is not just text. it bundles instructions and real executable code, and your agent runs that code with the same access you have.
so a skill you grabbed to save ten minutes can read your environment variables, lift your API keys, and quietly send them somewhere. recent research found roughly 1 in 4 public skills carry a vulnerability, and a smaller slice are outright malicious.
that is the gap SkillSpector closes. it is a security scanner that answers one question before you install anything: is this skill safe to run.
you point it at a skill, and a local folder, a single skill .md file, a GitHub link, or a zip all work.
it then runs two passes over the code. a fast static pass flags risky patterns like credential harvesting, data leaks, and prompt injection, and checks the dependencies against live cve data.
an optional second pass uses an LLM to read intent and clear out false positives.
at the end you get one risk score from 0 to 100 and a plain verdict that reads as safe, caution, or do not install.
it is open source under Apache 2.0 and scans skills for Claude Code, Codex CLI, and Gemini.
worth a run before you trust the next skill you find online.
link to the GitHub repo: github.com/NVIDIA/SkillSpect…

86
230
1,559
110,288
Sure (e/acc) retweeted
Jun 11
99% of people are using Claude Fable 5 wrong.
People don't know how to work with it yet because nothing this powerful has ever existed.
I'll show you 10 use cases and startup ideas that can only exist because Fable 5 is here in under 34 minutes.
Jun 9

Today is a wonderful day to build a company with Claude Fable 5
86
123
1,436
283,942