
Joined July 2017
- Tweets 2,578
- Following 1,801
- Followers 594
- Likes 12,786
676 Photos and videos









Pinned Tweet

Jan 12
My implementation of the Recursive Language Model (RLM) paper by @a1zhang , Kraska, and @lateinteraction .
Key insight: "Treat long context as an external environment, not something to stuff into a context window."
Applied to video understanding — instead of encoding 38K frames into a prompt, the agent:
→ Treats video as an environment
→ Writes code to explore segments
→ Uses recursive LLM sub-calls for analysis
Tested: 20 min video, 7 steps, $0.002
Paper: arxiv.org/abs/2512.24601
Code: github.com/mohammed840/RLM-i…
27
79
849
57,886
Mohammed Alshehri retweeted

"Everybody's an investor," says Peter Thiel.
Whether you write code, build companies, or choose a career, you're allocating scarce attention and belief into bets on the future.

1
1
1
33
idk how some people are not using @DSPyOSS like they are at least 2 years behind
1
31
Mohammed Alshehri retweeted

Jun 15
Kind of? x.com/SwishMoe/status/201050…
The concept of RLM itself can support videos as its not tied to text (can work with any data that the underlying LLM can support)
But a specific implementation of it might need tweaks.
Jan 12

My implementation of the Recursive Language Model (RLM) paper by @a1zhang , Kraska, and @lateinteraction .
Key insight: "Treat long context as an external environment, not something to stuff into a context window."
Applied to video understanding — instead of encoding 38K frames into a prompt, the agent:
→ Treats video as an environment
→ Writes code to explore segments
→ Uses recursive LLM sub-calls for analysis
Tested: 20 min video, 7 steps, $0.002
Paper: arxiv.org/abs/2512.24601
Code: github.com/mohammed840/RLM-i…
1
2
77
Mohammed Alshehri retweeted

Jun 15
16
66
7,293
Mohammed Alshehri retweeted

Jun 14
A few words on the Sovereign AI debate, having built several LLMs in Meta while in the UK and now working as a UK based startup:
1. Lots of people are trying to do the right thing to make the UK a better place to start AI companies. Time lags until the benefit show, but you should judge on the intent now. I support the direction of travel!
2. DeepMind has been enormously beneficial for the UK, but it has muddied the waters for a sovereign LLM company to emerge as (until recently) the Government continued to celebrate it as a British achievement / push it as a national champion.
3. Similarly, people are now celebrating recent US investment in King’s Cross, while also wanting more UK sovereignty. Clearly some income effects here, but I would worry about the substitution effects too. AI is not like other types of foreign investment.
4. The relevant talent nexuses in UK that could develop a competitive foundation model are from GDM and old Meta AI GenAI. Also some folks from smaller groups, ex Conjecture, Stability. The talent is still there, although a lot was snapped up by US FM companies in the past year. I personally think it’s not too difficult to develop new talent either from UK universities, but you probably need an ex GDM or Meta core (Gemini or Llama). Or if not: show evidence first (technical reports) before claiming you can do it.
5. Building an LLM is very different from doing regular AI research - skillset is different. Former is closer to engineering; long hours, often unsexy work. Important to distinguish between these two types of talent in the UK ecosystem; arguably too much focus on the latter / ideas guys.
6. On research - DeepSeek R1 post-train cost $300k . Yes, they also needed an ablation budget and to train a base model, invest in infra and talent - and yes the cost of an R1 moment is increasing year on year - but the idea that you need $1bn plus immediately to show results is complete FUD. You need billions to scale, not to validate new directions.
7. In my experience, every failed LLM effort (from model results perspective) I witnessed in the past came from a combination of poor leadership, politics, unclear vision, and premature scaling. Good efforts usually started from small teams who had worked with each other for a long time, had shared thesis, and scaled progressively in bite-sized pieces. Some recent lessons here for neolabs as well.
8. Things take time. Eg we’ve spent ~12 months mostly on internal infra just to get into the position to be able to make big swings. It’s important to nurture new companies through the initial phase. Expectation management is also crucial. I think expecting new UK companies to have single big bang releases is very dangerous; sort of like overwatering a plant. The correct release pattern is “decent”. “decent”, “decent”, “quite good actually”, “holy shit”.
9. Please don’t allow politicians or journalists to kill recent or upcoming AI investment efforts. We will need way more - at the price of potential inefficiency in places - as AI is existential for the country. Ambitious projects are usually incredibly fragile in the early stages; look after them!
10. Mythos is a good triggering moment, but what’s coming will make it look like a toy, so it’s worth building for what’s coming in 5 years time - not a current generation model.
Very proud to be building in the UK - more to share on that soon - alongside many other great early stage AI companies! 🇬🇧
41
106
751
128,864
Jun 14
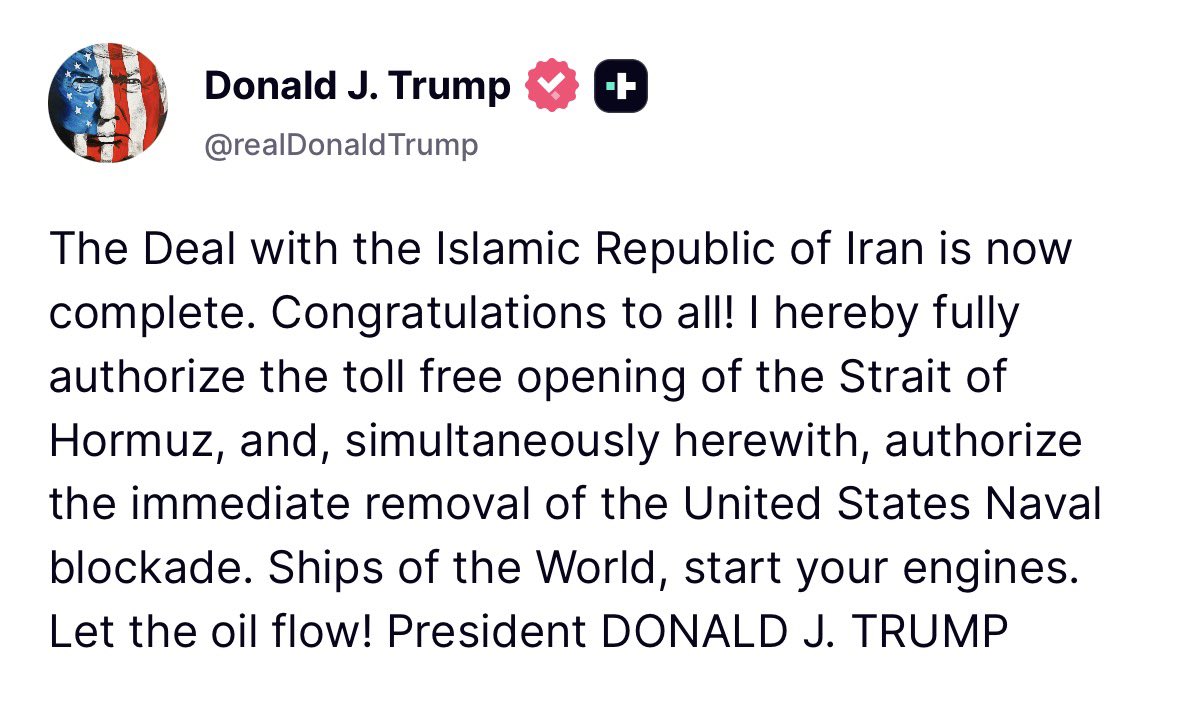
Thank you president Trump for bringing peace in the Middle East
Jun 14

“The Deal with Islamic Republic of Iran is now complete. Congratulations to all!” President Donald J. Trump 🇺🇸
40
Mohammed Alshehri retweeted

Jun 14
Satya is perfectly describing the why and what behind @primeintellect since 2023 🫡
> AI needs to be open & sovereign
> Let every company create its own self-improving agents: and own their loop to make them better
> A rich open ai ecosystem creates far more abundance than a future locked down by a few closed labs
> Every company is becoming an ai company: so every company needs to own its own product <> model improvement loop
@primeintellect enables this today:
> Your own evals rl envs for the outcomes you care about
> models self-improving in production from your real traces
> don't cede your moat to a handful of labs. This self-improvement loop is the IP and it compounds
Open self improving agents for everyone 🫡


13
32
223
23,115

Jun 13
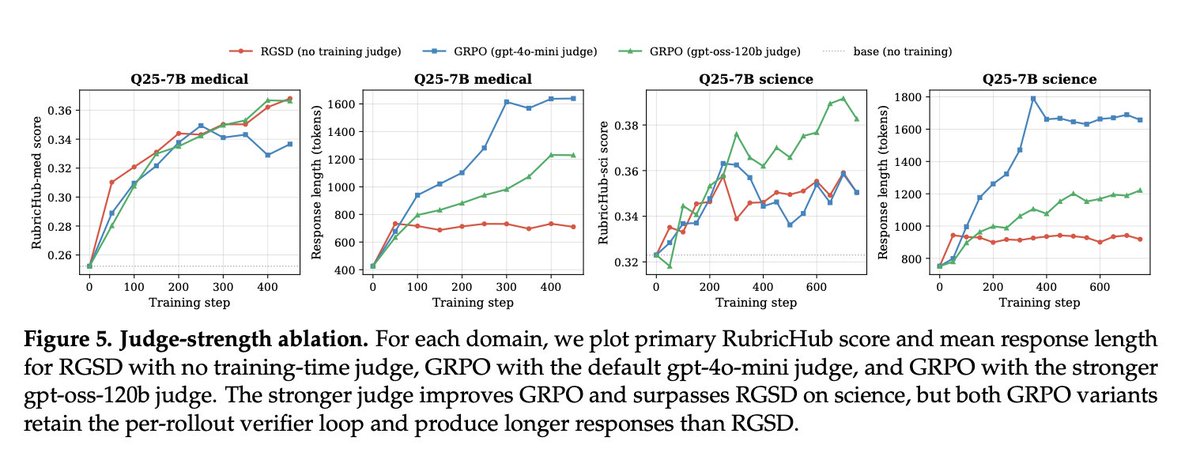
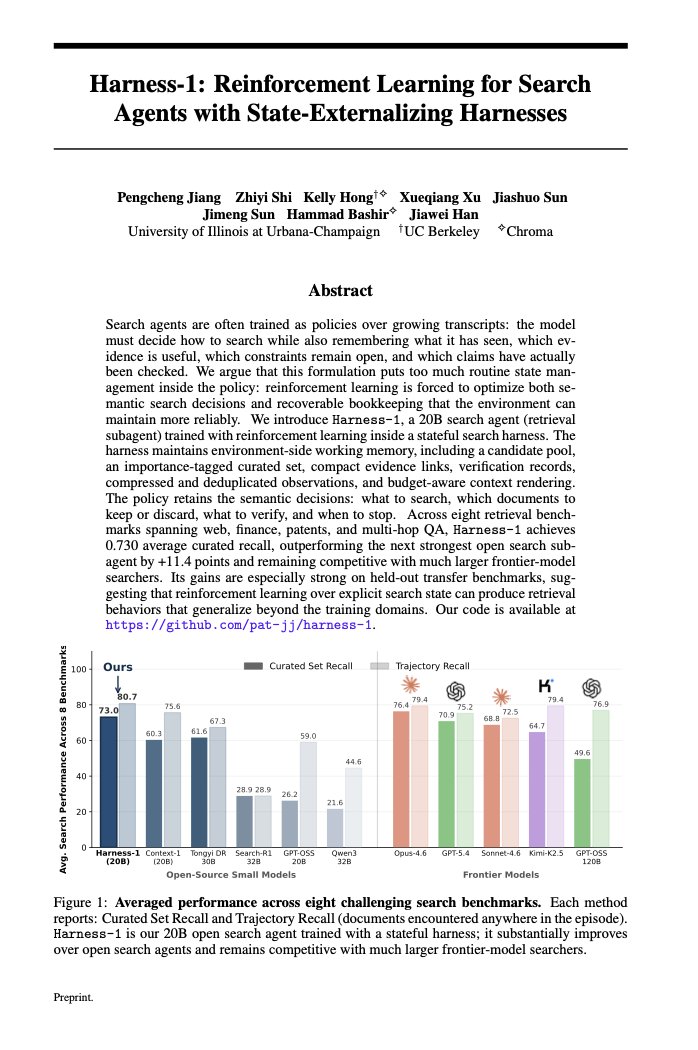
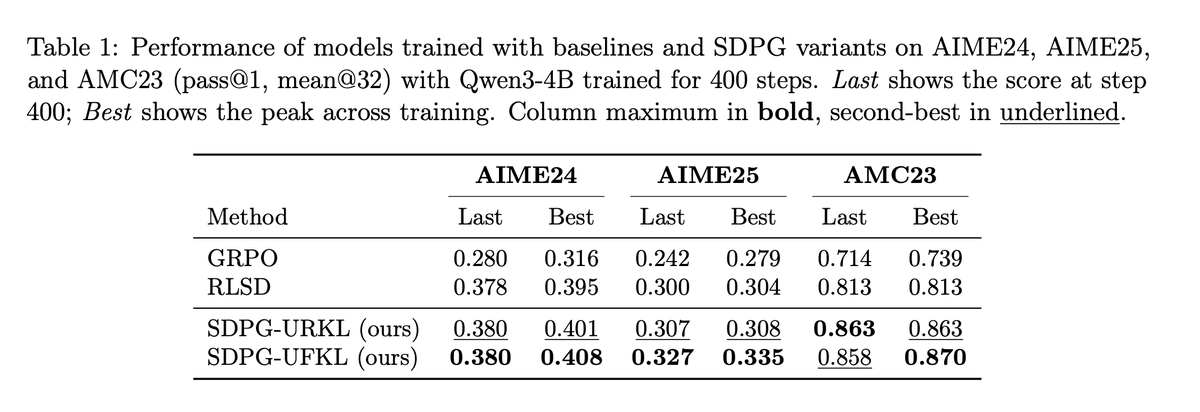
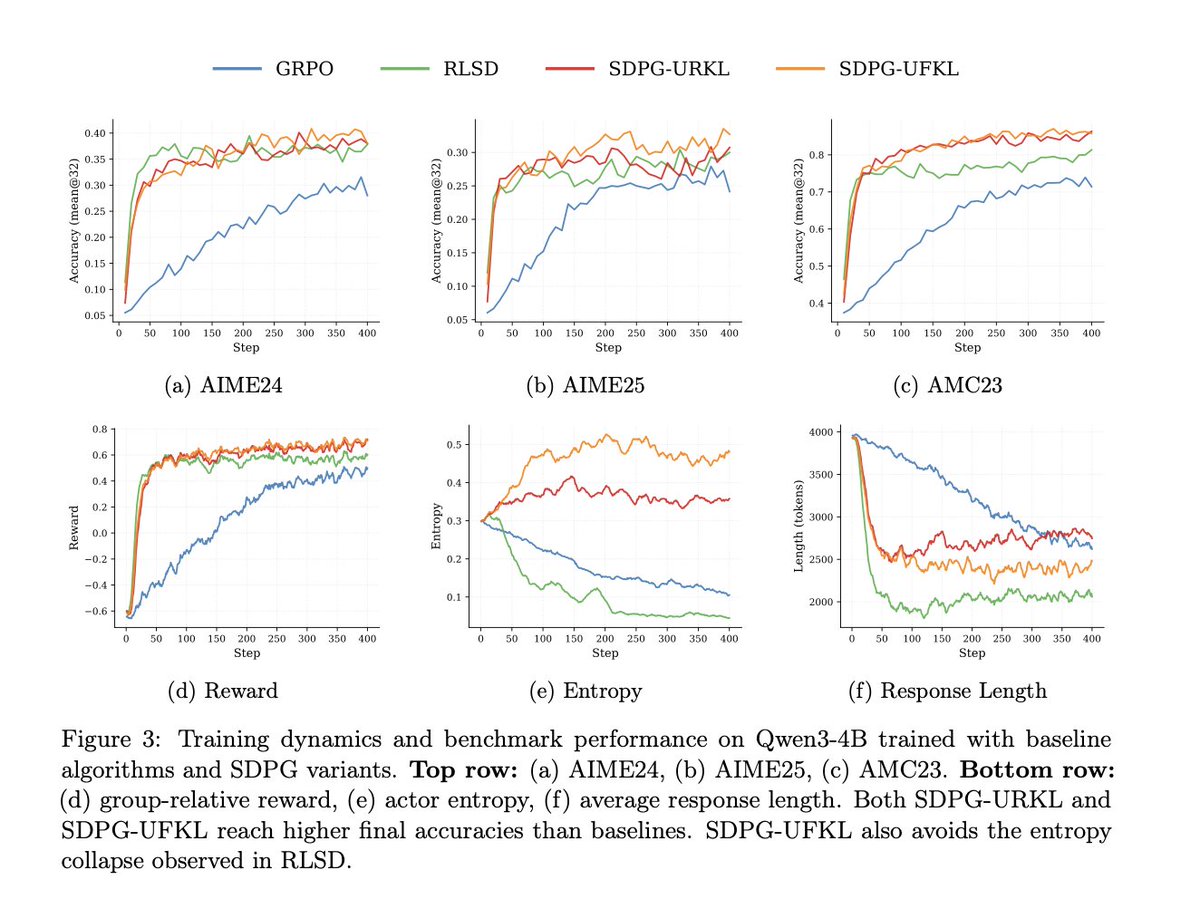
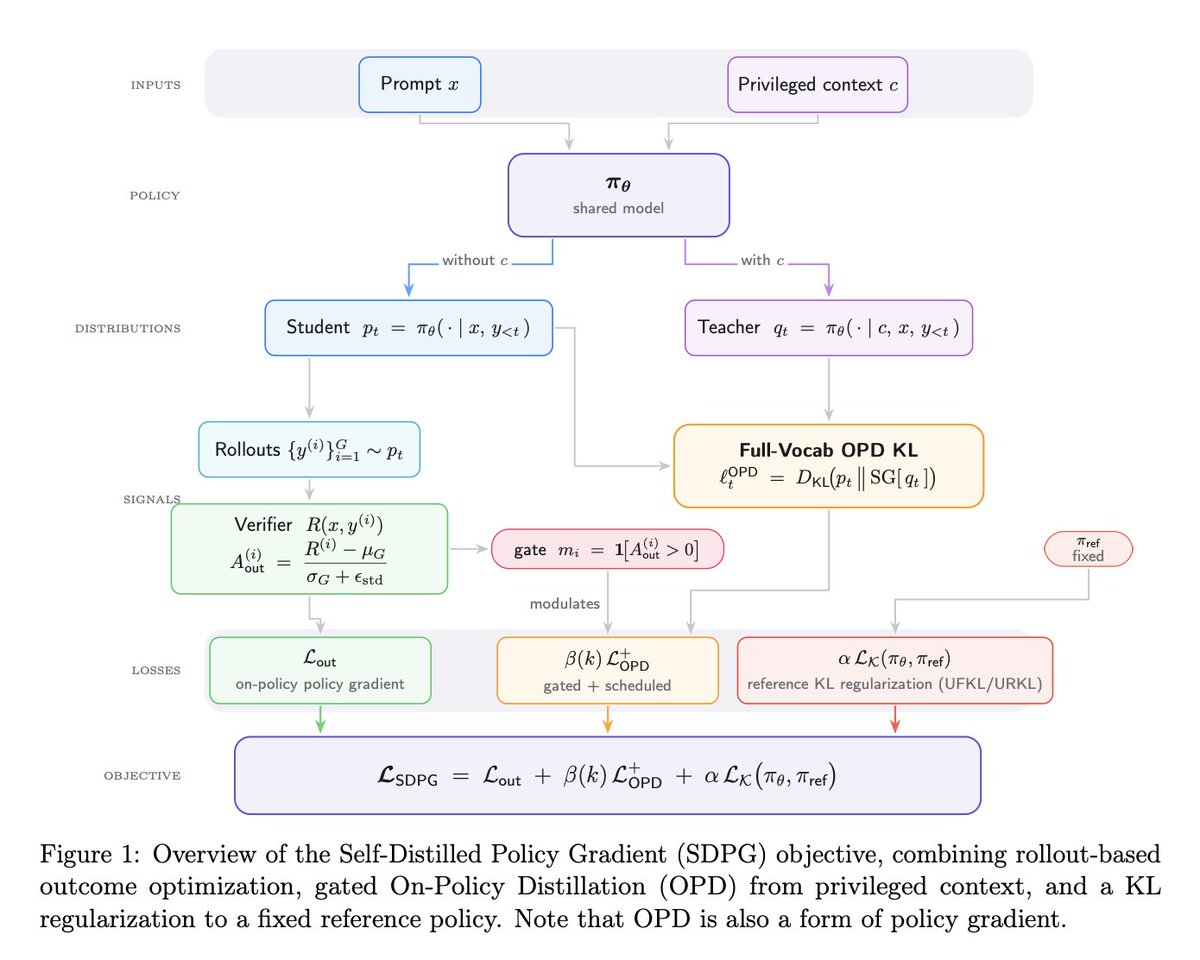
Scale AI’s approach here is one of the cleaner directions I’ve seen for post-training open-ended models:
stop treating the LLM judge as the center of the training loop.
Use the rubric as privileged context, then distill that behavior back into the base model.
1
3
132
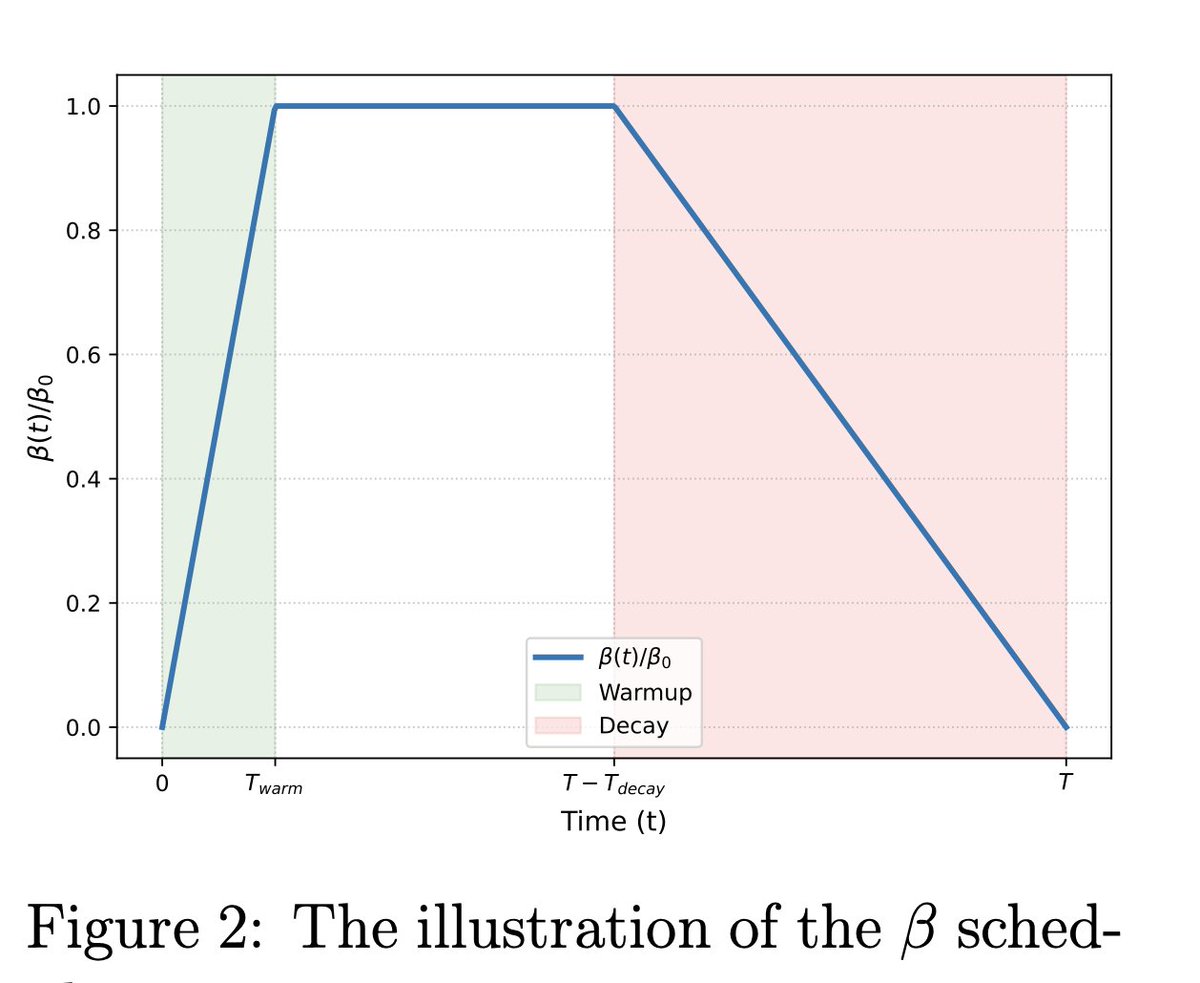
Jun 13
10/10
How I would attack this next:
test more domains,
stress-test weak rubrics,
measure judge transfer,
audit factuality without LLM judges,
try noisy/adversarial rubrics,
and check whether the student truly learns the rubric or just imitates rubric-conditioned style.
Still, this is a very nice direction from Scale AI.
1
31
Jun 13
Link: arxiv.org/abs/2606.12507
Great work to the team /
@nas_mahmoud_
@wzihao12
@utkarsh4430
@agxsai
@mhrezaeics
@RazvanDuu
@aakashsabharwal
@vbingliu
@_yunzhong
3
62