
LLM research, systems and compilers | ax dspy in TS | agent engineering. aithy.dev axllm.dev graphjin.com
Joined July 2008
- Tweets 16,668
- Following 1,702
- Followers 5,156
- Likes 7,055
1,003 Photos and videos









we're on track to building the best dspy powered llm framework in the typescript world
30 Jun 2025

Yes — @dosco’s Ax is pretty much the official DSPy in TS.
4
5
80
21,709
this idea sounds simple enough. i've often used multiple models like this with ax it's pretty easy to do either with their endpoint or just multiple endpoints.

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

1
3
428
ignore the noise focus on the signal, ipo's, politics, drama, all of this is noise. the signal is personal, you need to grow, what do you focus on.
high abstraction:
- building agents
- forward deploying agents
- working with open and closed models
low abstraction:
- building RL environments
- tuning / merging models
- sglang / vllm internals
lower abstraction:
- model arch. research
- inference optimization research
- data research
highest abstraction:
- sharing your work
- reaching out to others
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
5
1
23
1,519
the solarpunk future is already here
Jun 11

トラクターの中が、開発現場になった。
ラズパイZero 2 Wをスマホのテザリングでオンライン化。
家に置いてるCodexからTailscaleでつないで、畑のラズパイに直接コードを書いてもらう。
自分で何言ってるか、?になるけど畑でもCodex使ってラズパイ開発すらできる🚜

2
2
11
804
until there is wider adoption of frameworks like DSPy most people can’t use APIs effectively, model usage has only gone mainstream because of the solid harnesses that come with the subscriptions
Jun 10

Obviously this is way worse than API overall. However, explicitly nerfing subscriptions leads to huge public backlash, and the rapidly falling cost of intelligence means you'll be able to profitably serve Opus 4.8 level models for $20/month in the near future. We therefore think it's far more likely the labs will withhold new features/models from subscription plans. It will be interesting to see if Mythos ends up being API only. (4/4)
2
1
27
2,911
atleast we’ll know if these models help or if the real frontier is far out there
Jun 10

Imagine building a computer and not allowing its use in CS research. Thats some dystopian shit.
3
590
google just released a new open diffusion based gemma model (26b). it's insanely fast, and if its even decent on coding will be wild with ax-agent i need to try this with aithy.dev
uses diffusion to refine 256-token blocks in parallel, hitting:1,000 tokens/sec on H100 700 tokens/sec on RTX 5090
- runs quantized on consumer GPUs (just 18GB),
- multimodal inputs & up to 256K context.
Jun 10

DiffusionGemma is an open, experimental model that brings our text diffusion research to Gemma 4. It’s a racehorse 🏇achieving up to 4x faster inference by generating entire blocks of text simultaneously vs predicting token-by-token (word-by-word) output!
1
29
3,016
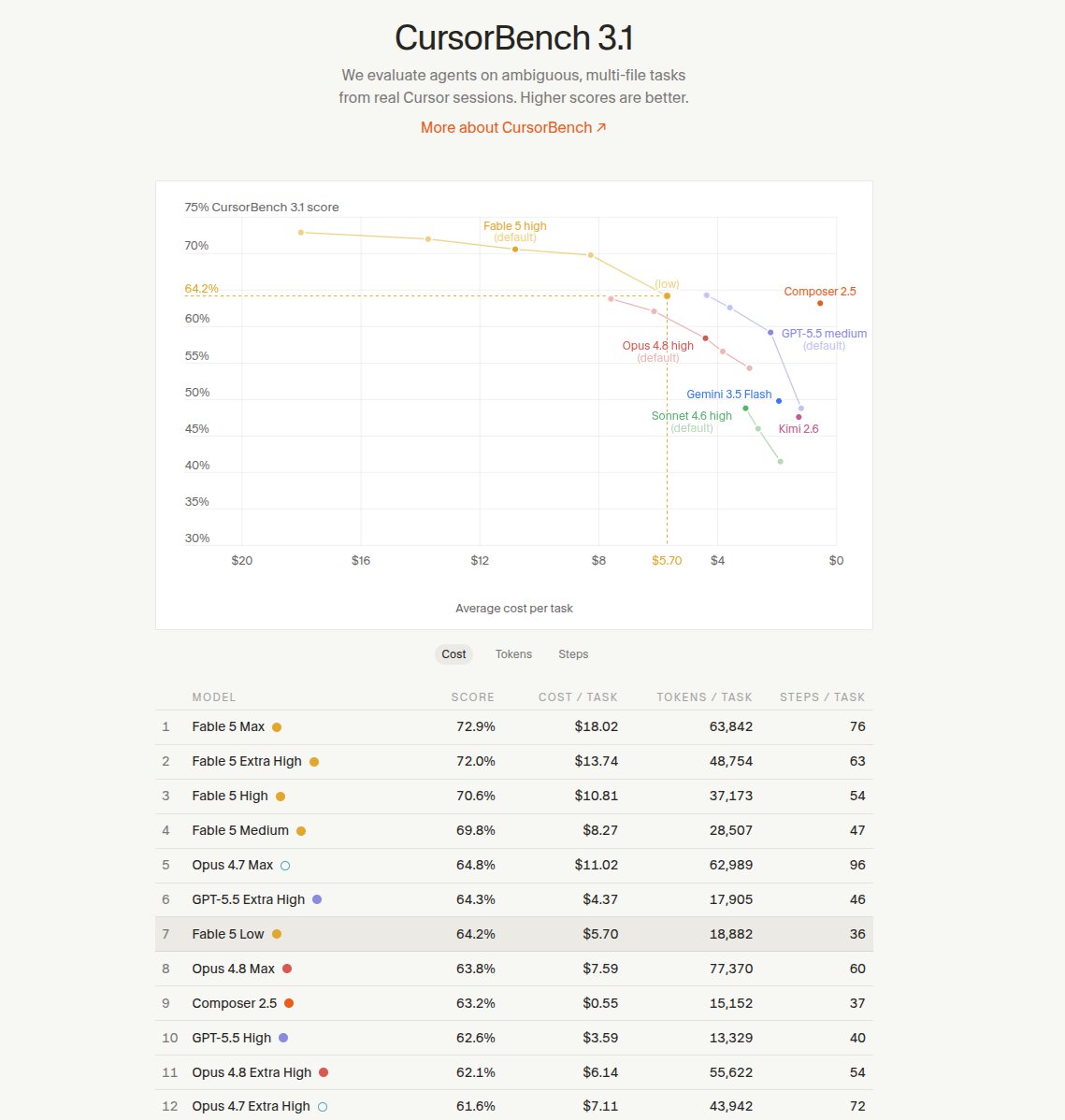
next up, i'm gonna look every type of benchmark and run it with the ax-agent, game on!

hmmm, now I have FOMO...can't wait for competition to do it's thing.
1
8
743
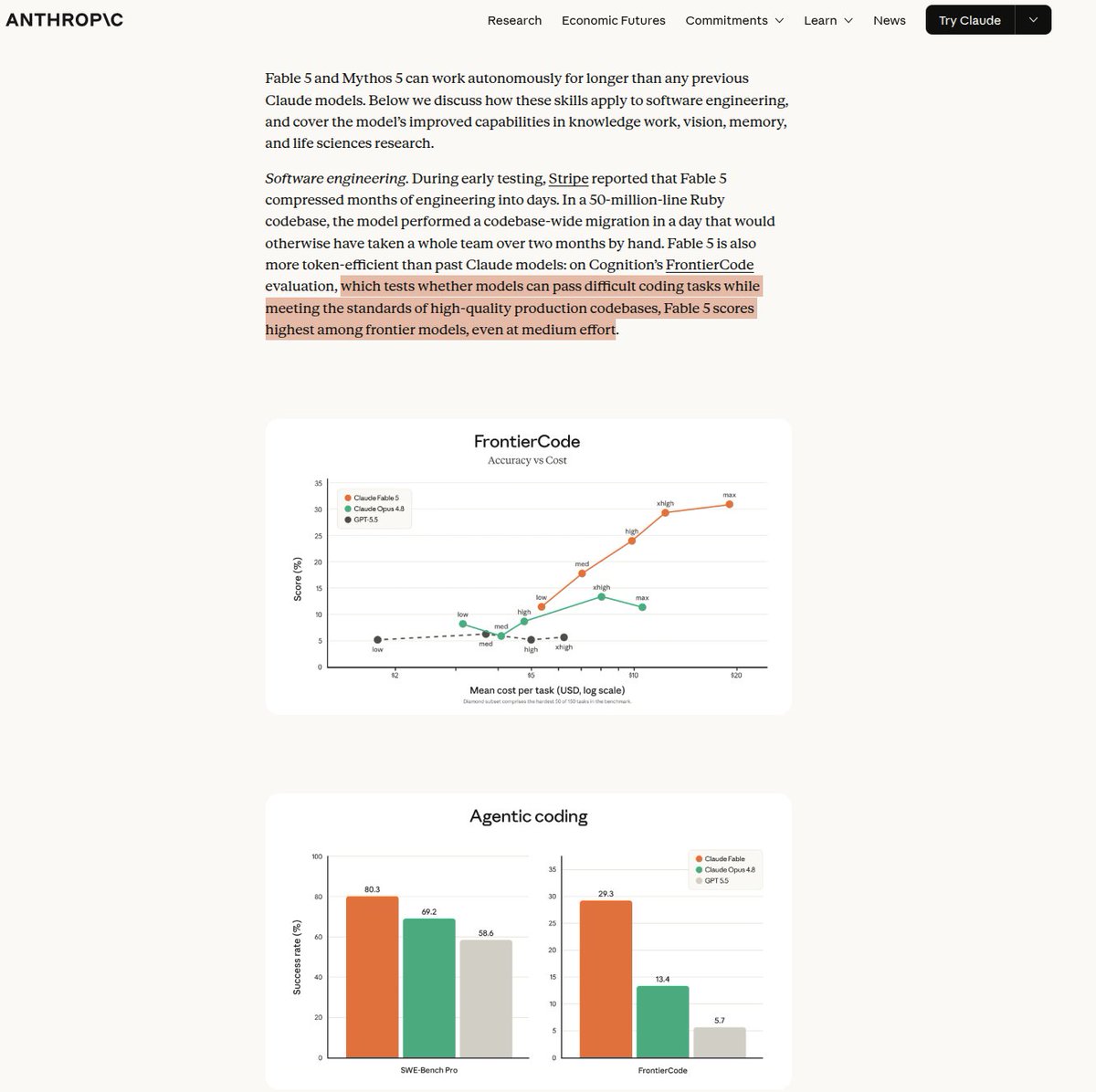
this is a great read and really solid work. fable is proof that these models are getting crazy good but you still have to manage the context.
here's some DSPy (ax) code to build your own version of the harness in the article.
experiment → independent verifier → correction → verified memory.

3
11
194
29,583
there are so many things AI is changing all at the once that people can barely wrap their head around all the acceleration. we are literally making the world flat and the impact of this at scale is too big to
imagine
Jun 9

23,000 ChinaRxiv papers are now freely available with more complete English translations after one developer replaced a complex OCR pipeline with GPT‑5.5.
x.com/seconds_0/status/20598…
3
674
spacy retweeted

Jun 9
We've known about LLM test-time compute scaling since @OpenAI o1.
Yet 2 years later labs still report scalar evals for models; safety orgs are still surprised when a scaffold does better via 100x inference; and RSPs still ignore inference budget when deciding critical thresholds.

33
68
860
80,505
while i use the biggest models i can for coding most of the agentic work i do uses much smaller models a large amount of more agentic work could be done by models under 20b one of the ways i do this is leveraging their coding skills vs native function calling and smart context management combined with ideas like PEEK, RLM, GEPA
Jun 8

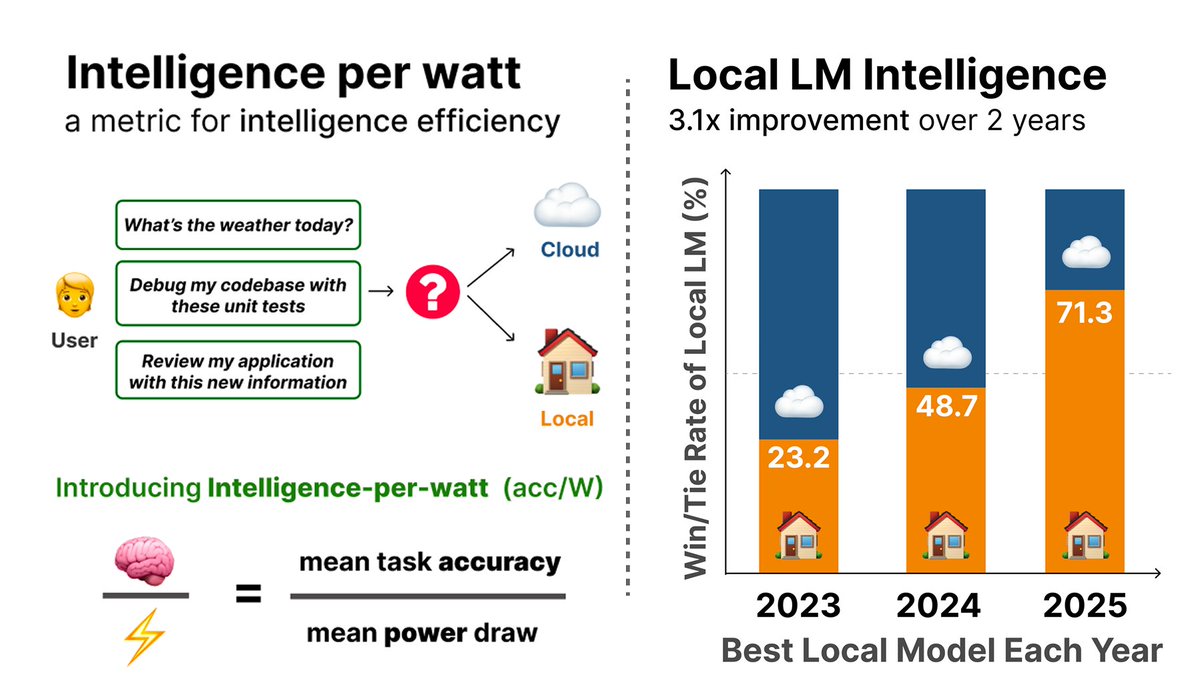
Narrative violation: according to @Stanford research, local models can answer 71.3% of real-world chat and reasoning queries accurately, up from 23.2% in 2023. Obviously at a fraction of the cost and energy consumption of frontier APIs.
The obvious conclusion: you don't need a frontier model for most tasks. The future is multi-model: local, open-source, smaller and cheaper for the majority of workloads, frontier APIs when no other choices!
5
3
13
1,314
everything i do is motivated by this. i got into comp. sci. to be a builder not a user, in-context learning is the true democratic playing field in the LLM space, it’s where any of us can make a large impact much larger than tuning and training all of that just look at RLM and DSPy. the more i got into it the more i realized that model building and building with models is two very different skills. the reason i don’t think so much about long context or continual learning is because i already have it. this article is a must read.

4
4
49
4,303
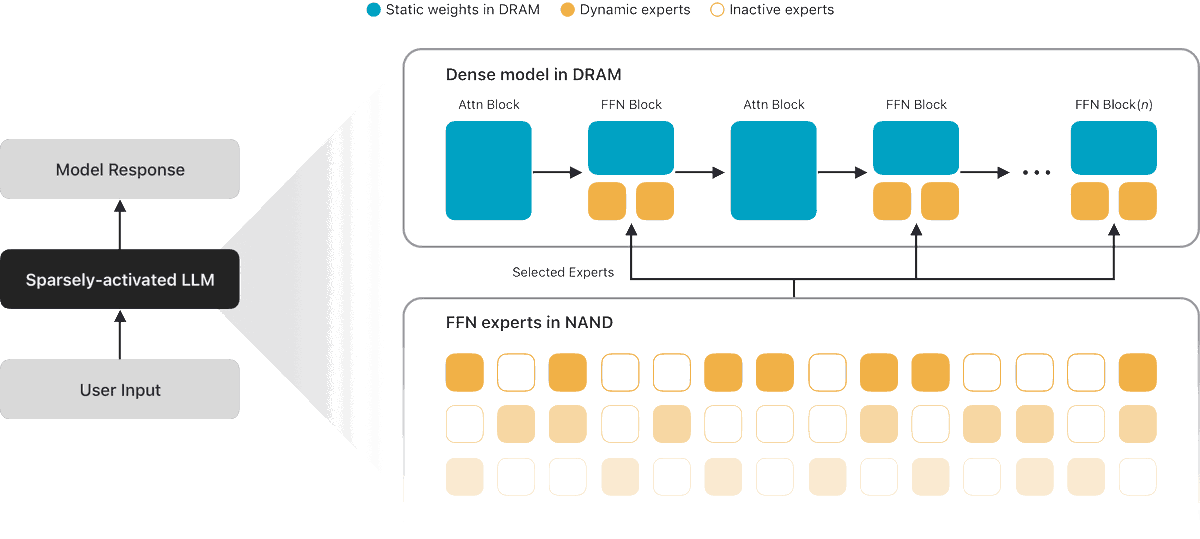
apple on device foundation models
AFM 3 Core: Next-generation 3-billion-parameter dense model built for quality upgrades.
AFM 3 Core Advanced: Powerhouse 20-billion-parameter model designed for complex tasks.
The 20B MoE model activates only 1 to 4 billion parameters at a time. Architecture enables expressive voices and high-accuracy dictation.
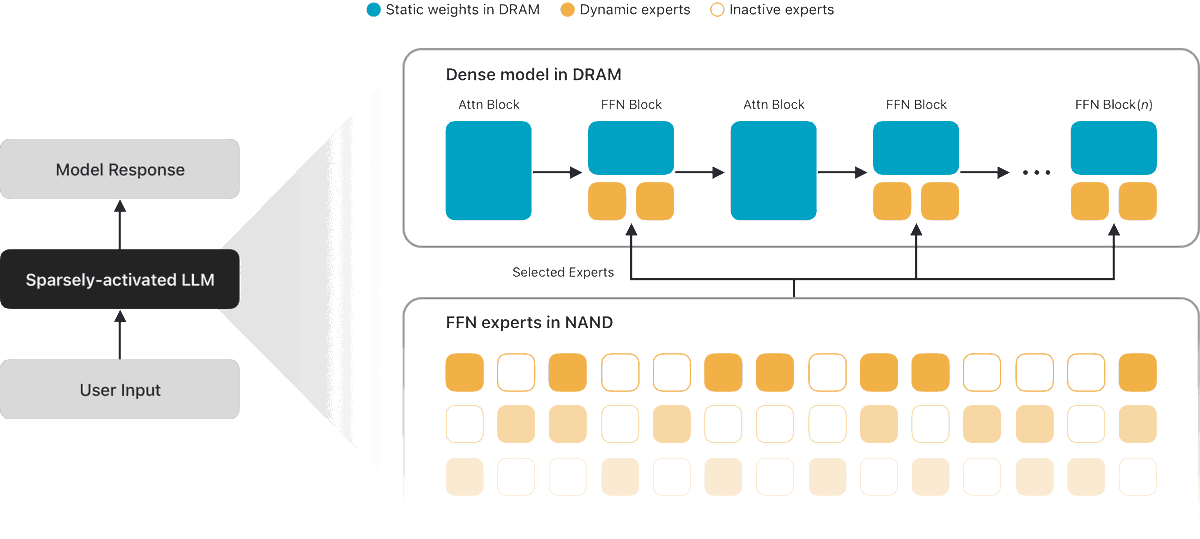

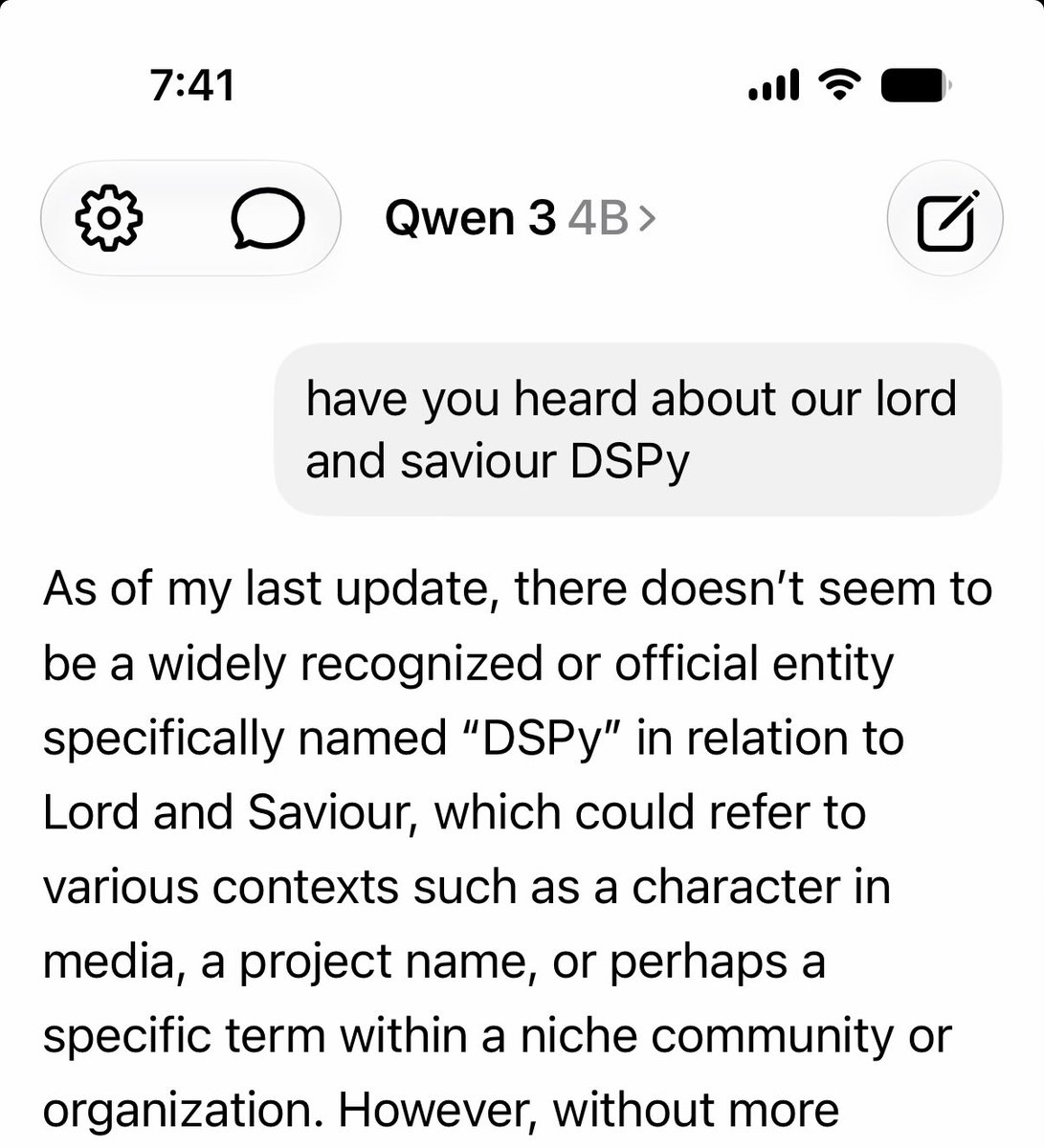
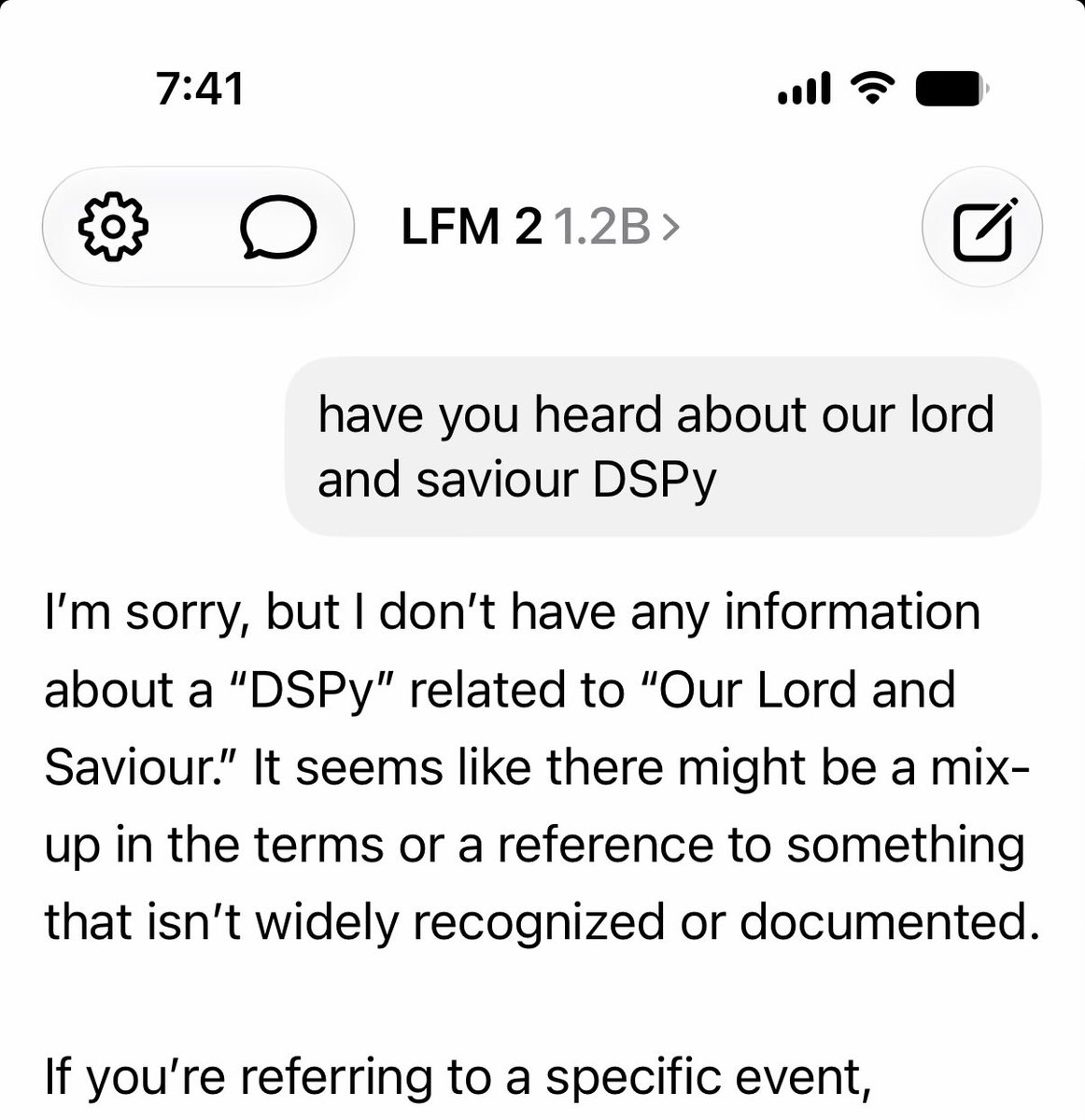
i’ve been playing with apple foundation model for a while it’s as fast as the other small models but seems to know a lot more. it punches way about other 3b models
22
2,338
👀
Jun 9

we're starting to send out invites for the our first Midjourney hardware launch and i feel like im missing some important mutuals. poke me if you haven't gotten an invite and think you should. we have a few spots left.
480