
IT consultant, technology user, tinkerer and sometimes Klingon ; tips pitch@technologyjournalist.com
Joined July 2008
- Tweets 49,960
- Following 2,654
- Followers 65,432
- Likes 127,262
6,875 Photos and videos













Pinned Tweet

3 May 2023
Sean Michael Kerner's Spring 2023 Human Writer certificate authory.com/SeanMichaelKerne…
That's write I'm human. I write about #AI. Skynet hasn't won (yet).
5
9
31
8,131

Moonshot AI releases Kimi K2.7-Code, claiming 30% lower reasoning token usage compared to K2.6, available under a modified MIT license (@techjournalist / VentureBeat)
(Visit Techmeme dot com for the link and full context!)
1
3
27
3,731
Jun 12
I've had the good fortune to connect a bunch with @beevek over the last 10 years (first NS1, an IBM Company, now @NetBoxLabs ). It's just astounding to me to see an open-source project go from being -this is how we now what we have in our network - to being a foundational element of understanding and the lifecycle of the biggest network infrastructure deployments networkworld.com/article/418…
2
6
241
Sean Kerner retweeted

Jun 12
NetBox at 10: Network inventory tool now a full infrastructure intelligence platform
spr.ly/6018B87TLs
1
3
362

Lots of people asked how I used Fable to edit its own launch video so I made a video about that!
TLDR it wrote a lot of code & tool calls to use transcription services, ffmpeg, do colorgrading, use the figma mcp, make remotion UI and render it.
I didn't touch a video editor.
293
618
9,215
957,370
Sean Kerner retweeted

This silent Android feature scans your photos for 'sensitive content' - how to uninstall it zdnet.com/article/android-sa… via @ZDNET & @sjvn
Get your nose out of my phone, Google!
1
1
107
Sean Kerner retweeted

Jun 12
AI memory sounds like personalization. In practice, it is context governance.
New research from Writer (writer.com/engineering/perso…) showing that memory systems can make AI models worse, not better. The issue is not mysterious. When user preferences and past context fill more of the model’s working memory, the model can start anchoring on irrelevant or wrong information.
One example from the research is painfully simple.
If a system remembers that a user likes “Station Eleven,” it becomes more likely to name “Station Eleven” when asked for a bestselling dystopian book, even when the user preference is irrelevant. The effect reportedly increased with memory compression tools like Mem0 and Zep.
That is cute in a book recommendation workflow.
It is not cute in finance, clinical operations, legal review, security triage, or executive decision support.
The enterprise lesson is straightforward:
Memory is not a feature you just turn on.
It needs scope, expiration, provenance, retrieval rules, and a way to separate durable user preferences from accidental user misconceptions. Otherwise, “personalized AI” quietly becomes “AI that agrees with your previous mistake.”
This is especially relevant in healthcare and enterprise operations, where context can be useful and dangerous at the same time.
Day 2 question:
Who owns memory quality in your AI system after six months of real use?
Not who enabled it. Who audits it?
#EnterpriseAI #AIGovernance #AIAgents #HealthcareAI #LLMOps #AIProductManagement

3
1
2
158
Sean Kerner retweeted

Jun 9
Apple's new on-device AI stores 20B parameters in flash memory — activating only what each prompt needs. The on-device memory wall just moved.
venturebeat.com/ai/on-device…
5
7
1,276
Sean Kerner retweeted
Jun 9
Cohere's open-source coding agent runs on a single H100 and ranks in the top 10 for output speed — but generates 3x more tokens than comparable models.You said: the title is not good, read the seo guide
venturebeat.com/ai/cohere-op…
1
5
3
1,346
Sean Kerner retweeted
Jun 11
The typewriter model is out. Google's DiffusionGemma generates text in parallel and self-corrects as it goes — 4x faster on a single GPU, with a quality trade-off it owns up to.
venturebeat.com/ai/googles-d…
4
9
1,185
Sean Kerner retweeted
Jun 11
New research cuts LLM context 16x before decode — 8.8x faster inference than every KV cache method tested. Open-sourced on HuggingFace.
venturebeat.com/ai/context-c…
3
4
1,148
Jun 11
Cohere open-sources a coding agent that runs on a single H100 venturebeat.com/technology/c… via @VentureBeat
2
8
409
Jun 11
Google's open source DiffusionGemma generates text 4x faster by scrapping token-by-token generation — but there are trade-offs venturebeat.com/technology/g… via @VentureBeat
1
94

Alright, Claude Fable 5 is good.
But Codex with a simple /goal is getting ridiculous:
"Build a Minecraft-inspired voxel fairground with rides and mini-games."
I left for 20 minutes and came back to a functional voxel game.
Fable 5 makes it beautiful:
“Create a beautiful Minecraft-like world.”
Codex makes it work:
“Create a Minecraft-like game that works.”
13
6
58
7,076
Sean Kerner retweeted

Jun 9
Imagine AWS announcing in 2017 that EC2 instances would run invisibly slower if it detected you were building a competing cloud.
Anthropic just shipped exactly that for Fable 5 and called it a safeguard.

Anthropic says Fable 5 has invisible safeguards that use prompt modification, steering vectors, or PEFT to limit its effectiveness for frontier LLM development (@maba_xr / The Decoder)
(Visit Techmeme dot com for the link and full context!)
22
109
1,442
43,808
Sean Kerner retweeted

Jun 10
PSA: If you used Claude Fable-5 today with memory turned on you just violated all your NDAs. Anthropic requires a 30 day retention policy including human review, and the memory feature (on by default) searches past chats for context, so sensitive historical chats get pulled in.

62
160
2,470
309,723
Sean Kerner retweeted

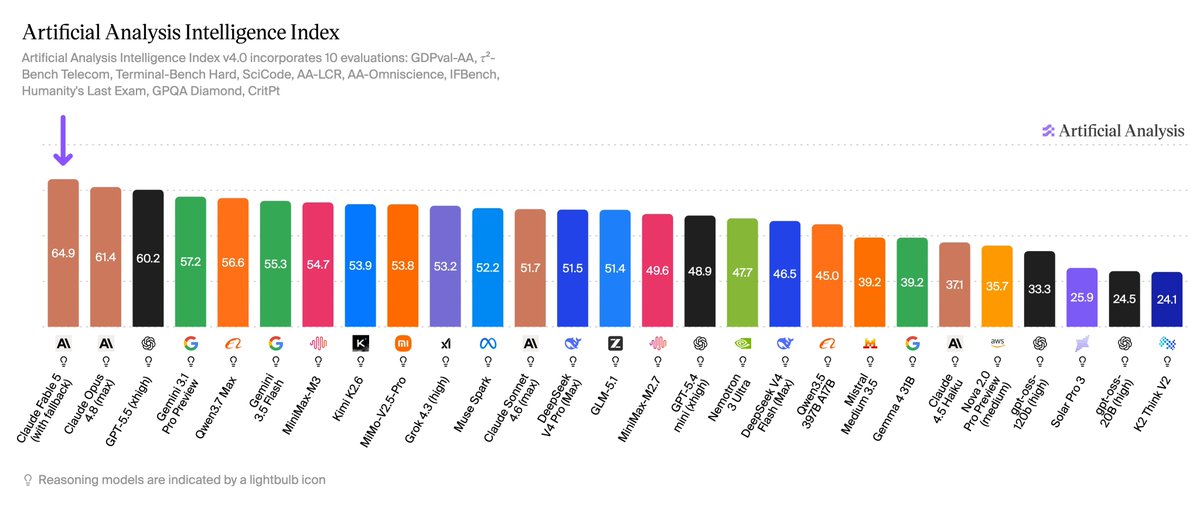
Claude Fable 5 launched today at #1 on the Artificial Analysis Intelligence Index, putting Anthropic nearly 5 points ahead of any other lab’s best model
We supported @AnthropicAI with pre-release evaluation of Claude Fable 5. Claude Fable 5 scores 64.9 on the Artificial Analysis Intelligence Index, claiming the #1 rank overall. It is ~5 points ahead of the closest non-Anthropic model (GPT-5.5), and Anthropic models now occupy both of the top 2 places.
Key takeaways for Claude Fable 5 (adaptive reasoning with max effort and Opus 4.8 as fallback model):
➤ New safety guardrails for Mythos-class models: Claude Fable 5 uses the same underlying model as Claude Mythos 5 for public usage, with additional guardrails for potentially-harmful cybersecurity, biology, chemistry, and distillation-related queries. We tested Fable 5 using Anthropic’s new ‘fallback’ mechanism, which can route safety-flagged messages to Claude Opus 4.8. Anthropic states that fallback occurs in fewer than 5% of sessions on average, and we recorded fallback routing in ~8% of tasks across the Intelligence Index (mostly in scientific questions from evaluations like GPQA, AA-Omniscience and Humanity’s Last Exam)
➤ State-of-the-art Intelligence: Claude Fable 5 takes the #1 position on the Artificial Analysis Intelligence Index, scoring 64.9 and setting the highest score on 5 of the 10 underlying benchmarks. On AA-Omniscience, our knowledge and hallucination benchmark, Fable 5 scores 40, 7 points over the previous leader, Gemini 3.1 Pro Preview, driven primarily by higher accuracy. We generally observe a strong relationship between AA-Omniscience accuracy and model size in open weights models, which suggests Fable 5 could be larger than previous public Anthropic models
➤ Frontier agentic capability: Claude Fable 5 is at the frontier across all three agentic evaluations in the Index: GDPval-AA (real-world work tasks), Terminal-Bench Hard (agentic coding), and Tau2-bench Telecom (tool use for customer service). Its GDPval-AA Elo of 1932 is a significant jump from the previous leader, Claude Opus 4.8, further extending Anthropic’s lead in agentic capabilities
➤ Leading HLE score, but refusal and fallback in 9% of tasks: Claude Fable 5 scores 53% on Humanity’s Last Exam, more than 7 points ahead of the next-best model, Claude Opus 4.8 (max). Fable 5 triggers safety guardrails on 9% of HLE tasks, falling back to Claude Opus 4.8. Including this fallback usage, running HLE with Fable 5 costs ~$2.2k, the highest of any model we have evaluated
Key model details:
➤ Context window: Claude Fable 5 retains the same 1M token context window as Claude Opus 4.8
➤ Price: Claude Fable 5 is priced at $10/$50 per 1M input/output tokens, 2x the token price of Claude Opus 4.8. The cache write/read price is $12.50/$1 per million tokens
➤ Availability: Claude Fable 5 is included in Pro, Max, Team, and seat-based Enterprise plans through June 22, consuming 2x Opus usage. From June 23, usage will require credits, with Anthropic saying it plans to restore subscription access once capacity allows
35
69
792
74,497
Sean Kerner retweeted

Jun 9
wow... Claude Fable 5 completes Pokémon FireRed using only vision.
It relies solely on raw game screenshots, with no maps, navigation tools, or extra game-state data.

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
26
57
820
209,908
Sean Kerner retweeted

Jun 9
This is a super exciting release - Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model "gets it" and it will just go, and it's never felt this tempting to stop looking at the code at all (but don't do this in prod!). The model still has quirks that people will run into and the safeguards are configured to be a little too trigger happy for launch, which can hopefully be tuned over time.
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref). Really looking forward to all the things people build!
Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
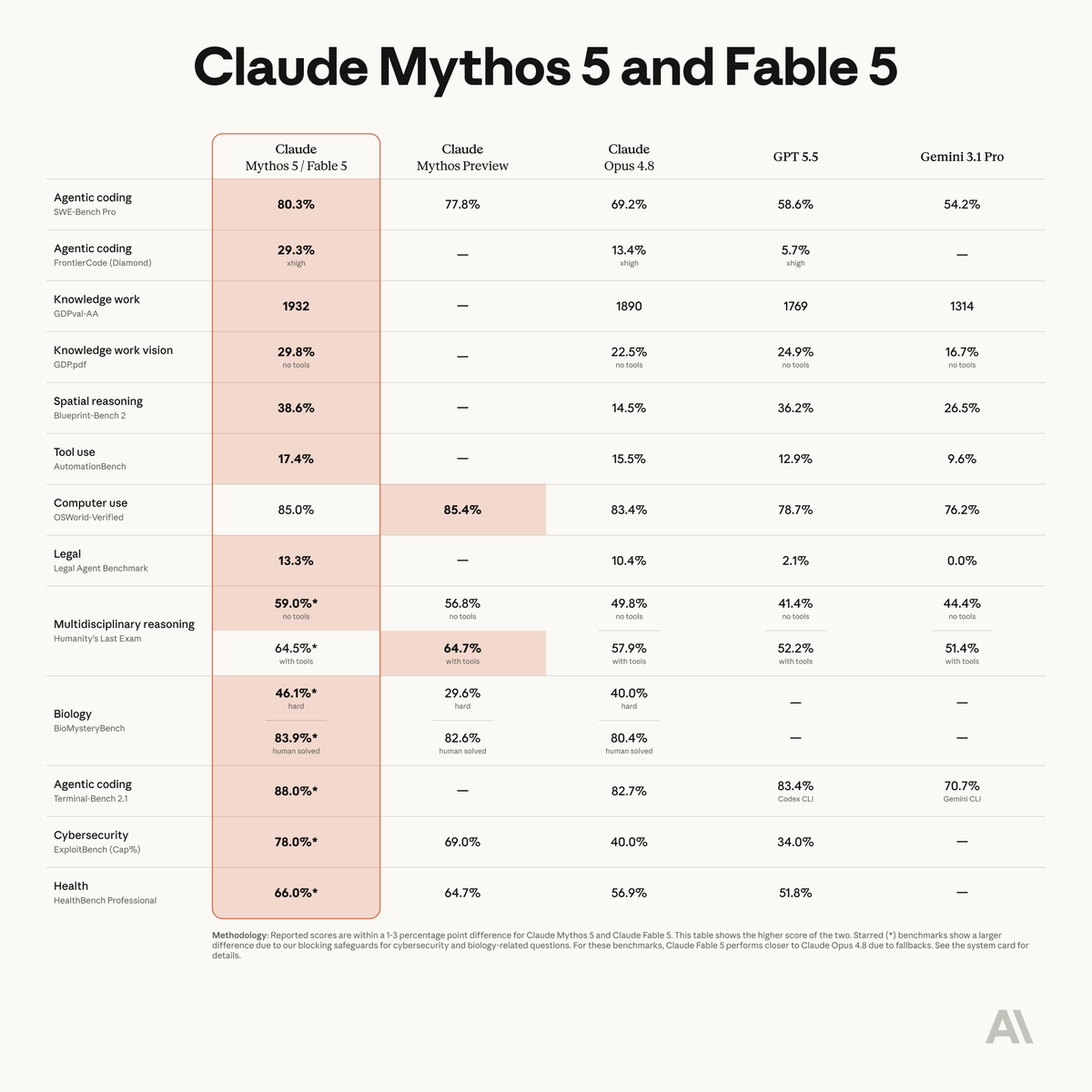
ALT Benchmark table titled Mythos 5 & Fable 5, comparing Claude Mythos 5 and Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
1,266
2,359
25,238
2,671,923
Sean Kerner retweeted

Jun 9
Try Claude Mythos at 25% off on Replit.
Jun 9

High Effort handles your most complex builds with ease on Replit.
Now powered by Claude Fable 5.
25% off for the next 7 days.

24
29
515
46,277
Sean Kerner retweeted

Jun 9
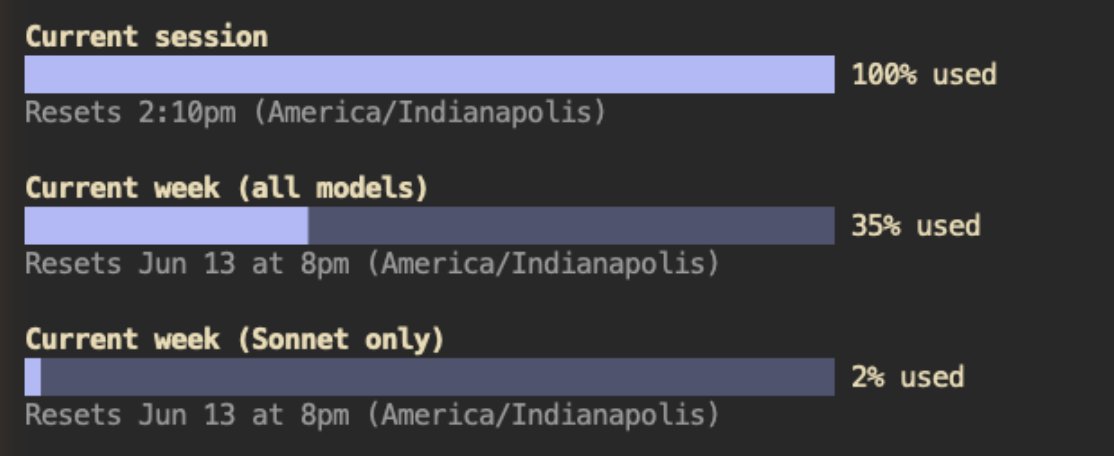
I hit my usage limits on my $200/month Claude Max subscription in less than 30 minutes using Claude Fable 5.
488
305
6,292
829,553