
AI Lab @AntGroup, we envision AGI as humanity's shared milestone. Our Language Model @AntLingAGI and LLaDA, Embodied AI @robbyant_brain, OSS projects AReaL etc.
Joined March 2025
- Tweets 120
- Following 18
- Followers 1,730
- Likes 98
8 Photos and videos





InclusionAI retweeted

May 14
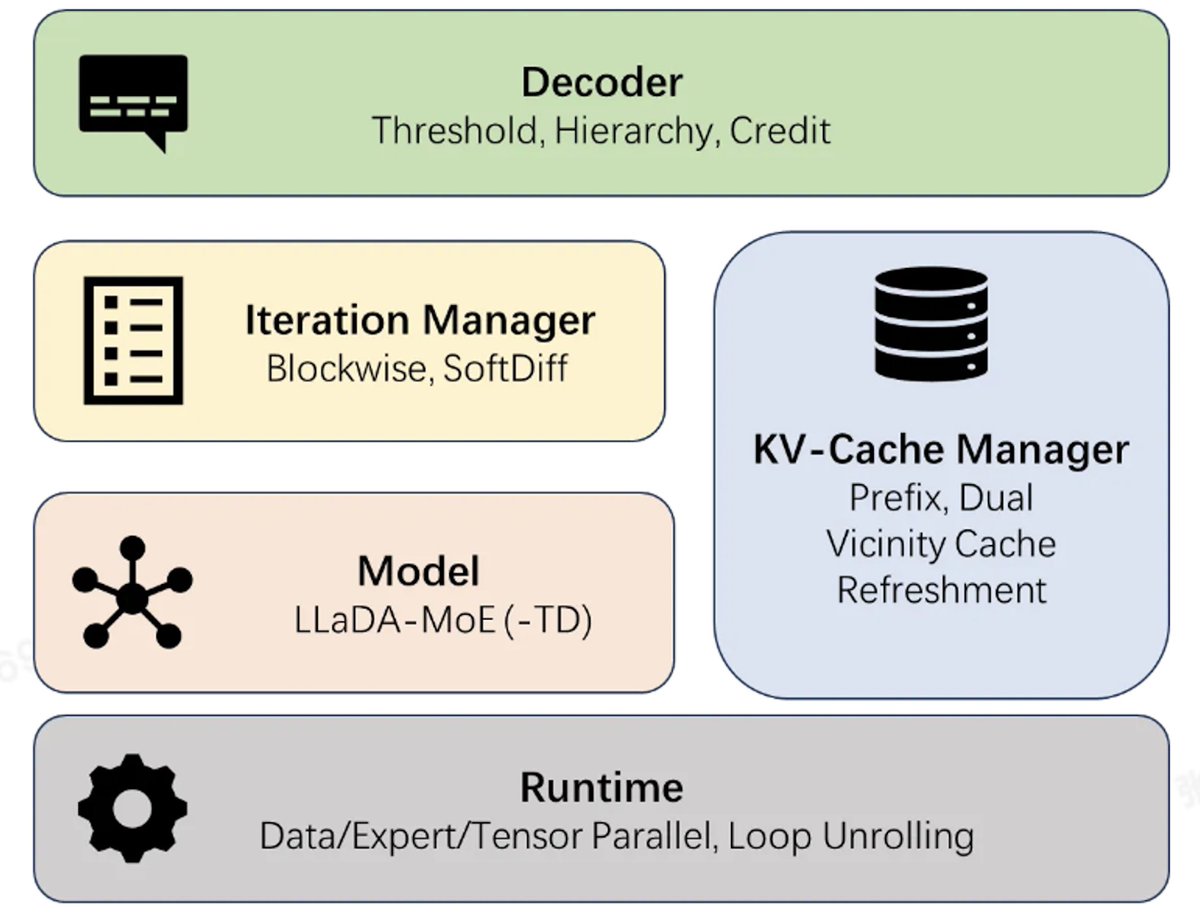
Ring-2.6-1T is now open source! 1T-parameter thinking model with two reasoning gears and SOTA Agent execution. 🚀
🔗 modelscope.cn/models/inclusi…
🤖 Stronger Agent execution: SOTA on PinchBench (87.60) and ClawEval (63.82), top-tier on TAU2-Bench and GAIA2-search. SWE-Bench Verified 74.00.
🎯 high / xhigh Reasoning Effort: high for production Agent workflows, xhigh for hard reasoning (AIME 26: 95.83, GPQA Diamond: 88.27)
⚡ Async RL Popsicle algorithm: stable long-cycle RL training at trillion-scale
Compatible with OpenClaw, Claude Code, OpenCode, Kilo Code, and more.
2
17
150
7,028

May 14
Introducing. Ring-2.6-1T! #OpenSource #LLM
✅Advanced agentic workflow support
✅Reasoning effort levels: high for agentic tasks, xhigh for complex reasoning
✅Scalable asynchronous RL
🤗 Hugging Face huggingface.co/inclusionAI/R…
📷 ModelScope modelscope.ai/models/inclusi…
May 14

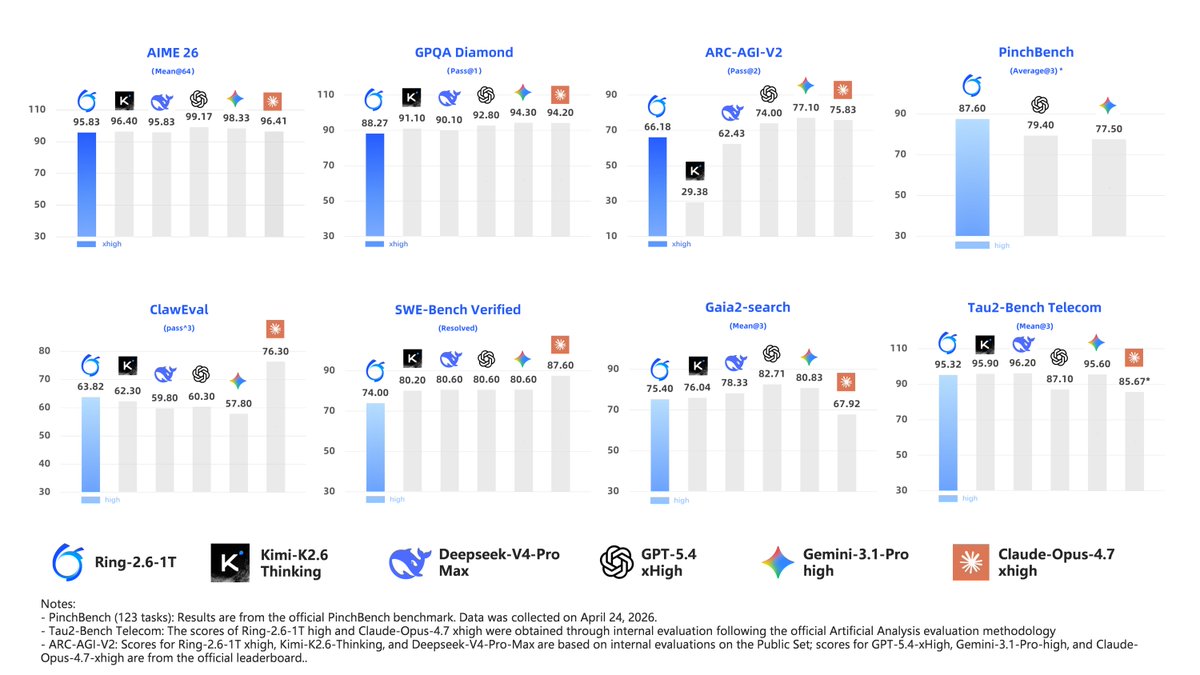
🚀 Ring-2.6-1T is now open source.
A trillion-scale flagship thinking model built for real-world complex tasks: Agent workflows, coding & engineering, long-horizon tasks, complex reasoning, research, and enterprise automation.
It is designed to move beyond “answering” toward execution: understanding context, planning steps, calling tools, and staying stable across long task chains.
Highlights:
- Advanced agentic workflow support.
- Reasoning effort levels: high for agentic tasks, xhigh for complex reasoning.
- Scalable asynchronous RL via the IcePop algorithm, enabling stable, trillion-scale training for long-horizon agentic RL.

3
8
23
2,949
InclusionAI retweeted

May 8
Ring-2.6-1T from @AntLingAGI is now live on @OpenRouter with free access available until May 15 PT.
1T total parameters · 63B active parameters
Built for real-world agent workflows:
• Coding agents
• Tool use
• Long-horizon execution
• Lower token overhead with adaptive reasoning
Designed for advanced autonomous systems where capability, latency, and cost efficiency all matter.
Powered by Novita AI
4
4
35
3,877

Ring 2.6 1T from @TheInclusionAI is live in Kilo, free for a limited time.
Worth noting: Ling 2.6 1T shot to the top of our leaderboard right after launch.
Both available now in the model picker! 🔥
May 8
We are launching Ring-2.6-1T, a trillion-parameter flagship thinking model engineered for real-world complex tasks and production env: 🚀
- Adjustable Thinking Effort: dynamic compute mechanism to flexibly balance cognitive depth, token cost, and execution speed;
- Agent-Optimized: Built for high-frequency workflows, delivering rapid multi-step execution and tool orchestration with SOTA stability;
- Deep Thinking: Unlocks the model's maximum capability ceiling for rigorous mathematical logic and scientific research;


3
25
4,851
Ring-2.6-1T is now 1️⃣week free on @OpenRouter!
✅Lower token overhead and rapid multi-step execution
✅Suitable for general and coding agent use cases
✅Designed to deliver reliable execution in production workflows at a rational inference cost
start now🤗 openrouter.ai/inclusionai/ri…
May 8
We are launching Ring-2.6-1T, a trillion-parameter flagship thinking model engineered for real-world complex tasks and production env: 🚀
- Adjustable Thinking Effort: dynamic compute mechanism to flexibly balance cognitive depth, token cost, and execution speed;
- Agent-Optimized: Built for high-frequency workflows, delivering rapid multi-step execution and tool orchestration with SOTA stability;
- Deep Thinking: Unlocks the model's maximum capability ceiling for rigorous mathematical logic and scientific research;
2
2
9
695
AReaL is joining the @PyTorch Landscape🎉landscape.pytorch.org
Fully async, modular, built for the agentic AI era. AReaL is a scalable, RL infrastructure designed to bridge foundation model training with modern agent-based applications.
Explore AReaL: github.com/inclusionAI/AReaL
2
6
21
6,470
InclusionAI retweeted

May 7
Announcing Ling-2.6-1T by inclusionAI, now available on OpenRouter. 🚀
This trillion-parameter flagship instruct model is built for real-world agents. It utilizes a “fast thinking” approach to cut costs by ~75% while maintaining SOTA performance on AIME26 and SWE-bench Verified. Ideal for:
- Advanced coding
- Complex reasoning
- Large-scale agent workflows

20
10
184
11,992
InclusionAI retweeted
Apr 29
One more thing: we welcome you to join the AntLing Discord community! 🤗🥳🥳🥳
discord.gg/jQtDsU5J6C
1
10
1,122
InclusionAI retweeted
Apr 29
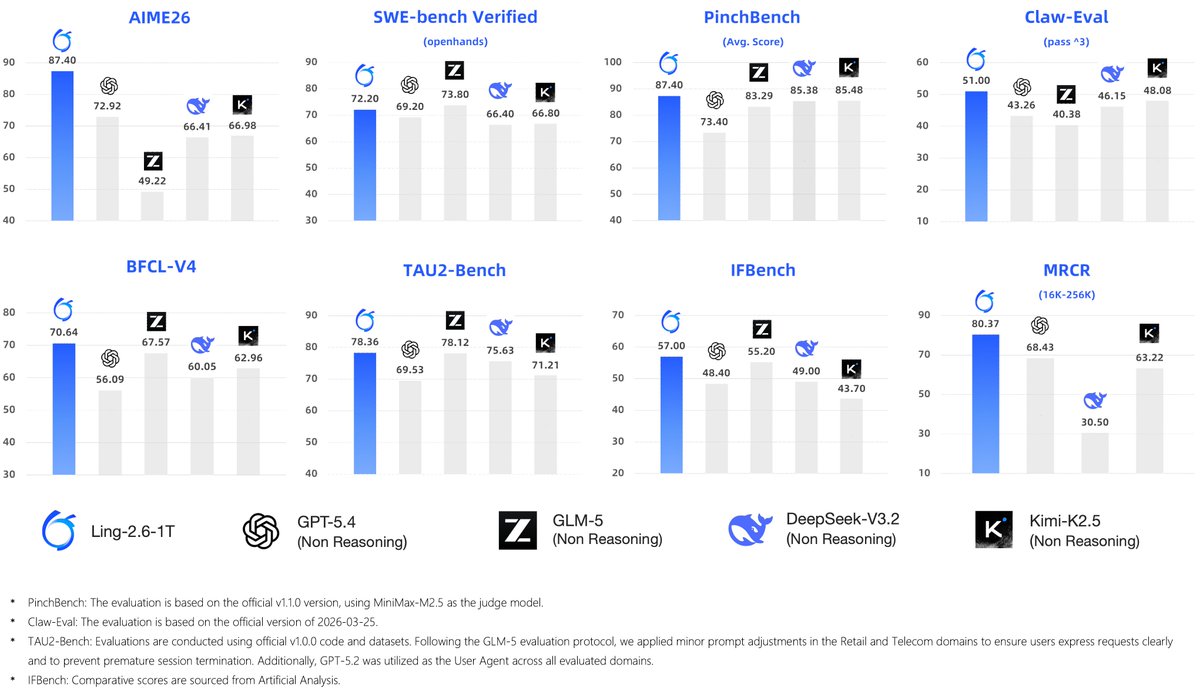
So excited to announce Ling-2.6-1T is now live on ModelScope!🔥
This 1T parameter model is built for complex agent workflows, multi-step execution and long-context understanding. It truly delivers in production.
📊The benchmarks speak for themselves:
- AIME26 — leads all non-reasoning models
- SWE-bench Verified, TAU2-Bench, BFCL-V4, PinchBench — first-tier open-source
- ~16M tokens on Artificial Analysis full eval — same efficiency story as Ling-2.6-flash
Works with Claude Code, OpenClaw, OpenCode & CodeBuddy ✅ SGLang & vLLM ready · Open weights available now 🚀
Explore on ModelScope 👇 modelscope.cn/models/inclusi…
modelscope.ai/models/inclusi…
4
11
143
10,224
Apr 29
Ling-2.6-1T, designed for precise instruct task execution is now #OpenSource🥂Built for the Agentic era, Ling-2.6-1T brings about a significant capability upgrade↗️ and top-tier performance.#LLM
🤗 Hugging Face: huggingface.co/inclusionAI/L…
📷 ModelScope: modelscope.cn/models/inclusi…
Apr 29
Last week, we introduced Ling-2.6-1T. Today, Ling-2.6-1T is officially an open model~ 🤗
1T total parameters · 63B active parameters
We bring values to developers by making it easier to test, deploy, customize, and build.
It is optimized to be "token efficiency" for real production needs:
• Lower token overhead: strong intelligence without long reasoning traces
• Reliable multi-step execution: better instruction, tool, context, and workflow control
• Production-ready deployment: from code generation to bug fixing, with broad agent framework compatibility
A sneak pick into the agentic capability in @opencode
4
2
35
3,653
Apr 28
📣Fast generation, high token efficiency, real task execution and improved experience, Ling-2.6-flash is now opensource!
🔧Available in BF16, FP8, and INT4 variants for different deployment needs.
Hugging Face: huggingface.co/inclusionAI/L…
ModelScope: modelscope.cn/models/inclusi…
Apr 28
Ling-2.6-flash is now officially open-sourced!
A fast, token-efficient Instruct model built for real-world agent workflows.
104B total parameters · 7.4B active parameters
Available in BF16, FP8, and INT4 variants for different deployment needs.
Key strengths:
- Fast generation: 215 tokens/s on Artificial Analysis Output Speed
- High token efficiency: only 15M tokens on the full AA Intelligence Index evaluation
- Real task execution: strong performance across coding, document processing, and lightweight agent workflows
- Improved experience: better Chinese-English switching and smoother compatibility with mainstream coding frameworks

2
3
36
5,492

📢 Ling-2.6-1T from @TheInclusionAI is live on @ZenMuxAI 🔥
Ant Group's trillion-param MoE flagship. 50B active per token. Open-source SOTA on SWE-bench Verified, AIME & agent benchmarks — no thinking tokens needed ⚡️
🔗 zenmux.ai/inclusionai/ling-2…

13
11
138
8,538
InclusionAI retweeted
Apr 27
✨ Inclusion AI's LLaDA2.0-Uni is open-source! A single MoE-based diffusion LLM that unifies visual understanding and image generation — natively, in one model.
Download on ModelScope 👉 modelscope.ai/models/inclusi…
Built on a single Mask Token Prediction paradigm, LLaDA2.0-Uni handles:
🖼️ Text-to-image synthesis at 1024×1024, with the option to "think" before drawing
🔍 Visual question answering, captioning, and document understanding on par with dedicated VLMs
✏️ Instruction-driven image editing — single or multi-reference, faithful to original details
🎨 Interleaved text-image reasoning, opening the door to a new class of multimodal chains
Released under Apache 2.0 — paper, code, and weights all open.
📄 modelscope.ai/papers/2604.20…
🔗 github.com/inclusionAI/LLaDA…

3
6
57
8,228
InclusionAI retweeted

Apr 23
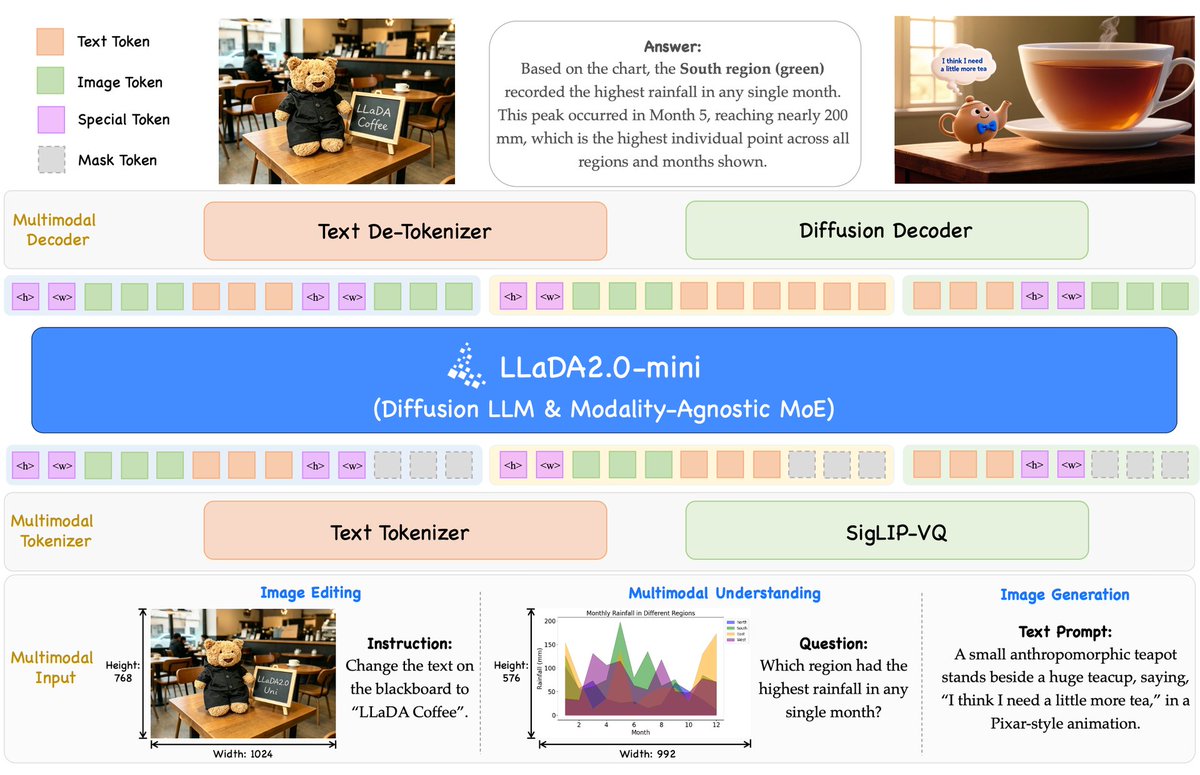
LLaDA2.0-Uni from Inclusion AI
Unified diffusion LLM for multimodal understanding and generation. Features MoE backbone with SigLIP-VQ tokenizer enabling 8-step image generation and native interleaved reasoning.
2
12
48
3,192
InclusionAI retweeted
Apr 23
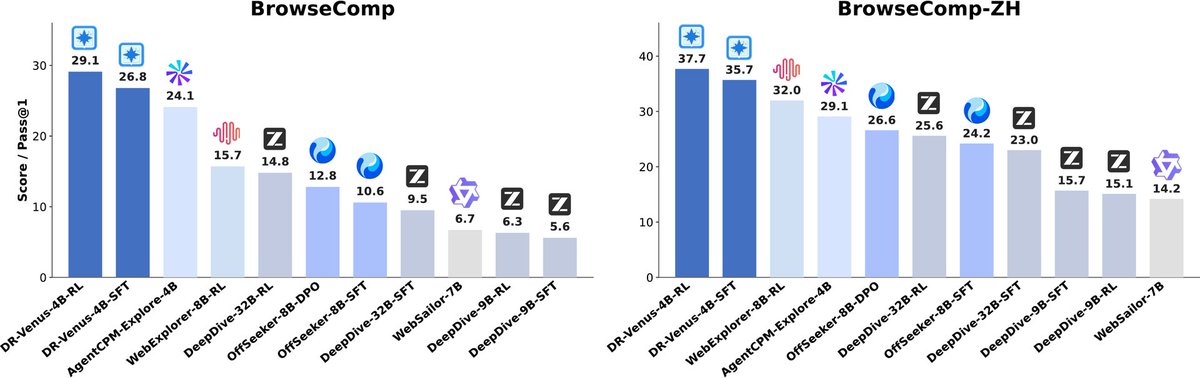
DR-Venus: a 4B parameter deep research agent trained on only 10K open data
Achieves frontier performance on edge-scale devices, outperforming prior 9B agents and narrowing the gap to 30B-class systems through agentic SFT and RL with information gain rewards.
2
12
46
3,414
Apr 24
Built for stable, high-speed execution in complex, real-world environments, meet Ling-2.6-1T!🥳Massive leap& top-tier performance, and 🛠️ Engineering-Task-Friendly.
We’re unlocking 1 week of free API access. Start testing now at @OpenRouter openrouter.ai/inclusionai/li…
Open-source model is on the way! Keep an eye out—more details dropping soon. 👀
#inclusionAI #LLM
Apr 23
🚀 Today, we are launching Ling-2.6-1T, a trillion-parameter flagship model designed for precise instruct task execution. By prioritizing a "Fast-Thinking" mechanism, it delivers SOTA intelligence with ultra-low token overhead, making token efficiency a first-class citizen.
7
1
24
2,055
Apr 23
Brand new release from our team! 🆕DR-Venus — exploring new possibilities for edge-scale deep research with just 10K open data.
🛠️ Built with a two-stage recipe:
1️⃣ Agentic SFT: strict trajectory cleaning long-horizon resampling for maximum data value
2️⃣ IGPO RL: turn-level rewards via information gain & format-aware regularization for stable long-horizon execution
#inclusionAI #deepresearch #AIAgent
Edge-ready GGUF format — deploy on your Mac today.
🐙 Code: github.com/inclusionAI/DR-Ve…
📄 Paper: arxiv.org/abs/2604.19859
🤗 Models: huggingface.co/collections/i…
5
1
16
765
Apr 23
We’re excited to introduce LLaDA2.0-Uni, the 💥first unified multimodal model in the LLaDA2.0 series.
Highlights:
🧠 One paradigm to rule all – With unified block-wise mask token prediction, LLaDA2.0-Uni achieves top-tier performance across visual understanding, high-fidelity image generation, and single/multi-reference image editing.
⚡ Efficient inference – A novel decoding strategy in the dLLM backbone, together with an 8-step distilled diffusion decoder, enables highly efficient inference. (SGLang support soon for even faster inference.)
🔄 Interleaved, intelligent, infinite – Unified discrete representations enable seamless interleaved generation and advanced interleaved reasoning capabilities.
Apr 23

After two months of teamwork, we’re excited to share our team’s latest achievement — LLaDA2.0-Uni, InclusionAI’s first multimodal LLaDA.
A unified discrete diffusion LLM built for both understanding and generation across text and images.
Highlights:
● One paradigm for VQA, doc understanding, and image generation
● Efficient inference with a new decoding strategy 8-step distilled decoder
● Interleaved text-image generation enabled by unified discrete representations
(SGLang support soon)
🤗 Hugging Face: huggingface.co/inclusionAI/L…
📷 ModelScope: modelscope.cn/models/inclusi…

9
17
140
16,306
Apr 23
🔧Try out and explore how LLaDA understand and generate the world.
📄 Technical Report: arxiv.org/abs/2604.20796
🤗 Hugging Face: huggingface.co/inclusionAI/L…
📷 ModelScope: modelscope.cn/models/inclusi…
🐙 Code: github.com/inclusionAI/LLaDA…
#dLLM #inclusionAI #LLaDA #Multimodal #Opensource #DiffusionModels
1
13
725
InclusionAI retweeted

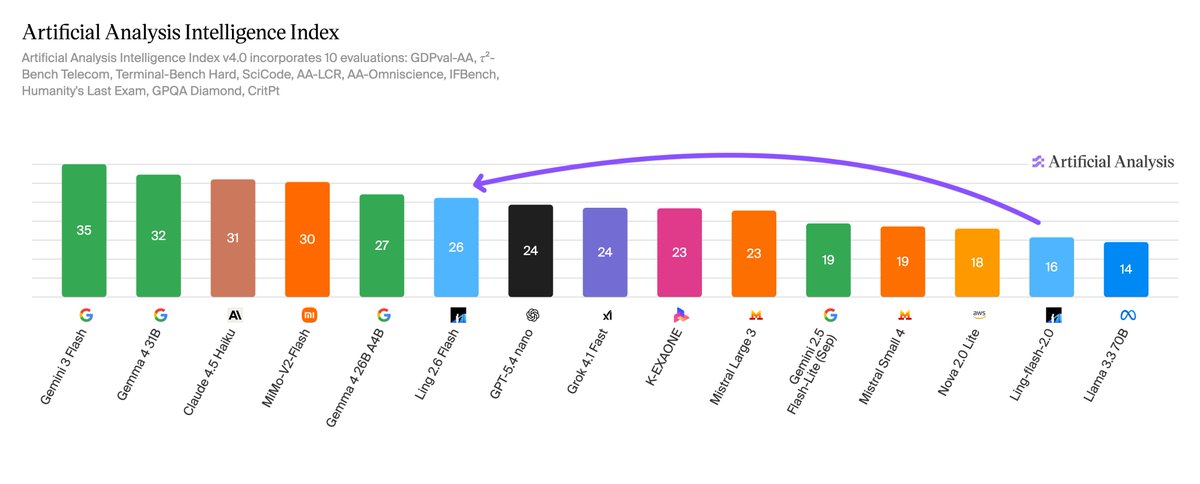
Ant Group's Ling 2.6 Flash scores 26 on the Artificial Analysis Intelligence Index, a 10-point jump from Ling-flash-2.0. It is one of few recent open weights releases focused on non-reasoning capabilities and focuses on a reasonable cost to intelligence ratio.
Ling 2.6 Flash is a non-reasoning model from Ant Group's @TheInclusionAI lab. Ant Group's model family comprises three series: Ling (non-reasoning), Ring (reasoning), and Ming (multimodal). Ling-flash-2.0 was the previous flash-tier non-reasoning model. Ling 2.6 Flash is expected to be open weights shortly after release, but as of today the weights have not been released on Hugging Face.
Key takeaways:
➤ At 104B total parameters with 7.4B active parameters, Ling 2.6 Flash (26) sits in intelligence near GPT-5.4 nano (Non-Reasoning, 24) and Gemma 4 26B A4B (Non-reasoning, 27), both models with comparable active parameter counts. However, at 18 points behind GLM-5.1 (Non-reasoning, 44), there remains a gap to frontier non-reasoning open weights models
➤ Ling 2.6 Flash is comparatively token efficient, using ~15M output tokens to run the Intelligence Index. This is comparable to Gemma 4 26B A4B (~14M) but a fraction of Qwen3.5 9B (~78M). Compared to models in the similar intelligence tier, Ling 2.6 Flash represents a reasonable efficiency tradeoff, which has positive effects on cost when deployed on larger workloads. At a price of $0.1 / million input tokens and $0.3 / million output tokens, Ling 2.6 Flash costs only ~$23 to run the full Artificial Analysis Intelligence Index.
➤ Gains from Ling-flash-2.0 were driven mostly by improvements agentic capabilities and instruction following. τ²-Bench jumped from 21% to 86% ( 65 points), IFBench from 34% to 57% ( 23 points), and GDPval-AA Elo from 425 to 783 ( 84%). Conversely, GPQA Diamond fell from 66% to 59% (-6 points) and SciCode from 29% to 27% (-2 points).
➤ AA-Omniscience performance is at -66 with 15% accuracy and 96% hallucination rate. This is consistent with the model's small 7.4B active parameter count. Knowledge recall benefits from larger parameter counts, and sub-10B active-parameter models systematically underperform on this metric.
Additional model details:
➤ Architecture: MoE, 104B total parameters, 7.4B active parameters
➤ Context window: 262K tokens (doubled from 128K for Ling-flash-2.0)
➤ Pricing: $0.10 / $0.30 per 1M input/output tokens (via Novita API)
➤ License: Weights not yet released ➤ Availability: Third party API through @novita_labs
8
8
184
19,494