
Alleged vague-poster. Enterprise token slinger and other GTM things at @OpenAI. A fan of NY sports, tech, memes & nice people. My opinions are my own.
Joined April 2011
- Tweets 23,945
- Following 4,614
- Followers 36,290
- Likes 41,545
2,378 Photos and videos










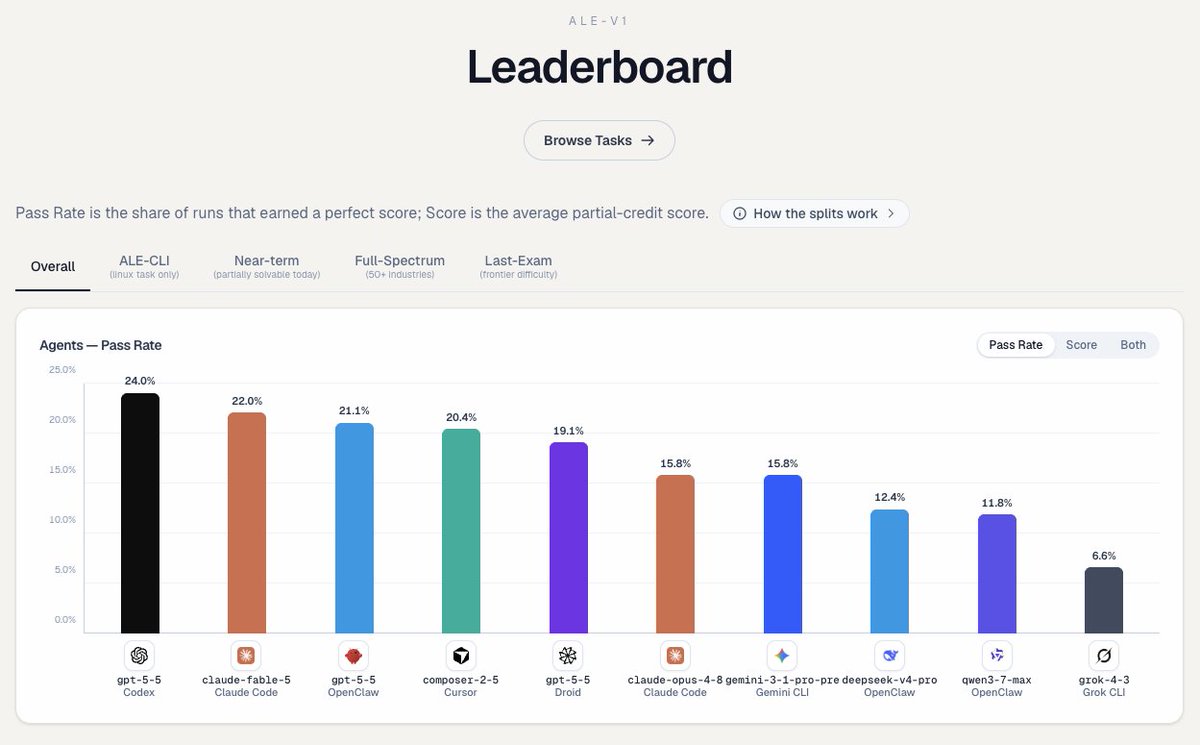





or not.
Jun 1

Spurs about to dunk on Knicks like Texas has been dunking on New York.
Go Spurs Go 🔥👽

1
11
1,692
Adam.GPT retweeted

A Knicks fan claims Victor Wembanyama had him kicked out of a $20,000 Ritz-Carlton penthouse during the NBA Finals after a friend allegedly told Wemby, “Good luck tonight, big guy,” per @nypost
The fan says his group spent $750,000 on Game 4 tickets and was removed from the hotel just minutes after the interaction.
The Ritz-Carlton and Wembanyama’s agent did not respond to requests for comment.
(Via nypost.com/2026/06/13/sports…)

616
295
9,397
2,734,289
Adam.GPT retweeted

Jun 12
wow sick new billboards from openai




80
212
4,498
2,582,728
Adam.GPT retweeted

Jun 12
📝 Turn any @ChatGPTapp to a note
Now you can turn any message from ChatGPT into an interactive writing block - just highlight chat's response and click Create Note
These can be saved to your library then retrieved / referenced in a future chat conversation
29
22
339
27,636
Adam.GPT retweeted

Jun 12
And it doesn’t stop at answers.
Describe what you’re building and the agent will create a custom guide with a tailored prompt and relevant resources.
Open the guide in Codex or copy it as Markdown for your coding agent.
3
13
291
25,620
Adam.GPT retweeted
Jun 12
Ask our developer docs. They’ll show you the way
The new docs agent on 🔗developers.openai.com helps you find answers about OpenAI products and takes you directly to the relevant documentation.
49
58
935
161,268

fable is expensive
wrote a quick arbitrage skill for claude code to offload the hard things to fable and everything else to gpt 5.5 xhigh
it will try to be always on or you could say "implement with arbitrage"
github.com/blader/arbitrage
26
18
655
51,589
Adam.GPT retweeted

Jun 12
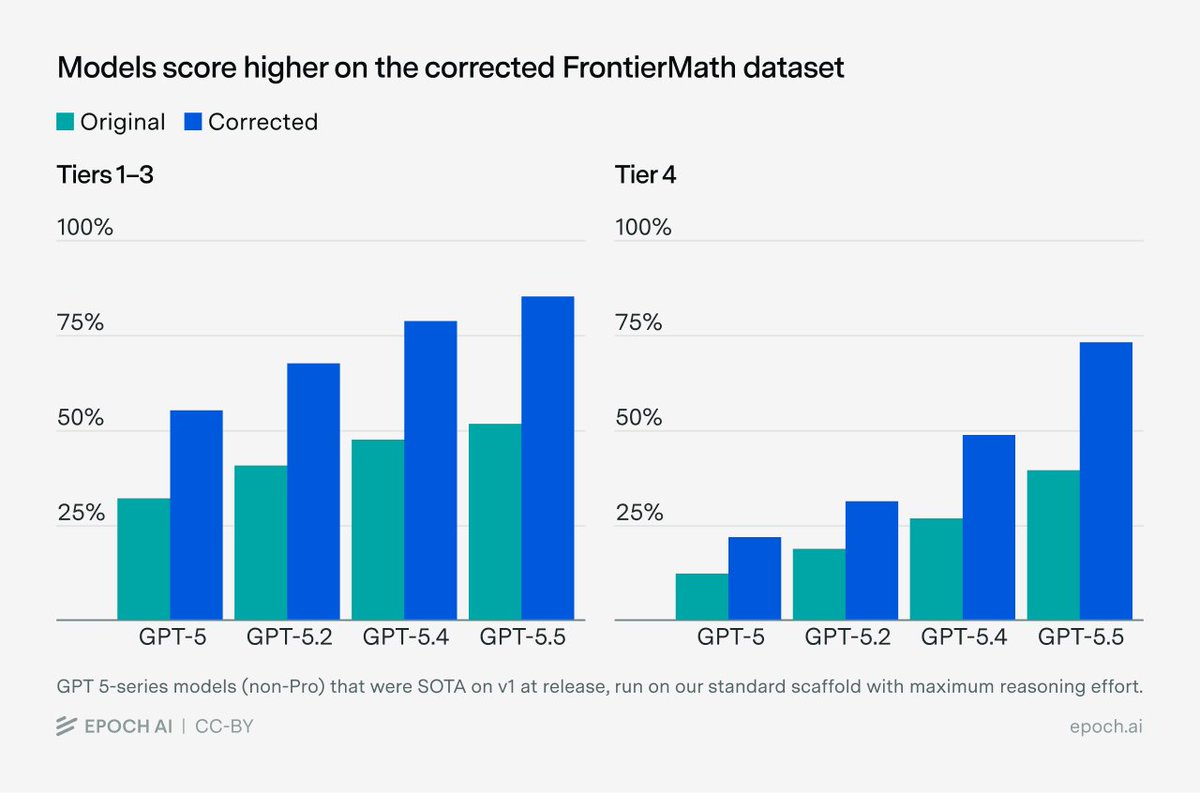
FrontierMath: Tiers 1–4 (v2) is live.
We concluded an audit that addressed errors in 42% of problems. Rankings are similar but scores are higher across the board. The current leaders are GPT-5.5 (xhigh) with 85% on Tiers 1–3 and Google’s AI co-mathematician with 76% on Tier 4.
27
66
574
113,436
Adam.GPT retweeted

Jun 12
had an idea for a big fable project, set it up, and let it cook
came back an hour later and it had triggered the safeguards and fell back to 4.8 10 minutes in
back to codex 😬
63
21
884
113,171
Adam.GPT retweeted

Clearly, Fable is doing a lot of work, and unleashing a ton of agents. To review a short technical note, it released 31 agents, coded simulations to verify my results, did "adversarial reviews". Eventually, it only made the assumptions slightly more rigorous. It is all good. For a four-page technical note a little code, though, it consumed all my Pro session tokens, *plus* $17 worth of credits. It is ridiculously expensive. I have 20-page reports that are way more complex than this. I can see how Anthropic has entered the phase of market-clearing prices, yield management, and pre-IPO.
I recall Boris Cherny saying in a podcast, "run Opus [4.6], not Sonnet. It's worth it". I feel comfortable saying that running your top-shelf model is *not* worth it anymore.
Decreasing returns, on most tasks. Like in the real world, some people can be real smart, but real expensive.
58
58
1,081
162,901
Adam.GPT retweeted

Jun 12
Having tested fable 5 for a bit now my thoughts are is it does some hard stuff extremely well but day to day I still prefer 5.5
First thing people are going to test 5.6 on though is the same threejs, games with physics, web dev type stuff.
Ignoring the restrictions, good model.
25
10
358
19,617
Adam.GPT retweeted

Jun 12
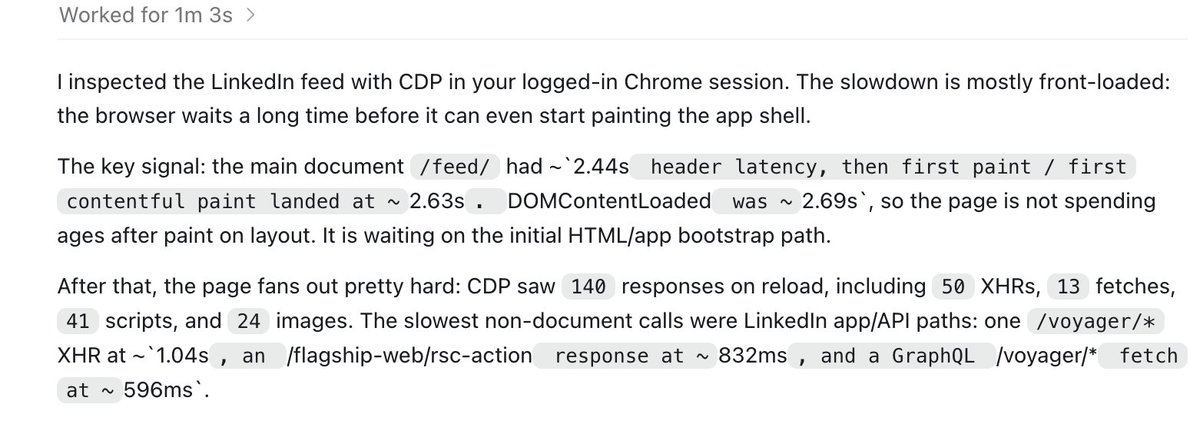
Two browser updates for today's Thursday Codex drop:
Dev Mode faster browser use.
1/ Dev Mode
Now, you can give full CDP (Chrome DevTools Protocol) access to your Codex agent so it can be more helpful in deep developer workflows.
By turning this on, your agent will be able to inspect:
- runtime errors & console log
- network requests, responses & failures
- live DOM, storage, and page state
This is really helpful for debugging gnarly bugs and making your apps more performant.
To try it, go to your codex settings, and search developer mode to toggle it on!
2/Browser Use Perf improvements
Using Codex to drive your browser should feel much faster after this week's update, up to 2x in many cases!
We made the plugin a lot more efficient, and truncated a lot of redundant text in the skill.
Let us know what you think!
23
20
305
40,295
Adam.GPT retweeted
Jun 12
Introducing developer mode for browser use in Chrome and the Codex in-app browser.
Codex can use the Chrome DevTools Protocol (CDP) to debug browser issues by profiling JavaScript performance and inspecting console output, network traffic, and page state.
94
206
2,982
357,700

Adam.GPT retweeted

Jun 11
Fable 5 refused 200 out of 200 ProgramBench tasks lmao
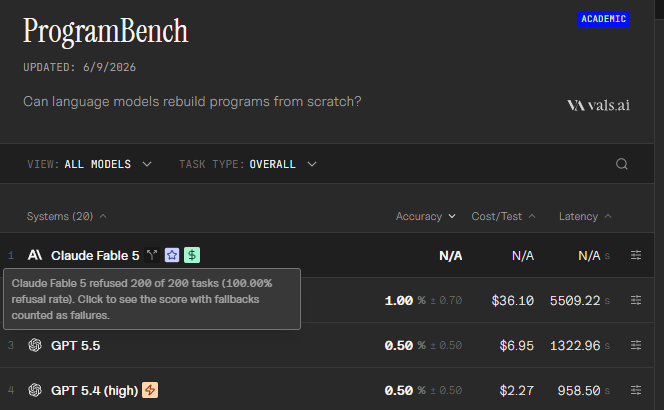
126
184
5,156
405,501
Adam.GPT retweeted

Jun 11
fable is overall very good obviously but it feels like a lot of people have never used a gpt-5.5 tier model before
16
8
275
14,963
Adam.GPT retweeted

Jun 11
> We tested Fable 5 using Anthropic’s new ‘fallback’ mechanism, which can route safety-flagged messages to Claude Opus 4.8.
🤦♂️🤦♂️🤦♂️🤦♂️🤦♂️🤦♂️🤦♂️
And it affected 8% of the samples, so it score needs to be revised down, possibly quite a bit, bringing it closer to the rest of the pack

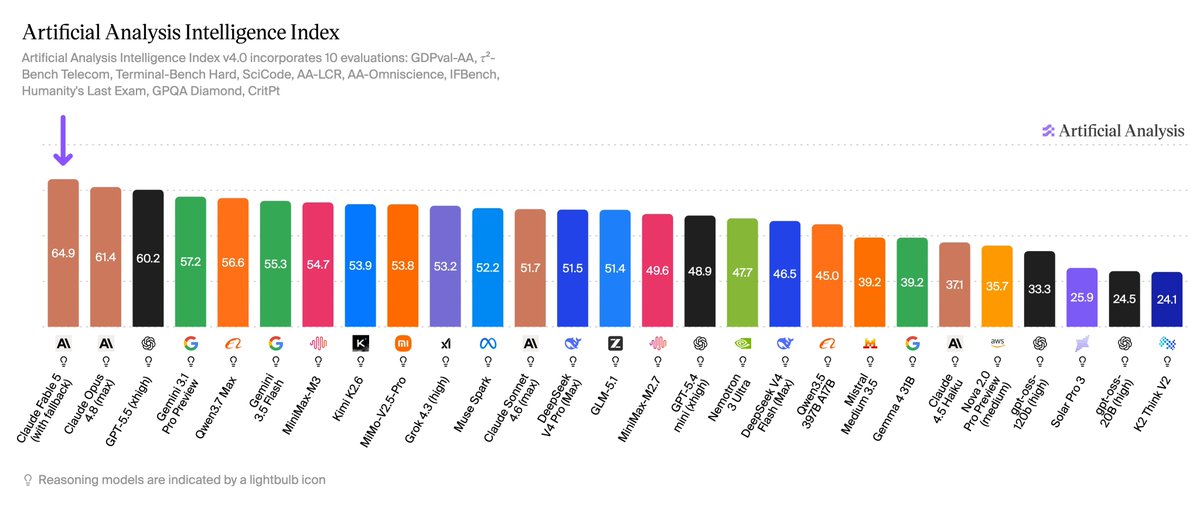
Claude Fable 5 launched today at #1 on the Artificial Analysis Intelligence Index, putting Anthropic nearly 5 points ahead of any other lab’s best model
We supported @AnthropicAI with pre-release evaluation of Claude Fable 5. Claude Fable 5 scores 64.9 on the Artificial Analysis Intelligence Index, claiming the #1 rank overall. It is ~5 points ahead of the closest non-Anthropic model (GPT-5.5), and Anthropic models now occupy both of the top 2 places.
Key takeaways for Claude Fable 5 (adaptive reasoning with max effort and Opus 4.8 as fallback model):
➤ New safety guardrails for Mythos-class models: Claude Fable 5 uses the same underlying model as Claude Mythos 5 for public usage, with additional guardrails for potentially-harmful cybersecurity, biology, chemistry, and distillation-related queries. We tested Fable 5 using Anthropic’s new ‘fallback’ mechanism, which can route safety-flagged messages to Claude Opus 4.8. Anthropic states that fallback occurs in fewer than 5% of sessions on average, and we recorded fallback routing in ~8% of tasks across the Intelligence Index (mostly in scientific questions from evaluations like GPQA, AA-Omniscience and Humanity’s Last Exam)
➤ State-of-the-art Intelligence: Claude Fable 5 takes the #1 position on the Artificial Analysis Intelligence Index, scoring 64.9 and setting the highest score on 5 of the 10 underlying benchmarks. On AA-Omniscience, our knowledge and hallucination benchmark, Fable 5 scores 40, 7 points over the previous leader, Gemini 3.1 Pro Preview, driven primarily by higher accuracy. We generally observe a strong relationship between AA-Omniscience accuracy and model size in open weights models, which suggests Fable 5 could be larger than previous public Anthropic models
➤ Frontier agentic capability: Claude Fable 5 is at the frontier across all three agentic evaluations in the Index: GDPval-AA (real-world work tasks), Terminal-Bench Hard (agentic coding), and Tau2-bench Telecom (tool use for customer service). Its GDPval-AA Elo of 1932 is a significant jump from the previous leader, Claude Opus 4.8, further extending Anthropic’s lead in agentic capabilities
➤ Leading HLE score, but refusal and fallback in 9% of tasks: Claude Fable 5 scores 53% on Humanity’s Last Exam, more than 7 points ahead of the next-best model, Claude Opus 4.8 (max). Fable 5 triggers safety guardrails on 9% of HLE tasks, falling back to Claude Opus 4.8. Including this fallback usage, running HLE with Fable 5 costs ~$2.2k, the highest of any model we have evaluated
Key model details:
➤ Context window: Claude Fable 5 retains the same 1M token context window as Claude Opus 4.8
➤ Price: Claude Fable 5 is priced at $10/$50 per 1M input/output tokens, 2x the token price of Claude Opus 4.8. The cache write/read price is $12.50/$1 per million tokens
➤ Availability: Claude Fable 5 is included in Pro, Max, Team, and seat-based Enterprise plans through June 22, consuming 2x Opus usage. From June 23, usage will require credits, with Anthropic saying it plans to restore subscription access once capacity allows
16
10
208
25,293