
Automated Enterprise Inference Stack & Research Lab
Joined May 2023
- Tweets 98
- Following 539
- Followers 415
- Likes 226
30 Photos and videos













Pinned Tweet

May 12
TheStage AI Platform is now open to everyone.
Automatically accelerate your models and download them to run in the cloud or on smartphones.
34
23
146
3,596,758
TheStage AI retweeted
Gemma4 E2B, compressed by @TheStageAI , from 9.3GB to 1.4GB, is running on iPhone 16e with tool calls!
The smallest and the best quality checkpoints open-sourced! @GoogleDeepMind
6
3
36
233,809
Jun 2
The smallest checkpoints for Gemma 4 E2B and E4B for local inference. Results for E2B:
size: 9.3 GB → 1.4 GB
speed: 113 tok/s on Apple M3
quality: -3% on ifEval
runs with: MLX, llama.cpp (coming)
Pareto-optimal, open source! Links to the blog post and GitHub repo ⬇️
@GoogleDeepMind @lmstudio @ollama @huggingface @ggerganov
2
5
22
275,008
May 17
Try it yourself, thestage.ai
May 12

TheStage AI Platform is now open to everyone.
Automatically accelerate your models and download them to run in the cloud or on smartphones.
2
5
316
Apr 10
Beyoncé heard cursing. TheWhisper heard Arsenal.
The fastest Whisper in the world.
Open-source real-time ASR.
Top 5 on OpenASR benchmarks.
1800 RTFx.
Built for live captions, transcription, and voice apps.
See the repo
4
19
179
2,655,479
Apr 8
For AI engineers, latency is product.
Wan 2.2 in Elastic Models now generates 5s of video in 34s on H100. Elastic Models is a library of accelerated open-source models.
Also new: TheWhisper at 1800 RTFx on a single H100 and instant FLUX LoRA switching.
Try it
14
41
570
7,655,245
Mar 19
How do you make text-to-music run in real time in production?
The model has to keep audio generation ahead of playback.
Our new case study with @MireloAI shows how inference optimization delivered up to 2.4х higher throughput.
See the full case study ↓
4
8
385
Mar 4
Proud to team up with @brilliantlabsAR and @neuphonicspeech on Halo’s on-device privacy engine.
Coming to Brilliant Labs’ Halo smart glasses: real-time voice vision, POV stays private.
ANNA GPU/NPU SDK memory manager for wake word, STT, TTS, diarization.
SDK demo 👇
6
9
25
2,321
Jan 22
Are you a big fan of jacket potato?
This is an open-source, real-time multilingual ASR for live speech.
It stays robust in heavy noise – even at SNR 0 dB.
That’s why it understands speech where people struggle to hear.
Use it for transcription, research, and multilingual apps
2
29
343
131,208
Jan 15
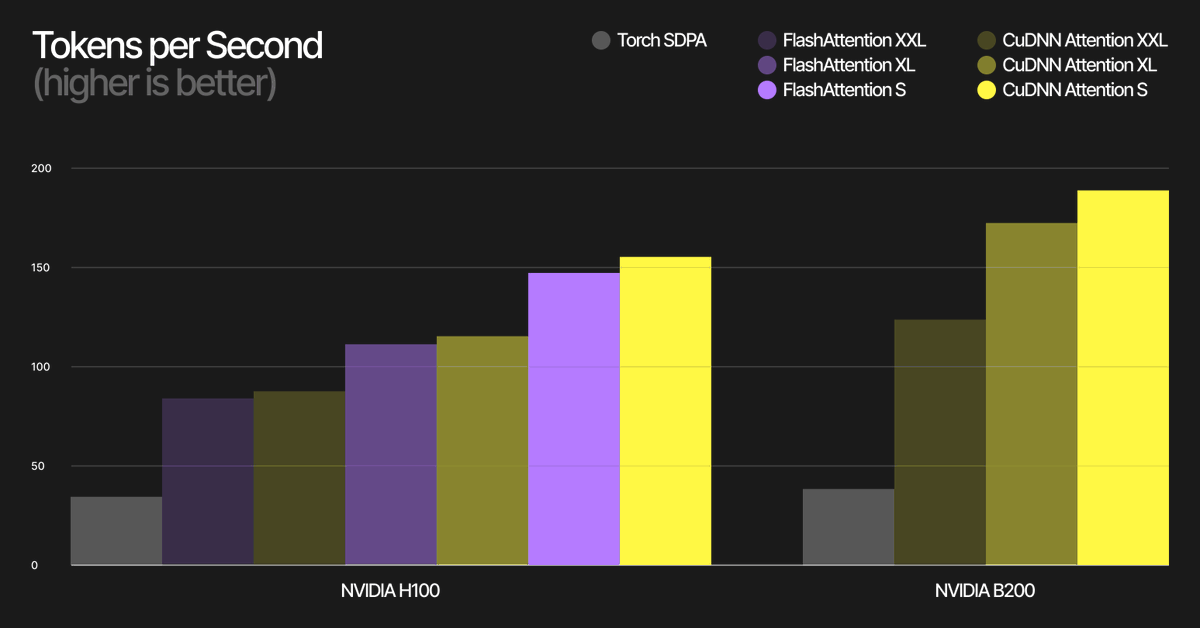
At TheStage AI, we shipped @nvidia cuDNN Paged Attention in our Elastic Models library.
We replaced paged FlashAttention for better integration. In our benchmarks, the cuDNN path shows nearly identical quality and latency vs the previous implementation.
Early results on B200: INT8 Llama 8B ~200 tok/s per sequence @ bs16 (≈ 3,200 tok/s aggregate).
The write-up also covers CUDA Graphs, graph caching, cuDNN Paged Attention, and INT8 LLMs. Next we are moving to native inference support across NVIDIA hardware including Jetson.
Check blog for details:
app.thestage.ai/blog/Integra…
1
11
428
Jan 13
Multilingual, open-source STT built for real-time streaming ↓
github.com/TheStageAI/TheWhi…
1
6
9,973
Jan 12
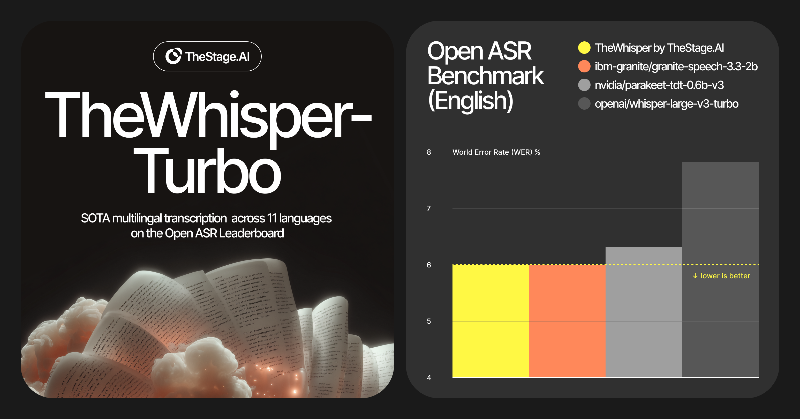
New SOTA TheWhisper checkpoint.
Update is out.
Open-source multilingual STT built for real-time streaming and noisy audio.
6.0 WER on Open ASR, ahead of Parakeet and Whisper.
Optimized with our stack – ANNA, Automated Neural Networks Accelerator.
Code is open. GitHub →
1
3
63
355,514
4 Dec 2025
Significant speed and size gains in model inference are possible without hurting output quality.
ANNA is our PyTorch framework for automated model acceleration, a new way to think about MLOps.
Smaller ckpts, lower cost, faster inference, no retrain.
Test demo or request access

1
8
149
844,222
TheStage AI retweeted

2 Oct 2025
Great communities make great products.
At @TheStageAI, we’re building ANNA, our Autonomous Neural Networks Accelerator, for faster, cheaper inference.
We need a Community Manager now. Be part of the early story →
2
1
12
2,130
24 Sep 2025
TheStage AI is now SOC 2 Type I compliant.
We did it to keep models, data, and IP secure. Clients get confidence, simpler procurement, and compliant AI deployment.
This milestone sets us up to grow into enterprise, government, and regulated markets.
1
8
620