
Joined October 2022
- Tweets 303
- Following 1,361
- Followers 690
- Likes 666
58 Photos and videos










Gemma4 E2B, compressed by @TheStageAI , from 9.3GB to 1.4GB, is running on iPhone 16e with tool calls!
The smallest and the best quality checkpoints open-sourced! @GoogleDeepMind
6
3
36
233,809
Kirill Solodskikh retweeted

Jun 2
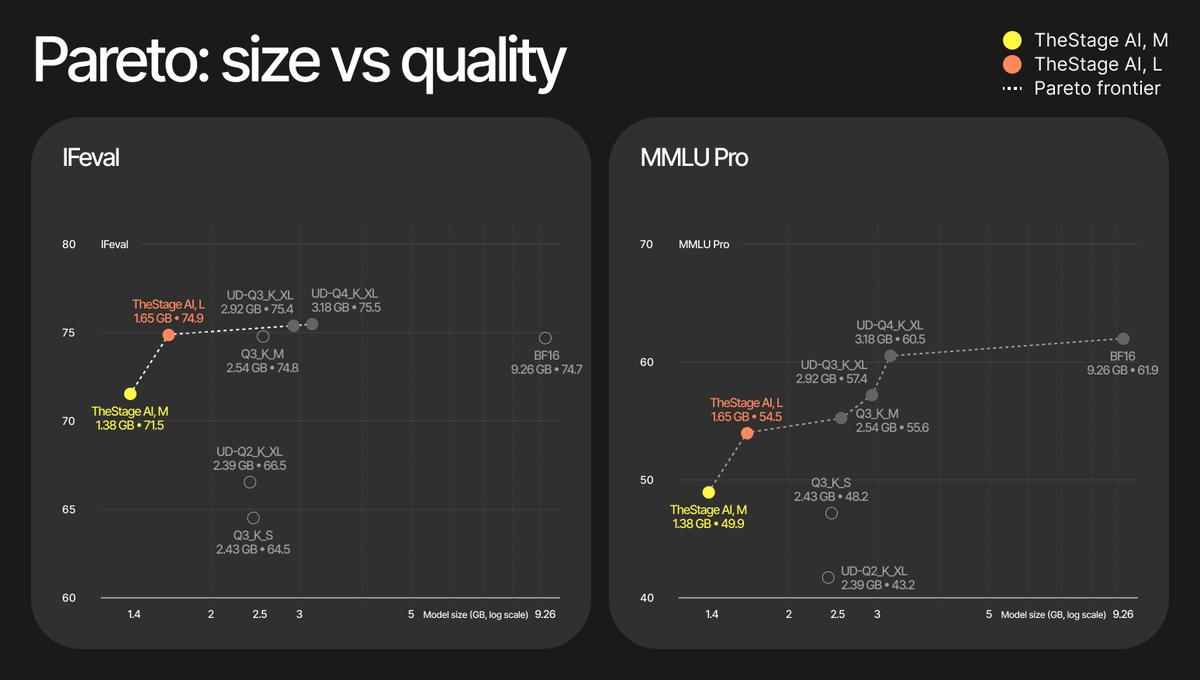
The smallest checkpoints for Gemma 4 E2B and E4B for local inference. Results for E2B:
size: 9.3 GB → 1.4 GB
speed: 113 tok/s on Apple M3
quality: -3% on ifEval
runs with: MLX, llama.cpp (coming)
Pareto-optimal, open source! Links to the blog post and GitHub repo ⬇️
@GoogleDeepMind @lmstudio @ollama @huggingface @ggerganov

2
5
22
275,008
Kirill Solodskikh retweeted
May 17
Try it yourself, thestage.ai
May 12

TheStage AI Platform is now open to everyone.
Automatically accelerate your models and download them to run in the cloud or on smartphones.
2
5
316
Kirill Solodskikh retweeted

May 14
Say hello to V4.1
This model is built for images that captivate you. Photorealism is more human, gradients are dreamier, and new illustration styles are now possible.
Test it out in Recraft Studio today and see what you can create.
38
53
561
3,338,363
Kirill Solodskikh retweeted
May 12
TheStage AI Platform is now open to everyone.
Automatically accelerate your models and download them to run in the cloud or on smartphones.
34
23
146
3,596,756
Kirill Solodskikh retweeted
Apr 10
Beyoncé heard cursing. TheWhisper heard Arsenal.
The fastest Whisper in the world.
Open-source real-time ASR.
Top 5 on OpenASR benchmarks.
1800 RTFx.
Built for live captions, transcription, and voice apps.
See the repo
4
19
179
2,655,479
Self-hosted AGI starts with inference infra teams can actually run.
Well. Elastic Models v0.2.0 is much more self-serve: world’s fastest whisper-large-v3-turbo, Wan2.2 generating 5s of video in 34s on H100, and instant FLUX LoRA switching.
Explore v0.2.0
1
6
227
Actually, comparing 1-bit with 16-bit has no sense. Everyone is using 4-bit weights with MLX. And the speed will be around 150-180 tok/s on M4 Pro. Moreover, 4-bit quantization in MLX can be done as block quantization what preserve quality for the most cases.

1-bit Bonsai 8B running locally on an M4 Pro (MLX) alongside a standard 16-bit 8B model.
Same class of model, very different deployment profile: far lower memory use and substantially higher throughput.
4
186

Mar 31
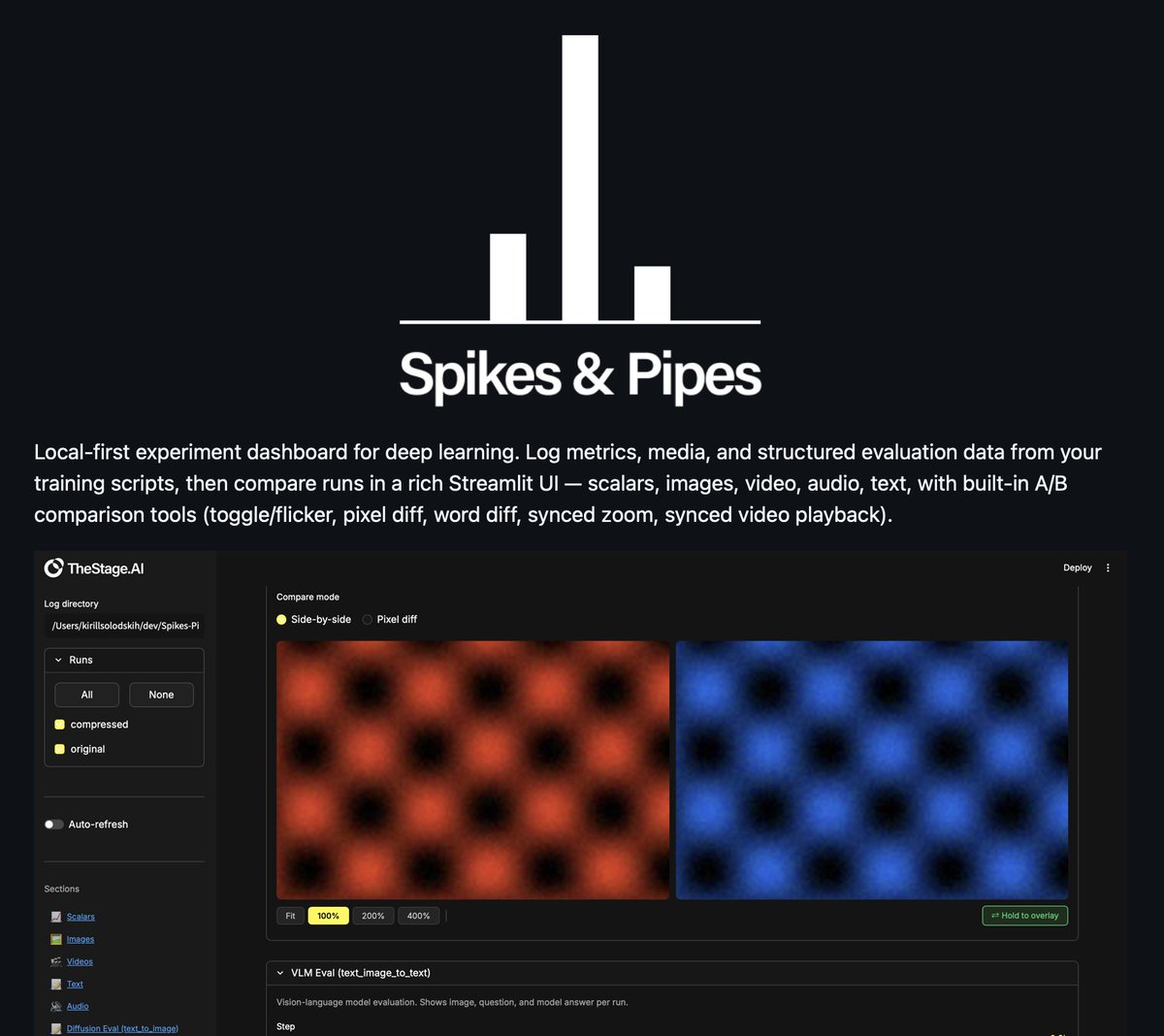
Open-source experiments dashboard for AI researchers. Cool comparison overlays across modalities. What add next? S3 integration, authentication, model registry?
github.com/TheStageAI/Spikes…
3
134
Kirill Solodskikh retweeted
Mar 19
How do you make text-to-music run in real time in production?
The model has to keep audio generation ahead of playback.
Our new case study with @MireloAI shows how inference optimization delivered up to 2.4х higher throughput.
See the full case study ↓
4
8
385
Kirill Solodskikh retweeted
Mar 4
Proud to team up with @brilliantlabsAR and @neuphonicspeech on Halo’s on-device privacy engine.
Coming to Brilliant Labs’ Halo smart glasses: real-time voice vision, POV stays private.
ANNA GPU/NPU SDK memory manager for wake word, STT, TTS, diarization.
SDK demo 👇
6
9
25
2,321
Kirill Solodskikh retweeted
Jan 22
Are you a big fan of jacket potato?
This is an open-source, real-time multilingual ASR for live speech.
It stays robust in heavy noise – even at SNR 0 dB.
That’s why it understands speech where people struggle to hear.
Use it for transcription, research, and multilingual apps
2
29
343
131,208
Jan 19
Good weekend!
I spent time testing our releases more extensively and writing usage guides during my tests.
Suddenly @akshat_b and @charles_irl from @modal liked my notebook. While testing TheWhisper with @quaz1m, I found that @matiii started following me!
Quietly motivating!
7
204
Jan 17
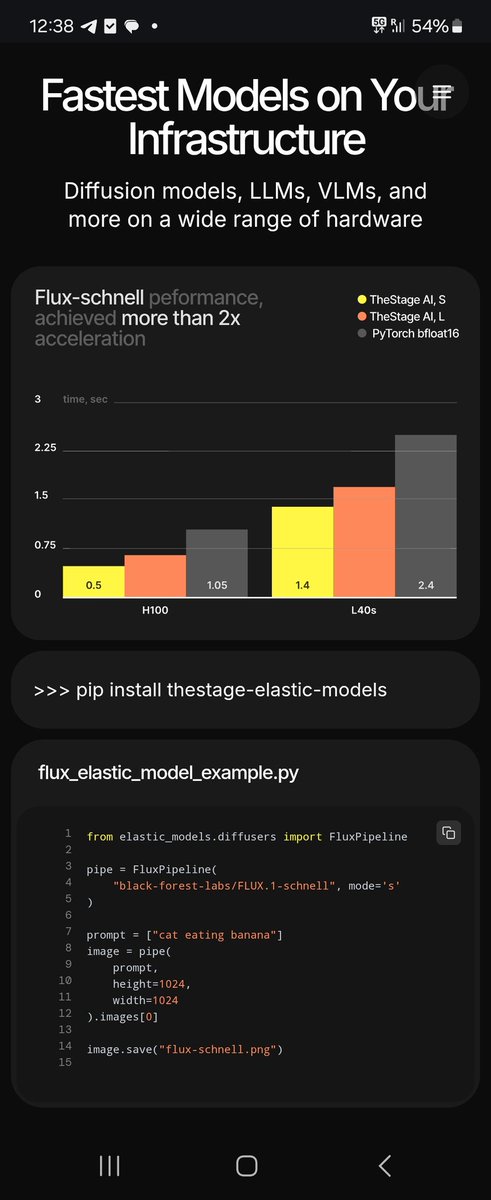
Mistal-Small-24B from @MistralAI with @nvidia CuDNN paged attention and w8a8 int8 quantization gives more than 2x acceleration on Nvidia B200.
Just covered simple tutorial to build a custom image for @modal notebooks and run there @TheStage AI ElasticModels with an integrated CuDNN paged attention and int8 w8a8 quantization (S size).
Got acceleration from 40 tok/s -> 95 tok/s (actually faster as it was measured with printing during streaming).
Notebook link in the thread 👇
1
1
7
325
Kirill Solodskikh retweeted

Jan 15
At @TheStageAI, Elastic Models started with paged FlashAttention.
This month we’re moving sequence generation to cuDNN Paged Attention to stay fast and speed up bring-up across newer @NVIDIA GPUs (including Jetson).
Details: app.thestage.ai/blog/Integra…
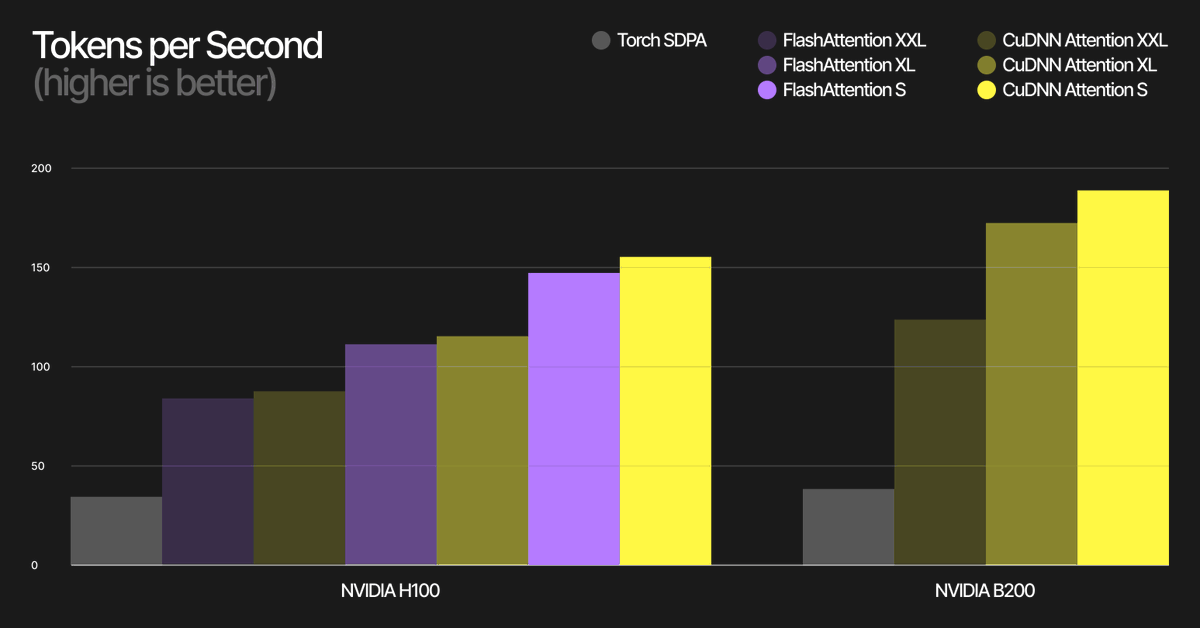
2
8
330