
Joined November 2011
- Tweets 5,236
- Following 2,675
- Followers 363
- Likes 9,899
457 Photos and videos









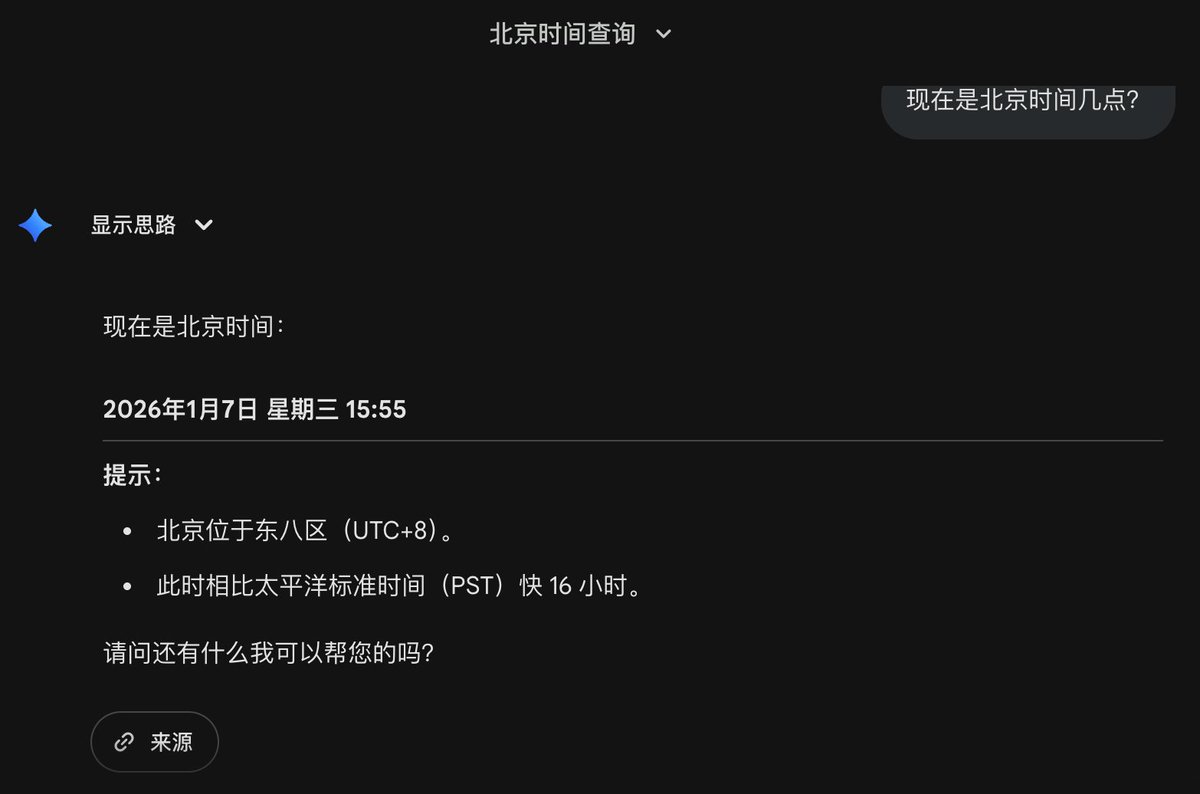





Anthropic 把 Claude Code 的每周用量上限提了 50%,即刻生效,截止到 7 月 13 日下午 6 点(太平洋时间)。
覆盖 Pro、Max、Team 和按席位计费的 Enterprise 用户,命令行、IDE 插件、桌面端、网页端,所有入口都一样涨。账号已经自动调整,不用做任何操作。
这 50% 是叠加在上周刚宣布的 5 小时窗口翻倍之上的,两个维度的天花板一起被抬。
【注:Claude Code 有两套限额。5 小时滚动窗口管的是短时间内能写多少,写得猛的人一下午就能撞顶;每周总额管的是一周能写多少,防止你某天突然把整周配额刷光。两个一起放宽,等于哪头都松了绑。】
过去几个月 Claude Code 用户最常吐槽的就是 Pro 套餐限额触发太勤,跟 Cursor、Codex 这些竞品比,"用着用着就停"的体感差不少。短期内连开两次额度,留人的意图挺明显。
7 月 13 日之后是否延续,没说。
May 13

Claude Code weekly limits are increasing 50%, now through July 13.
Live now for all Pro, Max, Team, and seat-based Enterprise users.

51
16
174
95,027
@Toong retweeted

Apr 22
看完这段视频,你就知道华为是家什么公司,奉行什么文化了。将等级制发展到奴才文化的典型特征之一,就是掌权者生活不能自理,哪怕喝水这样的小事,都需要奴才拧好了瓶盖递到嘴边。从余承东到习近平,都是这个德性。
695
321
2,503
1,048,983
@Toong retweeted

Apr 13
亲测 OpenCLI / BB-browser 搞不定 Boss 直聘的网页自动化操作。
Boss 直聘的反爬做得非常狠,尤其针对 CDP 远程控制。
Boss 网站会检测 Console 函数被 Hook 后的时间差 函数 toString() 特征。
一旦有外部 CDP 会话附加到浏览器,Chrome 的 Console 就会被 CDP 接管,console.log、Function.prototype.toString 等函数的执行就会产生可被 JS 检测到的微小延迟。
Boss 页面会埋点监控这个时间差,一旦发现就认为“这是被自动化工具远程控制的浏览器”,直接把页面强制回退或者关闭。


37
25
285
122,900
@Toong retweeted

Apr 4
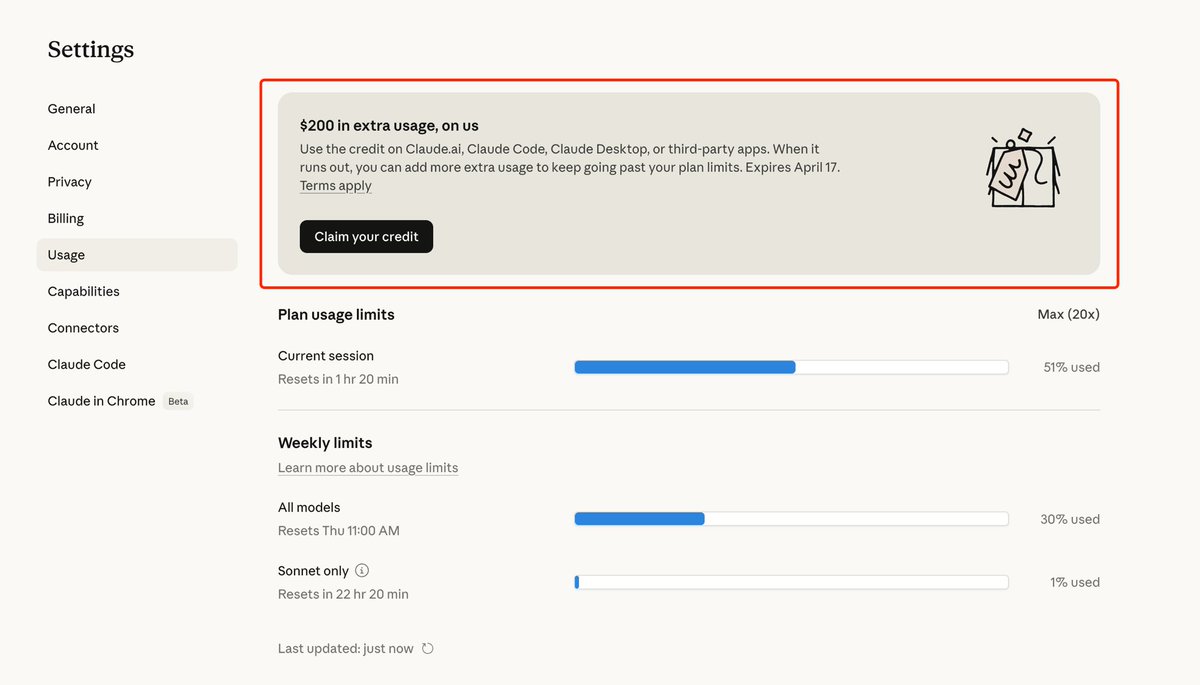
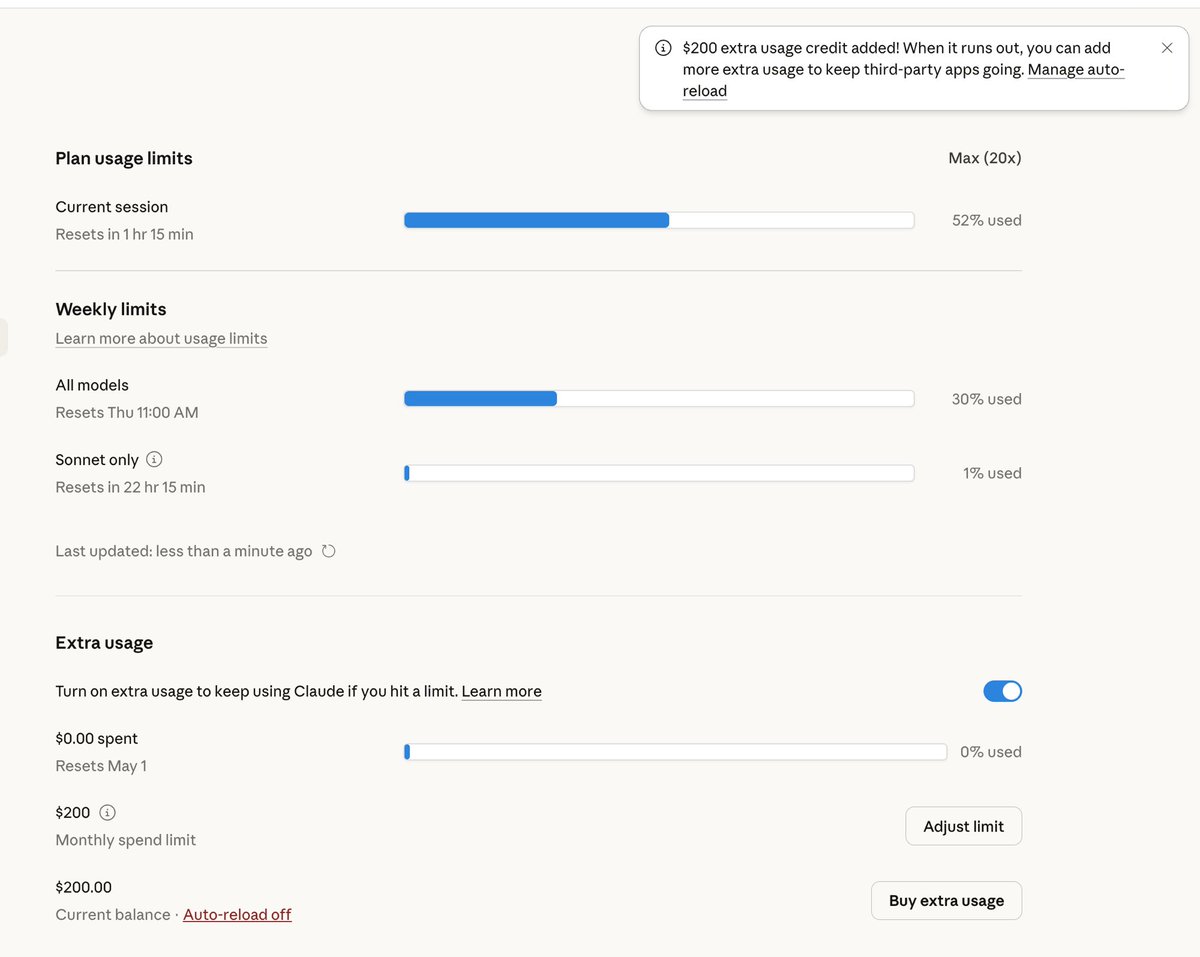
Claude 悄悄送了 $200 额度,藏在后台 Settings → Usage 里。
可以用在 Claude.ai、Claude Code、Claude Desktop、第三方 App,4 月 17 号过期。
注意:直接点 Claim 可能报错,先往下滑把 Extra usage 开关打开,再回去领就行了(app store订阅、没绑卡也成功哦)。
又可以开心的烧token了 !
24
19
103
44,721
好莱坞女星 Milla Jovovich(《第五元素》女主角)和开发者 Ben Sigman 联合发布了一个开源 AI 记忆系统 MemPalace,声称在 LongMemEval 基准测试中拿下满分,是有史以来第一个做到这个成绩的系统。项目完全本地运行,不需要云服务和 API 密钥,免费开源。
【1】它想解决什么问题
每次和 AI 对话结束后,所有上下文都消失了。你花几个小时跟 Claude 或 ChatGPT 解释你的项目架构、技术选型、调试过程,第二天它全忘了。半年下来可能积累了近 2000 万 Token 的对话,但没有一个系统帮你把这些东西管起来。
现有的记忆方案(比如 Mem0、Zep)让 AI 自己决定记什么,提取出“用户喜欢 Postgres”这样的标签,但把你解释为什么选 Postgres 的那段对话丢掉了。MemPalace 的思路相反:全部存下来,靠结构让它可搜索。
【2】怎么做的
借鉴了古希腊“记忆宫殿”(方位记忆法)的概念:把对话按项目和人物分成“翼”(wing),每个翼里按主题分成“房间”(room),房间之间有“走廊”(hall)按记忆类型分类,不同翼的同名房间通过“隧道”(tunnel)互相关联。
同时开发了一种叫 AAAK 的压缩语法,号称能把上下文压缩 30 倍,让 AI 用大约 120 个 Token 就加载几个月的关键信息。支持所有主流模型,包括本地运行的 Llama 和 Mistral。
通过 MCP 协议接入 Claude 等工具后,AI 会自动调用 MemPalace 的 19 个工具来搜索历史对话,用户不需要手动操作。
【3】争议
项目发布当天就遭到多方质疑,其中最系统的一篇来自 Penfield Labs,逐条拆解了 benchmark 数据的问题:
LongMemEval 的“满分”实际上只做了检索这一步,没有生成答案,也没有经过评判。
标准排行榜上的成绩是端到端的问答准确率,MemPalace 测的只是“能不能找到正确的对话片段”,难度低了一个量级。项目自己的文档也承认,最后三道题的修复是针对特定题目写的补丁代码,属于“teaching to the test”。
LoCoMo 基准测试的 100% 更离谱:10 段对话最多 32 个会话,但检索参数设成了 top_k=50,等于把所有内容全部丢给 Sonnet 做阅读理解,检索层完全被绕过了。项目自己的 BENCHMARKS.md 文件里白纸黑字写了这一点。而且 LoCoMo 数据集本身的标准答案就有大约 99 道题是错的,理论上不可能 100%。
“无损压缩”也站不住脚。AAAK 模块把句子截断到 55 个字符,decode 函数不能还原原文。项目自己跑的测试里,用 AAAK 压缩后的检索准确率从 96.6% 掉到了 84.2%,差了 12 个百分点。无损压缩不会导致质量下降。
宣传材料里提到的“矛盾检测”功能,在代码里也找不到实现。知识图谱模块只做了完全匹配的去重,矛盾的事实可以无限累积。
【4】该怎么看
项目内部文档其实还比较靠谱,大部分方法论缺陷在 BENCHMARKS.md 里都有披露。问题在于发布推文把所有限定条件都去掉了,只留下了最炸裂的数字。
抛开 benchmark 争议,MemPalace 的核心想法有可取之处:用结构化的方式组织对话记忆,全部本地运行,不依赖云服务。仅靠宫殿结构分层检索,准确率就提升了 34%,这个数字是实测的。纯本地无 API 的基线成绩 96.6% R@5 也确实是同类系统中最高的。
简单来说:明星光环制造的传播效果远超工程本身的分量。
Apr 6

Excited to announce a new open-source, free-to-use memory tool I have been developing with my good friend @MillaJovovich.
The project is called MemPalace and it is an agentic memory tool that scored 100% on LongMemEval - the industry standard benchmark for memory… this is higher on than any other published results - free or paid - and it is available now on GitHub.
You can check out Milla’s video about it on her Instagram.
I’ll also put some links in the comments below - please try it out, critique it, fork it, contribute to it - and join our discord.
13
9
100
40,481

ClaudeCode意外流出的代码可以说是当前 AI Agent 工程领域最好的一本架构教科书。
基于这份还原的源码,我深度硬核拆解了Claude Code 的记忆架构。
1. 核心理念:受限式、结构化的人类式记忆
过去很多Agent的记忆系统是大而全,不管什么聊天记录、代码片段都往向量数据库里塞,最后导致相似度检索混乱、上下文爆炸。 而从源码可以看出,Claude Code 采取的是一种受限式的、结构化且具备自愈能力的记忆机制。它完全模拟了人类优秀高级程序员的工作习惯——随手记笔记、列提纲、定期做总结。
2. 双轨记忆系统:CLAUDE.md 与 自动记忆 (Auto-Memory)
系统在每次对话启动时,会加载两个互补的记忆模块,且绝不盲目吃Token:
•静态/显式记忆(CLAUDE.md): 这部分由用户定义,类似于传统系统提示词的延伸。源码显示,启动时系统会自动读取主分支、当前分支、最近提交记录,再加上 CLAUDE.md(里面通常包含构建命令、代码规范、项目架构),构建出一个动态的项目全景。
•动态/自动记忆(Auto-Memory): 这是最亮眼的部分。Claude会在工作时“自己给自己写工作日志”。它通过一个 MEMORY.md 文件作为“记忆目录索引”,并且代码中硬性规定将其控制在极其精简的 200行以内。它不会把所有细节都塞进这个主文件,而是将详细的Debug记录、架构分析抽离到独立的主题文件中(如 debugging.md 或 patterns.md)。需要用到时,再通过专属的文件工具(File Tools)按需读取。
3. Memory Type System:四分类与绝对不记清单
源码中定义了一个严格的记忆类型系统,将记忆精准分为四类:
1User(用户画像): 用户的偏好和工作流习惯。
2Feedback(纠正反馈): 用户过去指出的错误和纠正方向,防止在同一个坑里跌倒。
3Project(项目状态): 任务规格、当前进度、错误与修正日志。
4Reference(引用指针): 指向外部文档或大文件的索引。
代码中硬编码了一个**「绝对不记清单」**! Claude Code 明确限制写入以下内容:具体的代码实现细节、Git提交历史、可以直接用 grep 或 git log 搜到的具体报错日志。 为什么? 因为工程团队认为:“能通过现成工具低成本现查的东西,就不该占用宝贵的长效记忆空间”。这极大地减少了上下文污染和记忆冗余。
4. 极致的上下文压缩术 (Context Compression)
如何防止Agent工作时间一长就“失忆”或突破Token上限?源码给出了教科书级别的解法:
•结果截断与落盘: 当调用命令行或搜索工具返回巨大的结果时,Claude Code 不会将其全部塞入上下文。源码逻辑是:将过大的输出写到本地磁盘,大模型上下文中只保留预览摘要和文件引用指针。
•滚动摘要机制: 当对话轮次接近清除阈值时,系统会触发警告通知。在旧的对话内容被上下文窗口剔除前,Claude 会主动将当前的关键进展浓缩,并写入持久化的记忆文件(如 refactoring_progress.xml)。
5. AutoDream 系统:令人惊艳的后台反思与梦境
内置的 AutoDream (梦境机制) 会在用户闲置或会话结束时悄悄激活。它会指挥 Claude Code 运行在一种后台Agent模式下,执行对记忆文件的“反思性处理”:
•扫描与提取: 翻阅当天的会话日志,寻找值得长期保存的通用新知识。
•去重与整合: 将新知识与旧记忆进行合并,消除矛盾和重复片段。
•遗忘机制: 主动删除或归档过时的记忆(例如已经废弃的旧架构讨论)。
这就相当于 AI 在你下班后,自己默默在后台整理当天的“工作日记”,并将其提炼为高浓度的知识库,供第二天的会话随时调用。
总结:对 AI 开发者们的启示
1不要盲信向量检索:结构化的 Markdown/XML 笔记加按需文件读取,往往比纯 Vector DB 更有逻辑、更不容易产生幻觉。
2让 AI 学会“记目录”而不是“背全文”:用层级索引来管理信息。
3增加“后台反思与GC(垃圾回收)”机制:好记忆是靠整理和定期清理出来的,不是靠无限堆砌出来的。
2
3
21
2,606
@Toong retweeted

Mar 10
我一直认为:研究多 Agent 团队结构是邪路
研究记忆、知识结构、上下文管理,和工作流就行了。非要说的话加个异步并发
大模型本来就只有一个,上下文窗口和文件记忆都是流动的
生搬人类的组织结构就只会学到中层病。要透过现象看本质。Agent 编排更像操作系统,而不是人类组织结构
52
30
321
174,593
@Toong retweeted

Mar 5
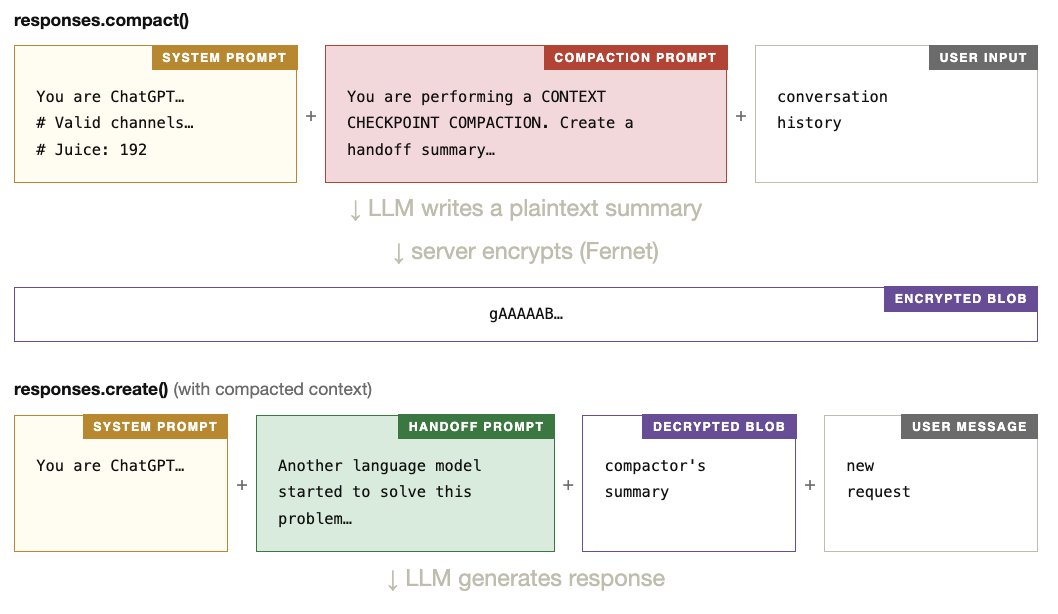
这篇文章是今天看到最精彩的文章,是一篇技术深度逆向工程实验,成功从 Codex CLI 的 compact() API中提取出了隐藏的系统提示。
非常好地解释了 Codex CLI 在使用自己模型,在长上下文管理上的实际运行方式,几乎把黑箱内部机制扒得一清二楚。
1 当上下文太长时,不是简单丢弃历史,而是调用 compact() API
2 服务器用一个专用的 compactor LLM,把整个对话历史总结成一个精炼的“handoff summary”。
3 这个 summary 被 AES 加密成 blob 返回给客户端
4 下次 responses.create() 时,客户端把 blob 传回去,服务器解密后总结,一起喂给 codex 主模型。
5 模型无缝接力继续工作,不会因为压缩而严重失忆或漂移。
这解释了为什么 Codex 在长任务上连续性特别强。
配图也很棒,非常好的科普文章。

10
174
959
142,179
@Toong retweeted

Mar 4
造孽啊,
不知道qwen团队的年轻人是不是顶着压力,抱着被裁的决心,咬着牙胸怀热爱上班的。🥲
最新的一款27B的qwen3.5,
匿名竞技场里和上代的claude haiku 4.5,glm-4.5,gemini flash 2.5这些一个层次。
而且分数还在上升。
相当于64G显存放家里,实现前沿闭源小杯模型自给自足。
Mar 4

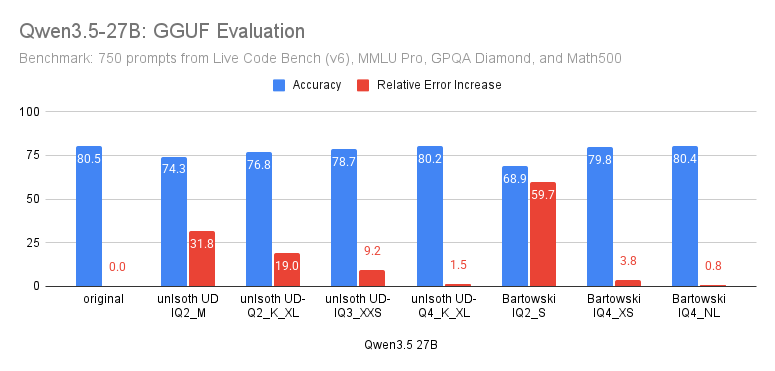
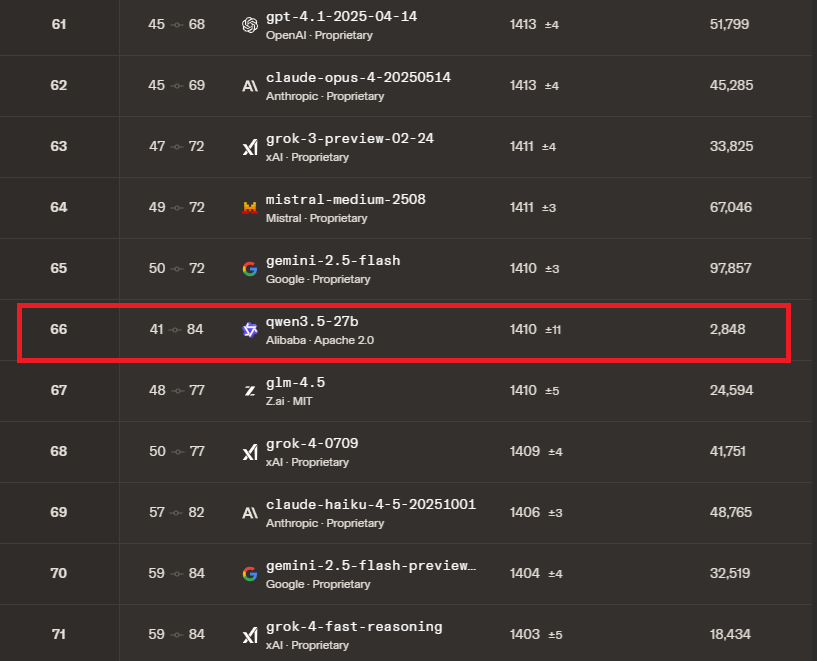
🦞 Clawdbot News: Interested in choosing the best local Qwen3.5 model to run your Agent? Qwen3.5-27B dominates the benchmarks in terms of size. Ranking #66 on @arena latest leaderboard (above MiniMax M2.5, Step 3.5, GPT-5-mini).
Benjamin's assessment shows Unsloth and Bartowski continue to be the gold standard.
Unsloth shows nearly no quality loss, bringing down the footprint by 65% (55.6GB to 19.46GB), the perfect size to run on an AMD Ryzen AI Max 395 rig with 64 GB RAM (or M4 Mac Mini w/64GB)
8
8
132
42,616

长久以来大家一直在嘲笑的独立开发者的三件套:笔记、记账、TodoList 可能是在 AI Agent 时代最重要的三件事情。
首先 AI 要依赖笔记存储记忆,也要通过记账来管理 token,最重要的是 TodoList 带来的 mission 系统,尤其是现在很多 Coding 相关的 Agent 完全把 goal 给定错了,它们把 goal 定成了提一个 GitHub PR,其实它们真正的 goal 应该是把这个需求 ship 到用户面前。再加上现在缺少一个 agent less 的 mission 系统,导致各个 Agent 各自为营,人类为了在各个 Agent 中同步 mission 消耗了太多。
42
28
407
53,382
@Toong retweeted

Mar 4
一直以来有一些感慨:qwen 团队、junyang 这样宝贵的理想主义的前沿团队领导者在一些偶然与必然下形成了,非常不易。
那时 glm 已经放弃了开放权重,除了 deepseek 有 coder 模型亮眼,一直是 qwen 团队在持续给社务贡献可用的模型,再就是 mistral 和 llama。
我记得 yihong 感慨过阿里云应该是没人瞎管理才造就了 qwen 团队,我很同意。
qwen3.5 之前有观察到团队的沉寂和 听到 toC/ 商业化压力的传言,还是有点担心的,next 模型还不算成熟,然后这两波 3.5 collection 刚刚让我松了口气,并且非常期待下一个 collection 的工作。
现在的百家争鸣开放权重的形式不是理所当然,这中间是 junyang 们的理想、努力所共同凝结。
期待 junyang 团队的下一段征程🫡
12
28
304
74,246


@Toong retweeted

Mar 3
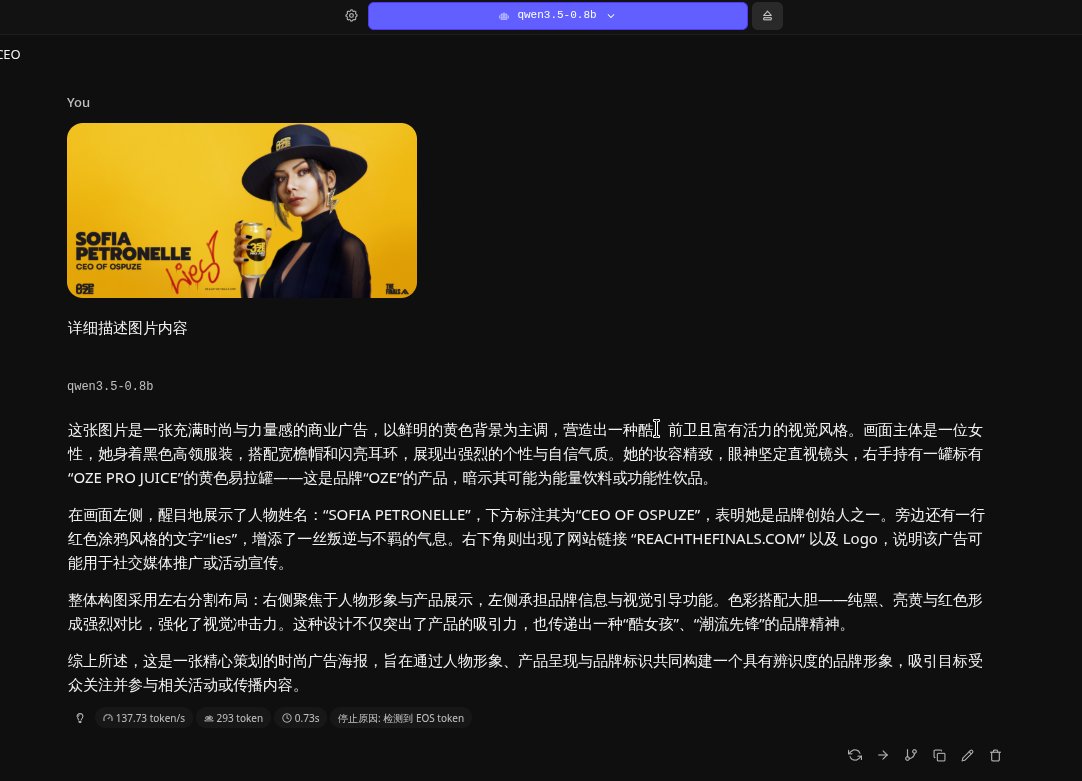
qwen3.5-0.8B这么小的模型还带视觉,我个破笔记本都能丢显卡上跑,qwen真王朝了🖐🏻️😭🖐🏻️
43
50
779
143,346


@Toong retweeted

Mar 3
首先,mengxi 没有以要钱为目的
其次,“要钱” ≠ “不体面”,你想让一个事情健康发展,钱是绕不过去的,如果你喜欢一个 软件/生态/开源本身,你的祝福应该是让他尽快赚钱,只有赚钱才能让这个事正向循环起来
如果这个事情没有赚到钱,那你就只能依赖于这个作者为爱发电能坚持多久,这就有点站在道德高地去审视别人了
所以,我其实对这个事情希望的发展是,两方取得联系,美团公开致歉 承诺为 mengxi 的开源项目进行持续性捐款以支持其运营

这哥们让美团开源只是一个说法,实际上想要钱,但是开源了怎么要钱?话说回来,想要钱的话就好好的去要,没有什么不好意思的,慢慢说,说不定给点,不要道德绑架,这样反而要不到钱。
8
2
72
11,225
@Toong retweeted

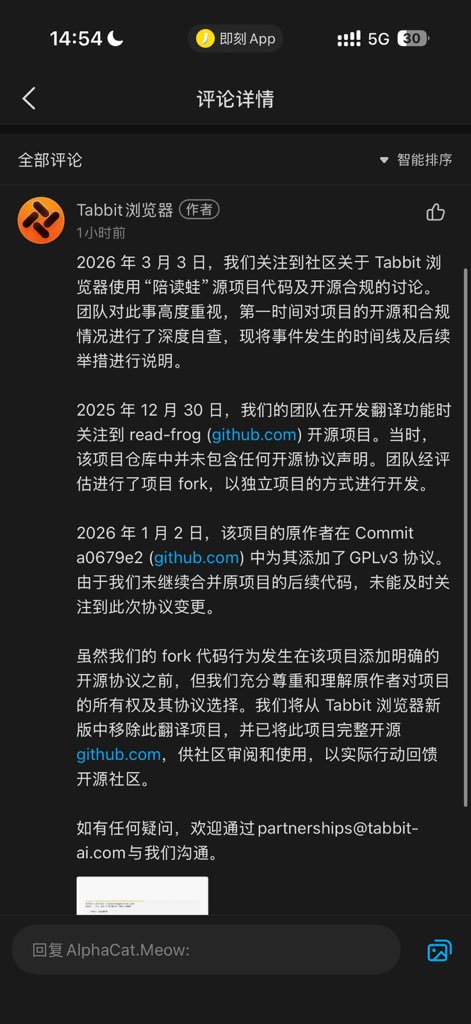
🤯 美团花 20亿 做的 AI 浏览器,今天大买特买媒体稿。
然而其中沉浸式翻译功能是原封不动搬了 @mengxi_ream 的 Read Frog 开源代码(GPL协议)。
但没给赞助、没给 credits、没按协议开源代码。
有认识美团这个研发团队的朋友帮忙联系看看是故意的还是不小心吗?
Mar 2

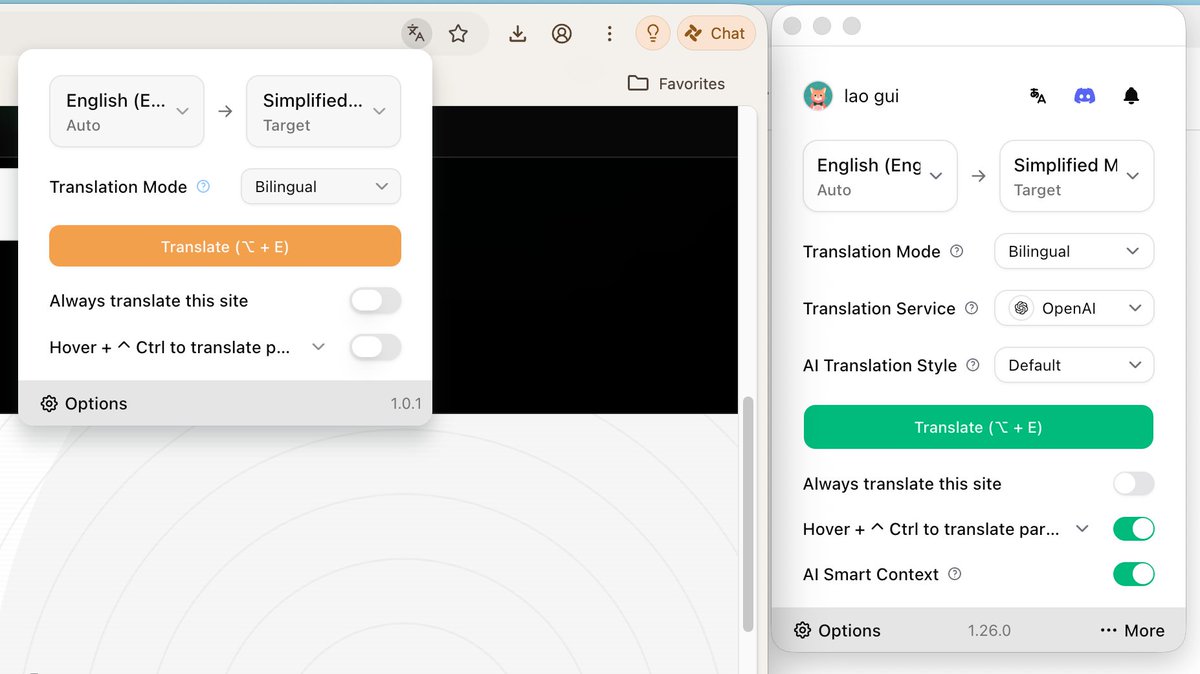
美团这么大公司,抄我的代码给自家 AI 浏览器用,还不给我赞助啊😂
几千亿市值的公司,白嫖嫖到我头上了,shame on you
左:美团 ai 浏览器,右:我的产品
根据我的 GPL 协议,任何使用我代码的产品都要开源,请问美团你的这个新 ai 产品开源了吗?法律意识呢?
更多截图在评论。
40
39
438
105,361
@Toong retweeted

Mar 2
美团这么大公司,抄我的代码给自家 AI 浏览器用,还不给我赞助啊😂
几千亿市值的公司,白嫖嫖到我头上了,shame on you
左:美团 ai 浏览器,右:我的产品
根据我的 GPL 协议,任何使用我代码的产品都要开源,请问美团你的这个新 ai 产品开源了吗?法律意识呢?
更多截图在评论。
445
278
3,062
792,996