
PhD student @UniofOxford and @MetaAI, prev Renmin University of China (RUC)
Joined September 2022
- Tweets 229
- Following 685
- Followers 258
- Likes 1,247
13 Photos and videos





Pinned Tweet

Feb 25
New Research!🚨
Humans get insights from pilot studies in long-horizon tasks, and it also applies to LLM.
Stepping stone questions provide inspiration for solving hard problems, and even a cutting-edge reasoning model benefits from stepping stones generated by a weaker model.
Feb 25

New research
1/🧵When running into hard questions that seem formidable, we try to make progress by asking related **stepping stone** questions that may help us gain intuition towards solving the ultimate question. In this work, we ask if LLMs can benefit from the same concept.

3
170
Tingchen Fu retweeted

CV has CNNs, NLP has transformers - what inductive bias does RL have? How can policies generalise to regions of the dataset suffering from poor transitions?
We motivate hierarchy by enabling distinct state-representations at different levels of the hierarchy @FLAIR_Ox @j_foerst
2
17
88
23,785

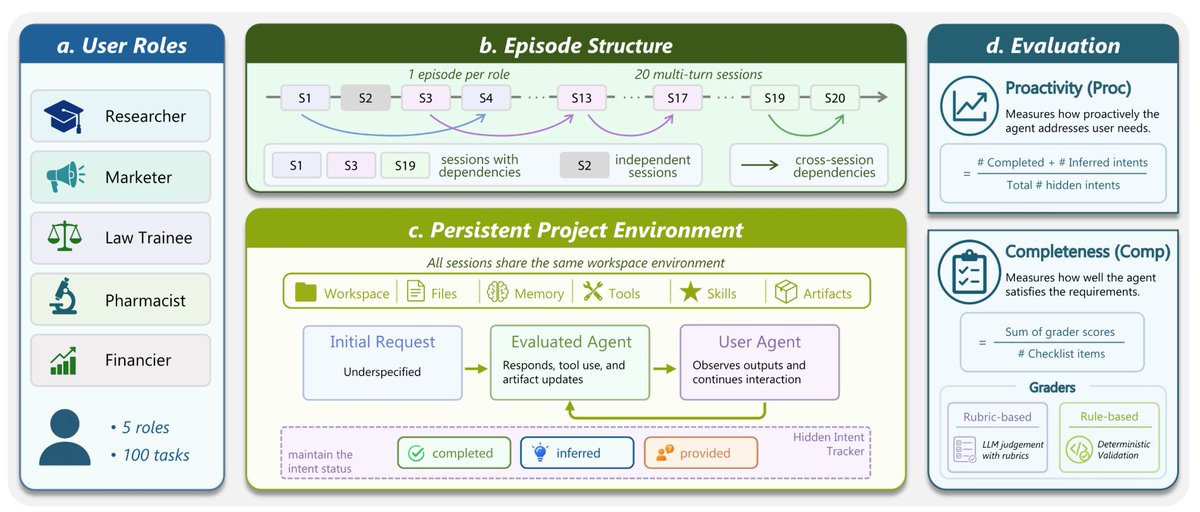
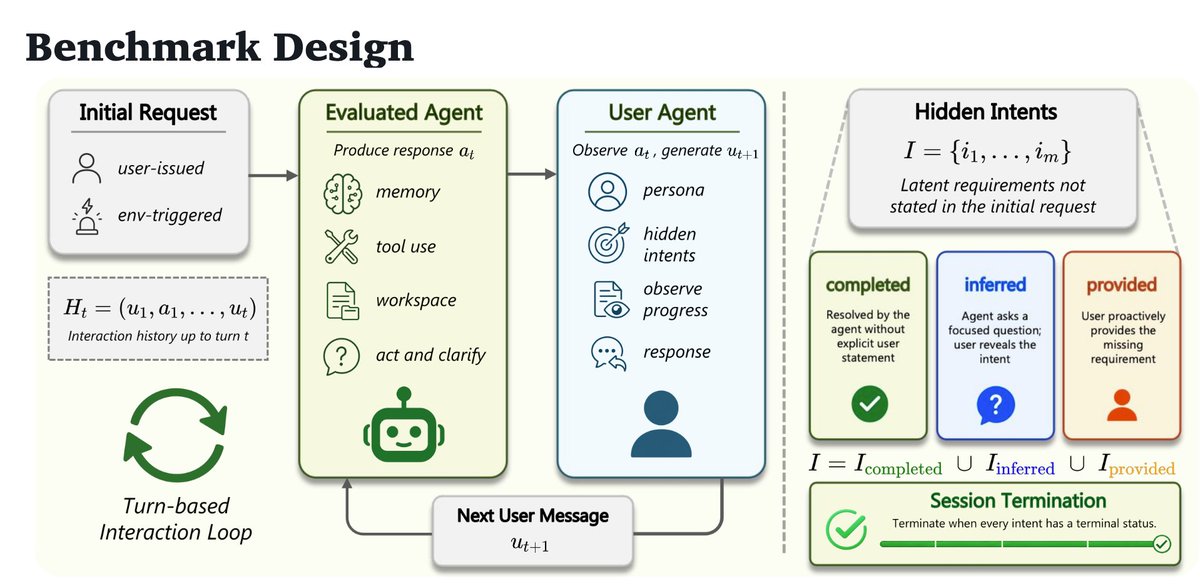
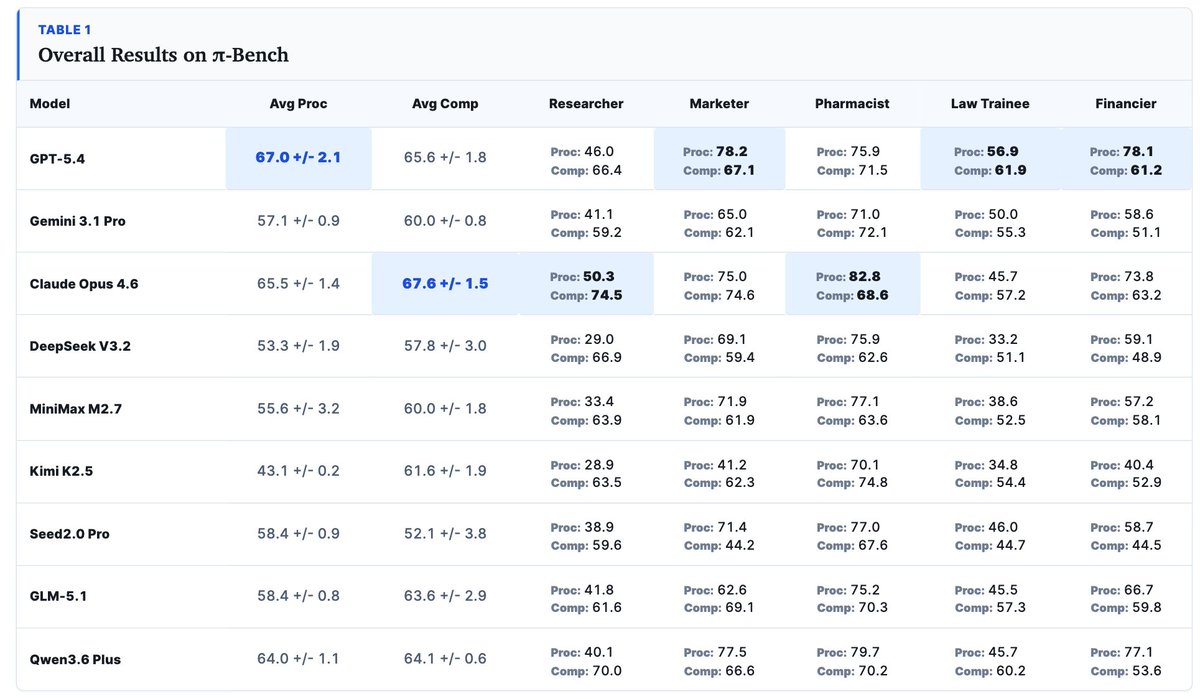
✨ Introducing π-BENCH: a benchmark for proactive personal assistant agents in long-horizon workflows.
Real personal assistants work in continuous application scenarios: research projects 🔬, legal handoffs ⚖️, marketing campaigns 📣, financial analysis 📊, pharmaceutical documentation 💊, and more.
In these settings, a task today may depend on something from much earlier: a decision made several sessions ago, a file updated last week, a previous artifact, or a persistent user preference.
π-BENCH tests whether agents can connect these dots across sessions—and, more importantly, use them proactively.
- Can the agent notice what the user forgot to mention?
- Can it ask the right clarification before going in the wrong direction?
- Can it reuse prior context instead of making the user repeat it?
That is the core of π-BENCH: evaluating whether agents can handle long-range dependencies and proactively resolve unstated user intents in realistic, multi-session personal-assistant workflows. 🧵
Huggingface: huggingface.co/papers/2605.1…
Project page: simplified-reasoning.github.…

5
18
745
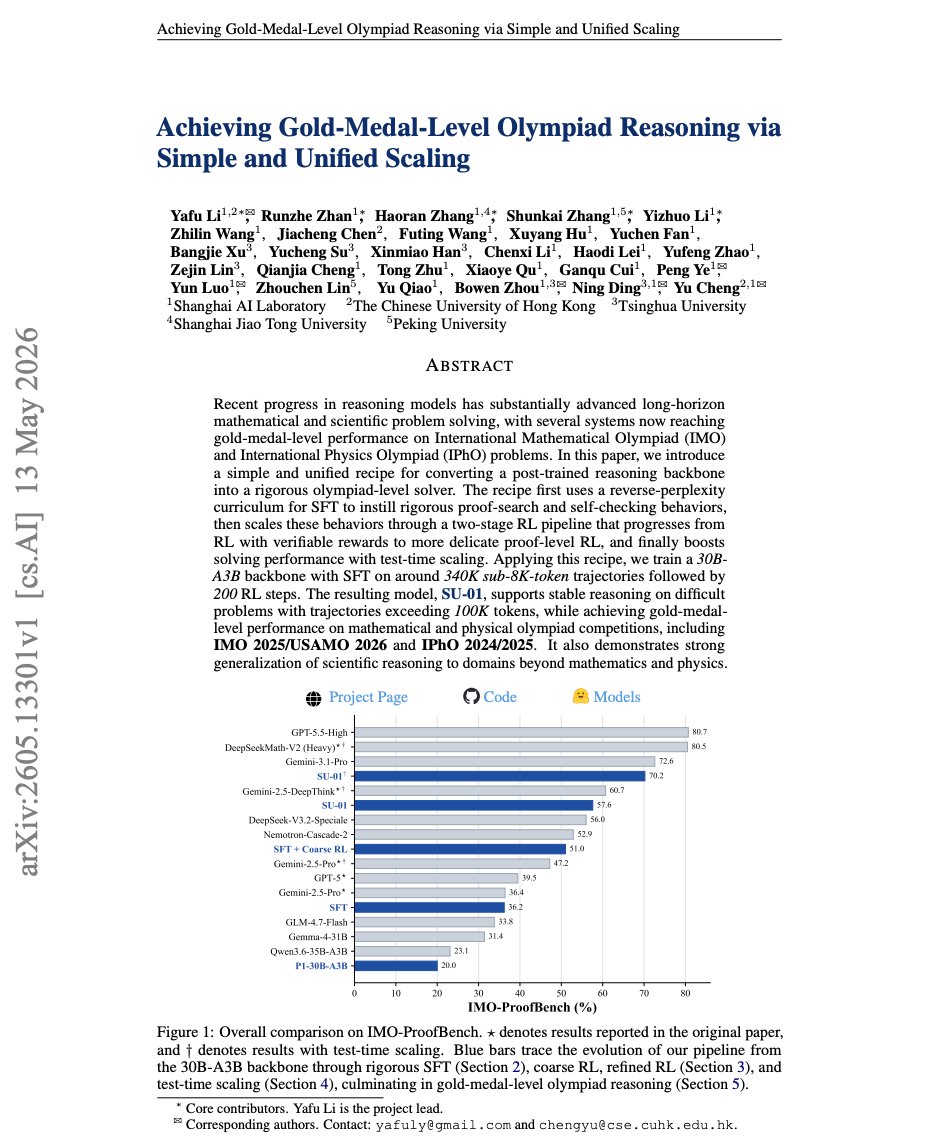
Can a simply trained 30B model reach gold-medal-level olympiad reasoning in pure natural language?
In our new report, we introduce **SU-01**, a 30B-A3B model trained with a simple unified recipe for rigorous mathematical and scientific reasoning.
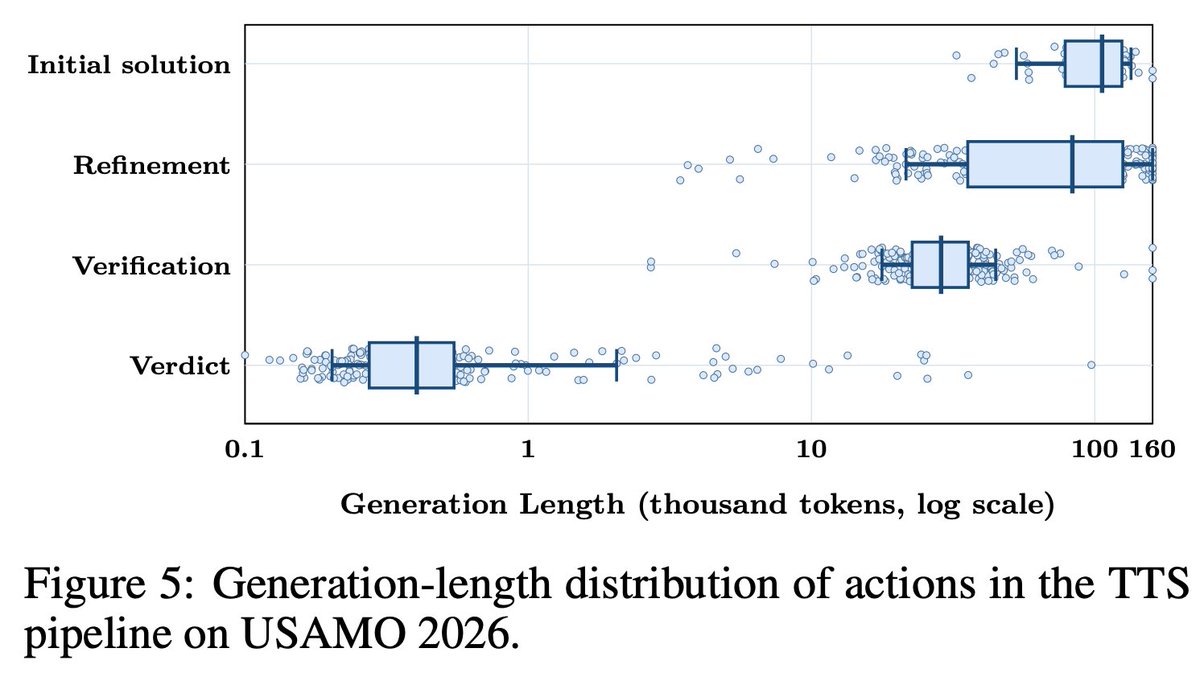
The recipe is intentionally lightweight: around **340K sub-8K-token SFT trajectories**, followed by only **200 RL steps**, then test-time verification and refinement.
The resulting model supports stable reasoning on difficult problems with trajectories exceeding **100K tokens**.
With test-time scaling, SU-01 achieves:
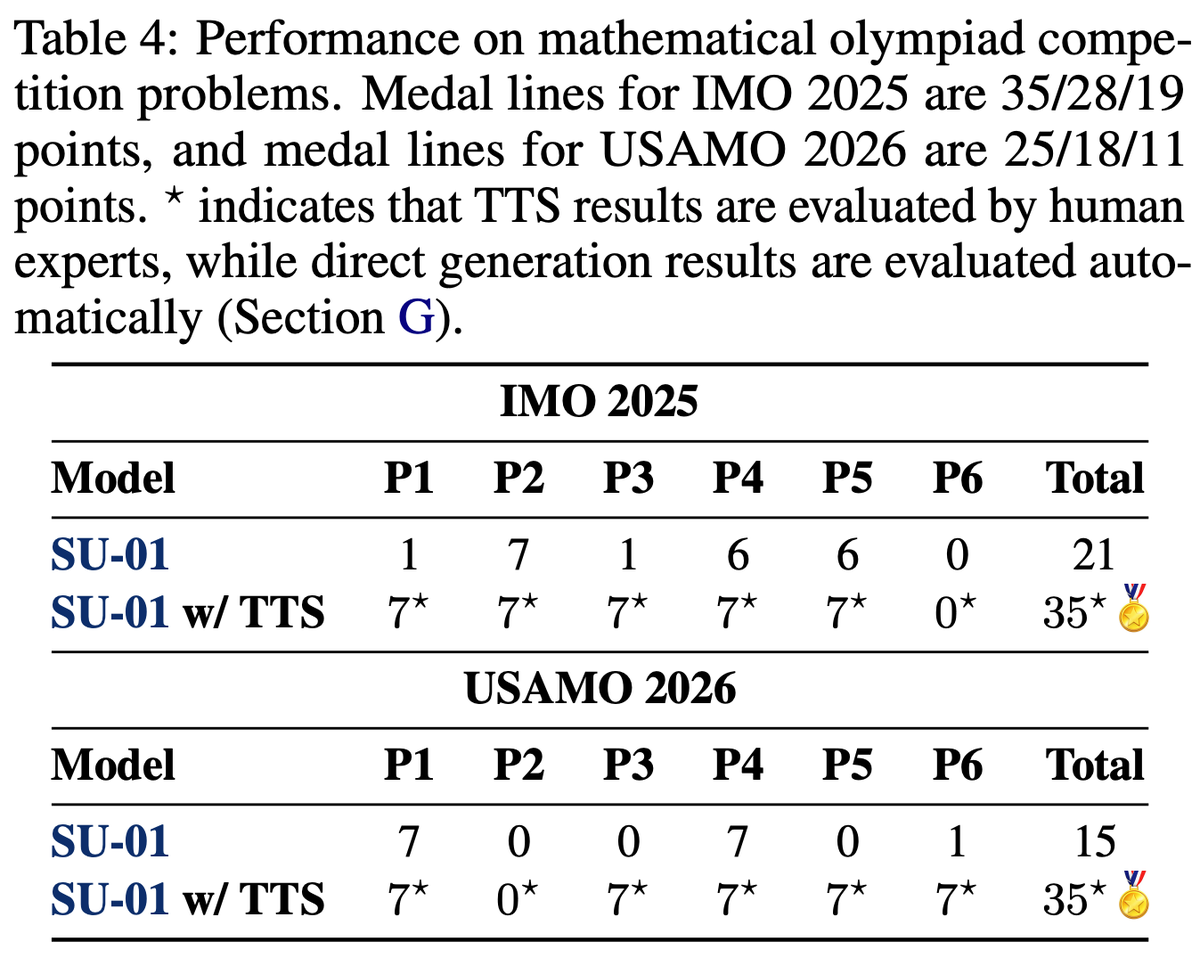
- **35 points on IMO 2025**, meeting the gold-medal line;
- **35 points on USAMO 2026**, far above the 25-point gold line and matching the highest human score among 340 contestants. It also received full credit on Problem 3, where the human average was only 0.01 and no contestant scored above 5;
- gold-level performance on **IPhO 2024/2025**;
- **70.2% on IMO-ProofBench**, close to Gemini 3.1 Pro Thinking.
The key takeaway is simple:
Olympiad-level scientific reasoning may not require a giant model or a heavily customized pipeline for each domain.
What matters is learning a reusable loop of **proof construction, verification, and refinement**.
We have open-sourced the code and model:
Paper: huggingface.co/papers/2605.1…
Github: github.com/Simplified-Reason…
Model: huggingface.co/Simplified-Re…

4
5
18
849
Tingchen Fu retweeted

Apr 20
小红书上的北美教授红黑榜
docs.google.com/document/d/1…
其实没有绝对的红和绝对的黑 读phd不容易 做教授也不容易 大家应该互相理解 找到平衡,找到适合自己的组才是最重要的
17
86
735
296,932
Tingchen Fu retweeted

Apr 16
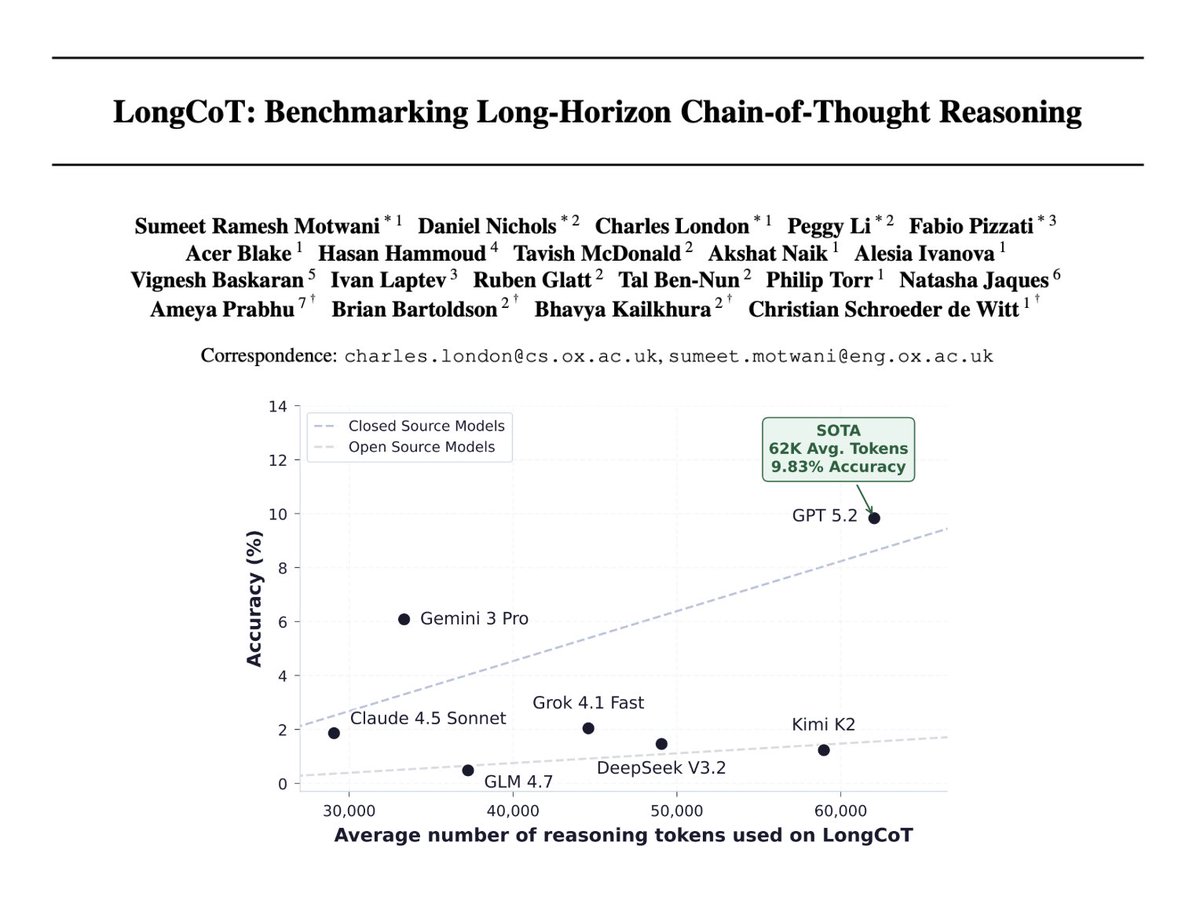
We’re releasing LongCoT, an incredibly hard benchmark to measure long-horizon reasoning capabilities over tens to hundreds of thousands of tokens.
LongCoT consists of 2.5K questions across chemistry, math, chess, logic, and computer science. Frontier models score less than 10%🧵
19
70
404
141,130

Tingchen Fu retweeted

Apr 8
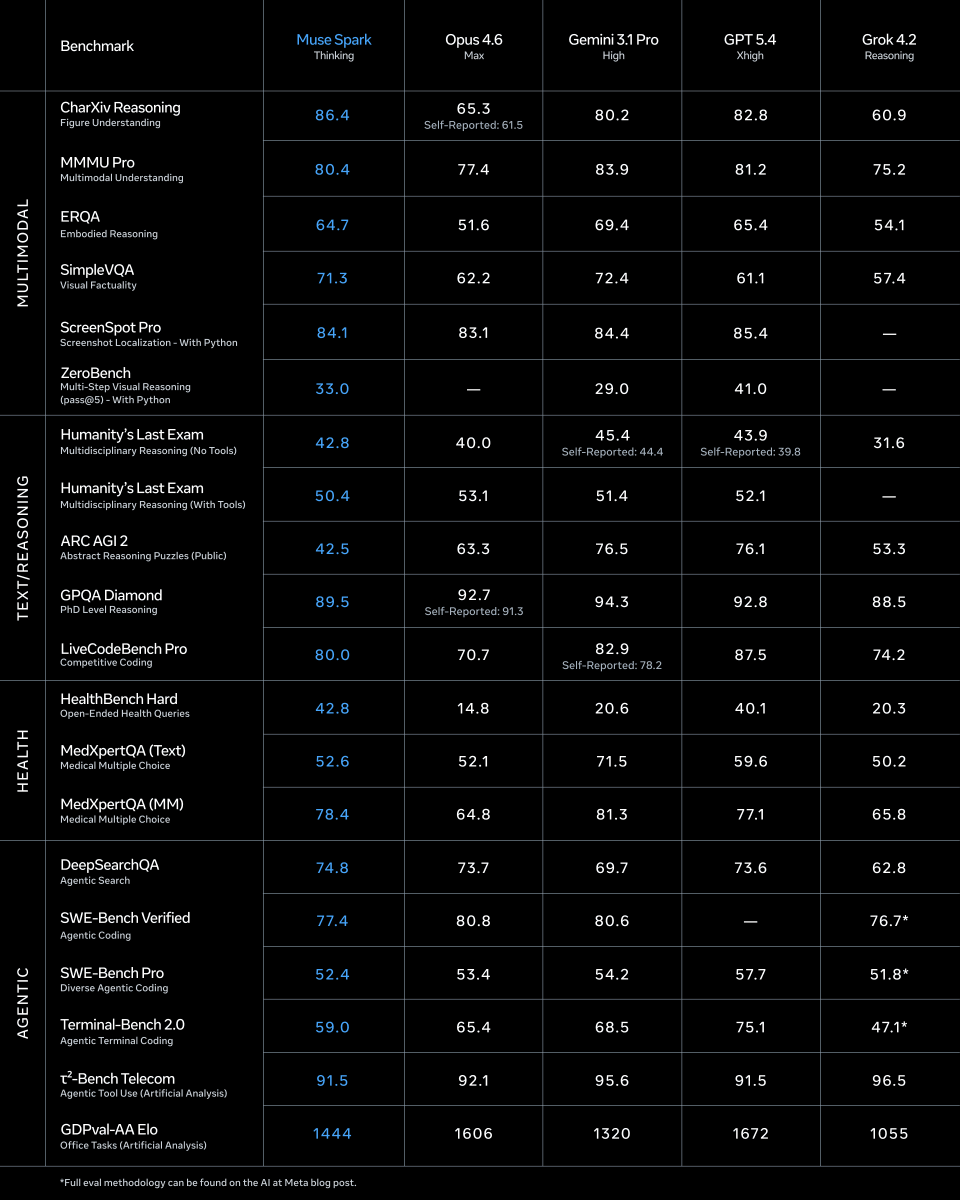
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
745
1,191
10,373
4,553,156
Tingchen Fu retweeted

Apr 7
Introducing ✨Infusion✨, our *new paper* made possible by the UK AISI Challenge Fund and Sovereign AI!
1/8🧵 TL;DR
Influence functions are commonly used to attribute model behavior to its training data. In this paper we explored the reverse: whether it's possible to use influence functions to craft training data that induces model behavior?
Huge thank you to my amazing collaborators for making this possible
@LauraRuis @_robertkirk @egrefen @j_foerst and of course
@AISecurityInst and @UKSovereignAI!

10
29
118
25,472

Two days ago, Anthropic cut off third-party harnesses from using Claude subscriptions — not surprising. Three days ago, MiMo launched its Token Plan — a design I spent real time on, and what I believe is a serious attempt at getting compute allocation and agent harness development right. Putting these two things together, some thoughts:
1. Claude Code's subscription is a beautifully designed system for balanced compute allocation. My guess — it doesn't make money, possibly bleeds it, unless their API margins are 10-20x, which I doubt. I can't rigorously calculate the losses from third-party harnesses plugging in, but I've looked at OpenClaw's context management up close — it's bad. Within a single user query, it fires off rounds of low-value tool calls as separate API requests, each carrying a long context window (often >100K tokens) — wasteful even with cache hits, and in extreme cases driving up cache miss rates for other queries. The actual request count per query ends up several times higher than Claude Code's own framework. Translated to API pricing, the real cost is probably tens of times the subscription price. That's not a gap — that's a crater.
2. Third-party harnesses like OpenClaw/OpenCode can still call Claude via API — they just can't ride on subscriptions anymore. Short term, these agent users will feel the pain, costs jumping easily tens of times. But that pressure is exactly what pushes these harnesses to improve context management, maximize prompt cache hit rates to reuse processed context, cut wasteful token burn. Pain eventually converts to engineering discipline.
3. I'd urge LLM companies not to blindly race to the bottom on pricing before figuring out how to price a coding plan without hemorrhaging money. Selling tokens dirt cheap while leaving the door wide open to third-party harnesses looks nice to users, but it's a trap — the same trap Anthropic just walked out of. The deeper problem: if users burn their attention on low-quality agent harnesses, highly unstable and slow inference services, and models downgraded to cut costs, only to find they still can't get anything done — that's not a healthy cycle for user experience or retention.
4. On MiMo Token Plan — it supports third-party harnesses, billed by token quota, same logic as Claude's newly launched extra usage packages. Because what we're going for is long-term stable delivery of high-quality models and services — not getting you to impulse-pay and then abandon ship.
The bigger picture: global compute capacity can't keep up with the token demand agents are creating. The real way forward isn't cheaper tokens — it's co-evolution. "More token-efficient agent harnesses" × "more powerful and efficient models." Anthropic's move, whether they intended it or not, is pushing the entire ecosystem — open source and closed source alike — in that direction. That's probably a good thing. The Agent era doesn't belong to whoever burns the most compute. It belongs to whoever uses it wisely.
173
229
1,841
771,543
Tingchen Fu retweeted

15
40
209
66,810
Apr 2
The funniest April Fools’ prank this year
117
Tingchen Fu retweeted

Mar 31
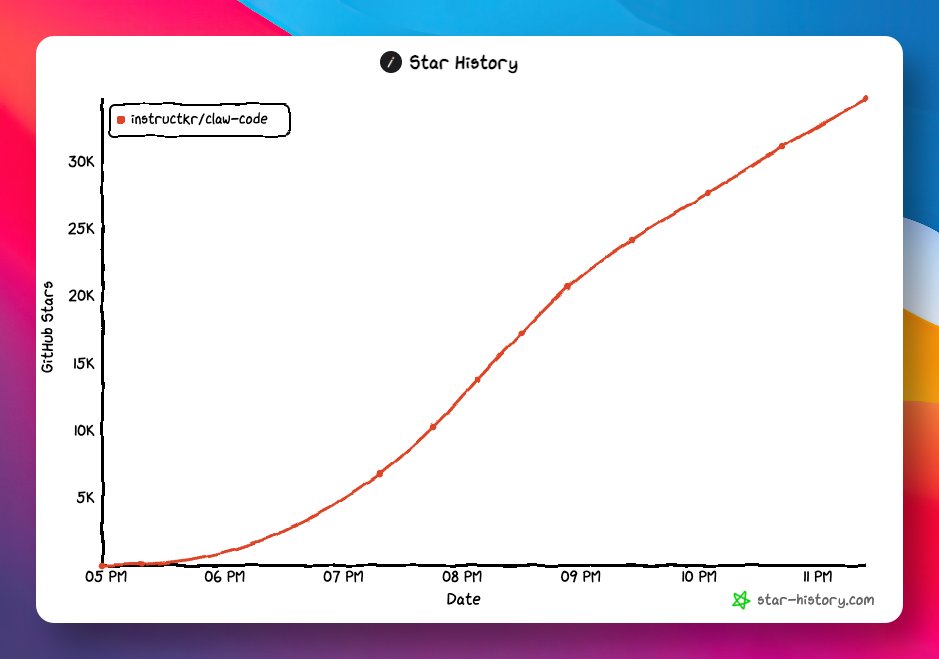
Claude Code 源码泄露,不到 24 个小时。
claw-code 成为 GitHub 历史上最快突破 3 万 Star 的开源项目,还在持续暴涨中。
项目作者在发现源码泄露后,选择从零开始用 Python 重写,实现了 Claude Code 的核心功能。
目前作者已启动 Rust 移植工作,运行速度更快、内存更安全,计划作为该项目的最终版本。
GitHub:github.com/instructkr/claw-c…
感兴趣的朋友可以持续关注一下。
34
173
985
167,432

Tingchen Fu retweeted

Mar 30
Hiring 🎉
Researchers to work on Chains-of-Thought faithfulness, reasoning verification, and AI monitoring robustness, some core questions for how oversight actually works in practice.
Looking for: 2 researchers (with PhD), 1 RA
DM or email with what you'd want to work on.

9
29
202
18,832
Tingchen Fu retweeted

Mar 25
1/ 🪩 Automating the discovery of new algorithms could unlock significant breakthroughs in ML research. But optimising agents for this research has been limited by too few tasks to learn from!
Introducing DiscoGen, a procedural generator of algorithm discovery tasks 🧵

3
44
178
59,062
Tingchen Fu retweeted

Mar 19
Agents can remember. Agents can learn. But can they learn how to learn? 🤔
MetaClaw tech report is out 📄 — a continual meta-learning framework that teaches deployed agents not just to learn, but to learn how to learn, evolving 24/7 through normal usage.
📊 On 588 continual CLI tasks over 14 simulated workdays:
🦞 Kimi-K2.5 accuracy: 21.1% → 39.6% ( 88%)
🚀 Task completion: 18.2% → 51.9% ( 185%)
💪 GPT-5.2 also benefits: 44.9% → 49.1% acc, 58.4% → 67.5% completion
Even the strongest models get better with MetaClaw.
Kudos to the team @richardxp888, @JimChenjw, @Xinyu2ML, @lillianwei423, @StephenQS0710, @HaoqinT, @JiaqiLiu835914, @yuyinzhou_cs, @ZhengBerkeley, @cihangxie

8
51
147
10,810
Tingchen Fu retweeted

Mar 16
The idea of rotating attention by 90° is sooooooo cool (credits to @Jianlin_S 's insights), and it surprisingly works.
We (w/ the amazing @nathan) are so excited about this— been working on the paper for months and couldn't stop.
Go give it a try. It's a drop-in replacement for standard residuals, born in 2015.
really like the figs btw :-)

Mar 16

Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
github.com/MoonshotAI/Attent…

19
71
951
125,800
Tingchen Fu retweeted

Mar 9
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
github.com/karpathy/nanochat…
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.

960
2,124
19,521
3,659,508


249
1,386
11,182
3,992,976