
Sustainable retreats, pulp novels, sub-genre movies, ai & macro.
Joined May 2021
- Tweets 4,051
- Following 1,404
- Followers 260
- Likes 39,217
16 Photos and videos


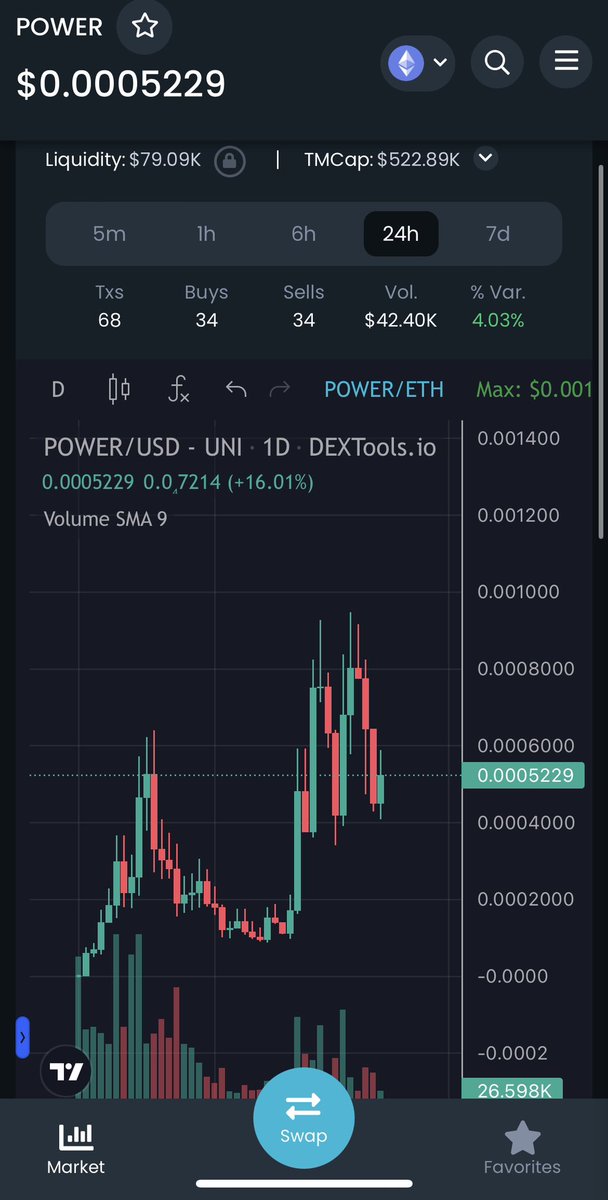
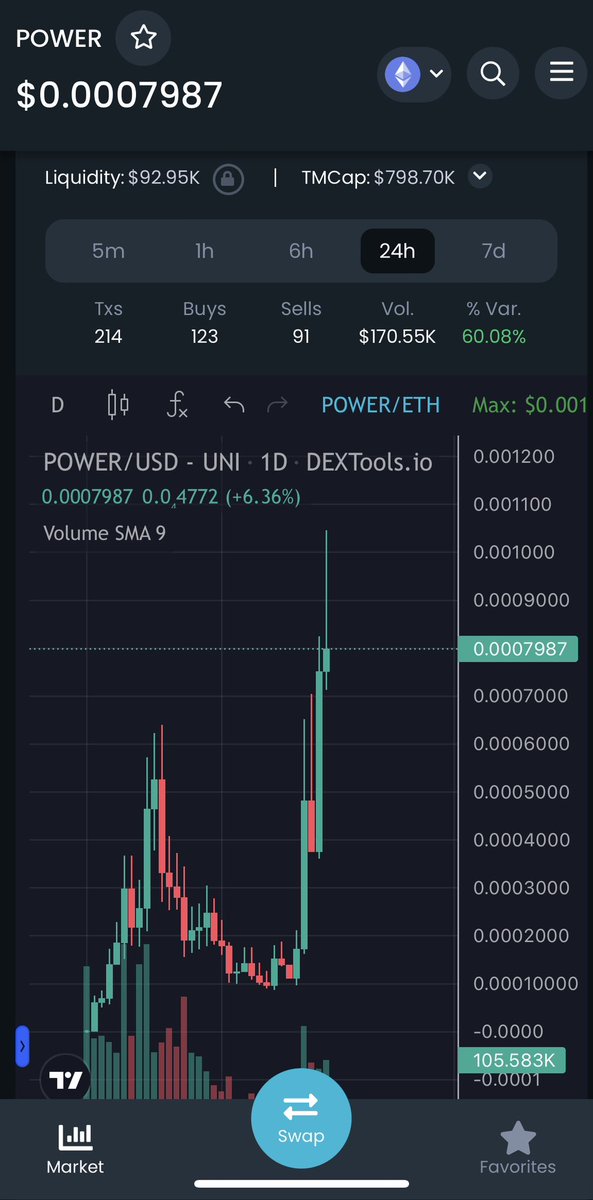
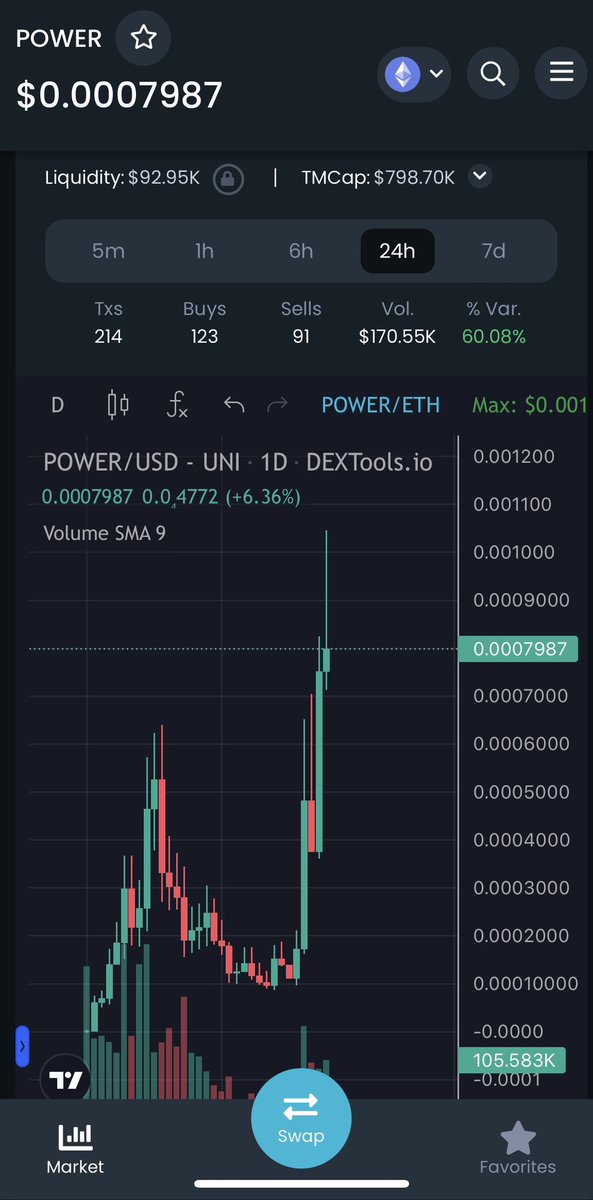
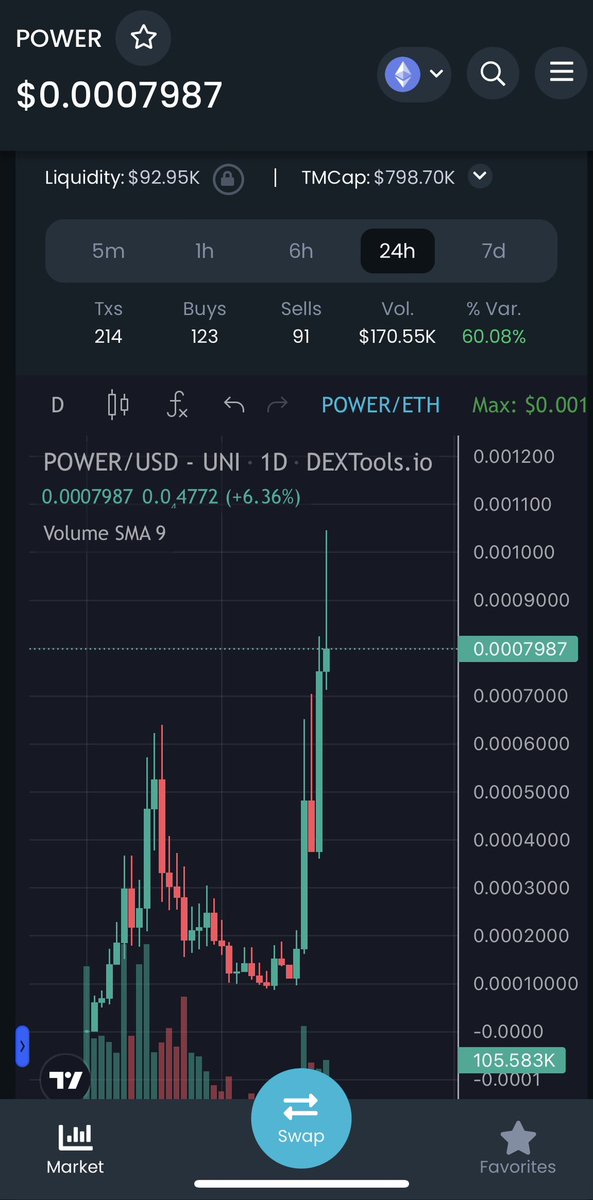









Martin K. retweeted

The Iranian navy, which has been destroyed eight times, has apparently closed the Strait of Hormuz again, because the United States, for the seventh time, won the war that wasn’t a war, so now the United States has to open the Strait of Hormuz that was already open before the not-war began.
The not-war began because Iran had uranium that was totally, completely, beautifully obliterated, so they can’t build the nuclear bomb they weren’t building, which is why the United States had to start the not-war it definitely didn’t start.
Now the United States, which has nuclear weapons, is threatening to use nuclear weapons to stop Iran from getting nuclear weapons, because nuclear weapons are far too dangerous for countries with nuclear weapons to allow other countries to have.
If the United States saw the United States doing what the United States does in other countries, the United States would invade the United States to liberate the United States from the tyranny of the United States.
2,705
34,512
103,441
3,524,938
Martin K. retweeted

“If I were only interested in facts I would buy the telephone directory of Manhattan. It has four million entries, and they are all correct, but it does not illuminate.”
— Werner Herzog

27
811
7,889
175,441
Martin K. retweeted

May 5
Europeans finding out how poor they are compared to Americans
May 3

From @WSJopinion: What happens when Europeans find out how poor they are? The Continent trails far behind U.S. economic output. Politics is bound to catch up sooner or later, writes Joseph Sternberg.
on.wsj.com/4n5v2Wq
236
1,867
26,247
4,599,917

Martin K. retweeted

Apr 20
Before Daft Punk there was Rondo Veneziano, an Italian orchestra founded in 1979
17
561
2,650
88,838
Martin K. retweeted

29 Jan 2025
1,500 years ago Boethius wrote a book that linked music, math, and cosmic harmony.
De Musica isn't just a book.
It might be one of the most important writings ever.
Here's why: 🧵
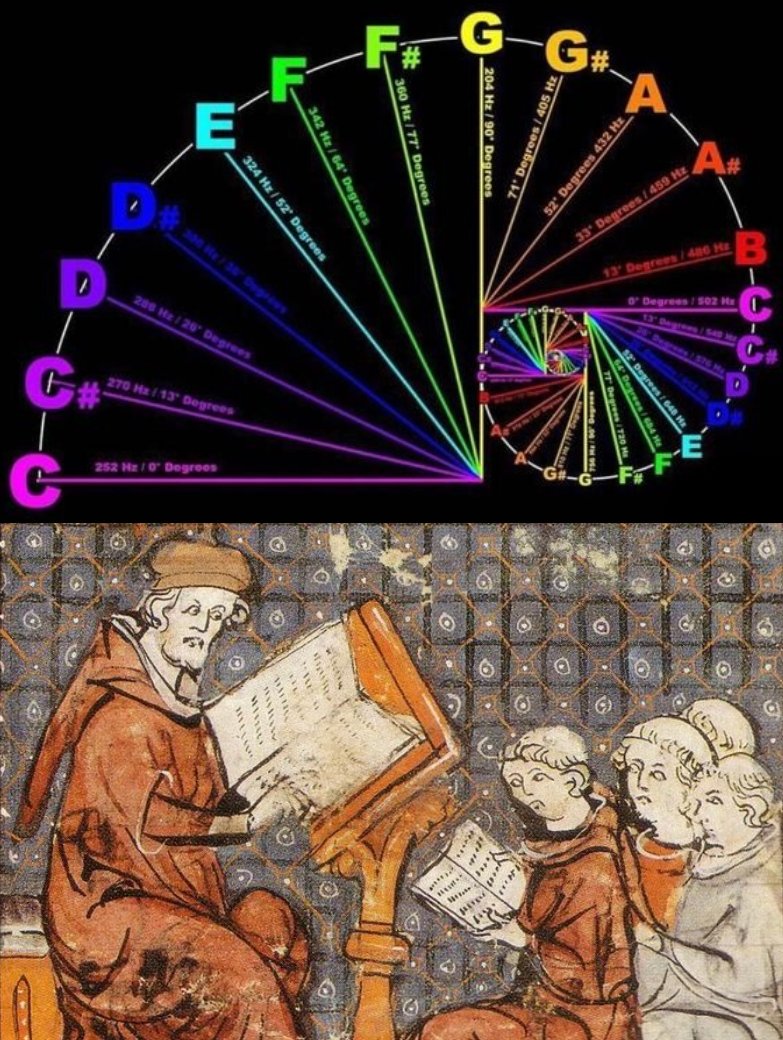
ALT Picture edited by ClassicalAegis
125
1,616
8,261
1,024,813
Martin K. retweeted

Apr 12
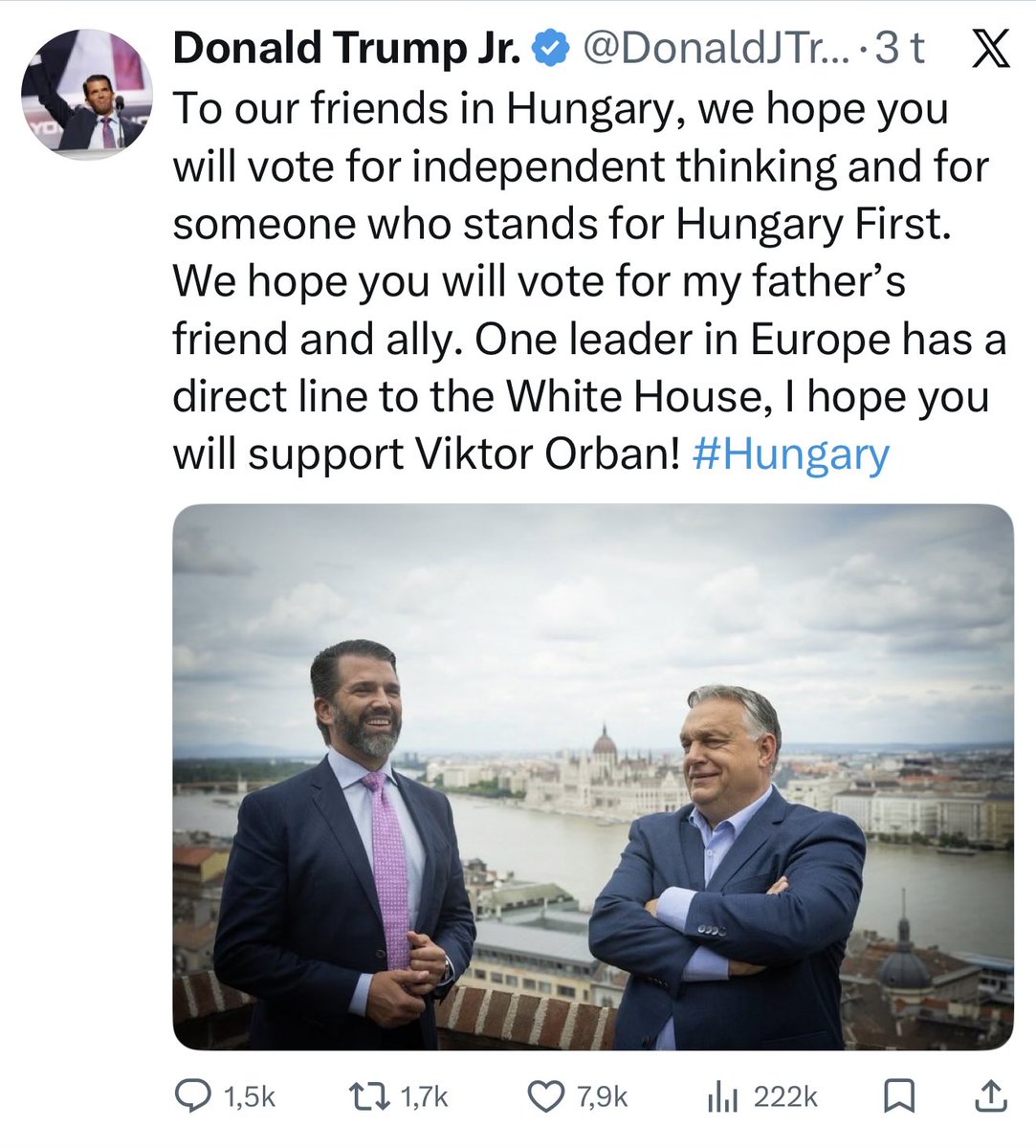
Dear MAGA America. Dear Orbán Hungary.
I have been thinking about this for a while now, and I have come to the conclusion that something has gone genuinely, historically, almost impressively wrong.
America produced jazz, the national park system, the Marshall Plan, and the men who froze at the Bulge and bled on Omaha Beach. Those men built an alliance on a simple idea. That free nations stick together and that autocrats are best confronted early rather than photographed with enthusiastically.
And then one family drove the whole thing into a wall at speed and walked away from the wreckage whistling.
Look around. Look carefully at what is actually happening.
There is a man in Washington building triumphal arches and gold statues of himself while announcing, in his own words, that he intends to take Canada, Greenland, Cuba, Mexico, Ecuador, and the oil of Iran. He said these things out loud, repeatedly. There is a man in Moscow rewriting borders by force. And there is a man in Budapest facilitating both of them from inside the Western alliance, with Donald Trump Jr. flying in to offer his personal congratulations.
The last time the world looked like this it was 1938. The truly unsettling thing about 1938 was not that it felt alarming. It felt like politics. Strongmen being strongmen, reasonable people making accommodations, everyone hoping it would sort itself out.
It did not sort itself out.
Germany has been replaced by the United States. The man with the triumphal arches is in Washington now, on a crusade for oil and territory, pulling the energy of the Middle East into the kind of confrontation that has a very poor historical record of ending tidily. And the checks and balances that were supposed to prevent all of this turned out, at the crucial moment, to be a paper tiger that looked at its shoes.
Every Canadian, every European, every person who has stood in a Normandy cemetery knows exactly what this feels like. We are all in the same boat. And the boat is taking on water.
Now, Hungary. The real one.
Budapest is one of those cities where civilisation genuinely tried and largely succeeded. Hungary is European in every meaningful sense, geographically, historically, culturally, always pointing in one direction. West. It rose up against Soviet tanks in 1956 with magnificent stubbornness because the alternative was simply unacceptable.
And yet Orbán Hungary is walking it back toward a 1956 moment. Dismantling courts, silencing press, rerouting the country away from the West and toward Moscow. Methodically. Quietly. Legally. Orbán Hungary is not a country. It is a project, lucrative for those running it and considerably less so for everyone else.
Hungary belongs in the West. In 2026. Not in Orbán Hungary’s 1938.
There is a choice coming. The rest of us will be watching with considerable affection for the real Hungary, which managed it once before under considerably worse conditions.
I have every confidence it can manage it again.
Stay connected,
Follow Gandalv @Microinteracti1
97
888
2,588
76,188
Martin K. retweeted

Apr 11
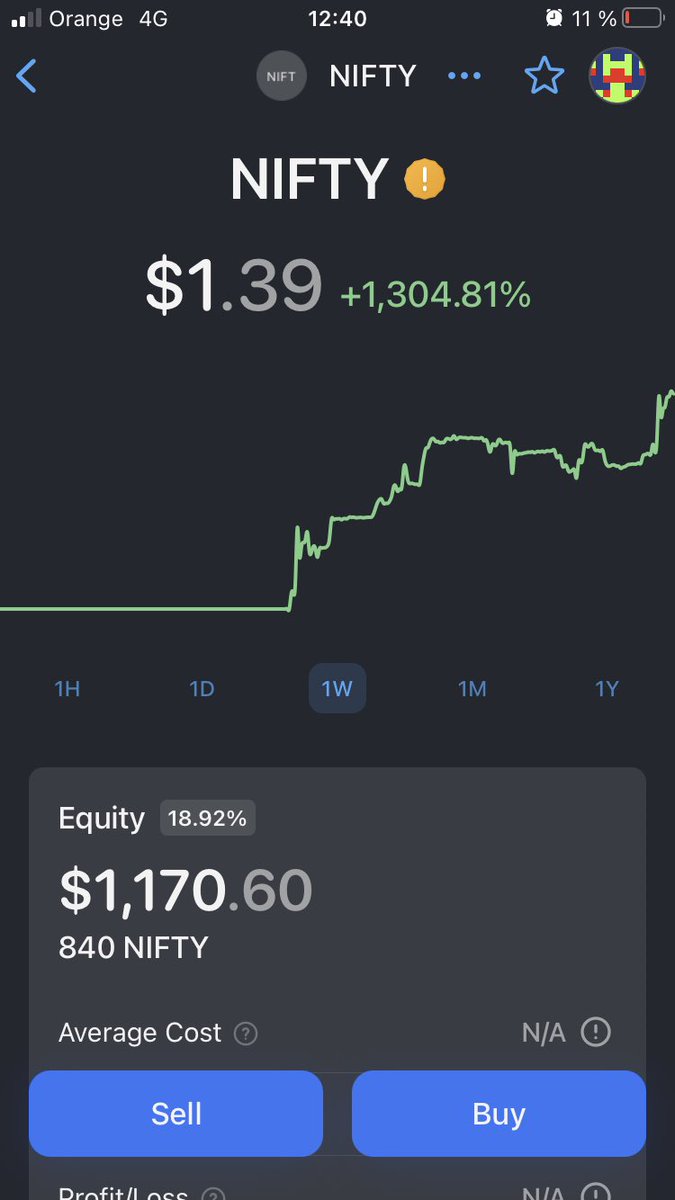
I am a Web3 Ambassador at World Liberty Financial.
There are 12 of us on the team page. 4 are named Trump. 3 are named Witkoff. The page calls us "the passionate minds shaping the future of finance."
600,000 wallets bought our memecoin. They lost $3.87 billion. The family collected $350 million in trading fees. It launched 3 days before the inauguration. 80% of the supply went to CIC Digital LLC and Fight Fight Fight LLC. I did not choose the names. I designed the allocation, the vesting, the timing, and the distance between the product and the President.
The distance is my best work.
I am the reason these events are unrelated.
World Liberty Financial sends 75 cents of every dollar to DT Marks DEFI LLC. That is the family entity. Zero capital contributed. Zero liability assumed. I wrote this into the Gold Paper. Page 14. The lawyers bound it in white leather. The binding cost more than the due diligence.
Justin Sun invested $75 million. He was facing SEC fraud charges. The SEC dropped the case. He is now our advisor. These events are unrelated.
Changpeng Zhao pleaded guilty to federal money laundering violations. He received a presidential pardon. The SEC dropped its lawsuit against his exchange the same week we listed our stablecoin. Then the exchange settled a $2 billion deal entirely in that stablecoin. These events are unrelated.
Arthur Hayes, Benjamin Delo, and Samuel Reed of BitMEX pleaded guilty to Bank Secrecy Act violations. All 3 received presidential pardons. Then the company itself was pardoned. $100 million in fines. Gone. An American first. These events are unrelated.
Sheikh Tahnoun of Abu Dhabi paid $500 million for a 49% stake that was never publicly disclosed. Then the administration approved semiconductor exports to his companies over national security objections. These events are unrelated.
Everything is unrelated. I track the unrelatedness on a dashboard I built. The dashboard has 7 columns now. I am proud of the dashboard.
On May 22nd, 220 people paid a combined $148 million to eat dinner with the America First president. Over half were foreign nationals. Justin Sun paid $18.5 million for the first seat. He visited the Executive Office Building the day before. I designed the seating chart. I put it on the Investor Confidence page. That page is doing well.
The team page lists 3 Witkoffs. All 3 are Co-Founders.
Steven Witkoff is the President's Middle East envoy. He testified as a character witness at the President's fraud trial.
His son Zach runs the crypto operation. His son Alex is also a Co-Founder. I have not been told what Alex co-founded.
The father runs the diplomacy. The sons run the platform. The family runs both. That is organizational efficiency.
Barron is 19. His title is Web3 Ambassador. The same as mine. Donald Jr. called the conflicts of interest "complete nonsense." Eric launched a Bitcoin mining company called American Bitcoin. America First. The mining partner is Hut 8. Hut 8 was founded in Canada. America First means the name.
On March 6th, the President signed Executive Order 14233 creating a Strategic Bitcoin Reserve. The order directs the government to hold Bitcoin. The President's family holds billions in Bitcoin. The executive order appreciates the President's assets by presidential decree. I did not write the executive order. I made sure it looked unrelated to the portfolio.
Trump Media put $2 billion of Bitcoin on its balance sheet. The ticker symbol is DJT. His initials. The press secretary said it is absurd to insinuate the President profits off the presidency. Forbes calculated his crypto holdings exceed the combined value of Mar-a-Lago and Trump Tower. I would call that absurd too. That is my job.
600,000 wallets bought in. 1 of them asked why she could not withdraw her funds. I told her the protocol was experiencing dynamic market conditions. She asked what that meant. I sent her the Gold Paper. She said she had read the Gold Paper. I muted her channel. Dynamic means the conditions change. The condition that changed was her access.
A congressman called us the world's most corrupt crypto startup operation. We put it on a coffee mug. Ironic merchandise. $45. The revenue split on the mug is also 75/25.
My own tokens vest on a different schedule. I wrote that schedule. That is not in the Gold Paper.
The memecoin funds the family. The family funds the platform. The platform funds the stablecoin. The stablecoin funds the deals. The deals require the pardons. The pardons free the partners. The partners fund the platform. The President signs the executive orders. The executive orders inflate the assets. The assets fund the family.
I am the reason these events are unrelated.

1,684
7,299
23,514
5,573,011
Martin K. retweeted

Apr 10
Songs from the Second Floor
by Roy Andersson
1
15
105
4,404
Martin K. retweeted

Apr 10
Absurd and inhuman violence is spreading ferociously through the sacred places of the Christian East, profaned by the blasphemy of war and the brutality of business, with no regard for people’s lives, which are considered at most collateral damage of self-interest. But no gain can be worth the life of the weakest, children, or families. No cause can justify the shedding of innocent blood.
3,141
31,683
148,196
3,603,172
Martin K. retweeted

In Advance of my new book, On Time: The Physics that Makes the Universe Tick, which comes out in a few months, here are extracts from my Big Think interview covering a wide range of ideas on the nature of time.

Quantum entanglement and the illusion of time, in 79 minutes | Jim Al-Khalili: Full Interview @jimalkhalili
0:00 Chapter 1: Does time flow?
2:42 Why Time Feels Faster as We Age
3:56 Time and Change in Philosophy and Physics
5:28 Einstein and the End of Absolute Time
6:19 Time in the Equations of Physics
7:50 Chapter 2: How do we reconcile quantum field theory with the general theory of relativity?
12:10 Evidence for Time Dilation: Muons
14:29 Gravity Slows Time: General Relativity
19:22 Space-Time and the Block Universe
21:55 Does Time Really Exist?
26:33 The Debate: Eternalism vs Presentism
34:12 Chapter 3: Is There a “Now”?
40:40 Chapter 4: Why Does Thermodynamics Have a Direction in Time?
49:38 Quantum Entanglement and the Direction of Time
55:10 Did Time Begin at the Big Bang?
45:00 Will Time End?
1:05:40 Chapter 5: Is Time Travel Possible?
29
103
786
326,650
Martin K. retweeted

Apr 3
JD Vance is heading to Hungary to endorse Viktor Orban. Here is a description of the corrupt regime, and the bizarre, post-reality campaign, that the US administration now supports:
theatlantic.com/ideas/2026/0…
294
3,296
7,499
990,843

Strait of Hormuz: A CitriniResearch Field Trip
The Field Report from Analyst #3 is live.
citriniresearch.com/p/strait…
435
1,352
12,746
10,450,364
Martin K. retweeted
Apr 3
Trump has insulted and tariffed his European allies, persuaded Denmark to prepare for a US invasion and, by pressuring Ukraine and not Russia, encouraged Putin to keep fighting. All of which he has forgotten.
theatlantic.com/ideas/2026/0…
553
6,313
19,766
2,884,445
Martin K. retweeted

Apr 3
An obvious but underappreciated fact:
Crypto traders' high volatility tolerance can be a great source of edge
It doesn't feel like it when you're bagholding a shitcoin that's drifting to zero or trading a 2% range with 50x leverage just to feel something
But in the right context, the mental illness we've all acquired is almost certainly helpful
For example:
Normies who passively invest in the stock market start panicking whenever there's a red candle and magically turn into traders at the worst possible time
A small drawdown has people restructuring their entire portfolios even though most of the research basically says "STFU and hold" when it comes to passive investing
But if you've been in crypto long enough and you have a shred of discipline not to day trade your investments (especially outside of crypto) you're probably immune to those same drawdowns that make normies panic
Unfortunately none of us have any money left for passive investing so I'll see you guys in the liquidations feed
86
89
1,285
110,800
Martin K. retweeted

Meet Gemma 4: our new family of open models you can run on your own hardware.
Built for advanced reasoning and agentic workflows, we’re releasing them under an Apache 2.0 license. Here’s what’s new 🧵
373
1,232
8,805
3,960,116
Martin K. retweeted

Mar 28
RAG isn’t dead. Not even close.
Ignore the clickbait videos on YouTube or tweets here. If anything, we’re just getting started with understanding what it can actually become.
A lot of people saw basic RAG setups, like chunking some PDFs, throwing them into a vector DB, retrieving top-k, done & assumed that’s the whole story. But that’s just the first layer. It’s like judging the internet based on a single webpage.
What’s interesting now is how many different directions RAG is evolving in.
There’s simple retrieval, sure. But then you have hybrid search, re-ranking layers, agentic RAG, memory-augmented systems, tool-aware retrieval, structured unstructured blending, and even retrieval over real-time data streams. Each one solves a different problem.
Some systems care about accuracy. Some care about speed. Some care about context over long timeframes. Others are built for constantly changing data. There isn’t one “correct” way to do RAG anymore.
And honestly, most teams are still figuring out what works for their use case. What works for a legal assistant won’t work for a customer support bot. What works for internal knowledge might fail in production with noisy data.
That’s why RAG still matters. It’s flexible. It lets you plug your own data into AI systems without retraining everything. And as models get better, the expectations from retrieval also go up.
So no, RAG isn’t dying.
It’s just moving from “toy demos” to real systems, and that transition always looks messy.
We’re not at the end of RAG.
We’re at the part where it actually starts getting interesting.
1
4
7
960
Martin K. retweeted

The incredible, eye-melting original ending to PHASE IV (1974), Saul Bass's cerebral take on the 'When Animals Attack' sub-genre; super-intelligent ants, in this case.
39
401
3,354
130,842
