
Graphics and design professional. Creator of Rasterizer.
Joined May 2014
- Tweets 1,371
- Following 55
- Followers 1,098
- Likes 818
68 Photos and videos









VectorGL retweeted

Jun 6
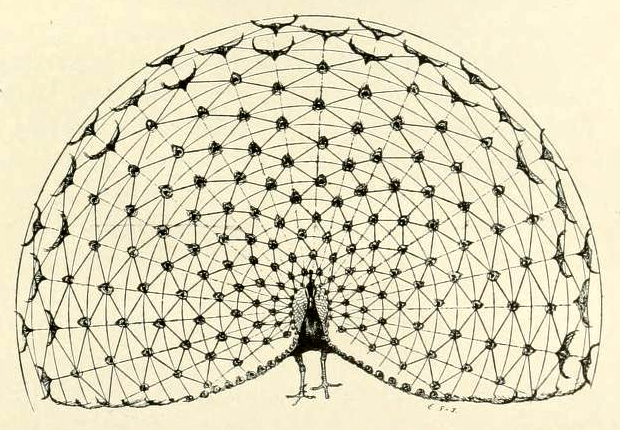
Our mathematical universe. I love looking through vintage drawings from the 1800s that suggest the timeless interplay between math, beauty, and the natural world.
Figure: Ernest Thompson Seton, for his 1896 ornithological study, "Studies in the Art Anatomy of Animals".
6
36
149
4,488
VectorGL retweeted

An engineer built an interactive book on data structures and algorithms of 680 pages:
39
733
5,938
352,197
VectorGL retweeted

Mar 17
New blog post: A Decade of Slug
This talks about the evolution of the Slug font rendering algorithm, and it includes an exciting announcement: The patent has been dedicated to the public domain.
terathon.com/blog/decade-slu…


48
377
2,223
292,520
VectorGL retweeted

Mar 19
Interference (537 chars)
Couldn't get this one to fit inside a tweet
shadertoy.com/view/scSGD1
15
73
503
17,377


Curious why Scripting runs on Luau? Our CTO @luigirosso breaks down the architecture, tradeoffs, and why a fast, safe, lightweight language makes the most sense for real-time graphics: rive.app/blog/why-scripting-…
4
6
36
13,836
VectorGL retweeted

18 Nov 2025
Here's some cute bounding box functions for 2D shapes. A link to a longer list in the next post.
20
351
4,453
174,063
VectorGL retweeted

21 Oct 2025
Open for new job or freelancing in the near future. Anything with realtime graphics, prototyping, ui/ux, rnd, vfx, games, creative coding, etc. Feel free to reach out, DMs should be open. #UnrealEngine #Unity #threejs #godot
1
1
3
613
VectorGL retweeted

17 Sep 2025
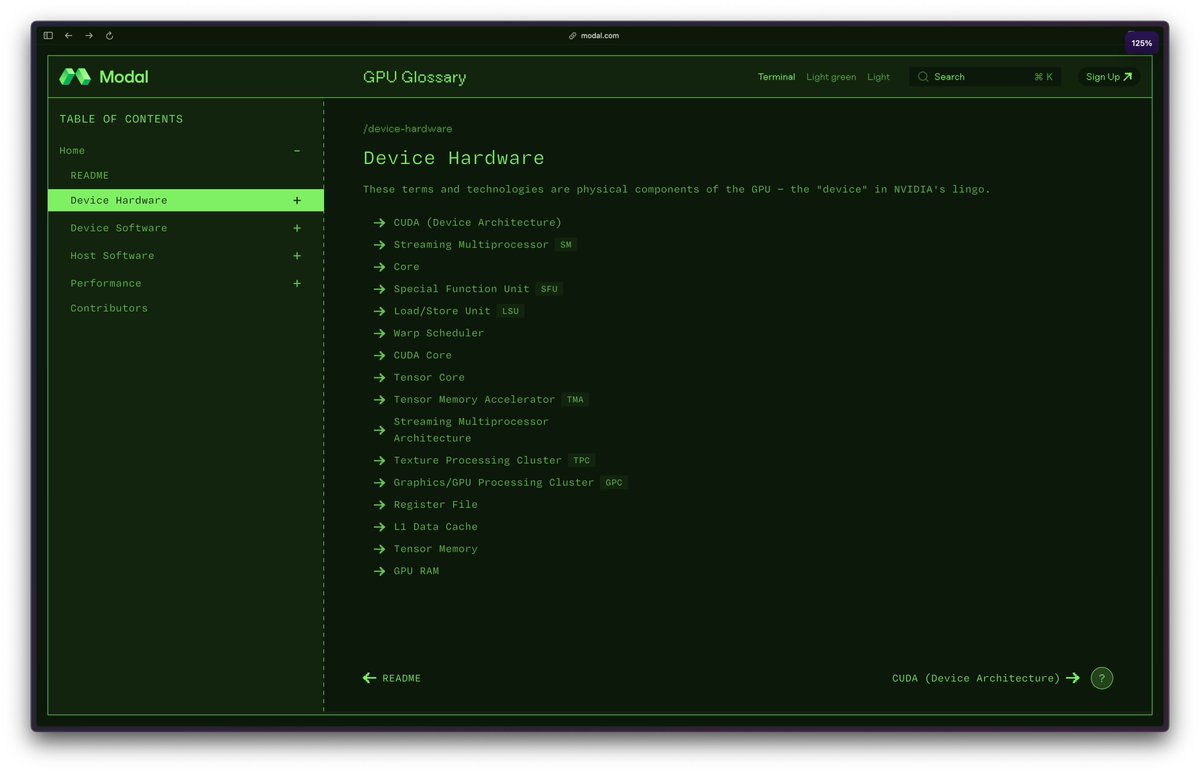
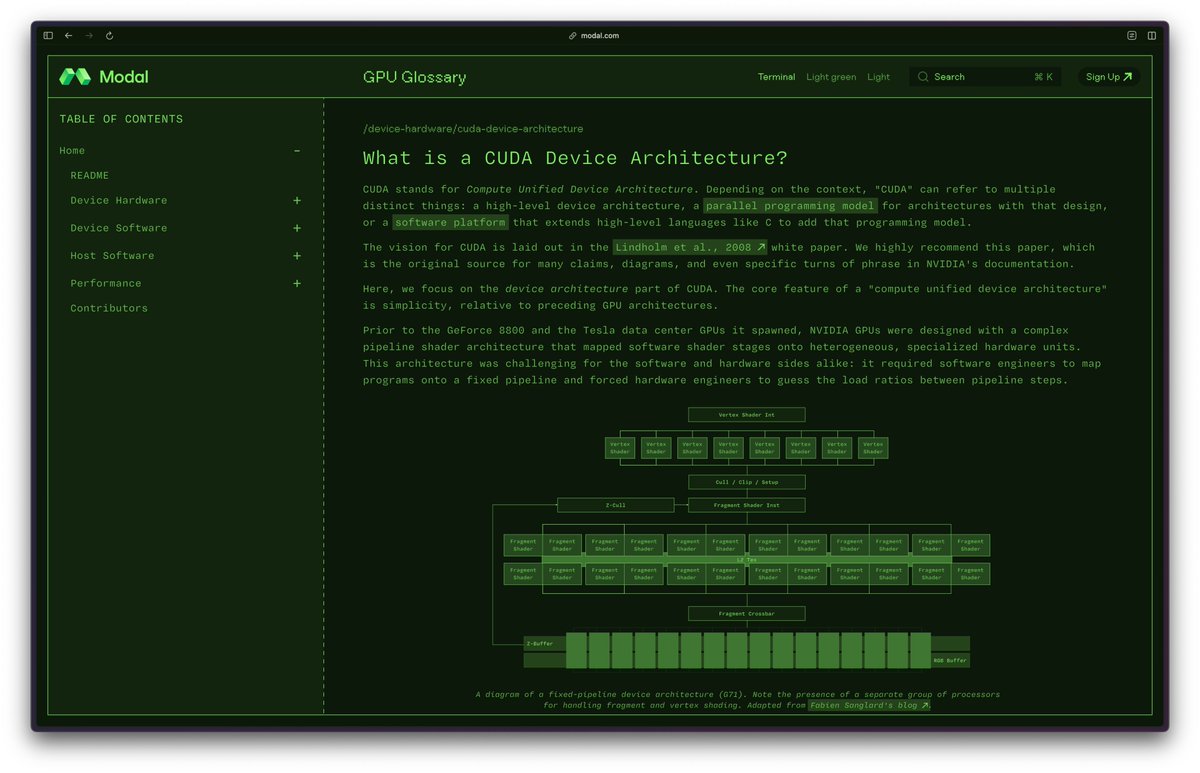
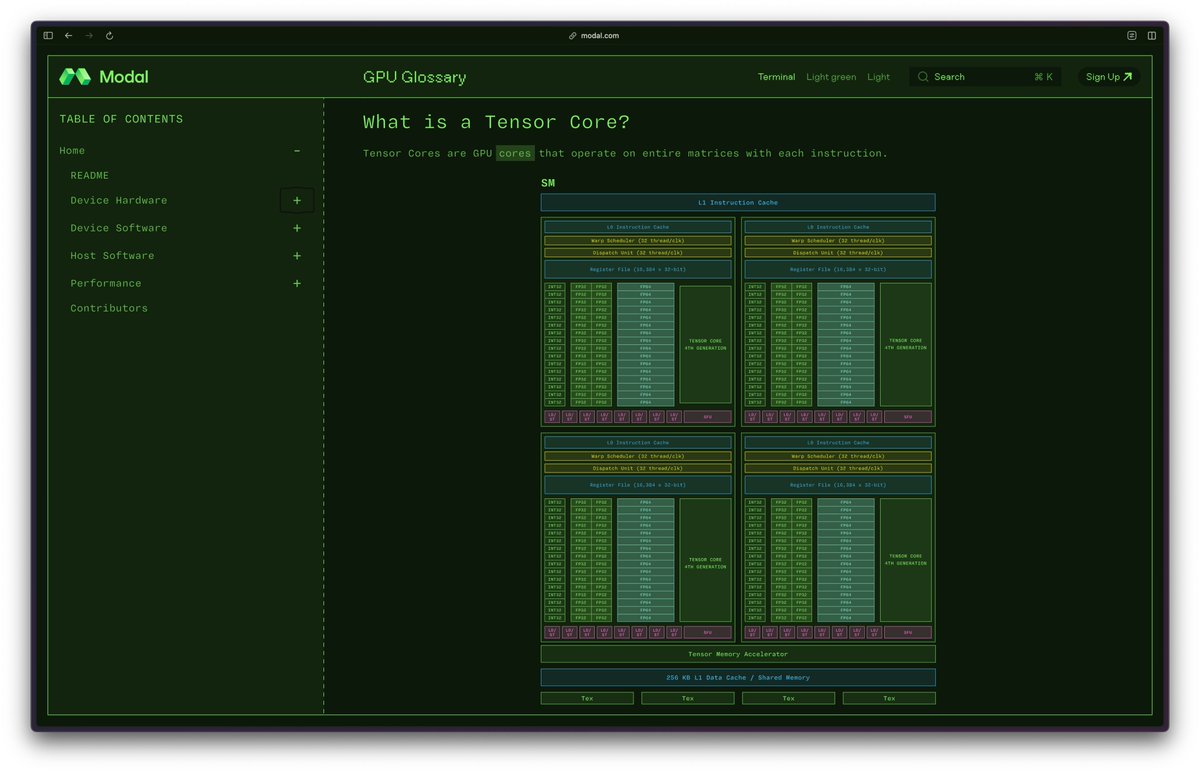
This has to be one of the best GPU programming resources I've found - the GPU Glossary from Modal breaks down complex concepts with clear visuals and explanations, from CUDA architecture to Tensor Cores to CTAs.
modal.com/gpu-glossary

13 Sep 2025

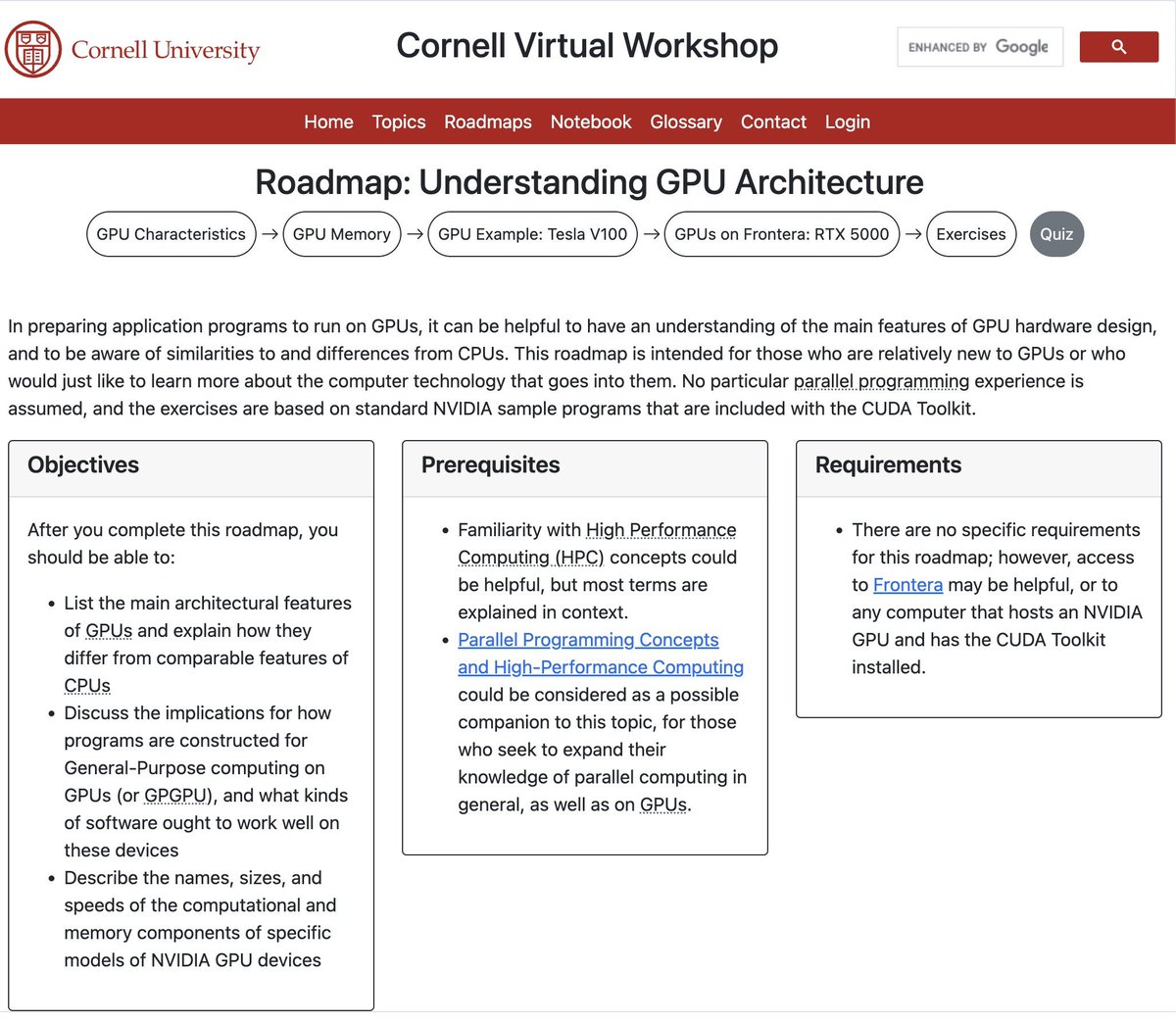
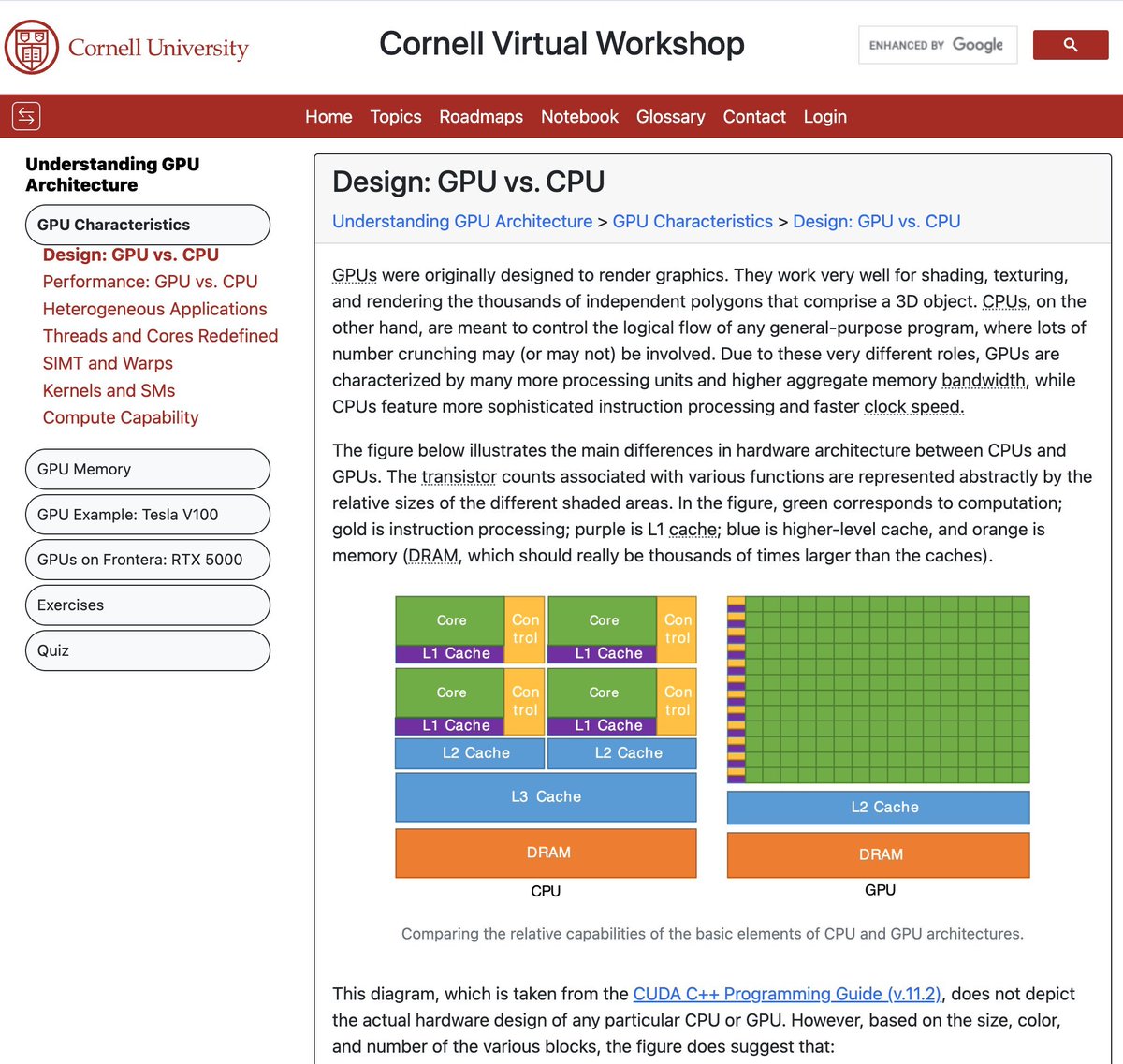
Understanding GPU Architecture from Cornell
cvw.cac.cornell.edu/gpu-arch…
During a low-level discussion at a casual meetup, many folks were interested in understanding GPUs more closely.
While CPUs optimize for complex control flow (see those big cores caches), the GPUs maximize throughput with thousands of simple cores sharing memory. The GPU architecture roadmap is a good starting point for diving deeper.

7
210
1,663
107,134
VectorGL retweeted

18 Sep 2025
There is a lot about Euclid’s Elements that is easily misunderstood. Some proofs seem to have logical gaps. Some constructions seem pointless, others seem needlessly convoluted.
Each of these provides a window into how the ancient Greeks thought about math and the philosophical role that geometry played.
In the fifth and final of a series of guest videos I've been posting, @BenSyversen delves into a question anybody who has had to do ruler and compass constructions in a geometry class may have wondered: What's the point?
youtu.be/M-MgQC6z3VU
36
111
1,459
156,914
VectorGL retweeted

11 Sep 2025
> be me, NVIDIA in 2006
> making GPUs so gamers can play World of Warcraft in HD
> Jensen Huang has a vision
> "what if we made them do... math?"
> entire boardroom thinks he's finally lost it
> create CUDA
> a software prison so elegant, academics will volunteer to be inmates
> gamers are confused. "Will this make Crysis run faster?"
> Jensen: "...no :)"
> fast forward to 2012
> AI researchers, hopped up on adderall and free pizza, discover they need a shitload of matrix multiplication to make cat pictures
> their Intel Xeons are crying, smoking, and filing for divorce
> they discover CUDA
> "holy shit this math thing you made is perfect"
> the entire field of AI becomes a subsidiary of a company known for making Fortnite run better
> we see this and our eyes turn into dollar signs
> decide the prison needs better amenities
> invent Tensor Cores
> "what if part of the chip did ONLY the AI math, but did it at ludicrous speed?"
> it's like adding a nitro booster to a Honda Civic specifically for going to the grocery store
> AMD's competing card is over there trying to do the same math with a abacus and hope
> because researchers are so lazy they can't be trusted to write a for-loop
> just give them a big red "MAKE AI" button that runs our code
> create cuDNN
> bake it directly into TensorFlow and PyTorch
> ecosystem lock-in is complete. We own the land, the factory, and the souls of the workers.
> a bunch of hippies from a thing called "OpenAI" call
> they want to build AGI or something
> they need compute
> roll up to their office, which is probably a converted garage, with the world's first DGX-1
> it's like the monolith from Space Odyssey
> I tell them it has 8 GPUs connected by NVLink, so they can gossip like schoolgirls at light speed
> they ask what it does
> "It does AI, idiots. Just plug it in."
> they sign the papers.
> But we're not done. The prison needs a better yard.
> See them trying to connect our beautiful DGX boxes with CAT-5 cables
> embarrassing.
> Acquire Mellanox for their InfiniBand tech
> Now the nervous system connecting the GPUs is also ours
> NVSwitch makes an entire rack of GPUs hold hands so tight they become one colossal mega-brain
> Meanwhile, in a dimly lit basement in Santa Clara... AMD
> They drop a new GPU. "The AMD Instinct MI300X! We have more theoretical FLOPs!"
> "Better Benchmark performance."
> One brave researcher tries to use it.
> spends 6 weeks trying to install ROCm, their knock-off wish.com version of CUDA
> gets 400 errors, a kernel panic, and divorce papers from his wife
> he finally gets a model to run at half the promised speed
> The benchmark was for a matrix size of 1x1
> He throws the card in the trash and buys an NVIDIA H100 on the company card. The cost is irrelevant.
> Sanity is priceless.
> Jensen takes the stage. The leather jacket has its own gravitational pull. Unleashes the GB200 NVL72
> 72 GPUs and 36 Grace CPUs in a single NVLink domain with 130 TB/s of bandwidth
> the GPUs share thoughts before they even have them.
> 2025
> AMD comes out with their "rack scale" solution, the MI355X 128-GPU rack
> It's just 16 groups of 8 GPUs duct-taped together with Ethernet
> A scale out clown car
> We announce Rubin CPX GPU enabling cheaper prefill during inference
> saving $$$$
> it's the ultimate vendor lock-in
> every other chip designer sees this and has to throw their architecture in the trash and go back to the drawing board
> All hail the leather-clad prophet.

144
735
8,380
617,084

5 Sep 2025
This was posted on Monday and went nowhere. Today it is on the front page. Thank you HN gods ;-)
1 Sep 2025

Hacker News thread for Rasterizer: news.ycombinator.com/item?id…
Upvotes much appreciated.
1
12
987
VectorGL retweeted

1 Sep 2025
Last week, I published a chapter about color. It's fairly comprehensive:
makingsoftware.com/chapters/…
69
335
3,277
182,707

1 Sep 2025
Hacker News thread for Rasterizer: news.ycombinator.com/item?id…
Upvotes much appreciated.
2
7
1,847
1 Sep 2025
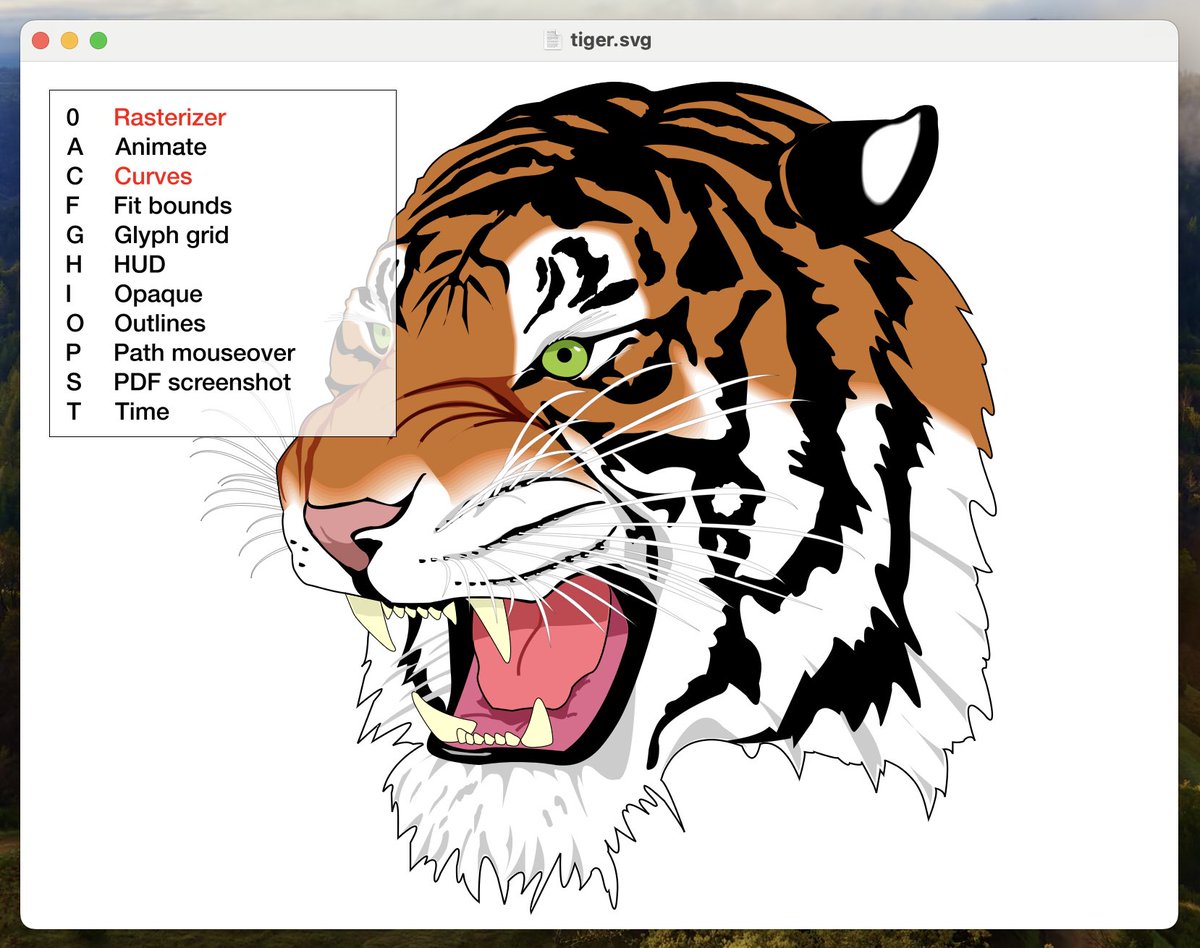
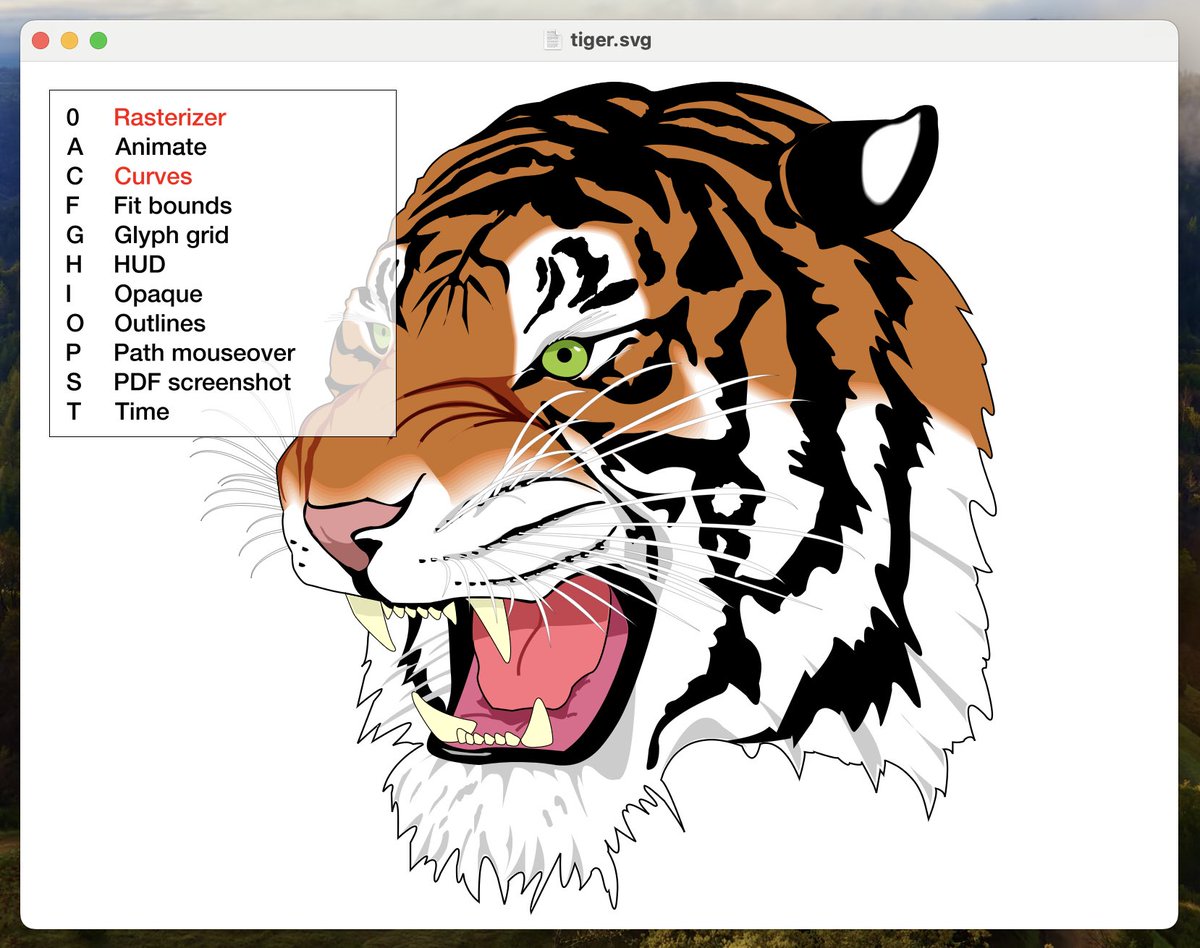
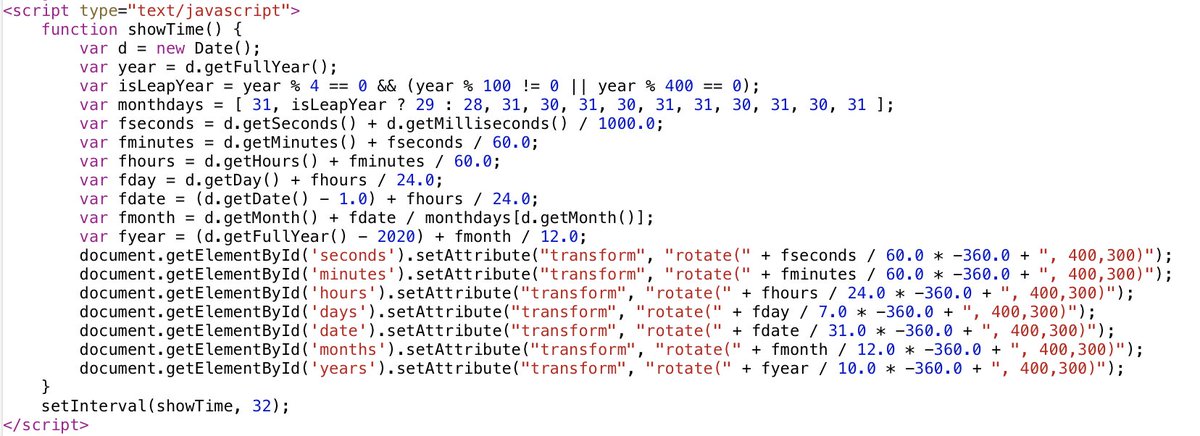
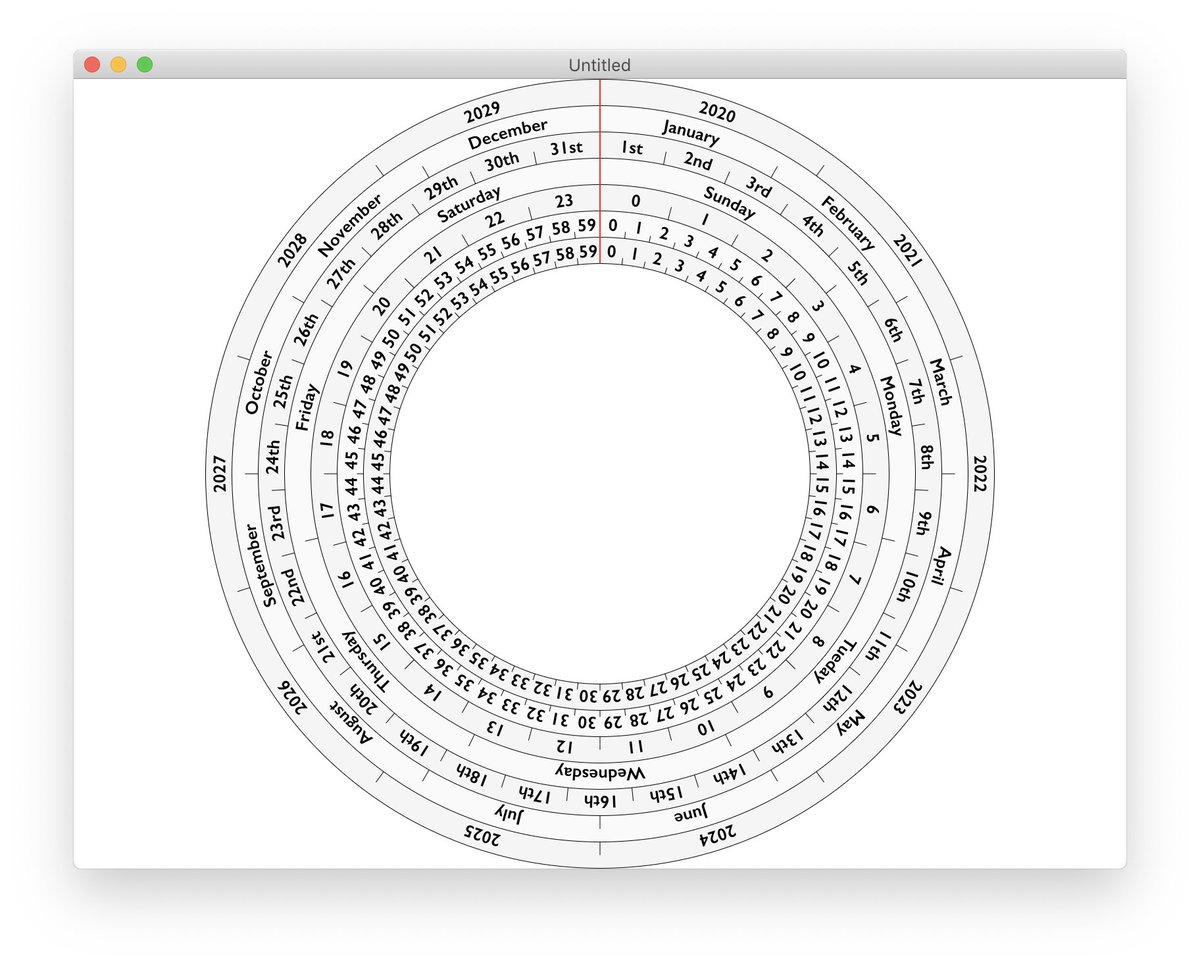
Rasterizer, the 3rd iteration of my 2D GPU-accelerated vector graphics engine, is now available.
• Around 30x faster than Core Graphics
• Less than 4,000 lines of code
• CPU stages use efficient batch parallelism
• Quadratic Béziers solved on GPU
github.com/mindbrix/Rasteriz…
6
34
308
17,908
VectorGL retweeted

29 Nov 2024
"Quadratic Approximation of Cubic Curves" contains a neat method of representing one cubic Bézier as two C1-continuous quadratics, maintaining tangents at the endpoints. Combining that with a heuristic for how many times to split the source curve gives excellent results.
1
3
8
888
29 Aug 2025
Rasterizer, the 3rd iteration of my 2D vector GPU engine, will be released on Monday.
1
2
14
734
VectorGL retweeted

20 Aug 2025
Developed a more generalized version. The pattern 東南西北 can be displaced, but remains conserved.
38
243
3,115
240,017
VectorGL retweeted

19 Aug 2025
Hi, my name is Peter and I’m a Claudoholic. steipete.me/posts/just-one-m…
15
11
207
25,200