
CS PhD student @PrincetonCS, Currently Intern @nvidia, Previously CS MEng BS @CornellCIS
Joined November 2021
- Tweets 65
- Following 200
- Followers 1,043
- Likes 137
14 Photos and videos






Pinned Tweet

Apr 22
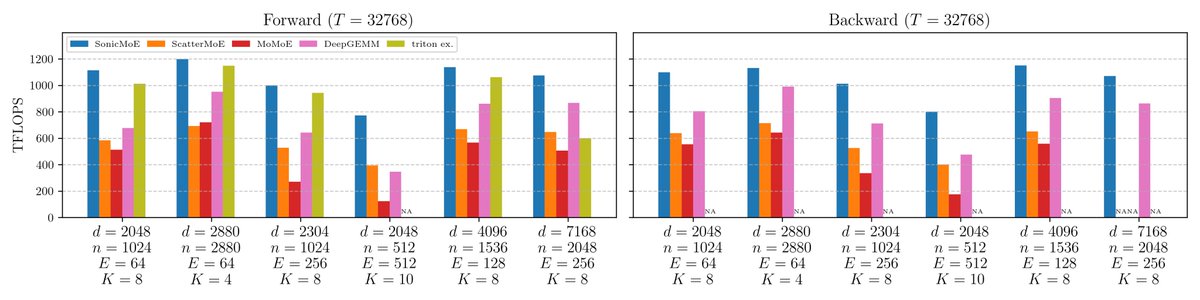
🚀SonicMoE🚀now runs at peak throughput on NVIDIA Blackwell GPUs 😃
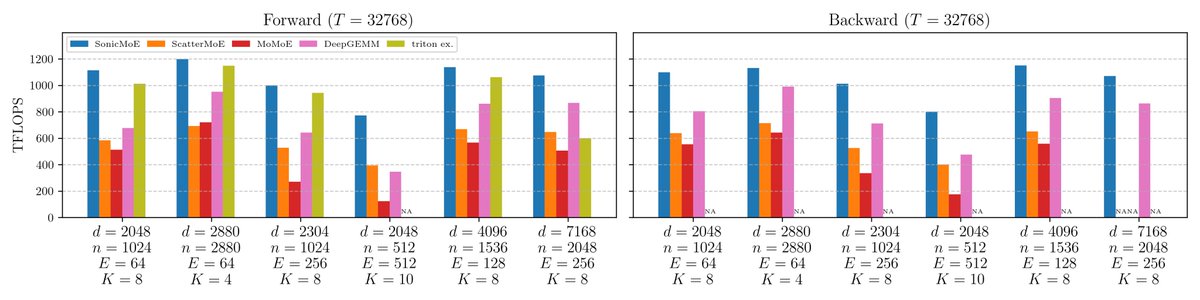
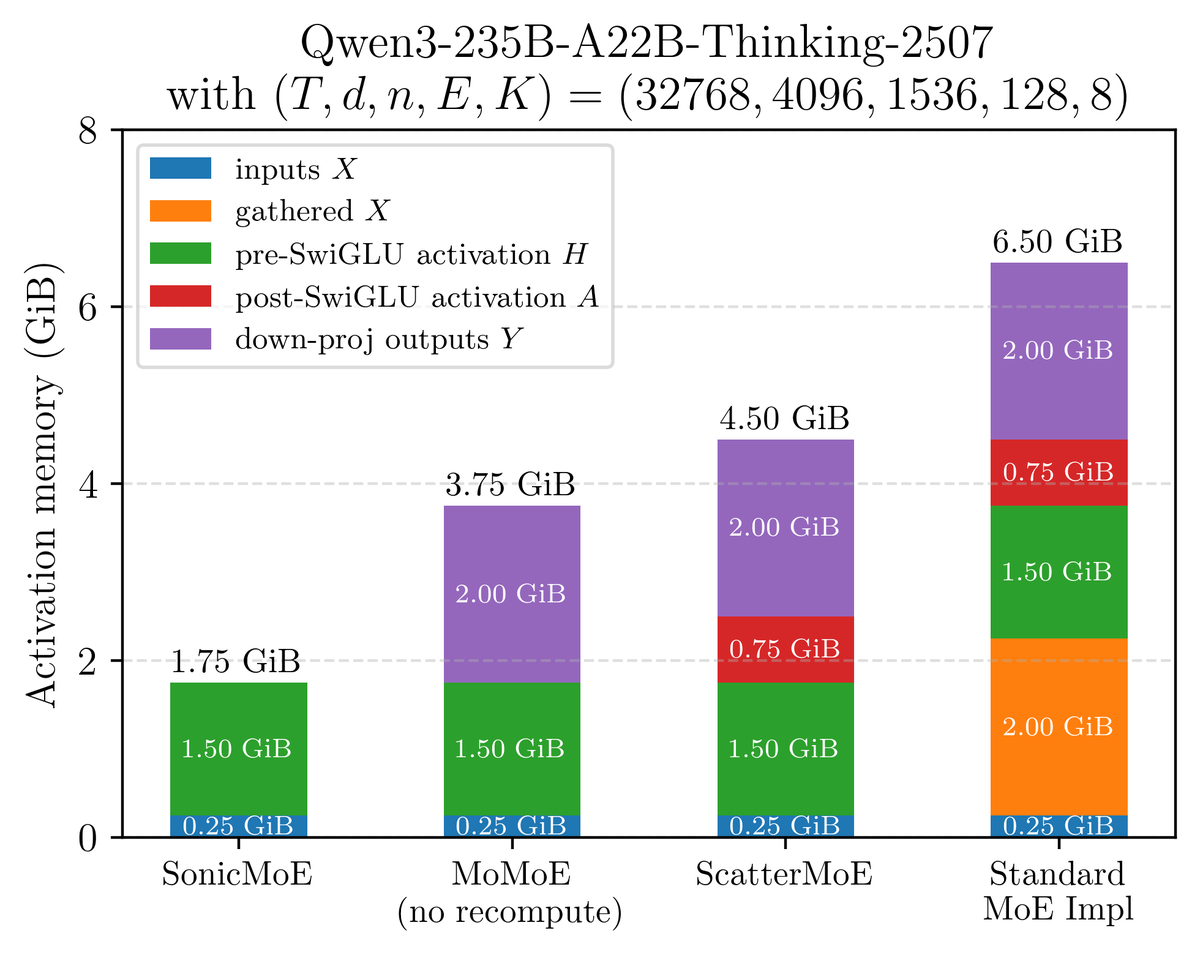
54% & 35% higher fwd/bwd TFLOPS than the DeepGEMM baseline and 21% higher fwd TFLOPS than the triton official example. SonicMoE still maintains its minimum activation memory footprint: the same as a dense model with equal activated parameters and independent of expert granularity. We wrote a blogpost on how we leveraged Blackwell features and the software abstraction on QuACK:
Work with @MayankMish98, @XinleC295, @istoica05, @tri_dao
14
59
331
56,919
Wentao Guo retweeted

Excited to share that LessIsMore has been accepted to ICML 2026! 🚀
LessIsMore is a training-free sparse attention for efficient long-horizon reasoning. By enforcing cross-head unified token selection, it brings up to 1.6x E2E speedup while preserving reasoning accuracy under practical workloads.
Huge thanks to my amazing co-authors and mentors @Jackfram2, @JiaZhihao, Ravi!
Paper: arxiv.org/abs/2508.07101
Code: github.com/DerrickYLJ/LessIs…
#ICML2026 #LLM #EfficientAI
8
22
75
9,117
Apr 22
🚀SonicMoE🚀now runs at peak throughput on NVIDIA Blackwell GPUs 😃
54% & 35% higher fwd/bwd TFLOPS than the DeepGEMM baseline and 21% higher fwd TFLOPS than the triton official example. SonicMoE still maintains its minimum activation memory footprint: the same as a dense model with equal activated parameters and independent of expert granularity. We wrote a blogpost on how we leveraged Blackwell features and the software abstraction on QuACK:
Work with @MayankMish98, @XinleC295, @istoica05, @tri_dao
14
59
331
56,919
Apr 22
Again, great thanks to NVIDIA CUTLASS team @nvidia, PLI @PrincetonPLI and AI Lab, SkyLab @BerkeleySky and Together AI @togethercompute
8
624
Apr 22
[7/N]
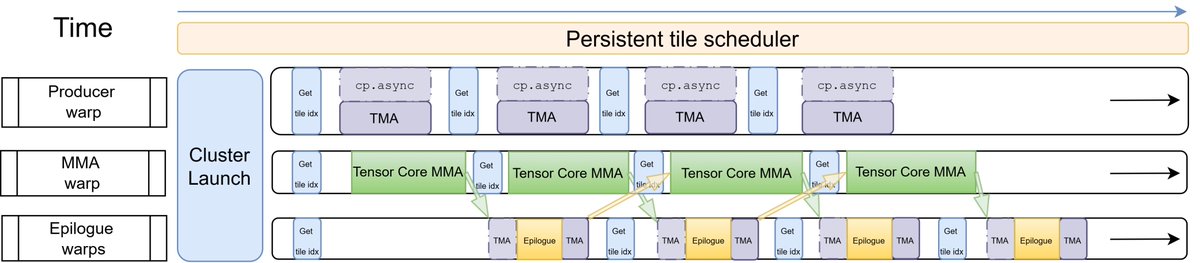
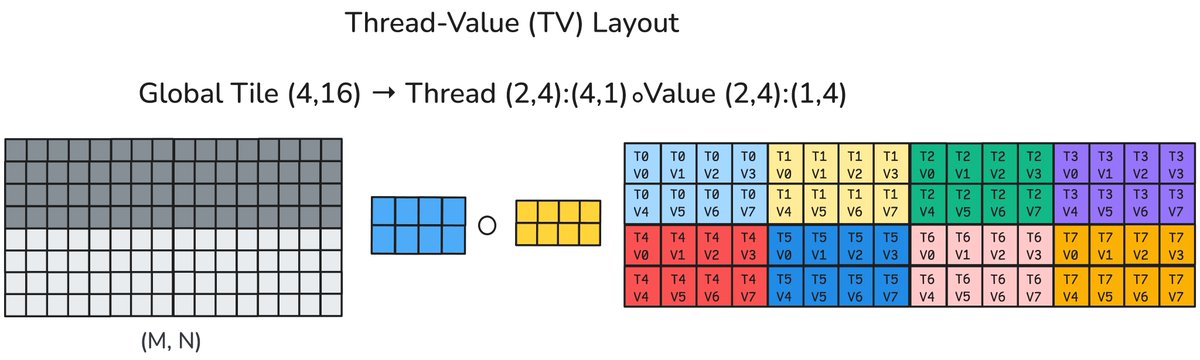
A detailed blogpost of our approach describing how we use Blackwell's TMEM double-buffering, 2CTA MMA, CLC tile scheduling, and gather fusion to hide IO costs behind MMA compute. We also walk through QuACK's software abstraction, and a few ablation studies on Blackwell GPUs.
Blogpost: dao-lab.ai/blog/2026/sonicmo…
1
9
656
Apr 22
[6/N]
All SonicMoE Grouped GEMM kernels are built on QuACK. Each kernel overrides a single function. The most complex kernel (dH backward) only adds ~200 LoC for SonicMoE on top of QuACK, and the same code runs on Hopper and Blackwell GPUs.
1
9
576
Apr 22
[5/N]
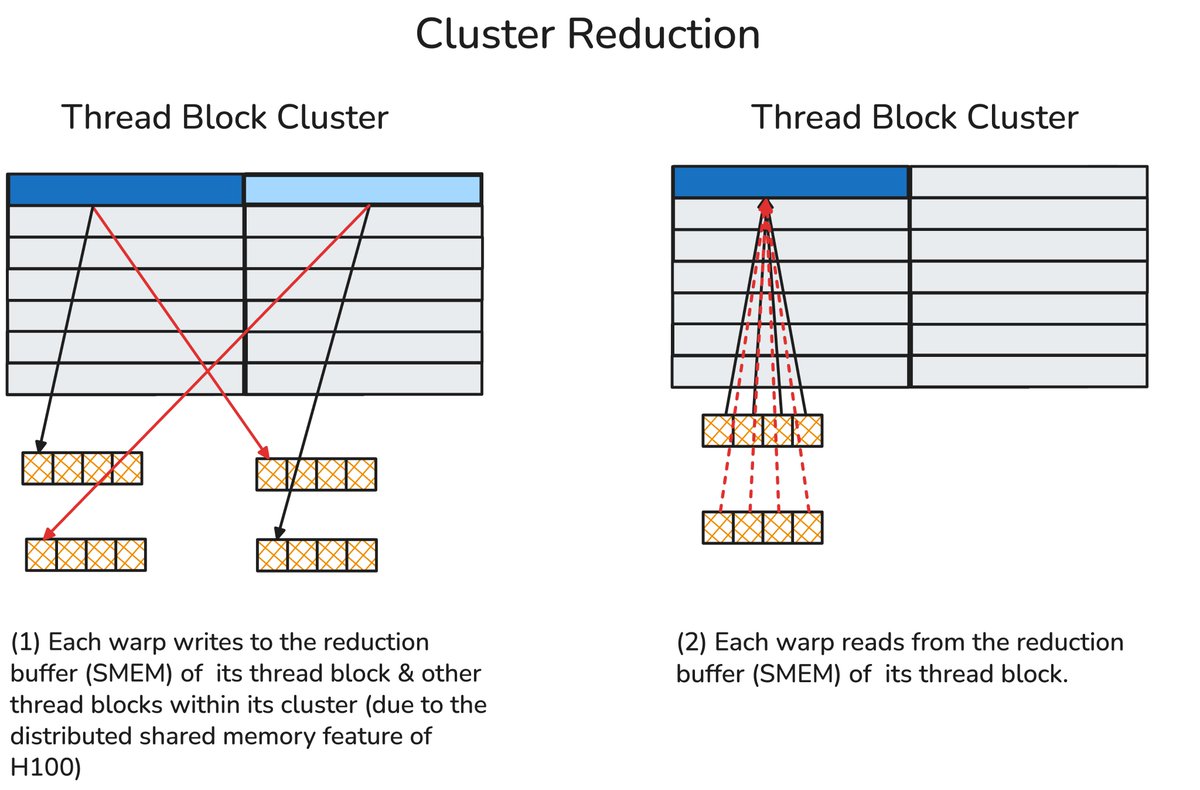
On Hopper, we leverage Ping-Pong warpgroup scheduling to overlap the heavy epilogue IO with the tiled GEMM computation.
On Blackwell, the hardware does it differently but in the same spirit: we have a dedicated on-chip tensor memory (TMEM) split into two accumulator stages. The MMA warp fills one stage while epilogue warps handle the other stage, then they swap. The heavy epilogue IO is overlapped with the tiled GEMM again, which we elaborate on in the blogpost.

1
9
622
Apr 22
[4/N]
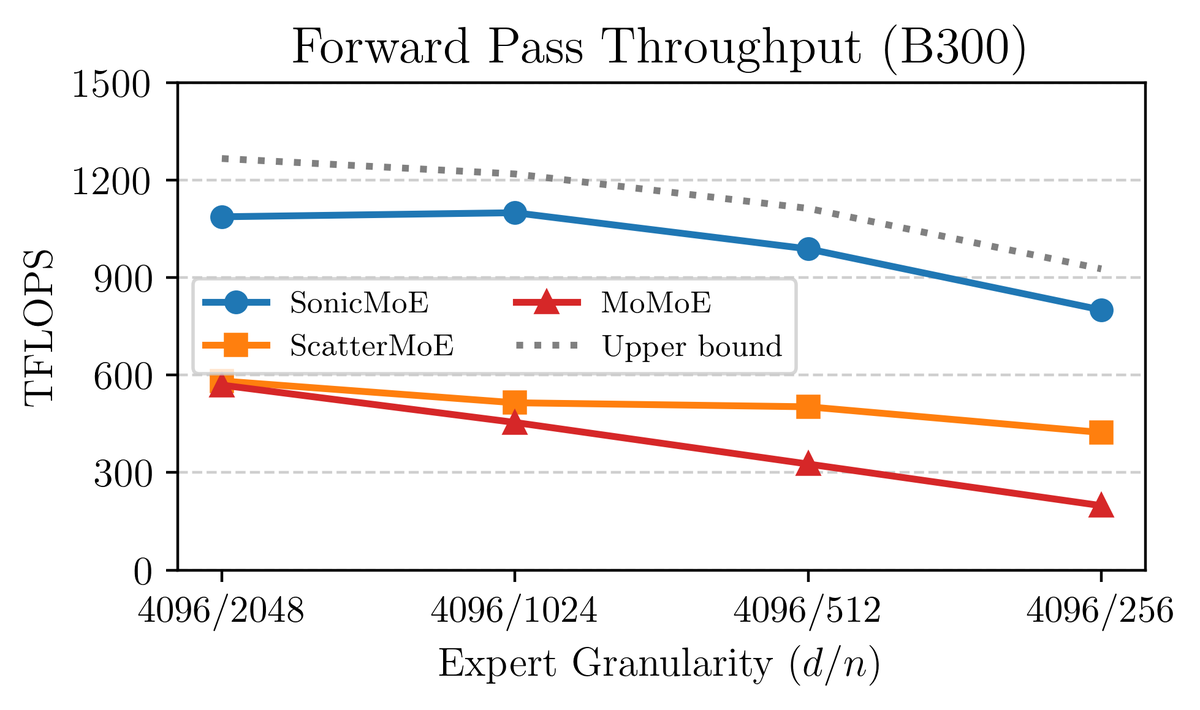
SonicMoE is designed for fine-grained MoEs. It achieves greater relative speedup over existing MoE baselines when we increase the expert granularity on B300 GPUs.
1
2
11
663
Apr 22
[3/N]
On B300 GPUs, SonicMoE achieves 54% & 35% higher fwd/bwd TFLOPS than the DeepGEMM baseline and 21% higher fwd TFLOPS than the triton official example across 6 open-source MoE configs (7B to 685B). SonicMoE often doubles the achieved TFLOPS over ScatterMoE and MoMoE.
1
11
880
Apr 22
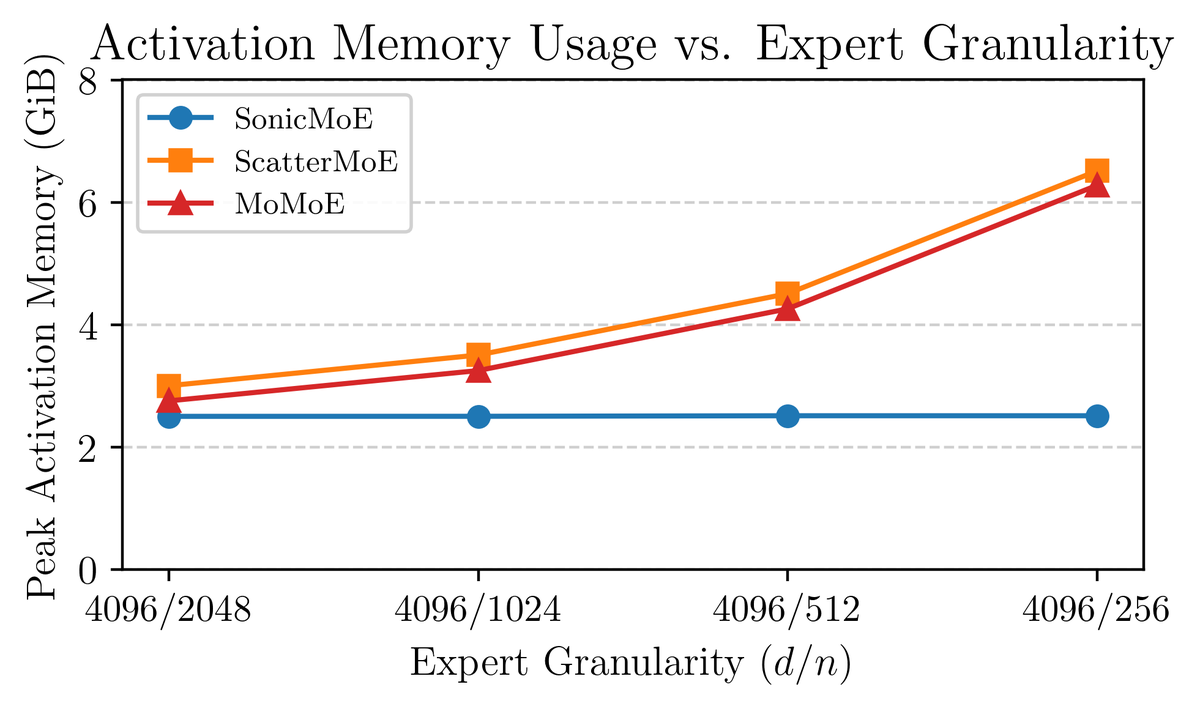
[2/N]
Modern MoEs are scaled towards the fine-grained regime where we have more smaller experts to activate. However, the activation memory footprint of existing MoE kernels will linearly increase and drain the VRAM resources. We instead compute the MoE backward pass in a different but math-equivalent way. Activation memory usage is now the same as a dense model with equal activated parameters, with 45% reduction from community MoE kernels. SonicMoE’s activation memory usage is also independent of expert granularity.
2
12
1,190
Apr 22
[1/N]
Blogpost: dao-lab.ai/blog/2026/sonicmo…
Pip: pypi.org/project/sonic-moe/
Run pip install --upgrade sonic-moe to try it out!
We updated the paper to include Blackwell results: arxiv.org/abs/2512.14080
Code: github.com/Dao-AILab/sonic-m… - Feedback and contribution are welcome!
5
24
2,138
Wentao Guo retweeted

Mar 30
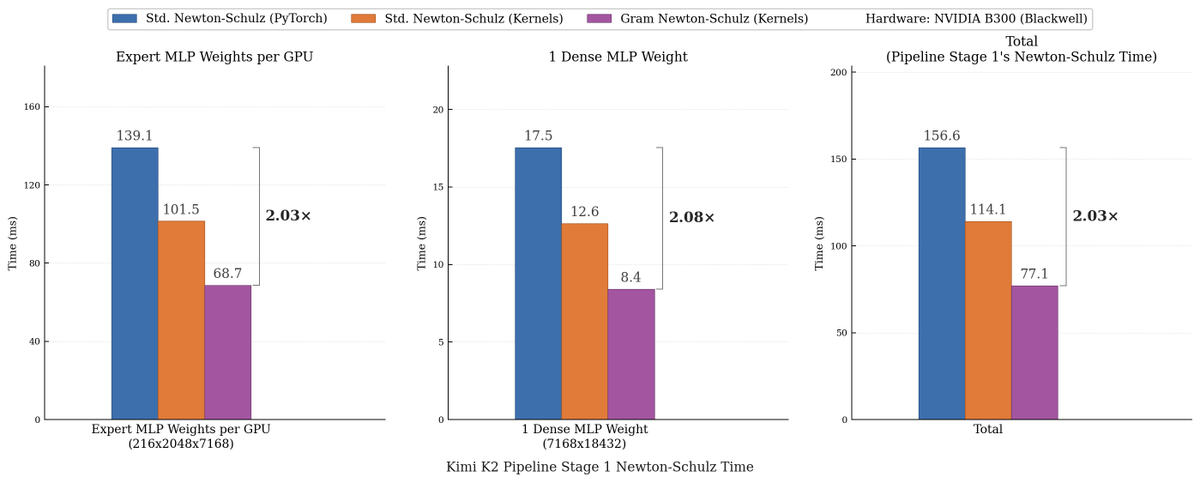
We made Muon run up to 2x faster for free!
Introducing Gram Newton-Schulz: a mathematically equivalent but computationally faster Newton-Schulz algorithm for polar decomposition.
Gram Newton-Schulz rewrites Newton-Schulz such that instead of iterating on the expensive rectangular X matrix, we iterate on the small, square, symmetric XX^T Gram matrix to reduce FLOPs. This allows us to make more use of fast symmetric GEMM kernels on Hopper and Blackwell, halving the FLOPs of each of those GEMMs.
Gram Newton-Schulz is a drop-in replacement of Newton-Schulz for your Muon use case: we see validation perplexity preserved within 0.01, and share our (long!) journey stabilizing this algorithm and ensuring that training quality is preserved above all else.
This was a super fun project with @noahamsel, @berlinchen, and @tri_dao that spanned theory, numerical analysis, and ML systems! Blog and codebase linked below 🧵
17
164
1,036
218,154
Wentao Guo retweeted

Mar 19
Introducing M²RNN: Non-Linear RNNs with Matrix-Valued States for Scalable Language Modeling
We bring back non-linear recurrence to language modeling and show it's been held back by small state sizes, not by non-linearity itself.
📄 Paper: arxiv.org/abs/2603.14360
💻 Code: github.com/open-lm-engine/lm…
🤗 Models: huggingface.co/collections/o…
10
109
515
147,709
Wentao Guo retweeted

Mar 17
The newest model in the Mamba series is finally here 🐍
Hybrid models have become increasingly popular, raising the importance of designing the next generation of linear models.
We've introduced several SSM-centric ideas to significantly increase Mamba-2's modeling capabilities without compromising on speed. The resulting Mamba-3 model has noticeable performance gains over the most popular previous linear models (such as Mamba-2 and Gated DeltaNet) at all sizes.
This is the first Mamba that was student led: all credit to @aakash_lahoti @kevinyli_ @_berlinchen @caitWW9, and of course @tri_dao!
41
310
1,596
447,057
Wentao Guo retweeted
Mar 5
FA4 now available in lm-engine: github.com/open-lm-engine/lm…
13.4% end-to-end speedup for Llama 8B training on 4x GB200s (1 node) 🚀🚀🚀
1005.55 TFLOPs for SDPA vs 1140.73 for FA4 (BF16 precision)
@tedzadouri @ultraproduct @__tensorcore__ @tri_dao cooked
Thanks to @bharatrunwal2 for running the experiment!
2
11
60
6,334
Wentao Guo retweeted

Mar 5
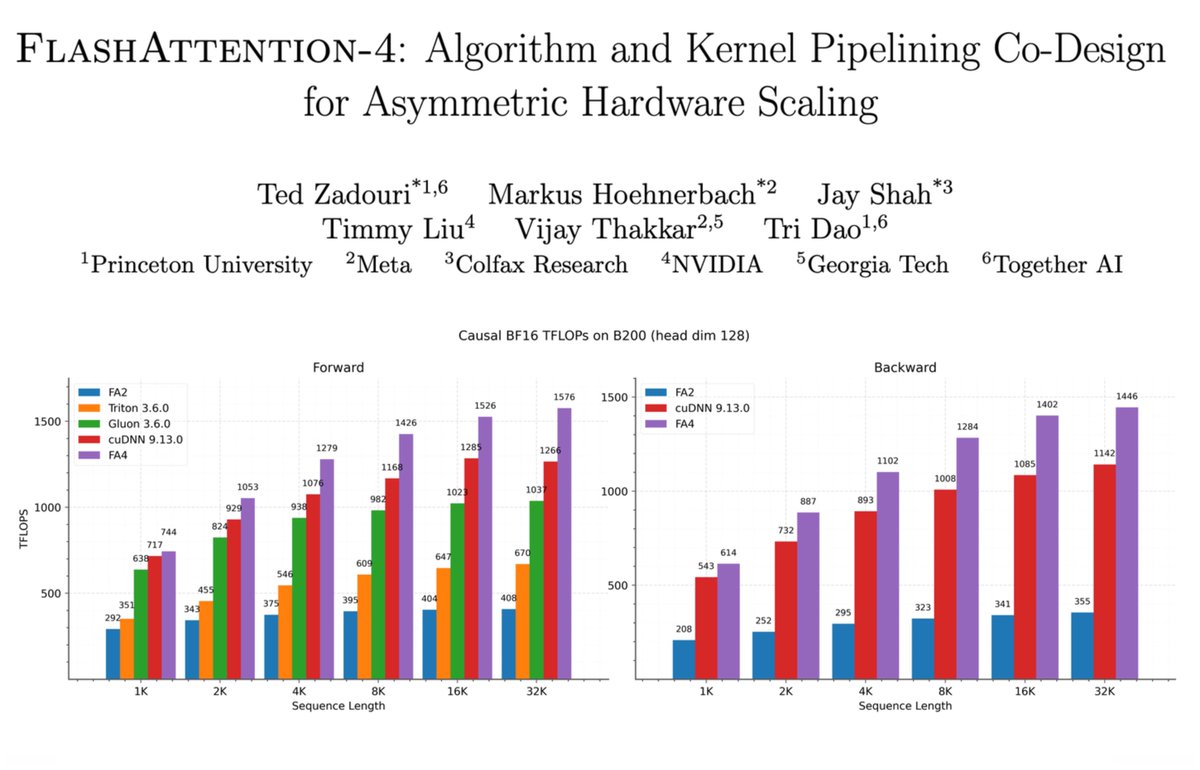
Asymmetric hardware scaling is here. Blackwell tensor cores are now so fast, exp2 and shared memory are the wall. FlashAttention-4 changes the algorithm & pipeline so that softmax & SMEM bandwidth no longer dictate speed. Attn reaches ~1600 TFLOPs, pretty much at matmul speed!
joint work w/ Markus Hoehnerbach, Jay Shah(@ultraproduct), Timmy Liu, Vijay Thakkar (@__tensorcore__ ), Tri Dao (@tri_dao)
1/
7
130
782
230,063
Wentao Guo retweeted
Feb 25
We identified an issue with the Mamba-2 🐍 initialization in HuggingFace and FlashLinearAttention repository (dt_bias being incorrectly initialized).
This bug is related to 2 main issues:
1. init being incorrect (torch.ones) if Mamba-2 layers are used in isolation without the Mamba2ForCausalLM model class (this has been already fixed: github.com/fla-org/flash-lin…).
2. Skipping initialization due to meta device init for DTensors with FSDP-2 (github.com/fla-org/flash-lin… will fix this issue upon merging).
The difference is substantial. Mamba-2 seems to be quite sensitive to the initialization.
Check out our experiments at the 7B MoE scale: wandb.ai/mayank31398/mamba-t…
Special thanks to @kevinyli_, @bharatrunwal2, @HanGuo97, @tri_dao and @_albertgu 🙏
Also thanks to @SonglinYang4 for quickly helping in merging the PR.
17
73
742
371,648
Wentao Guo retweeted

Feb 12
Gave a talk at @GoogleDeepMind on our joint work with @HazanPrinceton and @tri_dao on deployable RL policies for robotics. Great discussion with @JeffDean.

10
20
169
22,989
Wentao Guo retweeted

Jan 22
Today, we're proud to announce @inferact, a startup founded by creators and core maintainers of @vllm_project, the most popular open-source LLM inference engine.
Our mission is to grow vLLM as the world's AI inference engine and accelerate AI progress by making inference cheaper and faster.
The Challenge
Inference is not solved. It's getting harder.
Models grow larger. New architectures proliferate: mixture-of-experts, multimodal, agentic. Every breakthrough demands new infrastructure. Meanwhile, hardware fragments: more accelerators, more programming models, and more combinations to optimize.
The capability gap between models and the systems that serve them is widening. Left this way, the most capable models remain bottlenecked and with full scope of their capabilities accessible only to those who can build custom infrastructure. Close the gap, and we unlock new possibilities.
And the problem is growing. Inference is shifting from a fraction of compute to the majority: test-time compute, RL training loops, synthetic data.
We see a future where serving AI becomes effortless.
Today, deploying a frontier model at scale requires a dedicated infrastructure team. Tomorrow, it should be as simple as spinning up a serverless database. The complexity doesn't disappear; it gets absorbed into the infrastructure we're building.
Why Us
vLLM sits at the intersection of models and hardware: a position that took years to build.
When model vendors ship new architectures, they work with us to ensure day-zero support. When hardware vendors develop new silicon, they integrate with vLLM. When teams deploy at scale, they run vLLM, from frontier labs to hyperscalers to startups serving millions of users. Today, vLLM supports 500 model architectures, runs on 200 accelerator types, and powers inference at global scale. This ecosystem, built with 2,000 contributors, is our foundation.
We've been stewards of this engine since its first commit. We know it inside out. We deployed it at frontier scale—in research and in production.
Open Source
vLLM was built in the open. That's not changing.
Inferact exists to supercharge vLLM adoption. The optimizations we develop flow back to the community. We plan to push vLLM's performance further, deepen support for emerging model architectures, and expand coverage across frontier hardware. The AI industry needs inference infrastructure that isn't locked behind proprietary walls.
Join Us
Through the open source community, we are fortunate to work with some of the best people we know. For @inferact, we're hiring engineers and researchers to work at the frontier of inference, where models meet hardware at scale. Come build with us.
We're fortunate to be supported by investors who share our vision, including @a16z and @lightspeedvp who led our $150M seed, as well as @sequoia, @AltimeterCap, @Redpoint, @ZhenFund, The House Fund, @strikervp, @LaudeVentures, and @databricks.
- @woosuk_k, @simon_mo_, @KaichaoYou, @rogerw0108, @istoica05 and the rest of the founding team
181
129
1,153
482,887
18 Dec 2025
🚀SonicMoE🚀: a blazingly-fast MoE implementation optimized for NVIDIA Hopper GPUs. SonicMoE reduces activation memory by 45% and is 1.86x faster on H100 than previous SOTA😃
Paper: arxiv.org/abs/2512.14080
Work with @MayankMish98, @XinleC295, @istoica05, @tri_dao
24
112
639
247,971
18 Dec 2025
Many thanks to NVIDIA cutlass team @nvidia, PLI @PrincetonPLI, SkyLab @BerkeleySky and Together AI @togethercompute
1
15
1,748
18 Dec 2025
[5/N]
The token rounding routing eliminates padding waste in grouped GEMM and can achieve 16% relative speedup over TC top-K on kernel computation time while delivering robust token-choice accuracy even under highly sparse MoE training regimes.
2
19
1,878