
Moved to 🦋! Explainable/Interpretable AI researchers and enthusiasts - DM to join the XAI Slack! Twitter and Slack maintained by @NickKroeger1
Joined March 2022
- Tweets 1,191
- Following 772
- Followers 2,220
- Likes 615
14 Photos and videos

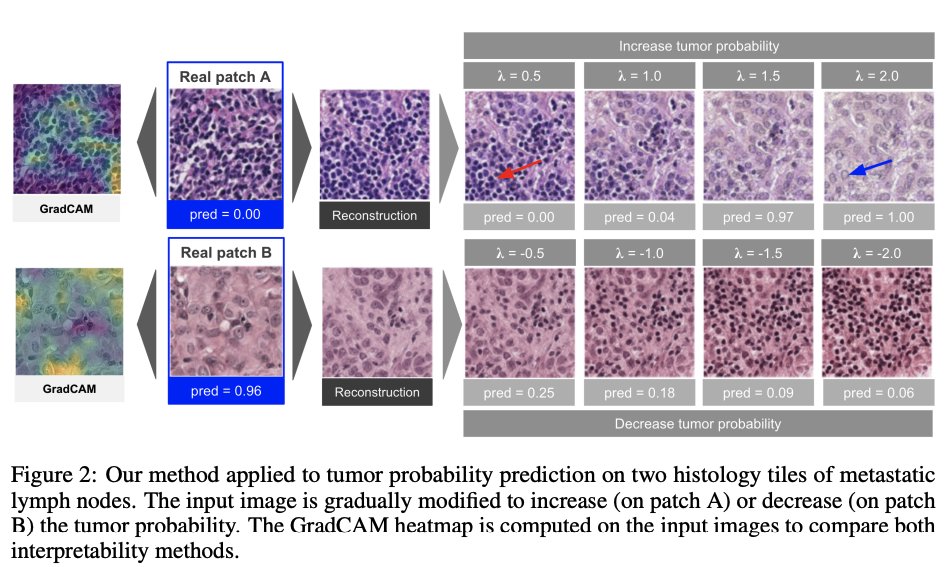





Pinned Tweet

28 Mar 2022
There's a new XAI Slack!
Connect with XAI/IML researchers and enthusiasts from around the world. Discuss interpretability methods, get help on challenging problems, and meet experts in your field! DM to join 🥳
22
10
50
Explainable AI retweeted

4 Feb 2025
Our Theory of Interpretable AI (tverven.github.io/tiai-semin…) will soon celebrate its one-year anniversary! 🥳
As we step into our second year, we’d love to hear from you! What papers would you like to see discussed in our seminar in the future? 📚🔍
@tverven @ML_Theorist
1
4
17
1,853
Explainable AI retweeted

4 Feb 2025
🚨 Excited to share: "Learning to Generate Unit Tests for Automated Debugging" 🚨
which introduces ✨UTGen and UTDebug✨ for teaching LLMs to generate unit tests (UTs) and debugging code from generated tests.
UTGen UTDebug improve LLM-based code debugging by addressing 3 key questions:
1⃣ What are desirable properties of unit test generators? (A: high output acc and rate of uncovering errors)
2⃣ How good are models at 0-shot unit test generation (A: they are not great) ... so how do we improve LLMs' UT generation abilities? (A: bootstrapping from code-generation data via UTGen)
3⃣ How can we use potentially noisy feedback from generated tests for debugging? (A: via test-time scaling and validation backtracking in UTDebug)
🧵👇

4
58
169
47,971
Explainable AI retweeted

4 Feb 2025
Super excited to share our latest preprint that unifies multiple areas within explainable AI that have been evolving somewhat independently:
1. Feature Attribution
2. Data Attribution
3. Model Component Attribution (aka Mechanistic Interpretability)
arxiv.org/abs/2501.18887 [1/N]
#AI #Safety #Interpretability #XAI #explainableAI

2
17
137
17,132
Explainable AI retweeted
24 Jan 2025
Reminder we have moved to 🦋
Stay up to date with the latest XAI research!
1
1
11
909
Explainable AI retweeted

29 Jan 2025
Hot off the press: my PhD thesis "Foundations of machine learning interpretability" is officially published! Enjoy it at theses.hal.science/tel-04917…
@XAI_Research @trustworthy_ml
1
3
17
1,248
Explainable AI retweeted
21 Jan 2025
We have moved to 🦋 bluesky! Please follow over there @ XAI-Research
bsky.app/profile/xai-researc…
2
3
660
Explainable AI retweeted

22 Jan 2025
Exciting opportunity at the intersection of climate science and XAI to work on groundbreaking research in attributing extreme precipitation events with multimodal models. Check out the details and help spread the word! #ClimateAI #Postdoc #UVA #Hiring
Job description: shorturl.at/uP5fq
Tagging @XAI_Research @trustworthy_ml @uvadatascience @ClimateChangeAI to spread the word!
22 Jan 2025

Dear Climate and AI community!
We are hiring 😀 a postdoc to join @UVAEnvironment at @UVA and work with @_cagarwal and myself, on using multimodal AI models and explainable AI to attribute extreme precipitation events! Fascinating stuff!
Link below. Please RT!
jobs.virginia.edu/us/en/job/…
7
17
4,665
Explainable AI retweeted

🔍 Curious about what's really happening inside vision models?
Join us at the First Workshop on Mechanistic Interpretability for Vision (MIV) at @CVPR!
📢 Website: sites.google.com/view/miv-cv…
Meet our amazing invited speakers!
#CVPR2025 #MIV25 #MechInterp #ComputerVision

14
58
24,645
Explainable AI retweeted

17 Jan 2025
The later features in DINO-v2 are more abstract and semantically meaningful than I'd expected from the training objectives.
This neuron responds only to hugs. Nothing else, just hugs.
9
64
554
34,378
Explainable AI retweeted

17 Jan 2025
This week's Apart News brings you an *exclusive* interview with interpretability insider @myra_deng of @GoodfireAI & revisits our Sparse Autoencoders Hackathon which featured a memorable talk from @GoogleDeepMind's @NeelNanda5.

1
4
18
962
Explainable AI retweeted

16 Jan 2025
Hi Dylan, it reminds me of our paper where we also train a model (model 2) on the output of another black-box model (model 1). ultimately we find that combining the outputs of model 2 and model 1 helps improve the perf significantly.
openreview.net/forum?id=OcFj…
1
3
265
Explainable AI retweeted

16 Jan 2025
In case you missed it: here is the recording of @YishayMansour's talk about the ability of decision trees to approximate concepts: youtu.be/uOwuho2er58
For upcoming talks, check out the seminar website: tverven.github.io/tiai-semin…


3
16
1,825
Explainable AI retweeted

15 Jan 2025
LLMs are all circuits and patterns
Nice Paper for a long weekend read - "A Primer on the Inner Workings of Transformer-based Language Models"
📌 Provides a concise intro focusing on the generative decoder-only architecture.
📌 Introduces the Transformer layer components, including the attention block (QK and OV circuits) and feedforward network block, and explains the residual stream perspective. It then categorizes LM interpretability approaches into two dimensions: localizing inputs or model components responsible for a prediction (behavior localization) and decoding information stored in learned representations to understand its usage across network components (information decoding).
📌 For behavior localization, the paper covers input attribution methods (gradient-based, perturbation-based, context mixing) and model component importance techniques (logit attribution, causal interventions, circuits analysis). Causal interventions involve patching activations during the forward pass to estimate component influence, while circuits analysis aims to reverse-engineer neural networks into human-understandable algorithms by uncovering subsets of model components interacting together to solve a task.
📌 Information decoding methods aim to understand what features are represented in the network. Probing trains supervised models to predict input properties from representations, while the linear representation hypothesis states that features are encoded as linear subspaces. Sparse autoencoders (SAEs) can disentangle superimposed features by learning overcomplete feature bases. Decoding in vocabulary space involves projecting intermediate representations and model weights using the unembedding matrix.
📌 Then summarizes discovered inner behaviors in Transformers, including interpretable attention patterns (positional, subword joiner, syntactic heads) and circuits (copying, induction, copy suppression, successor heads), neuron input/output behaviors (concept-specific, language-specific neurons), and the high-level structure mirroring sensory/motor neurons. Emergent multi-component behaviors are exemplified by the IOI task circuit in GPT2-Small. Insights on factuality and hallucinations highlight the competition between grounded and memorized recall mechanisms.

4
48
265
16,477
Explainable AI retweeted

13 Jan 2025
Follow us for AI safety insights
x.com/intent/follow?screen_n…
And watch the full video youtu.be/nqZ6EiPltSo&list=PL…
5
17
7,699
Explainable AI retweeted

13 Jan 2025
This Thursday (in 3 days), @YishayMansour will discuss interpretable approximations — learning with interpretable models. Is it the same as regular learning? Attend the lecture to find out!
💻 Website: tverven.github.io/tiai-semin…
@Suuraj @tverven
6 Jan 2025
The theory of interpretable AI seminar is back after the holiday season! 🎅🤶
Our next talk is next Thursday by Yishay Mansour who will talk about interpretable approximations
💻 Website: tverven.github.io/tiai-semin…
⏰Date: 16 Jan
@Suuraj @tverven @YishayMansour

3
17
1,196
Explainable AI retweeted

10 Jan 2025
We're open-sourcing Sparse Autoencoders (SAEs) for Llama 3.3 70B and Llama 3.1 8B! These are, to the best of our knowledge, the first open-source SAEs for models at this scale and capability level.

11
118
707
113,413
Explainable AI retweeted

10 Jan 2025
What can AI researchers do *today* that AI developers will find useful for ensuring the safety of future advanced AI systems? To ring in the new year, the Anthropic Alignment Science team is sharing some thoughts on research directions we think are important.

9
63
324
107,507
Explainable AI retweeted

10 Aug 2024
ACL Time @ Bangkok 🇹🇭
Our GNNavi work will be presented in the poster session at 12:30 on Aug. 14 (Wed.). Welcome to drop by and exchange with us!
Looking forward to talking with people, especially those who are interested in multilingual & low-resource & LLM interpretability🤗


7
28
2,486