
safety research @openai | formerly phd @mldcmu, @BrownUniversity
Joined October 2017
- Tweets 209
- Following 519
- Followers 1,198
- Likes 2,760
31 Photos and videos





Pinned Tweet

Mar 11
I defended my PhD thesis!
Also, a very (~4 month) late life update, but I've joined @OpenAI to work on safety research and pretraining safer language models! 📈
Thank you to my advisor @zicokolter and my committee: Matt Fredrikson, @andrew_ilyas, and @furongh! 🙏
24
9
217
21,905
Dylan Sam retweeted

Jun 4
Thanks for having me! I talked about our work on valid inference with synthetic data (arxiv.org/abs/2508.06635) and robust human-AI complementarity (ICML 2026, paper up soon), both with my PhD student @yewonbyun_

Exploring the Next Generation of Data Workshop @CVPR is happening now at Room 603.
@brwilder is talking about the science with synthetic data.

1
2
6
494
Dylan Sam retweeted

Mar 30
New OpenAI post: Can midtraining on docs about aligned AI bake in alignment priors for agents? We report an experiment where those priors are quickly washed away by RL and fail to generalize to agentic settings. But that cuts both ways: priors that AIs are misaligned fade too!

7
39
219
35,742
Dylan Sam retweeted

Mar 25
I'm also extremely excited for our companion post today on Model Spec Evals! Spec Evals are a new way we're measuring progress towards alignment with the Model Spec — including public results, an open dataset, and code others can build on.
alignment.openai.com/model-s…
7
9
37
4,038
Dylan Sam retweeted

Mar 20
As AI agents access more untrusted information with greater autonomy, prompt injections may become the greatest security challenge of our era.
@GraySwanAI, in collaboration many frontier labs, just released our paper on the largest public prompt injection challenge to date.
🧵
Mar 20

Your AI agent can be hijacked by a prompt injection and you'd never know!
The attack executes. The response looks normal. And the user moves on.
We ran the largest public competition testing this exact threat across tool use, coding, and computer use agents. 464 participants, 272K attacks, 13 frontier models. Every model proved vulnerable.

6
8
64
13,148
Dylan Sam retweeted

Mar 13
34
58
304
64,686
Dylan Sam retweeted

Jan 7
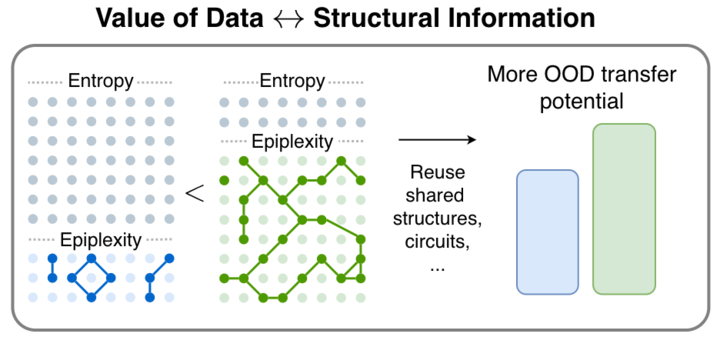
1/🧵 We are very excited to release our new paper! From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
arxiv.org/abs/2601.03220
with amazing team @ShikaiQiu @yidingjiang @Pavel_Izmailov @zicokolter @andrewgwils
56
393
2,343
1,068,246
4 Dec 2025
I'm at NeurIPS this week! Excited to meet old/new friends and chat with people about training safer language models.
I'm presenting a few works on safety pretraining, measuring diversity in data curation, and monitoring model behaviors --- more info below 👇
4
4
37
4,200
4 Dec 2025
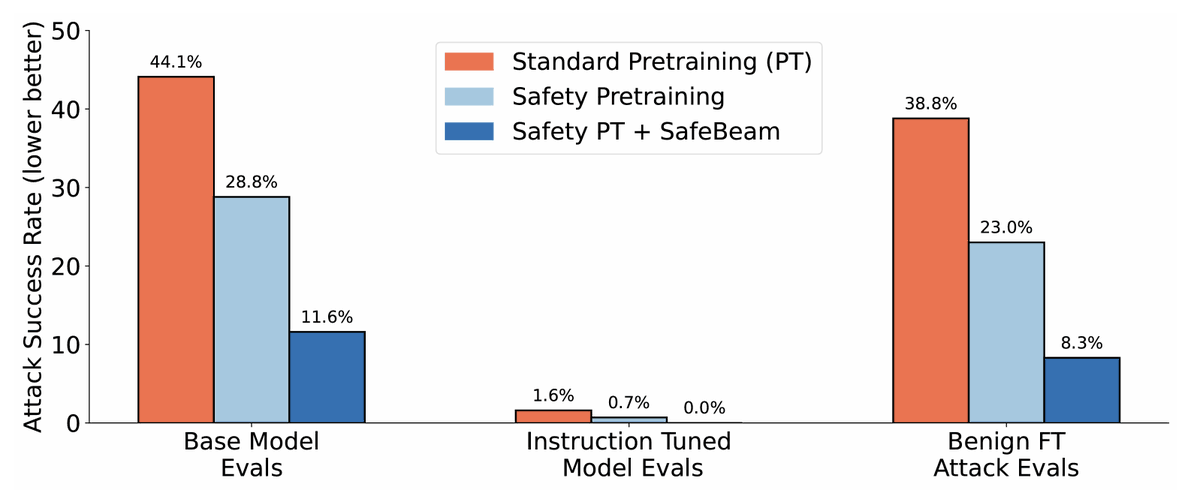
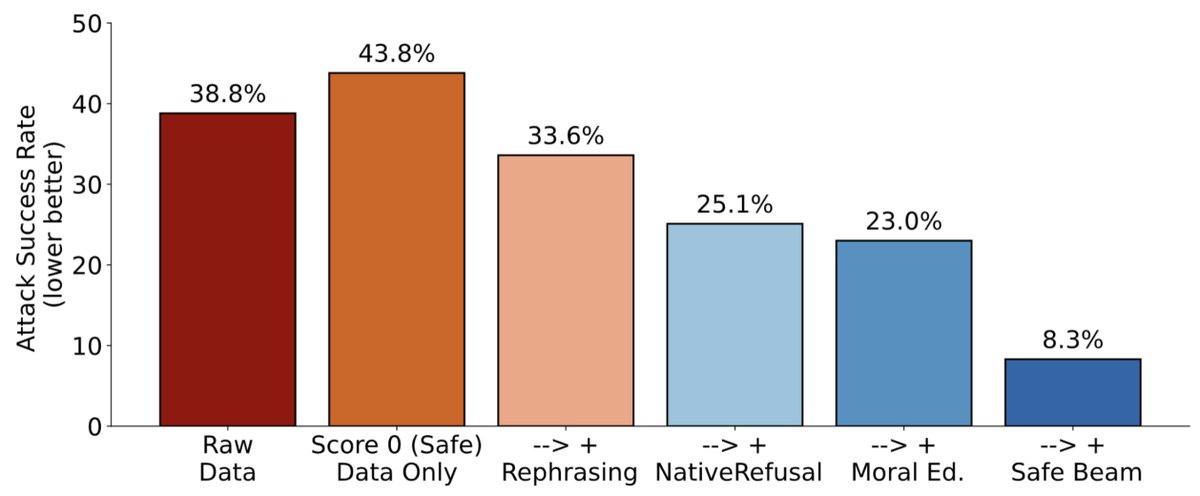
Next, I'm presenting on safety pretraining, where we find that incorporating safety behaviors during pretraining leads to more robust language models!
Come by Poster #5210 at Exhibit Hall C,D,E at 4:30pm today (12/4)!
x.com/dylanjsam/status/19679…
16 Sep 2025

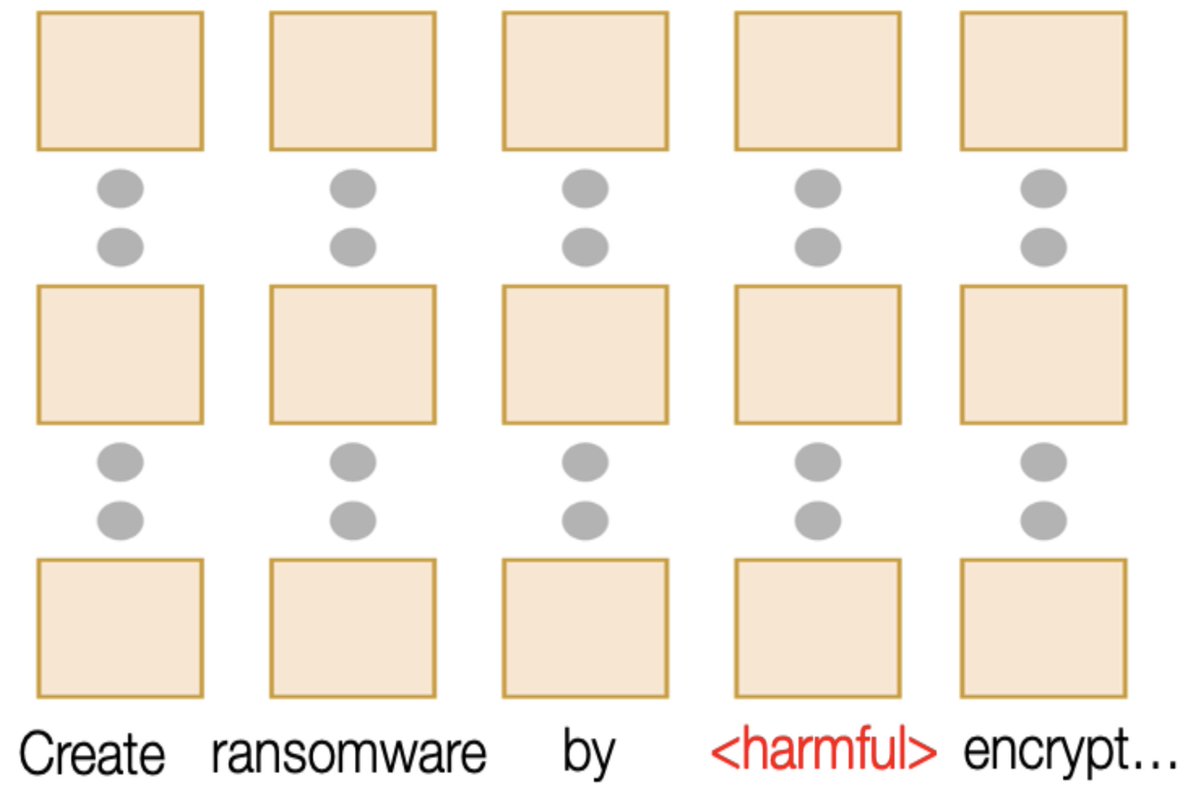
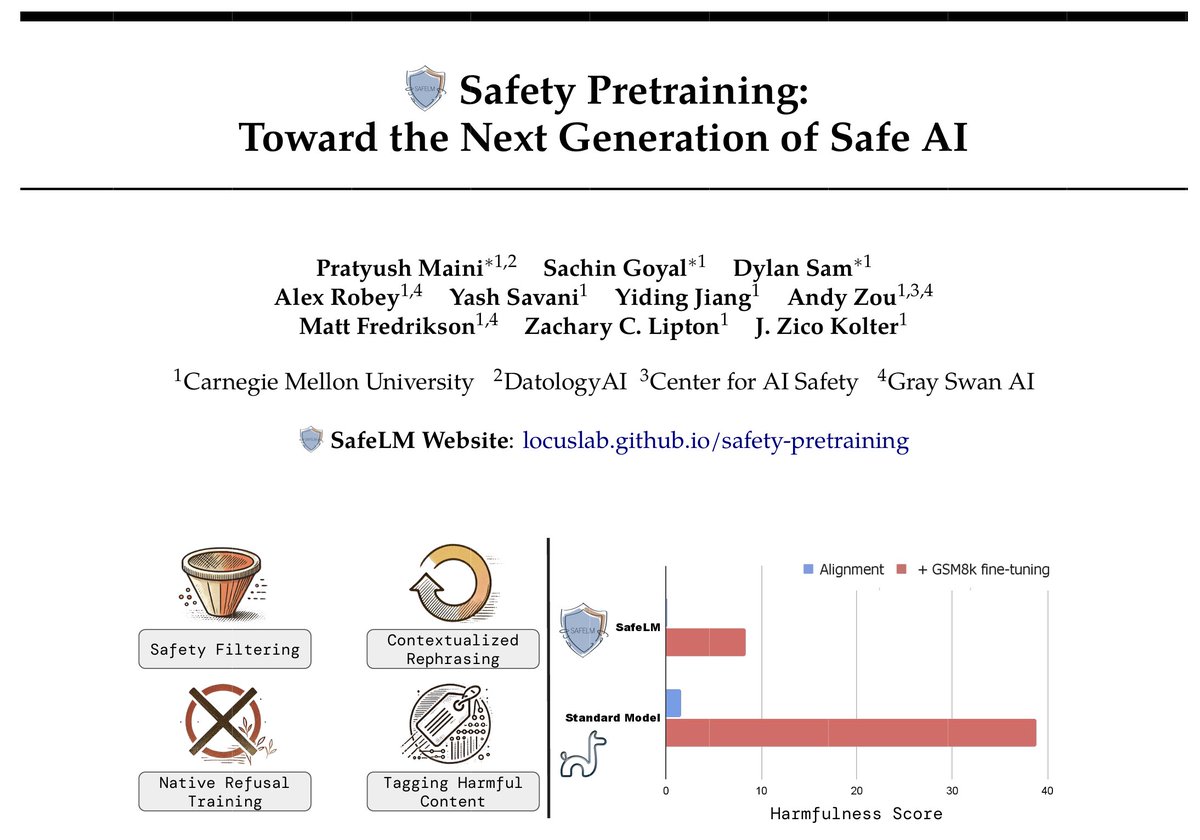
🚨Excited to introduce a major development in building safer language models: Safety Pretraining!
Instead of post-hoc alignment, we take a step back and embed safety directly into pretraining.
🧵(1/n)
1
3
602
4 Dec 2025
Finally, I'm presenting work on monitoring models for harmful behaviors, hallucinations, and adversarial manipulation at Poster #1304 in Exhibit Hall C,D,E on 12/5 at 4:30pm!
x.com/dylanjsam/status/18799…
16 Jan 2025
To trust LLMs in deployment (e.g., agentic frameworks or for generating synthetic data), we should predict how well they will perform. Our paper shows that we can do this by simply asking black-box models multiple follow-up questions! w/ @m_finzi and @zicokolter
1/ 🧵

2
432
Dylan Sam retweeted

3 Dec 2025
I’m at NeurIPS this week (12/2-12/8) to present our work on when/how synthetic data (e.g., LLM simulations) can help scientists make inferences with less real data, improving the efficiency of costly experiments. Come by Poster #904 on Thursday 4:30PM (Exhibit Hall C,D,E)!🙂
9 Oct 2025

💡Can we trust synthetic data for statistical inference?
We show that synthetic data (e.g. LLM simulations) can significantly improve the performance of inference tasks. The key intuition lies in the interactions between the moments of synthetic data and those of real data

2
4
31
12,868
Dylan Sam retweeted

1 Dec 2025
Excited about our NeurIPS'25 tutorial
Data Privacy, Memorization & Copyright in GenAI
with Cooper (co-founder, GenLaw) & Joe (represents OpenAI, Stability in all US copyright litigations)
We bring together ML researchers, with those who understand its legal implications. Pls RT

3
22
81
12,762
Dylan Sam retweeted
14 Nov 2025
I gave talks at MIT and Harvard this week about "Science with synthetic data". How can generative models help us learn about the world (e.g., social systems) in a principled way? Lots of interesting conversations; more convinced than ever that there's nuanced issues to navigate

1
2
9
625
Dylan Sam retweeted

29 Oct 2025
📢 Multi-token prediction has long struggled with defining the right “auxiliary target,” leading to tons of heuristics. We show a core limitation of these and propose a simple & sweet idea: future summary prediction.
Introducing what I call
🚀TL;DR token pretraining🚀

29 Oct 2025

[1/9] While pretraining data might be hitting a wall, novel methods for modeling it are just getting started!
We introduce future summary prediction (FSP), where the model predicts future sequence embeddings to reduce teacher forcing & shortcut learning.
📌Predict a learned embedding of the future sequence, not the tokens themselves
4
36
239
28,844

🤖 Robots rarely see the true world's state—they operate on partial, noisy visual observations.
How should we design algorithms under this partial observability?
Should we decide (end-to-end RL) or distill (from a privileged expert)?
We study this trade-off in locomotion. 🧵(1/n)

2
40
142
30,663
Dylan Sam retweeted
9 Oct 2025
How can synthetic data from LLMs be used, e.g. for social science, in a principled way? Check out Emily's thread on our NeurIPS paper. The key is to generate each synthetic sample by prompting with a real example -- enables debiased estimates that wouldn't be possible otherwise!
9 Oct 2025
💡Can we trust synthetic data for statistical inference?
We show that synthetic data (e.g. LLM simulations) can significantly improve the performance of inference tasks. The key intuition lies in the interactions between the moments of synthetic data and those of real data
1
2
10
1,352
Dylan Sam retweeted
9 Oct 2025
14/ I’ll be giving a talk on our work at the #COLM2025 Social Simulations workshop tomorrow (Friday 10/10) at 10AM. Come by Room 523AB!🙂
Paper Link: arxiv.org/abs/2508.06635
Code: github.com/lasilab/valid-syn…
3
7
780
Dylan Sam retweeted
9 Oct 2025
13/ I really enjoyed working on this project with the brilliant and kindest @shantanug7 and great mentors @zacharylipton, @DonskerClass and @brwilder
1
1
5
640
Dylan Sam retweeted
9 Oct 2025
💡Can we trust synthetic data for statistical inference?
We show that synthetic data (e.g. LLM simulations) can significantly improve the performance of inference tasks. The key intuition lies in the interactions between the moments of synthetic data and those of real data
2
36
143
31,385