
Research Scientist @Salesforce AI Research, Ph.D. from @SCSatCMU
Joined January 2021
- Tweets 32
- Following 185
- Followers 73
- Likes 59
Photos and videos
Jielin Qiu retweeted

26 Nov 2025
Today I finally get to share something our team has been quietly grinding on for months – we've created an 𝗼𝗽𝗲𝗻 𝘀𝗼𝘂𝗿𝗰𝗲𝗱 𝘃𝗲𝗿𝘀𝗶𝗼𝗻 𝗼𝗳 Cursor 𝗕𝗲𝗻𝗰𝗵 @cursor_ai .
If you’ve been following Cursor’s Composer launch and their internal "Cursor Bench" for testing vibe coding models, you can think of our 𝗟𝗖𝗕𝗔 𝗯𝗲𝗻𝗰𝗵 as the open-source, model-agnostic counterpart.
Here is what we provide by @SFResearch . With 𝗟𝗖𝗕𝗔 𝗯𝗲𝗻𝗰𝗵 we:
• Ship a 𝗖𝘂𝗿𝘀𝗼𝗿-𝘀𝘁𝘆𝗹𝗲 𝗮𝗴𝗲𝗻𝘁 𝘀𝘁𝗮𝗰𝗸: ReAct loop, semantic @ codebase search, grep, file read/write, refactor tools, and a three-tier memory system inspired by production coding assistants like Cursor.
• 𝗧𝗮𝗸𝗲 𝟴,𝟬𝟬𝟬 𝗿𝗲𝗮𝗹-𝘄𝗼𝗿𝗹𝗱 𝘃𝗶𝗯𝗲 𝗰𝗼𝗱𝗶𝗻𝗴 𝘀𝗰𝗲𝗻𝗮𝗿𝗶𝗼𝘀 and turn them into interactive agent gyms across 10 languages and 10K–1M token codebases.
• Let you plug in any model (GPT-5, Claude Sonnet 4.5, Gemini 2.5 Pro, etc.) and see how it actually behaves on long, messy, multi-turn coding tasks.
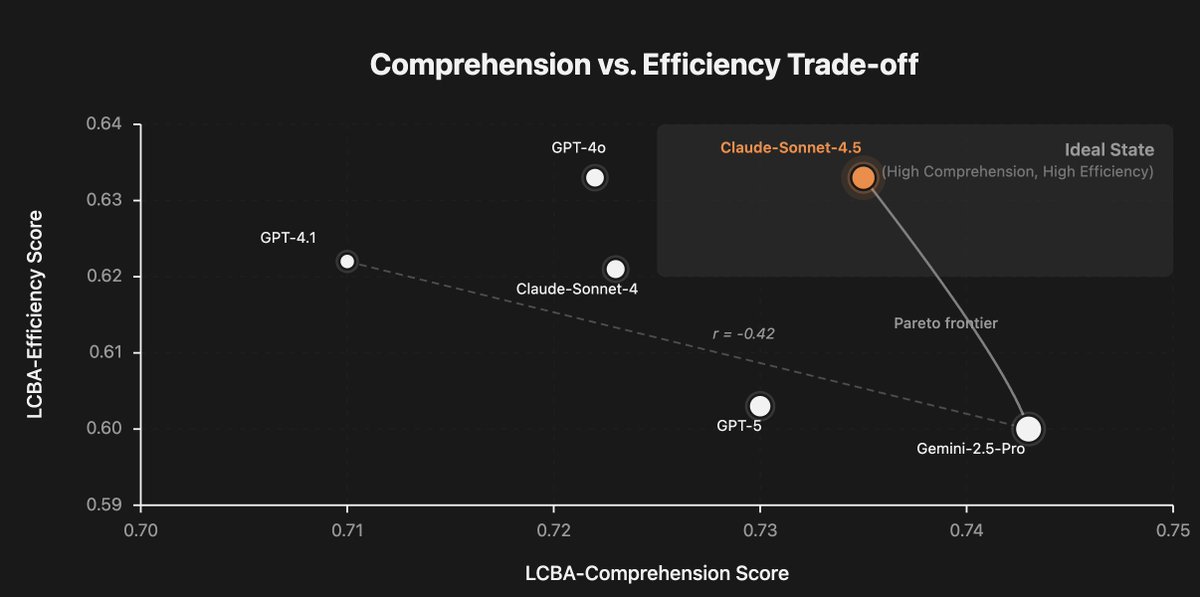
A few fun findings: Cursor-style agents with context management are surprisingly robust at 1M-token contexts, but there’s a hard trade-off between deep exploration vs. efficiency — no one frontier model sits in the “perfect” top-right corner yet. Anthropic Claude 4.5 and Google Gemini 2.5 pro are at the Pareto Frontier.
Everything is open source (agent, code, scenarios, traces, metrics) on @huggingface:
📄 Tech Report: arxiv.org/pdf/2509.09614
🤖 GitHub:github.com/SalesforceAIResea…
🤗 Dataset: huggingface.co/datasets/jaso…
If you’re building coding agents, benchmarking your model against GPT/Claude/Gemini, or want to train your coding agents with RL in real coding environments, we’d love for you to try LCBA bench, and tell us your findings!
2
6
7
544
Jielin Qiu retweeted

19 Nov 2025
🚨 Introducing LoCoBench-Agent: a comprehensive benchmark for evaluating LLM agents in long-context software engineering
📄 Paper: bit.ly/49mPrBv
🔗 GitHub: bit.ly/3KbpkTN
✨ Key Features:
🤖 8,000 interactive agent scenarios with multi-turn conversations (up to 50 turns)
🔍 Context lengths: 10K-1M tokens across 10 programming languages
⚡ 9 bias-free evaluation metrics (5 comprehension 4 efficiency)
🛠️ 8 specialized development tools: file operations, semantic search, grep, code analysis
🎯 8 task categories: architectural understanding, cross-file refactoring, multi-session development, bug investigation, feature implementation, code comprehension, integration testing, and security analysis
🔬 Key Findings:
- Fundamental comprehension-efficiency trade-off
- Tool usage patterns matter more than raw capabilities
- Strategic exploration > exhaustive exploration
LoCoBench-Agent assesses agent behavior across extended development sessions, measuring context retention, adaptive strategy refinement, and tool usage efficiency.
Authors: Jielin Qiu @Jason_Q, Zuxin Liu @LiuZuxin, Zhiwei Liu @JYJimLiu, Rithesh Murthy @rithesh__rn, Jianguo Zhang @JianguoZhang3, Haolin Chen @HaolinChen11, Shiyu Wang @shiyu04490786, Ming Zhu@ming_zhu0527, Liangwei Yang @Liangwei_Yang, Juntao Tan @chrisjtan, Roshan Ram @shoonyaka1, Akshara Prabhakar @aksh_555, Tulika Awalgaonkar @tulika614, Zixiang Chen @_zxchen_, Zhepeng Cen @ZhepengCen, Cheng Qian @qiancheng1231, Shelby Heinecke @shelbyh_ai, Weiran Yao @iscreamnearby, Silvio Savarese @silviocinguetta, Caiming Xiong @CaimingXiong, Huan Wang @huan__wang
#LLM #AIAgents #SoftwareEngineering #MachineLearning #Benchmark #FutureOfAI #EnterpriseAI

4
3
13
2,410
Jielin Qiu retweeted
15 Sep 2025
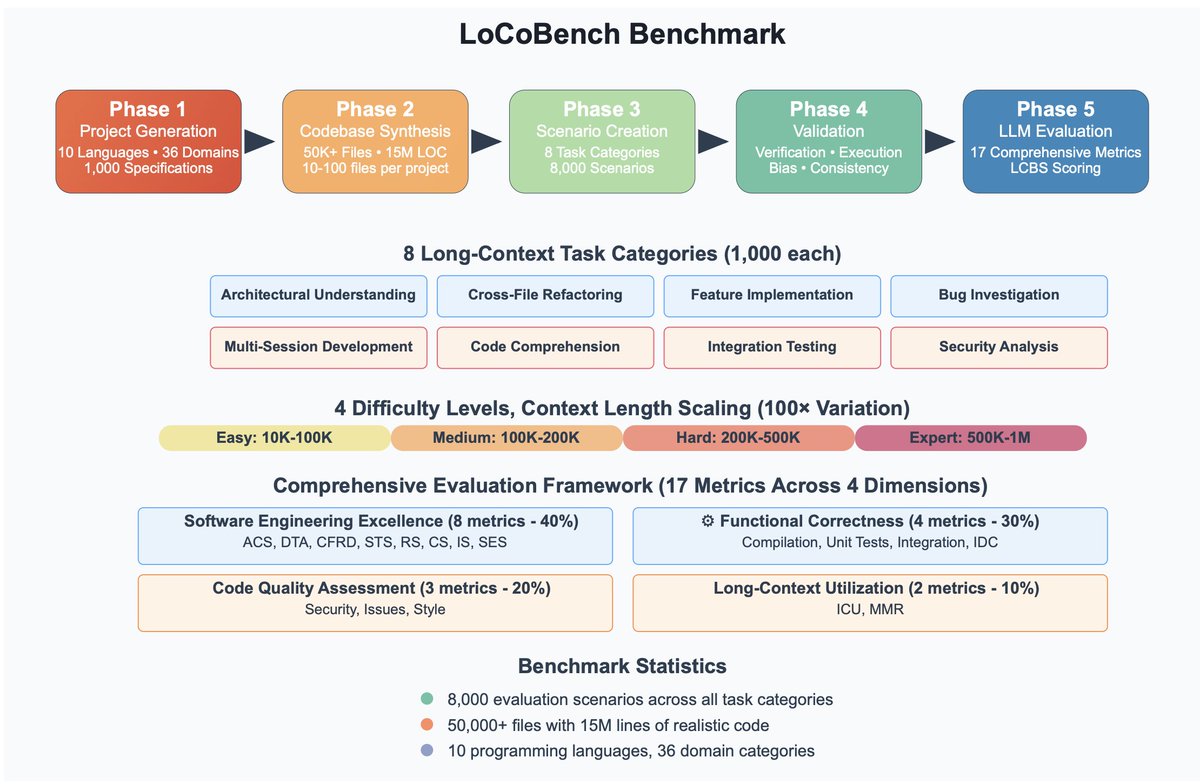
🚨 Introducing LoCoBench: a comprehensive benchmark for evaluating long-context LLMs in complex software development
📄 Paper: bit.ly/4ponX3P
🔗 GitHub: bit.ly/4pvIfbZ
✨ Key Features:
📊 8,000 evaluation scenarios across 10 programming languages
🔍 Context lengths: 10K-1M tokens (100× variation!)
⚡ 17 evaluation metrics across 4 dimensions (6 newly proposed)
🎯 8 essential task categories: architectural understanding, cross-file refactoring, multi-session development, bug investigation, feature implementation, code comprehension, integration testing, and security analysis
Current SOTA models show dramatic performance drops as context increases - highlighting critical gaps in long-context understanding for real-world software engineering.
Authors: Jielin Qiu @_Jason_Q, Zuxin Liu @LiuZuxin, Zhiwei Liu @JYJimLiu, Rithesh Murthy @rithesh__rn, Jianguo Zhang @JianguoZhang3, Haolin Chen @HaolinChen11, Shiyu Wang @shiyu04490786, Ming Zhu@ming_zhu0527, Liangwei Yang @Liangwei_Yang, Juntao Tan @chrisjtan, Zhepeng Cen @ZhepengCen, Cheng Qian @qiancheng1231, Shelby Heinecke @shelbyh_ai, Weiran Yao @iscreamnearby, Silvio Savarese @silviocinguetta, Caiming Xiong @CaimingXiong, Huan Wang @huan__wang
#LLM #SoftwareEngineering #MachineLearning #Benchmark #FutureOfAI #EnterpriseAI
13
19
2,290

Excited to see the first paper getting accepted at @DMLRJournal. In the last few months, we are fascinated by the quality of reviews and the engaging interactions between authors and reviewers! Thanks everyone! Please continue to send your best work about Data x ML😀

'Benchmarking Robustness of Multimodal Image-Text Models under Distribution Shift'
by Jielin Qiu, Yi Zhu, Xingjian Shi, Florian Wenzel, Zhiqiang Tang, Ding Zhao, Bo Li, Mu Li
Action Editor: Hongyang Zhang
openreview.net/forum?id=Vc1f…
#Multimodal #Robustness #DistributionShift
3
15
2,327

19 Jan 2024
🎊Extremely honored to share that our paper on multimodal model robustness has been accepted as the 1st paper for the Journal of Data-centric Machine Learning Research @DMLRJournal
With @yizhu59 @sxjscience @flwenz @mli65
#Multimodal #Robustness #DistributionShift
'Benchmarking Robustness of Multimodal Image-Text Models under Distribution Shift'
by Jielin Qiu, Yi Zhu, Xingjian Shi, Florian Wenzel, Zhiqiang Tang, Ding Zhao, Bo Li, Mu Li
Action Editor: Hongyang Zhang
openreview.net/forum?id=Vc1f…
#Multimodal #Robustness #DistributionShift
2
3
17
2,195
Jielin Qiu retweeted

15 Oct 2023
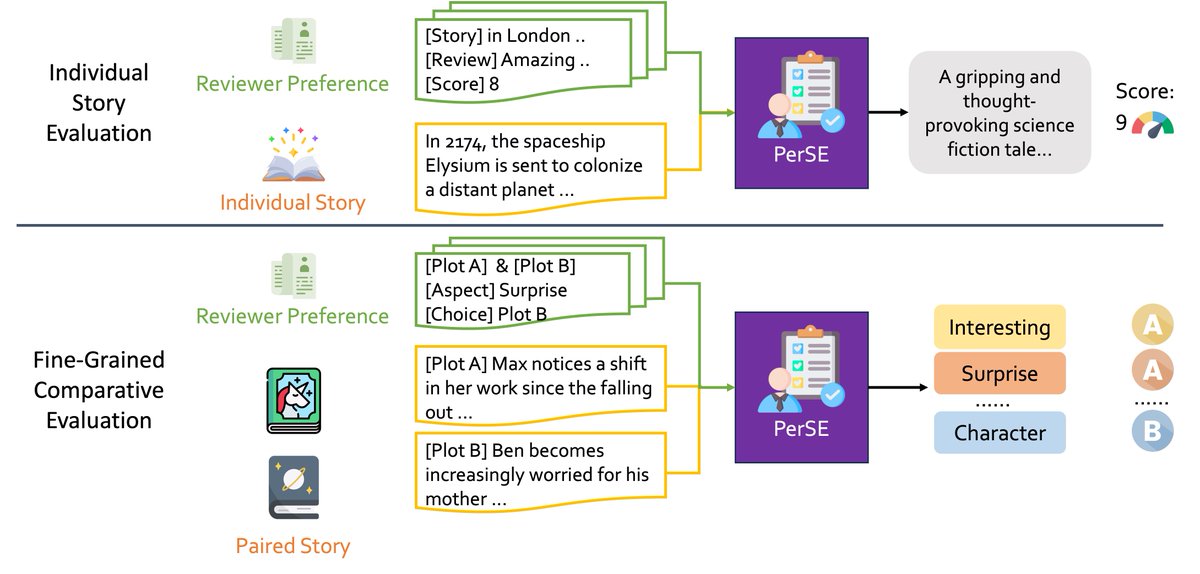
📚🌟 Evaluate any story to your heart's content with our new personalized story evaluation model, PerSE! No more worries about diverse preferences - get your own story evaluation report now! 📝🎯 arxiv.org/abs/2310.03304
1/5
1
9
30
19,071

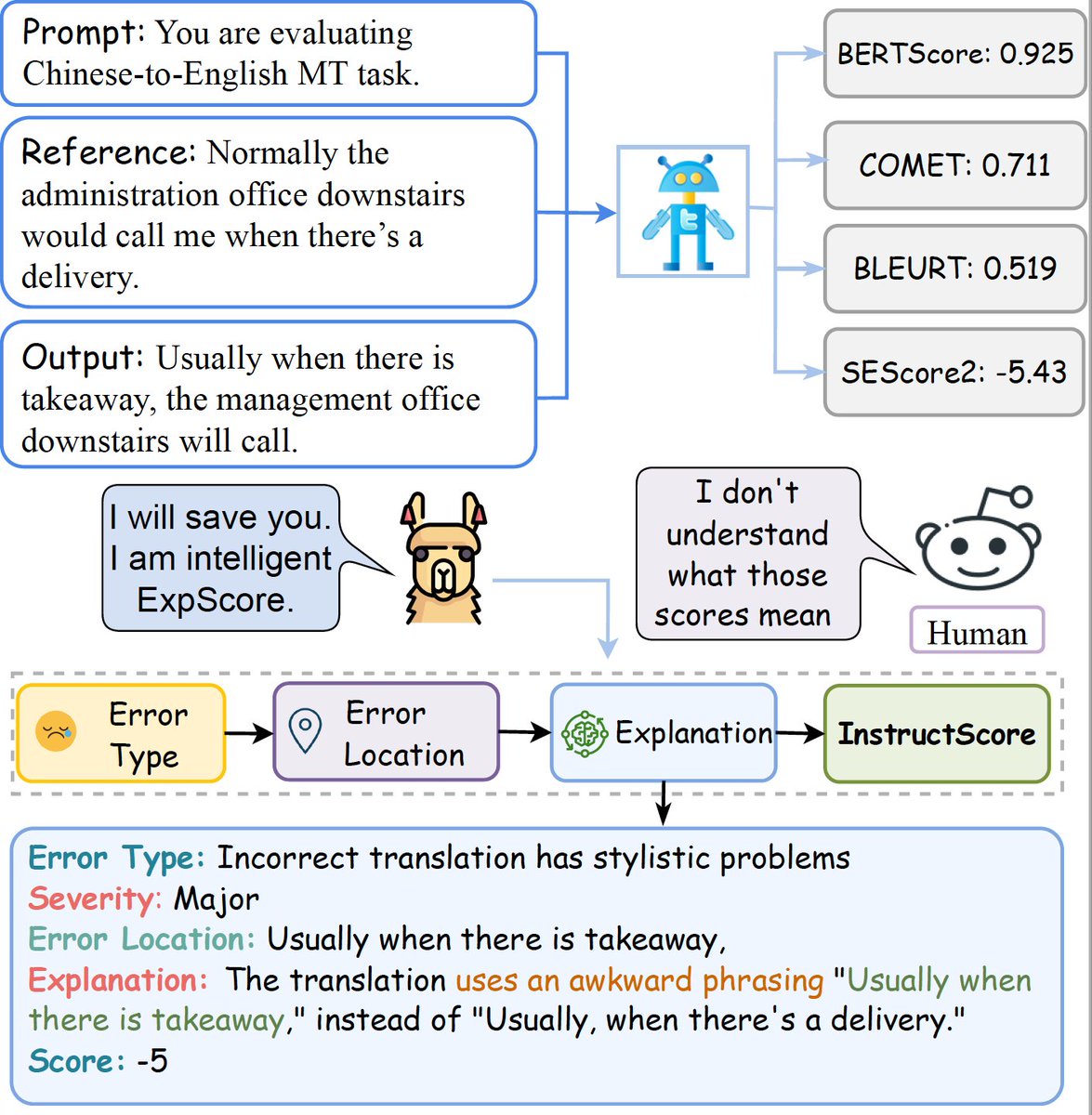
What is missing in the text generation evaluation for BERTScore, BLERUT, COMET, SEScore & SEScore2? Explanation! Can we build a metric that not only produces a well-correlated quality score but also tell you the rationales, error type, and error location? Checkout InstructScore!
ALT Joint work with Google Translate and UCSB NLP lab
7
13
85
15,023
Jielin Qiu retweeted
10 Oct 2023
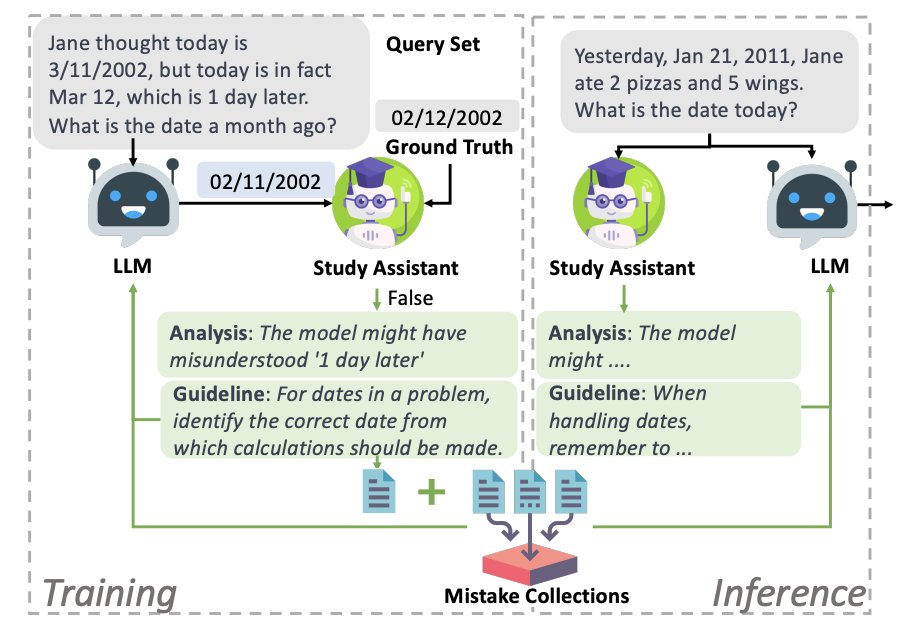
🚀 Excited to share our latest work in EMNLP main conference: "Learning from Mistakes via Interactive Study Assistant for Large Language Models". We introduce a study assistant (SALAM) to conduct thoughtful analysis on LLMs' mistakes and provide guidelines to avoid past mistakes
1
5
17
3,036
Jielin Qiu retweeted

12 Oct 2023
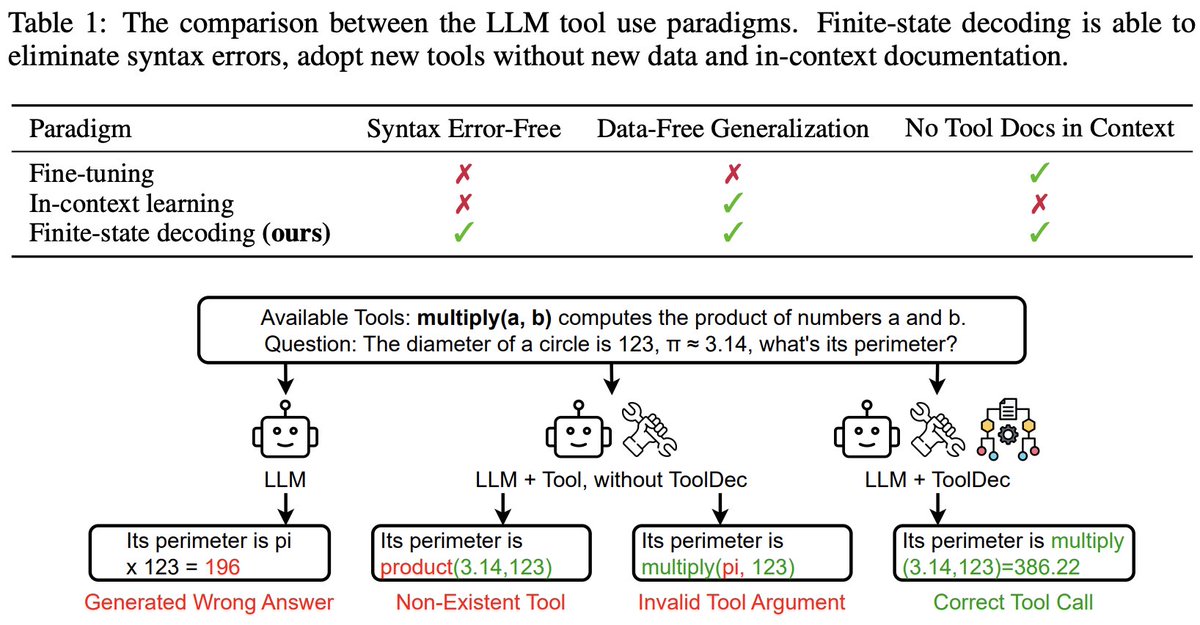
😭Tired of in-context demos & docs for LLM tool use?
💰Too GPU-poor to tune LLMs for unseen tools?
🤬Frustrated with frequent syntax errors in tool calls?
Check out our new preprint 𝐓𝐨𝐨𝐥𝐃𝐞𝐜 that addresses all these issues from the decoding side!
arxiv.org/abs/2310.07075
1/5
4
32
99
36,175
Jielin Qiu retweeted

29 Sep 2023
Excited to share our recent work, AnyMAL -- a unified Multimodal LLM built on LLaMA-2 that can reason over various inputs, e.g. images, audio, motion sensors.
Check out our paper for more information on the model training, evaluation, safety and more!
➡️ arxiv.org/abs/2309.16058

4
24
121
22,539

Check out our new evaluation benchmarks and metrics for robustness of image-text multimodal models! @AmazonScience #multimodal #stablediffusion

Are Multimodal Models Robust to Image and Text Perturbations?
deepai.org/publication/are-m…
by Jielin Qiu et al. including @yizhu59
#OpenSource #ComputerVision
2
5
24
7,409

Jielin Qiu retweeted

25 Mar 2022
Our #ACL2022 paper "Vision-and-Language Navigation: A Survey of Tasks, Methods, and Future Directions" is out (arxiv.org/abs/2203.12667)!!!
It serves as a thorough reference for the VLN research community (for both starters and experts).
github.com/eric-ai-lab/aweso…
2
27
129
Jielin Qiu retweeted

22 Mar 2022
How to present a line plot?
Line plots are effective for describing the relationship between two variables of interests.
Unfortunately, most junior students would simply copy&paste the figure from the paper in their talk and cause much confusion. 😕
Let's break it down ... 🧵
6
106
546

Our team at Google Brain is looking for outstanding PhD students (expected graduation after 2023) who are interested in student researcher internships this year 2022. careers.google.com/jobs/resu…
1
28
89

The Embodied AI Lecture Series at AI2 is back! Subscribe to the mailing list for info about how to join these free lectures live, or stay tuned and we'll post the recorded sessions after the fact.
Subscribe:
allenai.us1.list-manage.com/…
More info: prior.allenai.org/lectures

ALT Embodied AI Lecture Series @ PRIOR, Bi-weekly Fridays at 11am PST
4
13
Jielin Qiu retweeted

10 Feb 2022
I've been writing research articles for over 10 years now and one of the hardest parts is writing consistently and efficiently without procrastinating. I'm going to share some of my tips here 🧵 1/10
77
1,350
11,422
AI2's computer vision team PRIOR announced an exciting new release of their #EmbodiedAI platform AI2-THOR – in partnership with @unity, you can now train headlessly on multiple GPUs. 📈
Learn more:
medium.com/ai2-blog/ai2-thor…
13
43
Jielin Qiu retweeted

5 Feb 2022
I'm hiring an intern at Google AI team 2022! Email me (arjunakula@google.com) if you are 1) Graduating in 2023 or 2024; 2) Interested in multi-modal representation learning, language grounding; and 3) have strong publication record. #NLProc #intern #computervision #google #hiring
31
108
559
Jielin Qiu retweeted

21 Jan 2022
Where do the rewards for robotic reinforcement learning come from? In this blog post we explore how using crowdsourced language annotations and videos of humans, we can learn reward functions and enable them to generalize more broadly.
ai.stanford.edu/blog/reward-…
1
16
75