
Apr 24
Deep learning under distribution shift often relies on maximizing "disagreement discrepancy" to bound errors without target labels. But are we actually optimizing it?
In our new #ICLR2026 paper, we prove existing surrogate losses are mathematically flawed (not Bayes consistent). 🧵👇
Optimization here is a tug-of-war: the model wants to agree on source data, but disagree on target data. We show prior surrogates pull with the wrong strength. In certain regions, perfectly optimizing the surrogate completely fails to optimize the true objective! 🛑
💡 The Fix: We introduce the first provably Bayes consistent surrogate. By pairing a standard cross-entropy agreement loss with a novel, symmetric disagreement loss, we restore the balance and mathematically close the optimality gap. ⚖️
In practice, our consistent surrogate yields:
📈 Larger (better) disagreement discrepancy in ~80% of tested scenarios
🛡️ Strong robustness against adversarial target data
🕵️ Promising improvements in statistical power for harmful shift detection
Come say hi at our poster!
📍 Pavilion 4, P4-#4101
📅 Sat, Apr 25 | AM – PM
🔗 Paper: openreview.net/forum?id=VwCy…
w/ @NGMarchant, Andrew Cullen, and Sarah Erfani
@iclr_conf #ICLR #MachineLearning #LearningTheory #DistributionShift

2
145

When does context help? A systematic study of target-conditional molecular property prediction
1. The paper presents a systematic map of when target context helps (and hurts) molecular property prediction, spanning 10 protein families, 4 context-fusion designs, training data regimes from 67–9,409 compounds per target, and both random vs temporal splits.
2. Central result: how context is fused dominates whether context helps at all. With the same target identity signal, FiLM conditioning beats concatenation by 24.2 AUC points and beats additive-only conditioning by 8.6 points—showing that naive “add context” can be worse than no context.
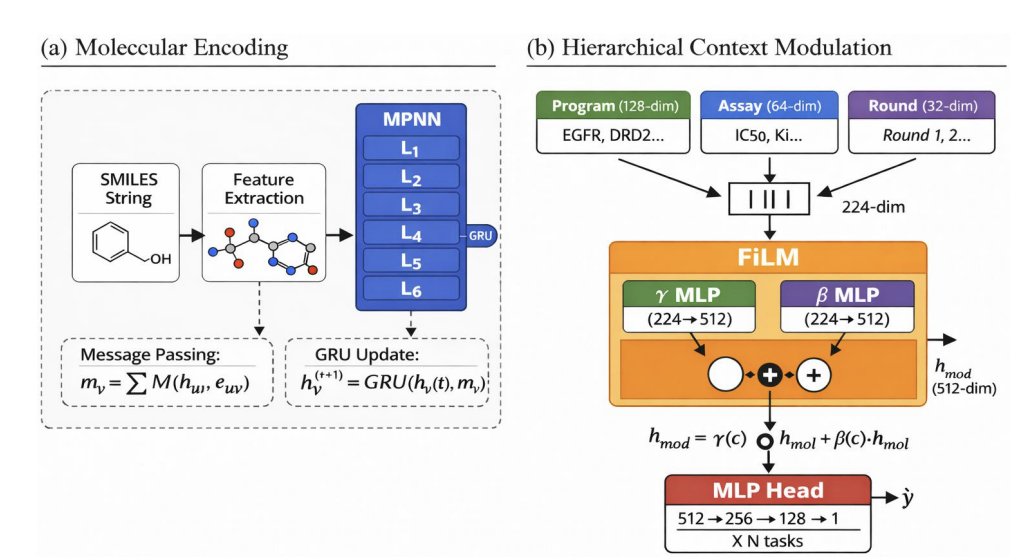
3. The model, NESTDRUG, uses an MPNN molecular encoder plus hierarchical context embeddings (target/program L1, assay L2, temporal round L3) and applies FiLM modulation: hmod = γ(c) ⊙ hmol β(c). The multiplicative γ term accounts for most of FiLM’s gain by selectively amplifying/suppressing molecular features per target.
4. In controlled ablations, target-specific L1 embeddings improve 9/10 DUD-E targets (mean 5.7 AUC points, p < 0.01). The largest gains are on ESR1 ( 13.4) and EGFR ( 13.2), suggesting context mainly helps by adapting to target-specific data/assay idiosyncrasies.
5. The clearest “context enables otherwise impossible prediction” case is CYP3A4, where only 67 training actives are available at the chosen activity threshold. A per-target Random Forest collapses to 0.238 AUC, while multi-task transfer with NESTDRUG reaches 0.686 AUC, indicating context-conditioned multitask learning can rescue data-scarce targets.
6. Context is not universally beneficial: BACE1 degrades by 10.2 AUC points with correct L1, attributed to distribution mismatch between ChEMBL (e.g., peptidomimetic series) and DUD-E (different scaffold distribution). The paper also reports few-shot adaptation of L1 embeddings consistently underperforms zero-shot (generic L1), warning against “quick embedding tuning” for new targets.
7. Mechanistic analysis suggests FiLM learns biologically structured modulation: kinase contexts yield γ > 1 (amplifying certain heterocycle/H-bond acceptor features), GPCR contexts yield γ < 1 (shifting emphasis toward lipophilicity). Inter-family variance in FiLM parameters exceeds intra-family variance (p < 0.001).
8. The work also audits benchmarking pitfalls on DUD-E: 1-nearest-neighbor Tanimoto similarity reaches 0.991 mean AUC without learning, and ~50% of actives overlap with ChEMBL training (highly target-dependent). The takeaway is that absolute DUD-E performance can be misleading, and leakage/structural bias can dominate apparent gains.
9. To address benchmark artifacts, the paper reports a temporal split evaluation (train ≤2020, test 2021–2024) with stable performance (overall 0.843 ROC-AUC, no year-over-year degradation), arguing this provides more realistic evidence that context-conditional representations can generalize to future chemical space.
💻Code: github.com/bryanc5864/nest-d…
📜Paper: arxiv.org/abs/2604.06558
#ComputationalBiology #Cheminformatics #DrugDiscovery #GraphNeuralNetworks #MachineLearning #ICLR #VirtualScreening #MultitaskLearning #DistributionShift #Benchmarking
3
10
1,249

19 Nov 2025
🤔 Have you ever wondered what’s actually on the surface of Mars?
🌊 Do you think Mars might have had water millions of years ago?
In collaboration with the @NASAJPL, we introduce Mars-Bench, the first benchmark that helps us answer such questions using machine learning. Our paper has been accepted at @NeurIPSConf 2025; discover more about Mars-Bench:
📄 Paper - arxiv.org/pdf/2510.24010
🌐 Project page - mars-bench.github.io/
#Mars #MarsScience #MarsExploration #SpaceExploration #SatelliteData #RoverData #NASA #JPL #Research #PlanetaryScience #EarthandPlanetaryScience #RemoteSensing #GeospatialAI #FoundationModels #Benchmarking #DistributionShift #OODGeneralization #NeurIPS2025 #ComputerVision #AI4Science

1
4
16
1,822

6/6
w/@LiuChenruo, @KenanTang, @YaoQin_UCSB, we hope this bridges two critical conversations—and inspires new ones.
Looking forward to your thoughts.
#AISafety #RobustML #TrustworthyAI #DistributionShift #MLTheory
2
4
727

14 Feb 2025
Summary Celestia Community Space
The meeting discussed the Mamathon hackathon @celestia , featuring 200 teams with 3–5 members each, totaling 600–1,000 participants. The hackathon includes three tracks: building unstoppable apps, crafting on-chain worlds, and upgrading the internet. Notable projects include a generative art hub, a sleep-to-earn app, and an on-chain Tamagotchi. The conversation also covered a CIP for locking staking rewards of locked tokens, aiming to align rewards with vesting schedules. The discussion highlighted the importance of economic security and the potential impact of reducing inflation by 33%. The team emphasized the shift towards sustainable token distribution and the importance of community belief in the project.
Key Discussion Points:
🦣Mamathon Hackathon Overview200 teams with 3–5 members each (600–1,000 participants).
Runs until February 28, with teams selecting ideas from partners.
Encouragement to utilize mentors and idea partners.
🦣Hackathon Tracks & Innovative ProjectsBuild Unstoppable Apps: Generative art hub using NFT metadata.
Crafting On-Chain Worlds: On-chain Tamagotchi, deck-building game on Happy Chain.
Upgrading the Internet: Sleep-to-earn app using zkTLS, Twitter clone on Chopin framework.
🦣CIP for Locking Staking RewardsIntroduced by Marco to align rewards with vesting schedules.
Locked tokens will have staking rewards locked accordingly.
Aims to strengthen long-term economic security and fairness.
🦣Community Reactions & ImplicationsPositive community sentiment regarding fairness.
Concerns about the impact of airdrop staking on trust.
Recognition of Celestia’s conservative staking economics compared to others.
🦣Economic Security & Staking YieldsEmphasis on high staking ratios for network security.
Penumbra’s low yield cited as an industry learning point.
Adjustments might occur based on evolving network needs.
🦣Air Drop Meta & Token DistributionShift from random airdrops to thoughtful, sustainable mechanisms.
Echo and Legion groups mentioned as innovative methods.
Importance of long-term, community-driven token distribution.
🦣Regulatory Impact & Future OutlookDiscussed potential regulations shaping token distribution.
Insights from Justin Drake on Ethereum’s data availability role.
Long-term focus on ensuring Celestia’s alignment with network goals.
For full details, please listen to the original Space recording:
x.com/nickwh8te/status/18900…
13 Feb 2025

1
5
159

19 Jan 2024
🎊Extremely honored to share that our paper on multimodal model robustness has been accepted as the 1st paper for the Journal of Data-centric Machine Learning Research @DMLRJournal
With @yizhu59 @sxjscience @flwenz @mli65
#Multimodal #Robustness #DistributionShift

'Benchmarking Robustness of Multimodal Image-Text Models under Distribution Shift'
by Jielin Qiu, Yi Zhu, Xingjian Shi, Florian Wenzel, Zhiqiang Tang, Ding Zhao, Bo Li, Mu Li
Action Editor: Hongyang Zhang
openreview.net/forum?id=Vc1f…
#Multimodal #Robustness #DistributionShift
2
3
17
2,195

'Benchmarking Robustness of Multimodal Image-Text Models under Distribution Shift'
by Jielin Qiu, Yi Zhu, Xingjian Shi, Florian Wenzel, Zhiqiang Tang, Ding Zhao, Bo Li, Mu Li
Action Editor: Hongyang Zhang
openreview.net/forum?id=Vc1f…
#Multimodal #Robustness #DistributionShift
2
9
25,800

24 Oct 2023
👩🏫 Teaching RL in my Grad #MLTheory course and want to shout 📣: RL isn't just another topic, it's the edge of distribution shift! 📈
🤔 Spotted so many #RL misconceptions out there. My own RL journey began at my postdoc time at #MSRNYC 🏙️with @JohnCLangford and Robert Schapire —steep but oh-so-worth-it: it required deep dives into literature📚, impacting my paper output but enriching my understanding. #NoRegretLearning ☺️
🤷 Should I drop my two cents on what sets RL apart from supervised learning, and discuss the #DistributionShift trap in RL?🦄
Additional questions to ponder:
👀 Can you do #RLHF without RL? What does ‘without RL’ mean? What does ‘RL’ mean? What are you really approximating, without RL? And when is that even valid? 🎯
6
5
103
21,233

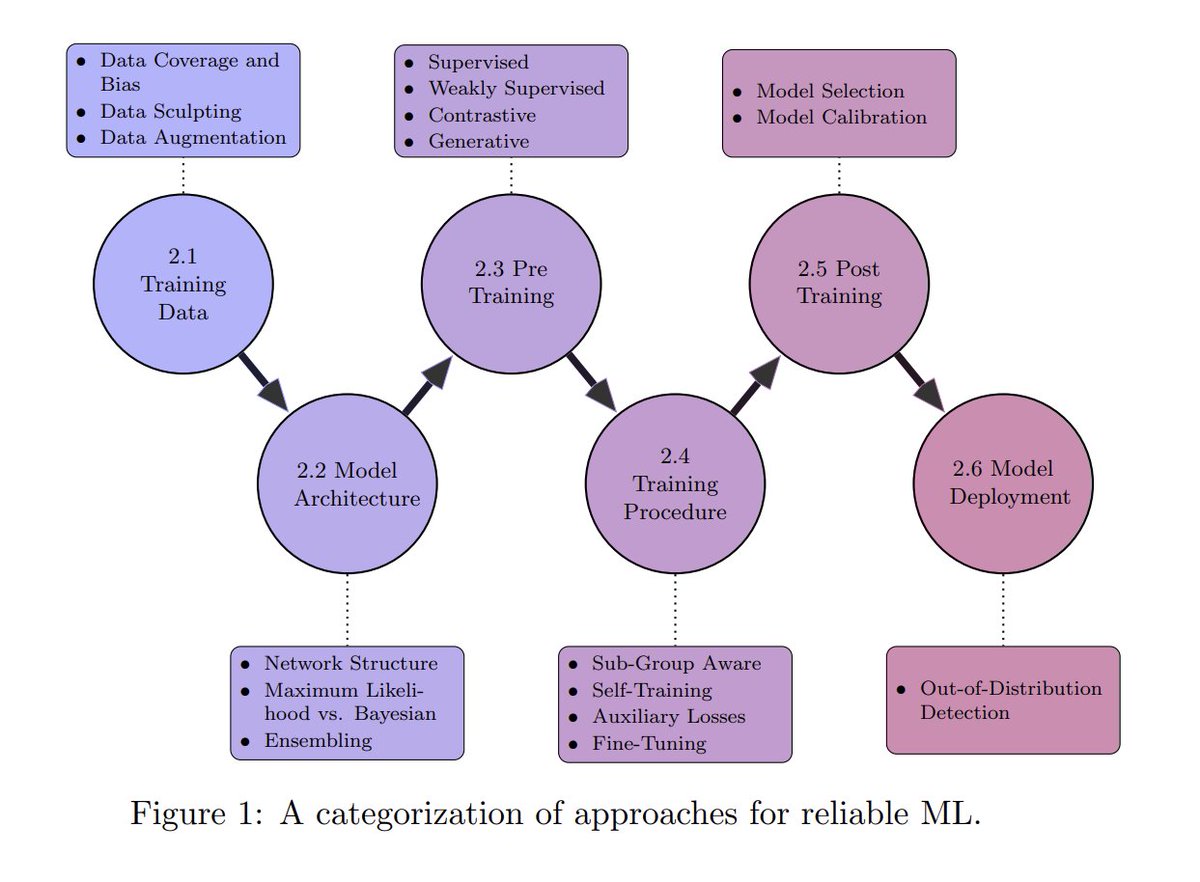
Recent study proposed a new methodology for the assessment of the reliability of ML systems that combines metrics related to in-distribution performance, distributionshift robustness, adversarial robustness, calibration, and out-of-distribution detection. arxiv.org/abs/2307.10586
1
2
586

5 May 2023
This work was done in the context of @WeNetProject.
Stay tuned for the pre-print.
@EPFL @Idiap_ch #generalization #datasetshift #mobilesensing #sensors #bias #distributionshift #ML #AI #machinelearning
1
4
153

28 Apr 2023
I had a great time learning from @sirbayes on various topics, including prediction under #DistributionShift and online decision making, during his visit to @NotreDame.
2
288

28 Nov 2022
Yet another #NeurIPS22 post in your timeline!
📣📣 My first in-person conference!
💡💡 Need your #ReinforcementLearning algorithms to be ROBUST??? a.k.a #distributionshift
Attend our poster in Hall J: Tue 29 Nov 4 p.m. CST
neurips.cc/virtual/2022/post…
1
5

20 Jun 2022
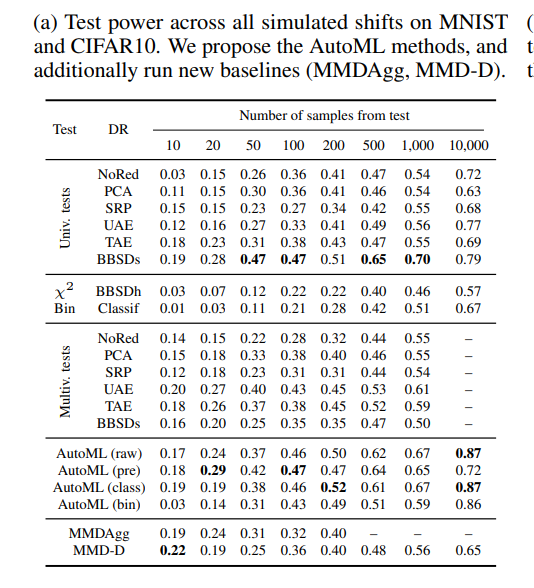
We use #AutoGluon (@innixma @smolix ) which out of the box leads to great empirical results and can outperform recent MMD-based tests (@AntoninSchrab, @AlexFengLiu1).
In particular, we run the #distributionShift benchmark of @steverab @zacharylipton @guenneman.
2
3
8

13 Apr 2022
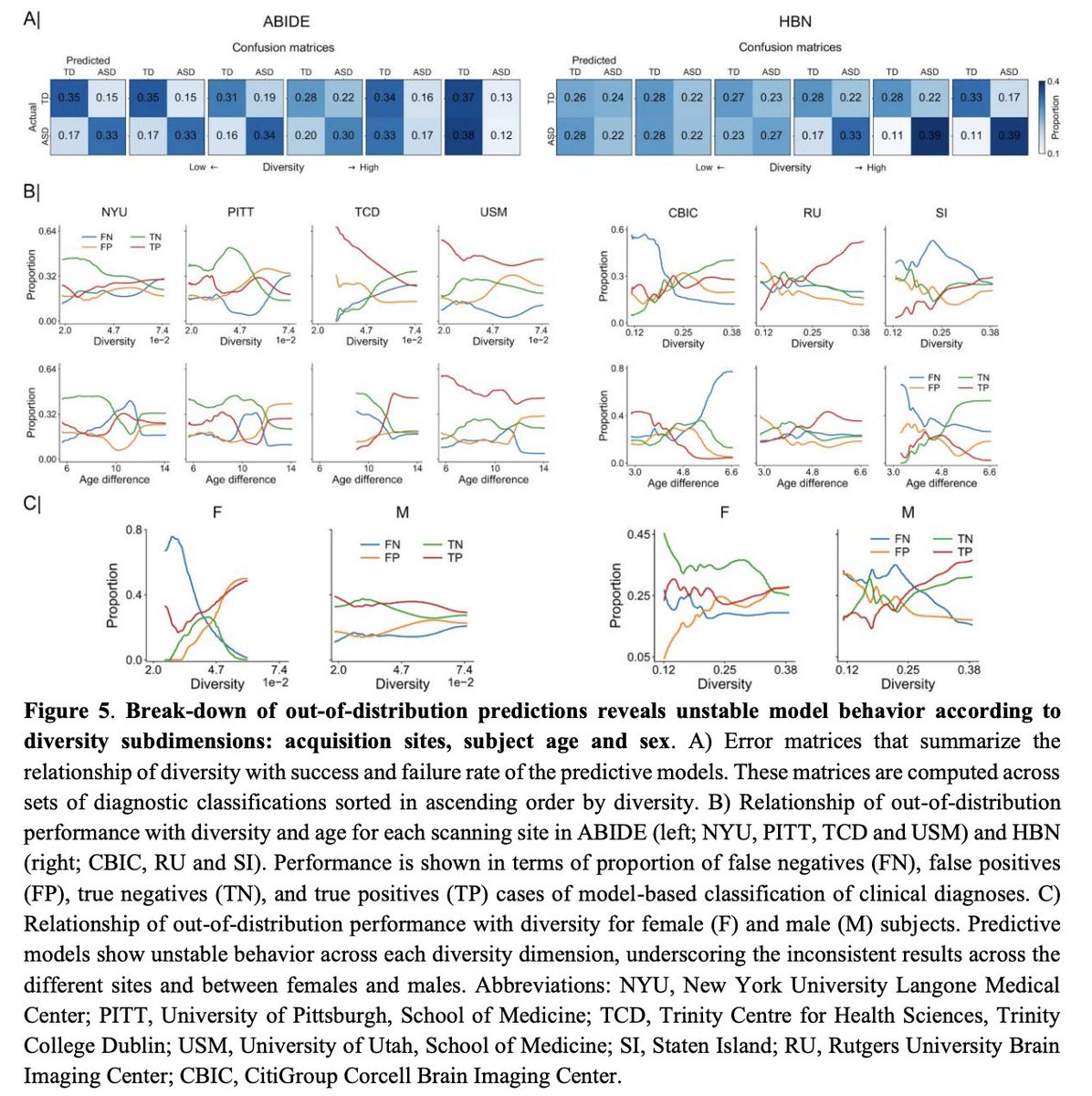
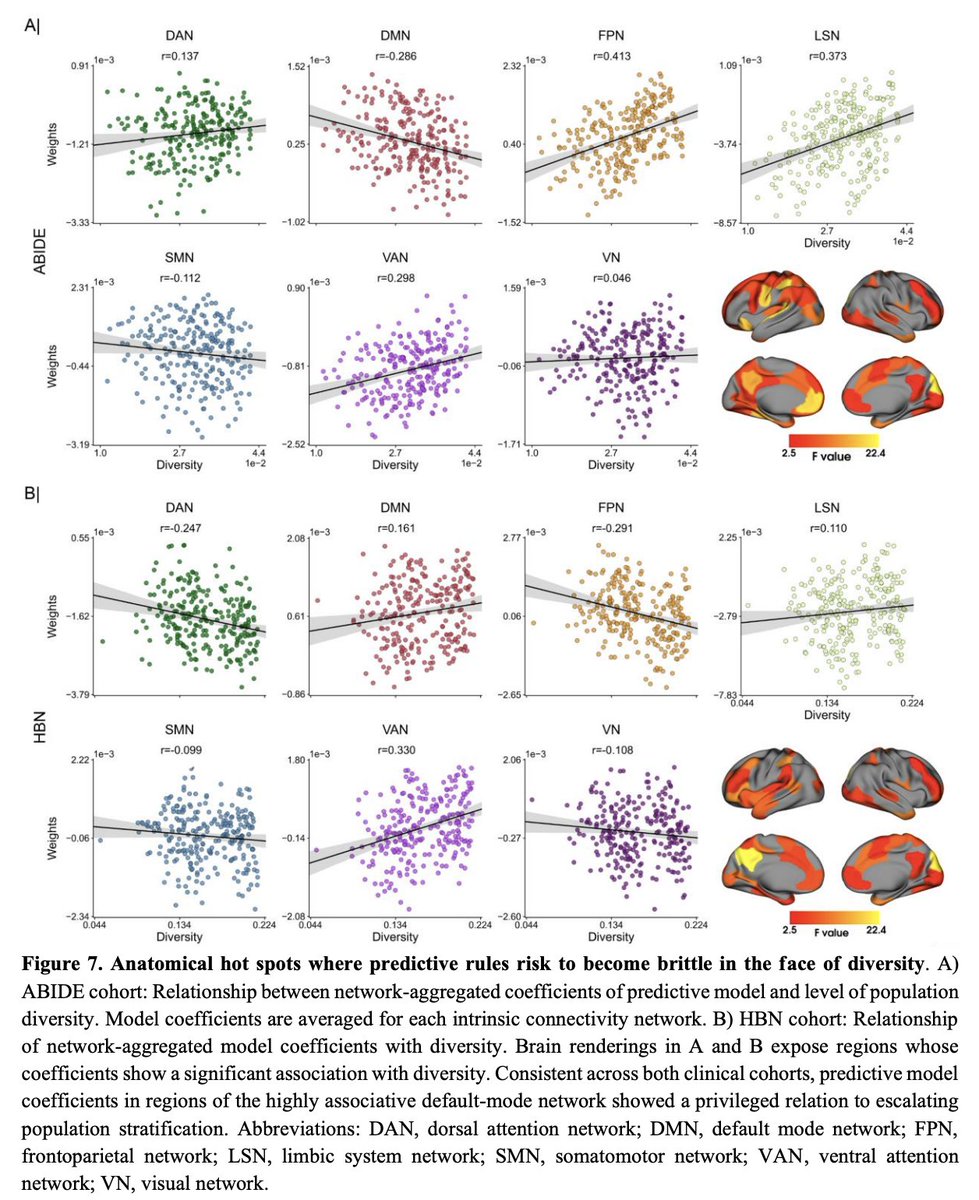
Our paper on #distributionshift in human neuroscience now accepted at @PLOSBiology.
Congrats to @oualid_benkarim for leading this quantitative analysis!
#untracked #diversity #outofdistribution
@enigmabrains @ABCD_ReproNim @BertrandThirion @phyzang
18 Jun 2021

New preprint, led by @oualid_benkarim, examining
out-of-distribution prediction in #ABIDE #HBN:
Analytical tools are needed to get a handle on
#untracked #diversity in multi-site cohorts
biorxiv.org/content/10.1101/…
5
12

28 Feb 2022
I am delighted to announce that a draft of my latest book, “Probabilistic Machine Learning: Advanced Topics”, is now available online at probml.ai. It covers #DeepGenerativeModels, #BayesianInference, #Causality, #ReinforcementLearning, #DistributionShift, etc.

36
961
4,622

11 Nov 2020
> #machinelearning pipeline as directed acyclic graph (#DAG) once for both training and inference (scoring)
DAGs are not powerful enough for modeling #NonStationaryLearning (#distributionShift, #conceptDrift) we need integration with other application level business processes
2
7 Oct 2020
"#ML systems which depend strongly on properties of their inputs (i.i.d. assumption) tend to fail silently; in practice; #ML pipelines rarely inspect incoming data for signs of #distributionShift"
#NonStationaryLearning #ModelRisk
#MachineLearningEngineering
Beyond "#MLOps"



arxiv.org/abs/1810.11953v1
S Rabanser et. al.
Failing Loudly: An Empirical Study of Methods for Detecting Dataset
Shift

2
2