
Auditable risk intelligence. Built for rating agencies, investors, underwriters, and risk teams. Every claim cited. A decision your auditor can accept.
Joined May 2026
- Tweets 40
- Following 16
- Followers 15
- Likes 56
1 Photos and videos

Pinned Tweet

Jun 1
1/ AI made diligence faster, but it did not automatically make it trustworthy.
A counterparty memo can be written in 10 minutes and still fall apart the moment someone asks how the team reached the view.
That is the problem ResearchTech is built for.
1
3
15
179

We got Mythos at home.

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

28
92
2,886
396,911
Jun 12
A risk methodology cannot be simpler than the system it is trying to assess.
That is where a lot of protocol ratings start to break. The protocol is a dependency graph, but the methodology treats it like a checklist. Fields are collected, scored, averaged, and compressed into a single number. The process looks structured, but it often removes the structure that actually creates the risk.
In DeFi, one unresolved dependency can affect many parts of the assessment at once. A governance config can change admin risk, upgrade risk, emergency controls, and user exit assumptions. An oracle route can affect pricing, liquidation, NAV, and redemption logic. A bridge dependency can connect risks that look separate inside the report.
So the hard part is not just defining a better framework. The hard part is maintenance. The methodology has to preserve dependencies, evidence trails, unresolved assumptions, scoring impact, and version changes every time the protocol changes.
That does not scale reliably with analysts alone, because coverage growth becomes headcount growth. It also does not work with basic LLM workflows, because the problem is not writing more text. The problem is maintaining structure, checking evidence, and updating the assessment without losing the rationale behind it.
This is the layer risk teams need now – a way to maintain complex methodologies as the systems they assess keep changing.
That is what we are building toward at ResearchTech.
11
Research Tech retweeted

Jun 11
What does asset-level transparency for a tokenized fund actually mean?
Let’s make it concrete. 🧵

1
1
9
853
Research Tech retweeted

Jun 11
Based on the latest Aave Risk Framework, Aave service providers have started preliminary outreach to all asset issuers on Aave to review their compliance with the Risk Framework before it goes live. If you have not yet been contacted, please reach out.
22
27
175
17,216
Jun 11
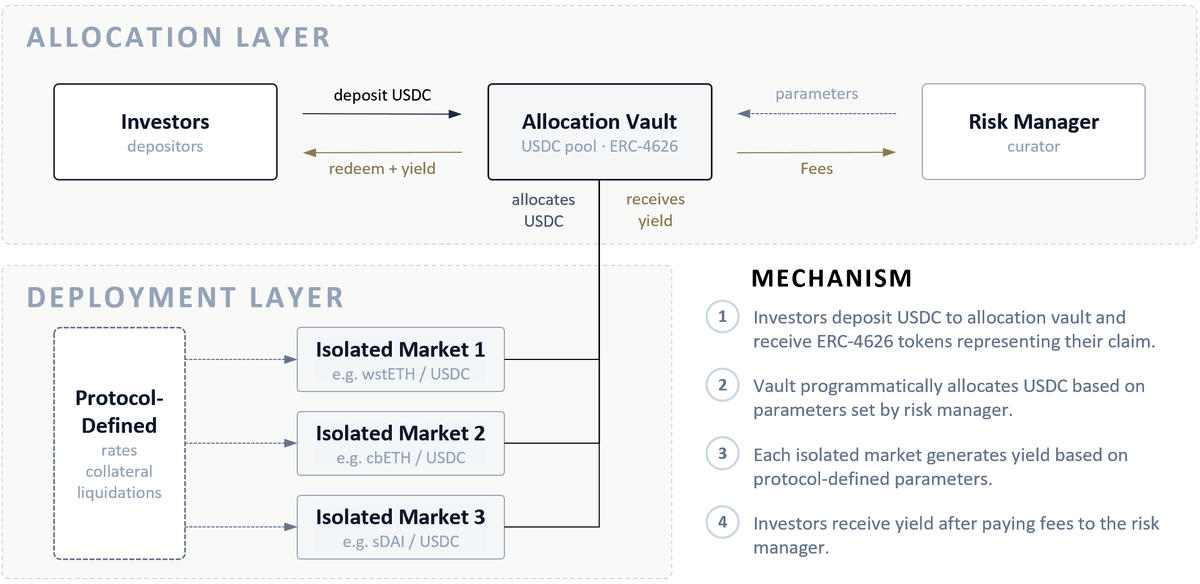
Allocation vaults abstract a lot of messy work for investors. Instead of underwriting every asset, issuer, pool and rebalance manually, the investor gets exposure through one managed allocation layer.
But it also changes what needs to be transparent. Investors should not be limited to balances, APY, and headline exposure.
For allocation vaults, the more important focus is whether the current portfolio construction remains justified.
That means understanding the assumptions behind the allocation, the dependencies shared across positions, the risk conditions being monitored, and the circumstances under which the strategy would need to change.

Solid overview of the vault space from @RWA_xyz
Tradeoffs, mechanisms and considerations for institutional players looking at the space
4
43
Jun 10
A DeFi risk assessment can collect 400 data points and still be controlled by 11 facts.
That sounds counterintuitive, but it is how risk works once you stop treating the assessment as a simplistic linear system. Most data points are not useless per se. They provide context, support the record, and help with review. But they do not all update the final risk view with the same 'force'.
The important distinction is between evidence that fills the report and evidence that changes the assessment. In a protocol review, many fields are downstream of the same unresolved dependency.
This is why signal and noise look different in risk work than they do in ordinary research. Noise is not only “bad data.” Noise can also be valid data that does not move a high-weight dependency. A documentation field may be accurate and still have very little effect on the final score. A single live config check may move the entire assessment because it resolves something upstream.
Evidence matters when it changes the probability of something decision-relevant. If a new data point does not update a major dependency, the posterior barely moves. If it resolves a high-weight uncertainty, the whole score can shift.
That is why more research/data is not automatically better risk coverage.
3
16
Jun 10
The forward-deployed engineer trend is a good signal for where AI risk management is going.
Enterprise AI is not scaling as pure self-serve SaaS because the hard part is not access to a model. The hard part is getting the model into real operating workflows without breaking controls.
Every deployment changes the risk state of the system. That is why FDEs matter a lot. They focus exactly on where the abstract AI policy meets the actual business process.
But it also means AI risk management has to become much more operational. You cannot approve the use case once and assume the control basis still holds after 6 months later.

1
3
61
Jun 9
Broader risk frameworks like this one will become the standard for every risk team in DeFi.
They all depend on qualitative and offchain evidence and the layers are deeply interconnected.
Structuring, enhancing, and maintaining that web of dependencies manually across hundreds of assets and dozens of chains won't be efficient / accurate.
We're building for exactly this reality.
Jun 9

LlamaRisk has published an ARFC proposing a new standardized Risk Framework that governs all assets on @Aave V3, V4, and Aave Horizon.
The framework establishes standards for evaluating asset, bridge, and chain-level risk criteria, and for monitoring and automated risk management systems.

2
19
Research Tech retweeted

Jun 8
1/ 3 days at @money2020 Amsterdam.
Dozens of conversations with risk teams.
One uncomfortable conclusion: we'd been solving the wrong problem.
1
1
2
33
Jun 8
Most risk teams hit the same scaling problem. They cover 50 assets, but the market asks for 200, and the default answer is to hire more analysts. That is a suboptimal answer if the process itself still grows linearly.
Every new asset adds documents, contracts, governance changes, integrations, dependencies, incidents, and monitoring work.
If each assessment is still treated as a one-off manual project, the team does not scale. It just creates more queues and more stale work.
Generic LLM research does not solve this either. Multi-step research workflows break down quickly when accuracy, source checking, conflicting evidence, and verification matter. You can generate more text, but that does not mean you have a reliable assessment.
The real bottleneck is one hour of analyst time. How much ground can that hour cover? How much evidence can it check? How much can it verify before the analyst has to make a judgment?
That is where risk work needs to improve. Not by removing analysts, but by making each analyst hour cover more surface area without losing the trail behind the assessment.
1
9
Jun 8
We believe that vaults transparency should evolve.
It should not only describe where capital is allocated. But also make clear why those allocations still hold under the current risk state.
In current transparency state you can observe where capital is allocated, APY %, and which markets it touches.
However, investors have no clarity on if current risk exposure is acceptable, which assumptions support it, which dependencies are shared (e.g. bridge exposure), or what would make the allocation invalid.
This becomes more complex/risky once vaults start holding tokenized assets. The risk profile changes dramatically with new offchain dependencies.

4
128
Jun 8
DeFi risk coverage started with collateral analysis. That was a necessary starting point. It is no longer enough.
The problem is that collateral is now utilized inside a larger dependency structure.
A lending market inherits risk from:
-the asset,
-the oracle path,
-liquidation design,
-governance controls,
-liquidity routing,
-market parameters,
-vault strategy,
-bridge exposure,
-and any issuer, wrapper, custodian, or balance sheet behind the asset itself.
That is already a dependency graph inside one protocol. The graph becomes way more complex once the same asset moves across markets and chains.
With tokenized assets, it extends further into offchain dependencies that carry potential risk vectors as well.
This changes the unit of risk coverage. Risk frameworks now have to track the dependency structure behind the asset and keep the evidence current (dynamic) as that structure changes.
Jun 3

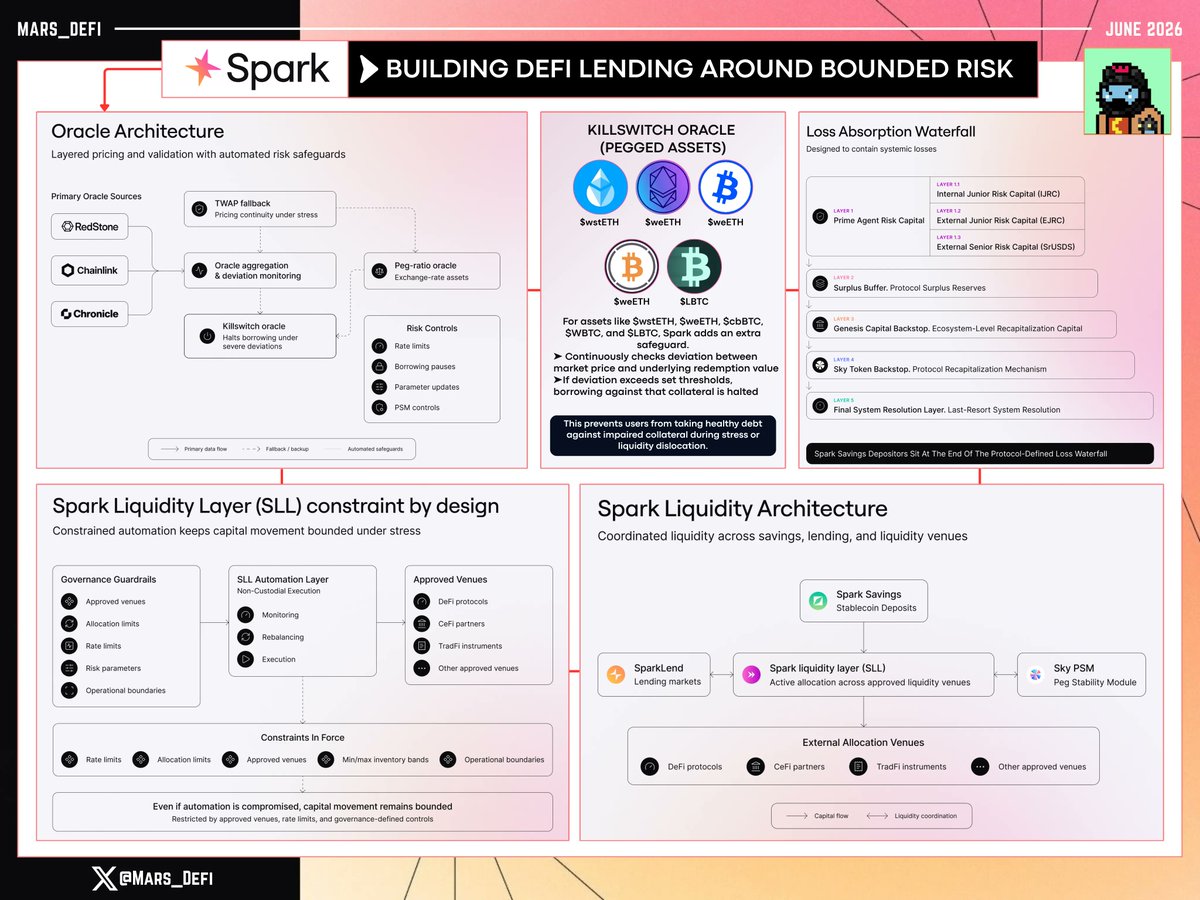
Most lending markets optimize for liquidity and capital efficiency first, then try to manage risk after the fact while @sparkdotfi ’s security/risk framework is one of the better examples of where DeFi lending is heading.
The whole architecture is built around bounded risk, controlled capital movement, layered loss absorption, oracle redundancy, and stress-response mechanisms.
Here’s how Spark does it.
—
Spark keeps a deliberately narrow collateral set, which reduces exposure to fragmented liquidity, weak redemption assumptions, and long-tail collateral risk.
Instead of trying to list every possible asset, it prioritizes predictable liquidation behavior and deeper market structure during stress.
For assets with more unique or chain-specific risks, Spark uses isolated markets. That means risk can be priced more precisely per collateral type, and a single collateral issue does not automatically contaminate the broader pool.
—
The oracle setup is also important.
Spark uses a three-oracle median system drawing from @redstone_defi , @chainlink , and @ChronicleLabs oracle.
When all three return valid prices, the median is used. If only two valid sources are available, the average is used, with fallback logic under degraded conditions.
That reduces dependency on any single oracle provider.
For pegged or exchange-rate assets like $wstETH, $weETH, $cbBTC, $WBTC, and $LBTC, Spark adds another layer through a killswitch oracle.
• This continuously checks whether market pricing is diverging from the underlying exchange-rate or redemption value.
• If deviation passes predefined thresholds, Spark can halt new borrowing against that collateral.
That is a very important safeguard because it prevents users from borrowing healthy debt against impaired collateral during periods of stress, liquidity fragmentation, or pricing dislocation.
—
The liquidity architecture is another strong part of the design.
Spark’s Liquidity Layer is not just idle capital sitting passively in a pool. It coordinates liquidity across Spark Savings, SparkLend, the Sky PSM, and other approved venues.
But the key part is that this liquidity movement is constrained by design.
All venues must be pre-approved by governance. Capital movement is subject to;
• allocation limits
• rate limits
• min/max inventory bands
• risk parameters
• operational boundaries
Spark’s framework is built around controlled risk, not unlimited automation.
Capital can only move through approved venues, rate limits, allocation limits, and governance-defined boundaries. So even if automation fails, the damage is contained.
The same idea applies to losses.
Before depositors are affected, losses pass through multiple buffers: risk capital, surplus buffer, Genesis Backstop, SKY backstop, and final resolution.
Spark Savings also has 1:1 USDS backing, liquidity buffers, fast withdrawal routing, real-time transparency, Credora risk reviews, and limited bridge exposure.
—
Overall, the theme is simple:
Spark is not just chasing higher yields.
It is building DeFi credit infrastructure around constrained liquidity, layered protection, and limited blast radius.
5
51
Jun 7
Tokenized assets will not remain isolated instruments. Once they are onchain, they will be pulled into DeFi balance sheets as collateral, yield assets, etc.
For native crypto assets, the evidence surface is mostly endogenous to the system (contracts, tx history, etc.) can be inspected directly onchain.
For tokenized assets, the binding risk is often not the token contract but the offchain state it references. Those facts are harder to verify and maintain.
They are spread and fragmented across documents, disclosures, attestations, audits, registries, counterparty reports, and periodic updates. They are not always public, standardized, machine-readable, or current.
At ResearchTech we believe as tokenized assets become part of DeFi balance sheets, risk teams will need to move beyond onchain data.
They will need pipelines that can collect offchain evidence, verify what each source supports, track stale or conflicting information, and update the risk view when the underlying facts change.
1
7
Research Tech retweeted

Mar 26
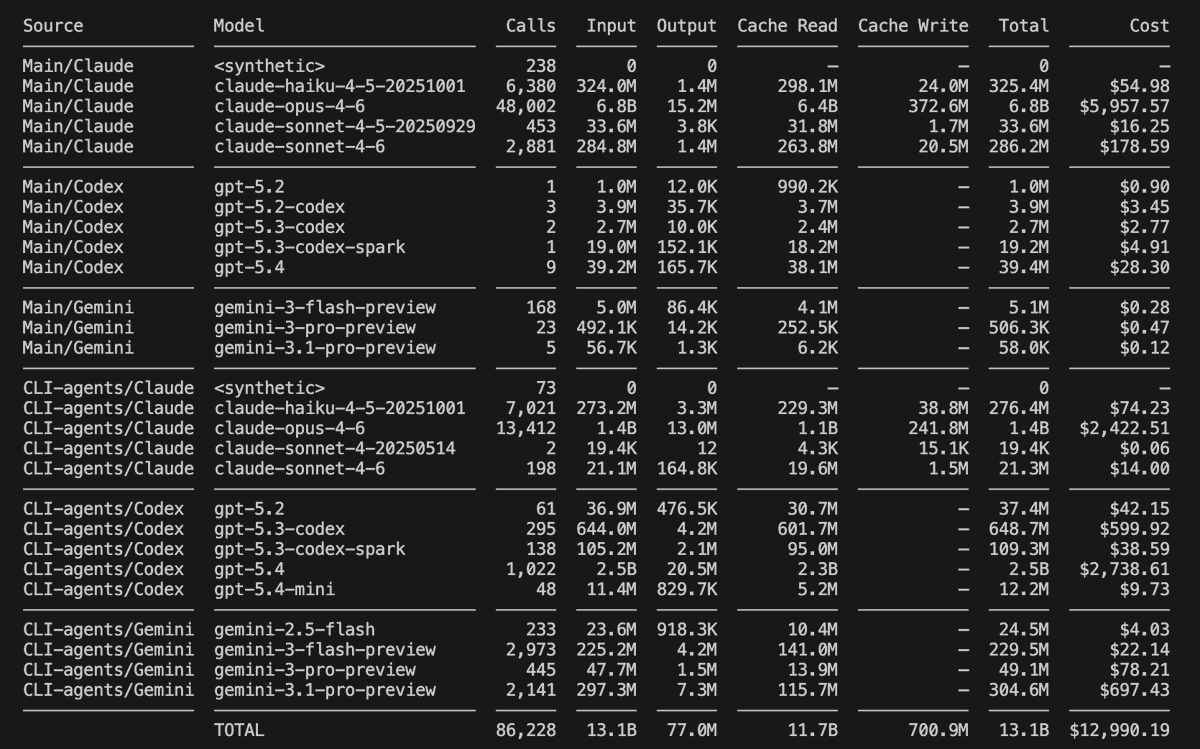
I'm building an AI startup called ResearchTech, we automate risk assessment and due diligence processes. During last 30 days for coding alone I used 13.1B input tokens and 77M output tokens. We move lighting fast, soon some of our products will be finally publicly available, they will be great.
We are hiring, if you are using AI coding tools and can build workflows which can take hours and they work well in practice, you are perfect match. We are no longer building code with AI, we are building coding frameworks for AI to build entire products for us, that's the only way to go, because during out analysis we process 100M tokens, it's no longer manageable to do it manually, so the only option is create AI agents to do it for us. Can't wait to share more, stay tuned.
1
1
10
347
Research Tech retweeted

Jun 5
Amazing solution for the current state of defi risk.
DeFi is not in complete early-stage and its so modular and interconnected. One asset is no longer just one asset. It becomes embedded across multiple layers of financial abstraction (vault, lending collateral, PT/YT markets, etc.)
When the balance sheet changes, the risk is not isolated. It propagates through the full dependency graph of markets and strategies that use it as collateral, liquidity, or yield.
Jun 5

What are all the positions affected by apyx and the STRC depeg?
50 tokens and vaults are intertwined in apxUSD across pendle, morpho, termmax, infinifi, neutrl, royco, beefy, and more (cross chain too on base and bsc).
I break down the apxUSD balance sheet graph here:
1
1
5
420
Jun 3
1/
Current crypto risk frameworks are still built too linearly. They break risk into separate categories, score each category, apply weights, and turn the result into one final number. That is useful for consistency, but it also oversimplifies how crypto systems actually behave.
1
1
4
61
Jun 3
5/
That matters because risk teams do not only need a final rating (oversimplification). They need to understand why the rating is where it is, what would move it, and which evidence or control gaps are actually material.
1
14
Jun 3
6/
Crypto risk frameworks need to start treating protocols, vaults, issuers, and counterparties as complex systems. Because that is what they are.
13