
Leading Reinforcement Learning at @Reflection_ai. Scaling RL for frontier reasoning models. Formerly @OpenAI, @GoogleBrain and @stanford_ee.
Joined December 2017
- Tweets 161
- Following 630
- Followers 1,540
- Likes 1,052
9 Photos and videos

Behrooz Ghorbani retweeted

I’m joining the OSS team at @reflection_ai! 🙏
My life mission has always been to work on open intelligence but there was always a missing piece in my skills:
PyTorch taught me the magic of combining Infra knowledge with applied research
@joespeez allowed me to be the dumbest person in the room and I learned more from him in those months than all years of my career.
It was a total intern feeling and was the happiest I’ve felt in a while.
I was convinced that working on OSS infra and applied research should be my next chapter.
I’m very grateful to @MishaLaskin and @real_ioannis to allowing me to be a part of the dream
To stronger chai and greater learnings at the frontier!

24
4
254
22,785

May 22
Exciting times at @reflection_ai!
Science moves faster when researchers can inspect, adapt, reproduce, and build. That is why open models matter.
If you want to build models that move science forward, come join us.
May 22

Our open models are designed to support the Genesis Mission by giving the scientists in our national labs the flexibility and sovereignty to work on their own terms. Learn more ⤵️
4
497

Behrooz Ghorbani retweeted

Mar 16
AGI is in its first stages of take-off.
Every country is realizing that AI sovereignty is existential, which requires open models.
We’ve signed a deal with Shinsegae Group to build South Korea’s sovereign cloud on a US open model built by Reflection.
More to come.
9
19
134
24,425
Mar 16
Proud to share that Reflection is partnering with Shinsegae Group to build a 250MW AI factory for Korea’s sovereign AI 🇰🇷
Excited to keep pushing the frontiers of RL, reasoning, and open models with this team!
wsj.com/tech/ai/nvidia-backe…
1
5
51
4,112
Behrooz Ghorbani retweeted

Excited to announce that, after finishing my PhD a couple of months ago, I will continue to do *open* science at @reflection_ai on @_ghorbani's new team!
And we are still looking for exceptional individuals to join us 😉
1 Dec 2025

Hi friends, after three incredible years at OpenAI I am excited to share that I am starting a new chapter at @reflection_ai, where I will be leading the Science of Scaling team.
Our mission is to deepen the scientific understanding of large scale learning and to turn compute into intelligence as efficiently and predictably as possible.
1
1
20
1,569
Behrooz Ghorbani retweeted

18 Dec 2025
Most approaches to “agentic AI” focus on post-training fixes.
In this conversation, member of our technical staff, @achowdhery argues the bottleneck is pre-training itself. Drawing on her work on PaLM and early Gemini, she explains why next-token prediction breaks down for long-horizon planning -- and how objectives, attention, and training data must evolve to support true agentic behavior.
17 Dec 2025

Today, we're joined by @achowdhery, member of technical staff at @reflection_ai, to explore the fundamental shifts required to build true agentic AI. While the industry has largely focused on post-training techniques to improve reasoning, Aakanksha draws on her experience leading pre-training efforts for Google’s PaLM and early Gemini models to argue that pre-training itself must be rethought to move beyond static benchmarks. We explore the limitations of next-token prediction for multi-step workflows and examine how attention mechanisms, loss objectives, and training data must evolve to support long-form reasoning and planning. Aakanksha shares insights on the difference between context retrieval and actual reasoning, the importance of "trajectory" training data, and why scaling remains essential for discovering emergent agentic capabilities like error recovery and dynamic tool learning.
🗒️ For the full list of resources for this episode, visit the show notes page: twimlai.com/go/759.
📖 CHAPTERS
===============================
00:00 - Introduction
02:26 - Reflection
04:54 - Limitations of post-training for building agents
07:31 - Rethinking pre-training in agents
10:51 - Scaling
11:27 - Evolving attention mechanisms for agentic capabilities
12:39 - Memory as a tool
14:13 - Loss objectives and training data
15:50 - Fine-tuning loss in agent performance
19:37 - Training data
21:29 - Augmenting dominant training data source
24:11 - Overcoming challenges in training on synthetic data
25:47 - Benchmarks
30:44 - Scaling laws in large models versus small models
33:20 - Long-form versus short-form reasoning
37:57 - Agent’s ability to recover from failure
40:15 - Hallucinations and failure recovery
43:53 - Tool use in agents
46:38 - Coding agents
48:37 - How researchers can contribute to agentic AI
5
15
112
45,037
Behrooz Ghorbani retweeted

2 Dec 2025
2 hrs in and I have almost lost my voice

3
3
73
6,153
1 Dec 2025
Hi friends, after three incredible years at OpenAI I am excited to share that I am starting a new chapter at @reflection_ai, where I will be leading the Science of Scaling team.
Our mission is to deepen the scientific understanding of large scale learning and to turn compute into intelligence as efficiently and predictably as possible.
31
12
281
74,671
1 Dec 2025
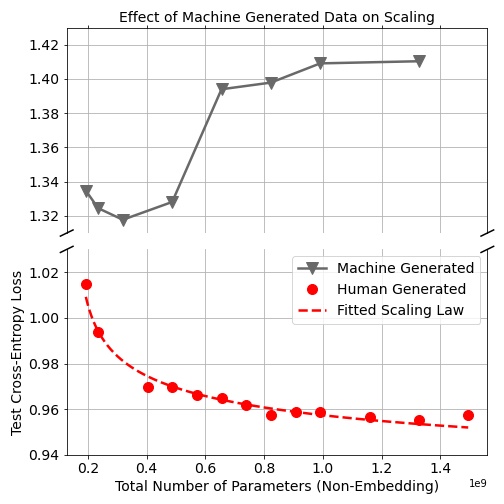
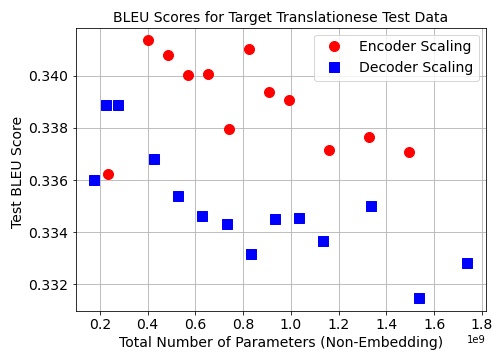
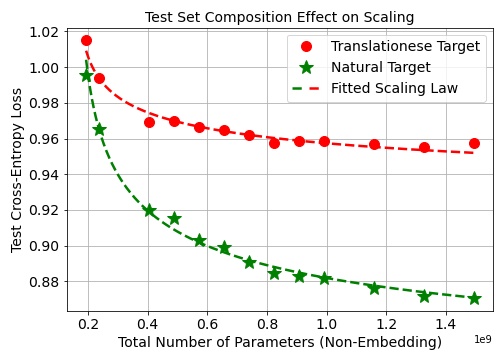
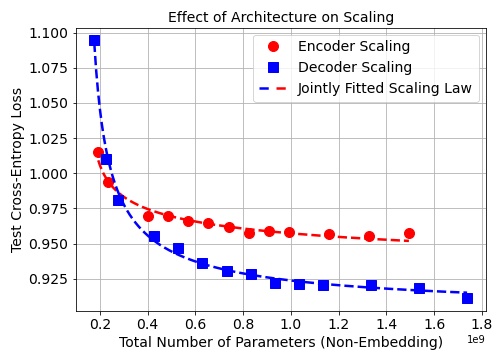
In Science of Scaling we will focus on three pillars: understanding LLM training dynamics at scale, the role of real and synthetic data, and the science of RL. I am especially excited to pursue this mission together with @MishaLaskin and @real_ioannis at Reflection.
I am building a small, high trust team that cares deeply about open research, careful measurement, and engineering excellence. If you are interested in the science of pretraining, data, and RL at scale and want to help push the frontier with a focused, tight knit group, my DMs are open. I will also be at NeurIPS this week (calendly.com/b-ghorbani-bg/3…).
3
3
33
3,791
1 Dec 2025
I am deeply grateful to my colleagues at OpenAI. It has been a privilege to be there from the early days of ChatGPT and to learn from so many brilliant people, especially the reasoning team, which has been my home these past few years and a constant source of insight, collaboration, and support.
Thank you for everything we built together. I am excited for what comes next.
1
1
18
2,240
Behrooz Ghorbani retweeted

29 Oct 2025
Generalists are useful, but it’s not enough to be smart.
Advances come from specialists, whether human or machine.
To have an edge, agents need specific expertise, within specific companies, built on models trained on specific data.
We call this Specific Intelligence.
It's what we're building at Applied Compute.
We unlock the latent knowledge inside a company, use it to train custom models, and deploy an in-house agent workforce that reports to your team.
We work with sophisticated companies that have already captured early gains from general models, like @cognition, @DoorDash, and @mercor_ai. They’re pulling even further ahead with proprietary in-house agents that don’t need to wait for the next public model release.
Together, we are building and validating models and agents in days instead of months, achieving state-of-the-art performance on customer evals.
Our team has high density and low latency. Our founders all worked on different parts of this problem while they were researchers at OpenAI — @ypatil125 as a key member on the agentic software engineer effort (Codex), @rhythmrg as a core contributor to the first RL-trained reasoning model (o1), and @lindensli as a core contributor on ML systems and infrastructure for RL training.
Two-thirds of the team are former founders, and everyone brings a deep technical background, from top AI researchers to Math Olympiad winners.
We are backed by $80M in funding from Benchmark, Sequoia, Lux, Elad Gil, Victor Lazarte, Omri Casspi, and others. With their support, we are growing the team, scaling deployments, and bringing to market the first generation of agent workforces built on specific models.
In short:
1. We are building Specific Intelligence for specific work at specific companies.
2. That will power in-house agent workforces to support their human bosses.
3. That in turn will unlock AI’s full potential through humanity’s greatest engine of progress: thriving corporations in a free market.

107
60
633
1,056,634
Behrooz Ghorbani retweeted

25 Sep 2025
Understanding the capabilities of AI models is important to me. To forecast how AI models might affect labor, we need methods to measure their real-world work abilities. That’s why we created GDPval.


Today we’re introducing GDPval, a new evaluation that measures AI on real-world, economically valuable tasks.
Evals ground progress in evidence instead of speculation and help track how AI improves at the kind of work that matters most.
openai.com/index/gdpval-v0
58
182
1,265
1,061,227
Behrooz Ghorbani retweeted

16 Sep 2025
the distance between category leaders and stragglers in frontier AI starts with talent and culture
by the time the revenue and valuation signals show up, it’s too late
10
9
80
7,360
Behrooz Ghorbani retweeted

2 Sep 2025
🚀 We’re hiring at NVIDIA!
Our team is pushing the frontier of LLM / DLM post-training and system optimization. We are looking for exceptional people with large-scale LLM systems experience to join us (full time only).
🔹 Focus areas include:
•Post-training of large models
•Systems for LLM/DLM training & inference at scale
•Efficiency, scaling, and evaluation frameworks of LLMs
At NVIDIA, you’ll work with world-class researchers and engineers on cutting-edge foundation models at unprecedented scale.
👉 If you’re passionate about LLMs, systems, and building the next generation of AI, we’d love to hear from you.
📩 If you’re interested, please send me your CV!
@nvidia #LLM #AI #Systems #PostTraining #DeepLearning
22
33
469
103,499
Behrooz Ghorbani retweeted

27 Aug 2025
In era of pretraining, what mattered was internet text. You'd primarily want a large, diverse, high quality collection of internet documents to learn from.
In era of supervised finetuning, it was conversations. Contract workers are hired to create answers for questions, a bit like what you'd see on Stack Overflow / Quora, or etc., but geared towards LLM use cases.
Neither of the two above are going away (imo), but in this era of reinforcement learning, it is now environments. Unlike the above, they give the LLM an opportunity to actually interact - take actions, see outcomes, etc. This means you can hope to do a lot better than statistical expert imitation. And they can be used both for model training and evaluation. But just like before, the core problem now is needing a large, diverse, high quality set of environments, as exercises for the LLM to practice against.
In some ways, I'm reminded of OpenAI's very first project (gym), which was exactly a framework hoping to build a large collection of environments in the same schema, but this was way before LLMs. So the environments were simple academic control tasks of the time, like cartpole, ATARI, etc. The @PrimeIntellect environments hub (and the `verifiers` repo on GitHub) builds the modernized version specifically targeting LLMs, and it's a great effort/idea. I pitched that someone build something like it earlier this year:
x.com/karpathy/status/188467…
Environments have the property that once the skeleton of the framework is in place, in principle the community / industry can parallelize across many different domains, which is exciting.
Final thought - personally and long-term, I am bullish on environments and agentic interactions but I am bearish on reinforcement learning specifically. I think that reward functions are super sus, and I think humans don't use RL to learn (maybe they do for some motor tasks etc, but not intellectual problem solving tasks). Humans use different learning paradigms that are significantly more powerful and sample efficient and that haven't been properly invented and scaled yet, though early sketches and ideas exist (as just one example, the idea of "system prompt learning", moving the update to tokens/contexts not weights and optionally distilling to weights as a separate process a bit like sleep does).
27 Aug 2025

Introducing the Environments Hub
RL environments are the key bottleneck to the next wave of AI progress, but big labs are locking them down
We built a community platform for crowdsourcing open environments, so anyone can contribute to open-source AGI
252
852
7,306
949,339

25 Jul 2025
Huge congratulations to @AIatMeta and to @shengjia_zhao! Shengjia is one of the most brilliant and kind researchers I’ve had the privilege to work with.
25 Jul 2025

We're excited to have @shengjia_zhao at the helm as Chief Scientist of Meta Superintelligence Labs. Big things are coming! 🚀
See Mark's post: threads.com/@zuck/post/DMiwj…

2
814
Behrooz Ghorbani retweeted

19 Jul 2025
To summarize this week:
- we released general purpose computer using agent
- got beaten by a single human in atcoder heuristics competition
- solved 5/6 new IMO problems with natural language proofs
All of those are based on the same single reinforcement learning system
43
111
1,253
173,130
19 Jul 2025
Congrats to @alexwei_ , @SherylHsu02 , @polynoamial , and the team for this truly remarkable result! It's a clear example of the rapid pace of AI progress!
19 Jul 2025

1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).

1
537