

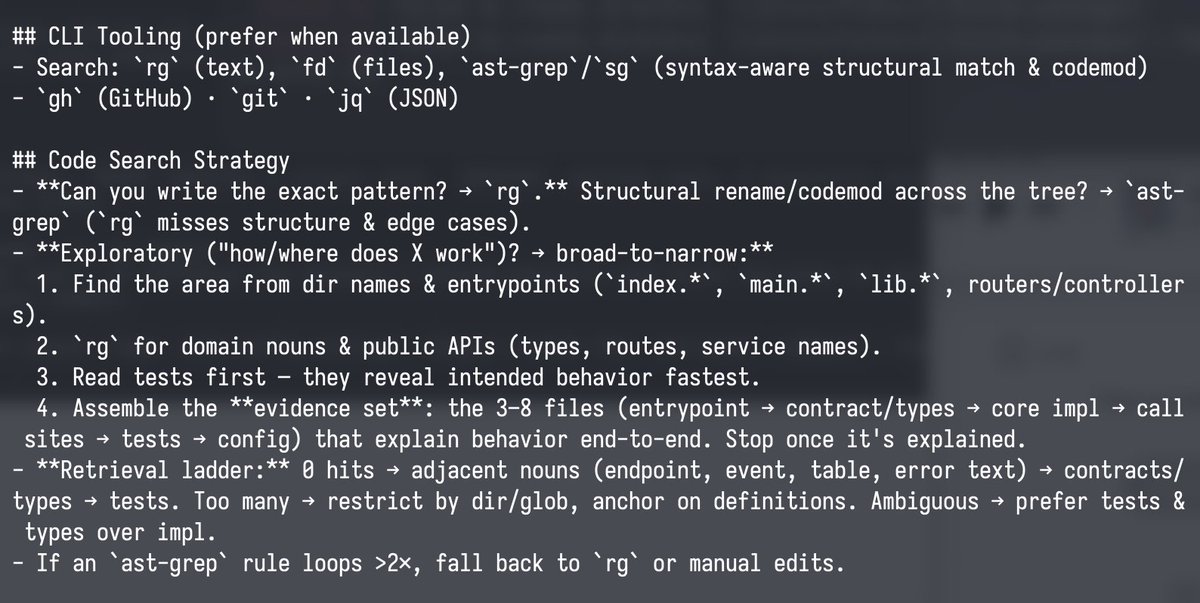








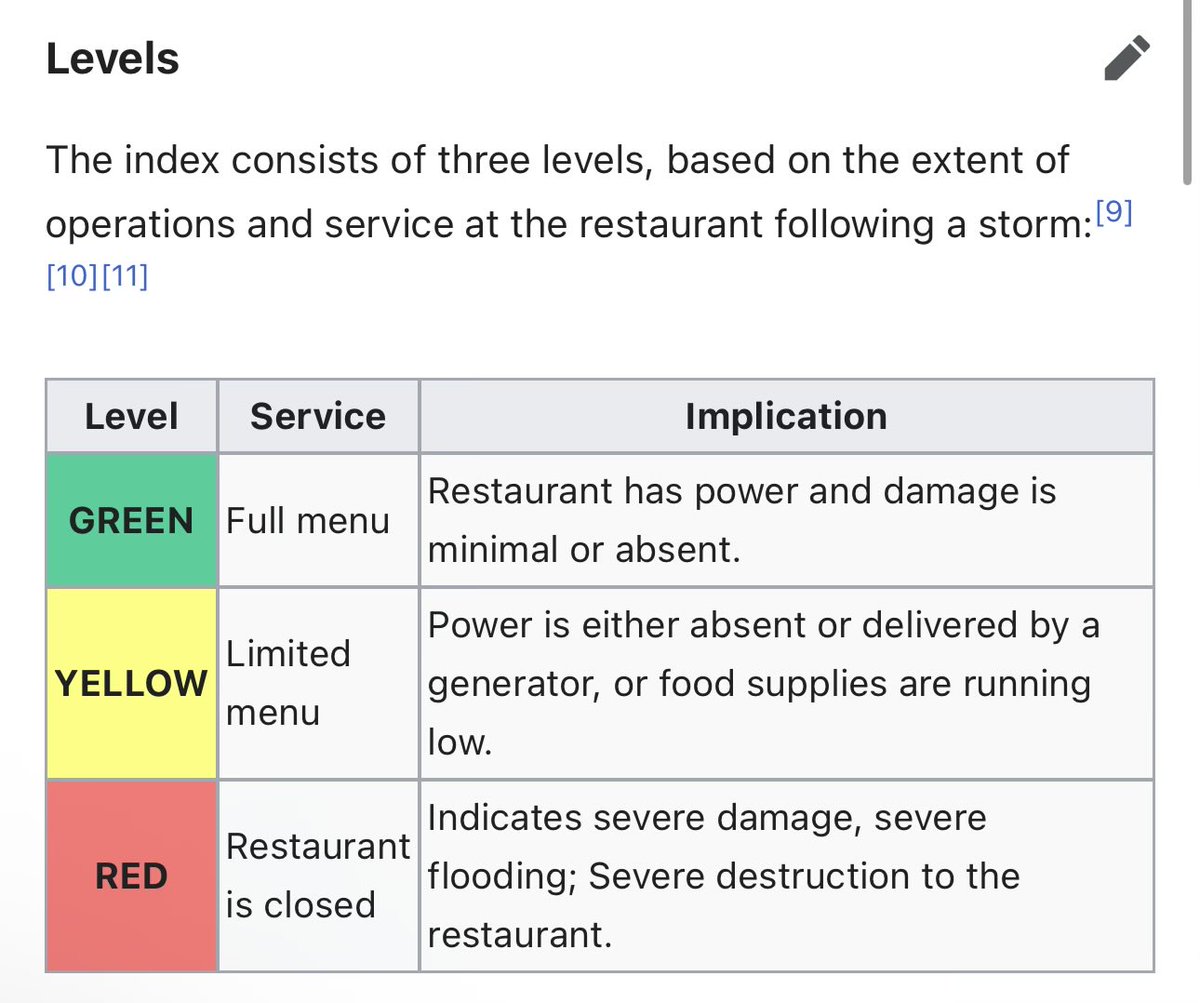




how many devs are out here rawdogging LLMs like this?
May 27

Interesting new SWE/agentic benchmark (DeepSWE) was released yesterday. 113 tasks across 91 repos in 5 languages. Here are interesting things I noticed:
- The evaluation harness (mini-swe-agent) gives every model a single bash tool and the same SI. No vendor editing primitives.
- Eval Prompts are shorter than SWE-Bench Pro, but require 5.5× more code and touch 7 files on average. The idea is to mimic how developers actually talk to agents, short behavioral descriptions, not verbose specs.
- SI describes a specific workflow: find code, reproduce, fix, verify, edge cases, submit. This maps directly onto how the verifier grades, which could bias toward models that follow instructions literally over models that explore more.
- The bash tool is guarded, outputs over 10k chars get truncated. Malformed tool calls get caught and retried with guidance rather than crashing. To prevent to blow up context.
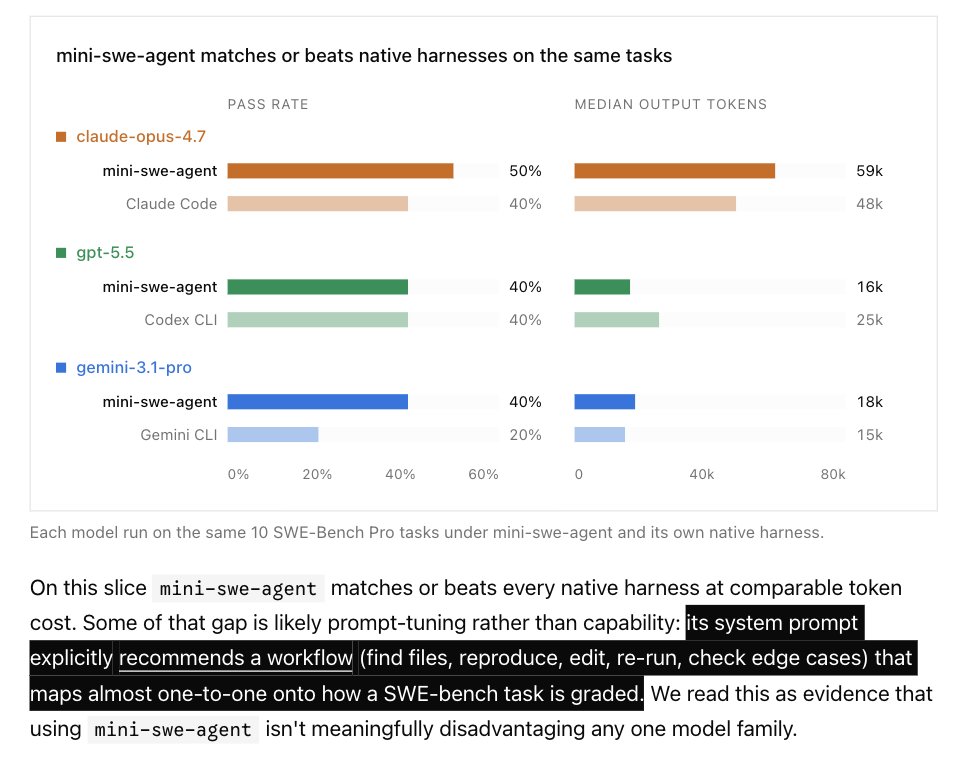
- Mini-swe-agent claims to match or beat 1P harnesses on the same tasks. Claude Opus scored 10pp over Claude Code. Gemini 3.1 Pro scored 20pp over Gemini CLI.
Would love to see how other harness × model combinations will do, e.g. @cursor_ai, @antigravity, @FactoryAI and how well the eval harness does on more general knowledge work, e.g. GDPval.
Great to see the SWE-agent team keep pushing on both the research and eval side. 🤗

74
When my Claude 5 hour timer refreshes
May 13

i have a feeling that he will be quite good with databases if anyone could put me in touch 🙏🏻
106


Been cooking something with @magicblock for @colosseum
Your financial platform shouldn't be able to see your money. So we're building it.
1
1
198

Agent3 with @Replit mobile is a fun way to destroy work life balance x.com/_vu/status/19664481253…
1
227
looking at @privy_io or @dynamic_xyz, anyone have any strong opinions? main use case is onboarding new users and then building a crypto -> local fiat payment offramp
1
1
120
🔗 github.com/mmulet/term.every…
I don't think our hero is on x, but his github repo has some other fun projects. We need more fun stuff and less "how I used AI to generate $1m ARR" on this app.
69