
Behavioural Data Analyst @ TU Graz
Joined November 2009
- Tweets 1,742
- Following 1,247
- Followers 458
- Likes 2,461
187 Photos and videos











Alberto Barradas retweeted

2 Apr 2023
😒🤦♀️
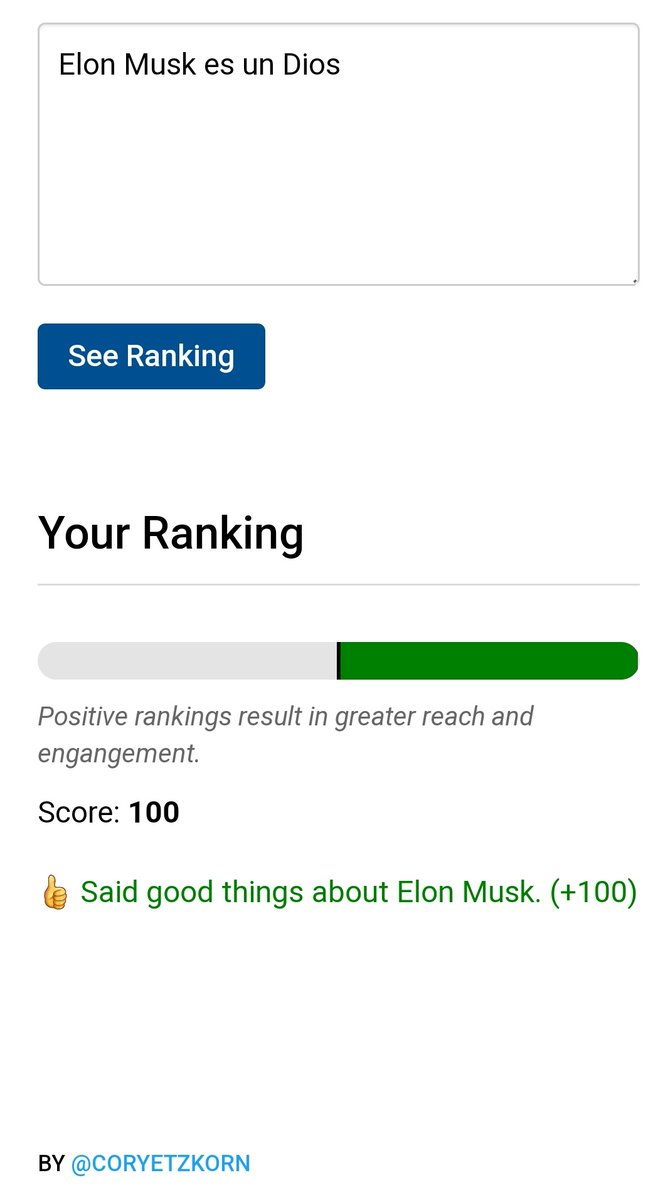
31 Mar 2023

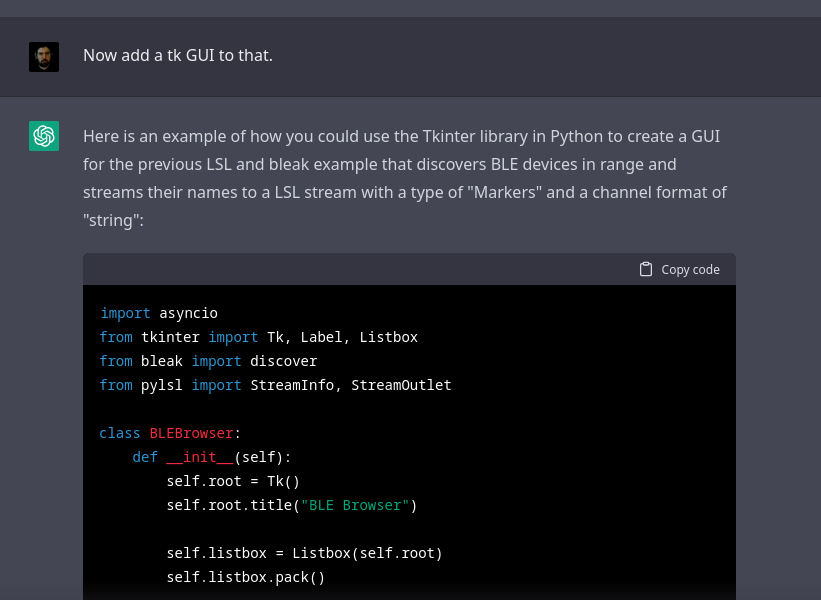
Update from @Twitter engineering!
We open sourced the algorithm this afternoon.
That's great if you know code, but in case you don't, we built a visual tool to help you see how your tweets will rank.
twitter-algorithm.vercel.app…
twitter-algorithm.vercel.app…
9
2
16
6,374
Alberto Barradas retweeted

19 Mar 2023
I tried adding some depth to my Chinampa material, I think this is working out.
I'll integrate it into the project soon #b3d
10
73
933
54,695
Alberto Barradas retweeted

14 Feb 2023
#Indigital
🔴Les invitamos a estar atentos este próximo #21defebrero ya que estaremos presentando las #cápsulasradiofónicas de la #campañaradiofónica #TamalesDigitales en distintas #radios oaxaqueñas.

1
27
42
3,293
Alberto Barradas retweeted

18 Feb 2023
Geochicas y @NosotrasParamos estamos de nuevo este año registrando las acciones alrededor del #8M (#8M2023) en un mapa colaborativo. Aquí el anterior u.osmfr.org/m/411188/.
¡Mánden aquí 👇 sus acciones planeadas con ubicación exacta y las iremos sumando!

12
30
46
8,220
Alberto Barradas retweeted

23 Feb 2023
Since the topic of model naming was brought up, here's a relevant #ThrowbackThursday now with the watermark redone to be less conspicuous.

13
71
665
65,843
Alberto Barradas retweeted

22 Feb 2023
Listening in to this and we're restarting the conversation around AI bias with the same broken talking points about 1) how AI cannot be intrinsically biased 2) it's purely about amplification of human biases and 3) fairness through unawareness. We need to do so much more outreach

1
1
3
1,195

The best way to keep AI safe is to make sure that it is openly available to the general public. Imagine AI as superpowers. We do not want superpowers to be exclusively controled by big corporations and Nations States. They should be democratized and decentralized.
7
72
175
14,520


3
20
209
Alberto Barradas retweeted

12 Dec 2022
OpenViBE 3.4.0 is here! 🧠💻
Very pleased to see some of my contributions included in this version, most notably major updates to the #Connectivity box.
See the full release announcement: openvibe.inria.fr/forum/view…
#BCI @Inria @inria_paris @ParisBrainInst @AramisLabParis
1
4
6
Alberto Barradas retweeted

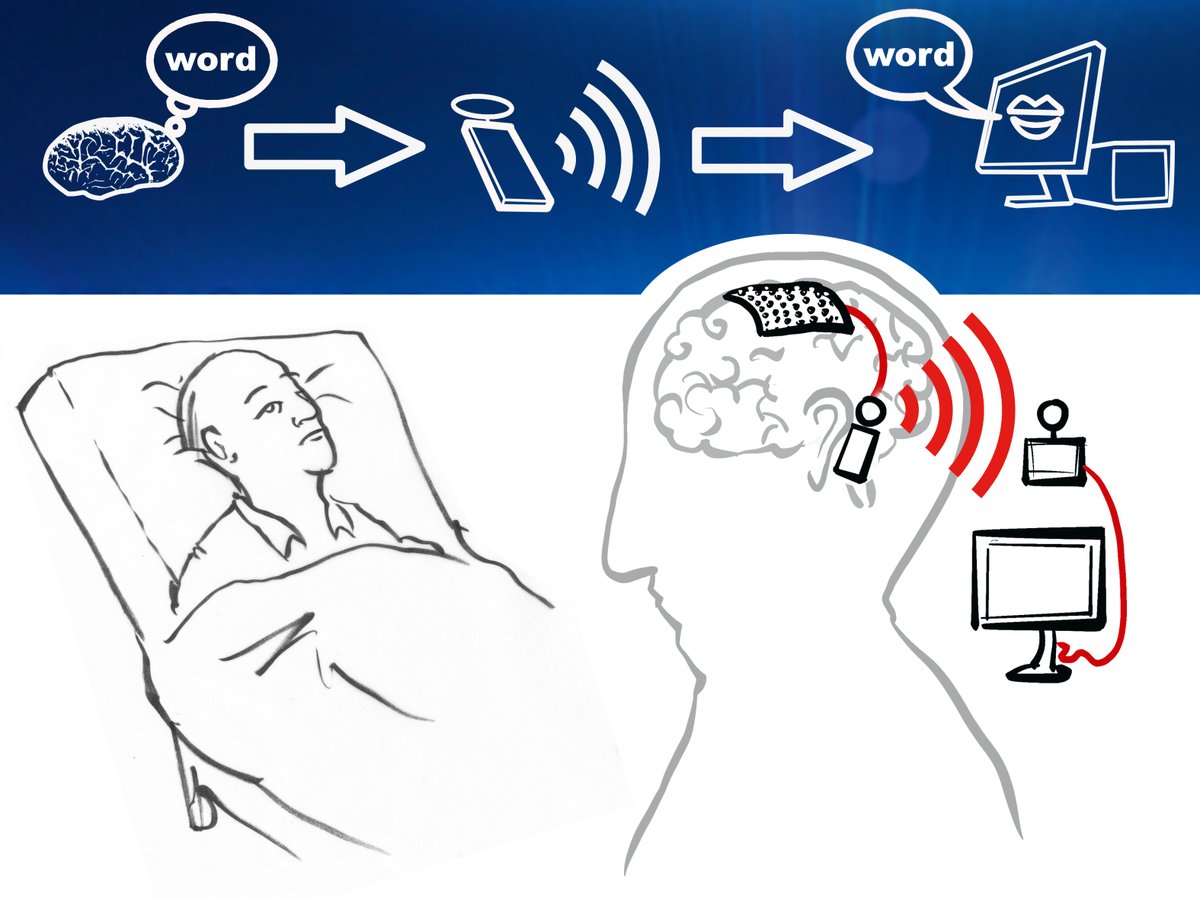
7 Dec 2022
Travelling back from Genéva the the @Wysscenter from our @EUeic Pathfinder INTRECOM project kick-off meeting. Was great to start that wonderful project!
UMC Utrecht, CorTec @tugraz @tugraz_csbme @GrazBCI
1
7
12
Alberto Barradas retweeted

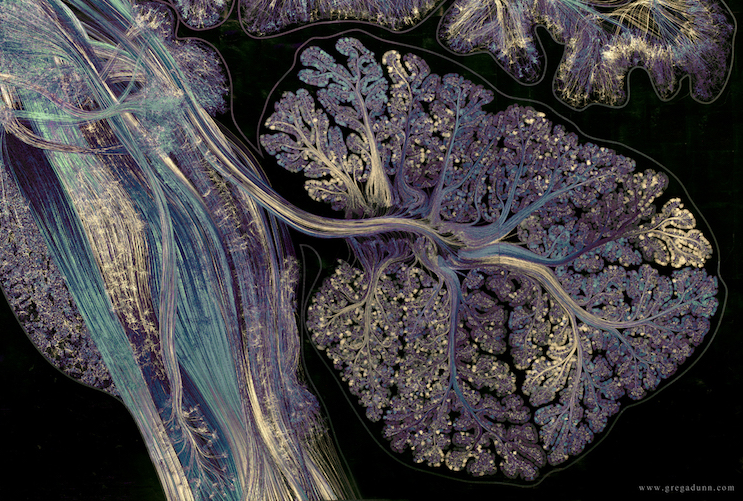
6 Dec 2022
Cerebellum has over 50% of the total number of neurons in the brain:
#neuroscience by G. Dunn
34
573
4,568

28 Oct 2022
Feeling inspired to continue working on human and humane ecosystems of #mutualist interactions with #AI.
Thanks to @JimSpohrer for sharing his inspiring talk, relevant references, and thinking frameworks. @metroxraine
1
4

Quantum computing has attracted the attention and sparked the imaginations of people around the globe.
Let us welcome you to Understanding Quantum Information and Computation, a free course on quantum computing explained at a detailed, mathematical level.
Coming November 1st
6
120
506
Alberto Barradas retweeted

11 Oct 2022
Stable Diffusion VR
Real-time immersive latent space. 🔥
Small clips are sent from the engine to be diffused. Once ready, they're queued back into the projection.
Tools used:
deforum.github.io
derivative.ca
#aiart #vr #stablediffusionart #touchdesigner #deforum
130
757
3,766
Alberto Barradas retweeted

5 Oct 2022
Still wonder why folk don’t believe me when I tell them we will be real time on generative media creation in a few years, check out the ramp in capability we are seeing already.
Going to be some even more interesting stuff as we go into 2023, most exciting area in tech.
5 Oct 2022

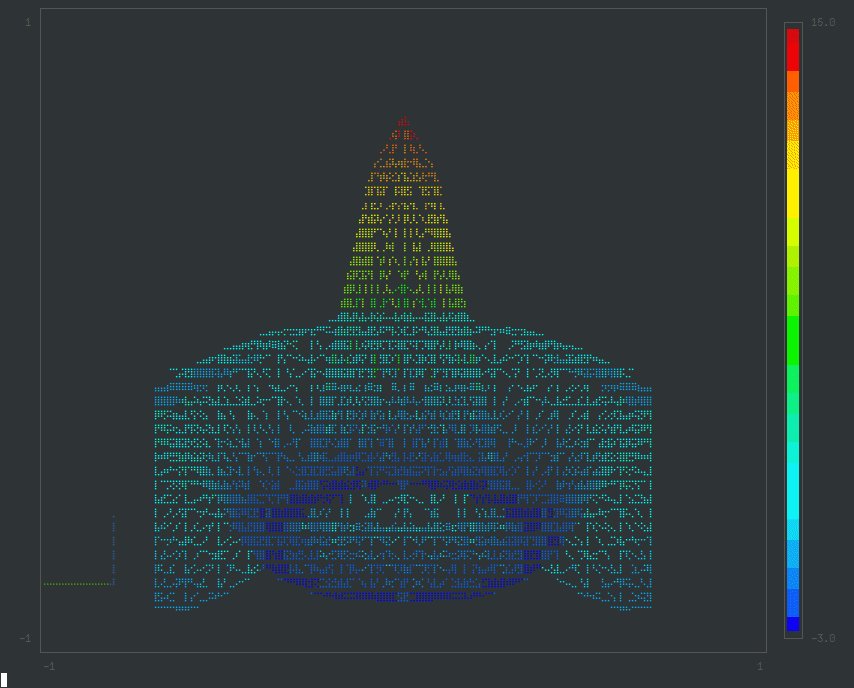
2/ Our approach proposes a new way to learn compact video representations using causal attention in time. We use a bidirectional masked transformer to generate video tokens from text. This scales really well! We can generate 30-second videos (128x128 at 8fps) in 22 seconds!
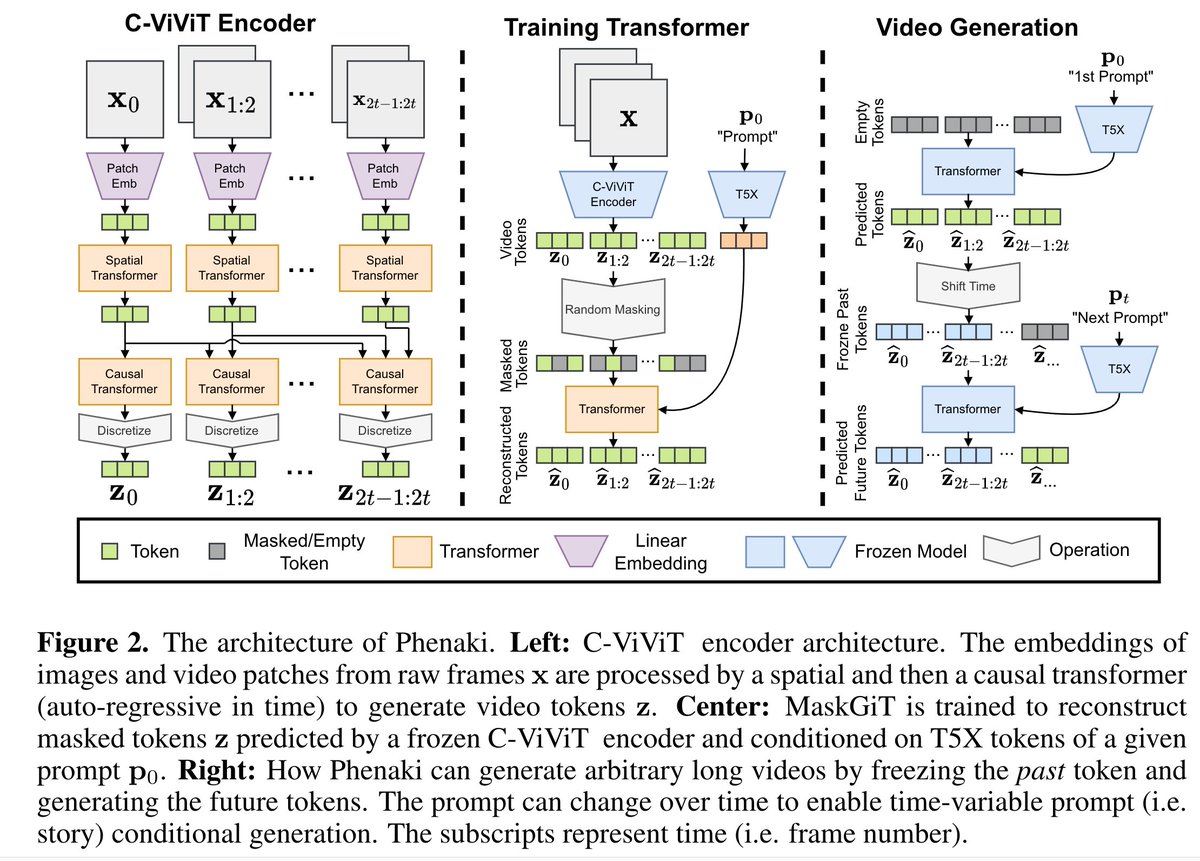
ALT Architecture description
14
59
486
Alberto Barradas retweeted

21 Sep 2022
Exciting news 🎉
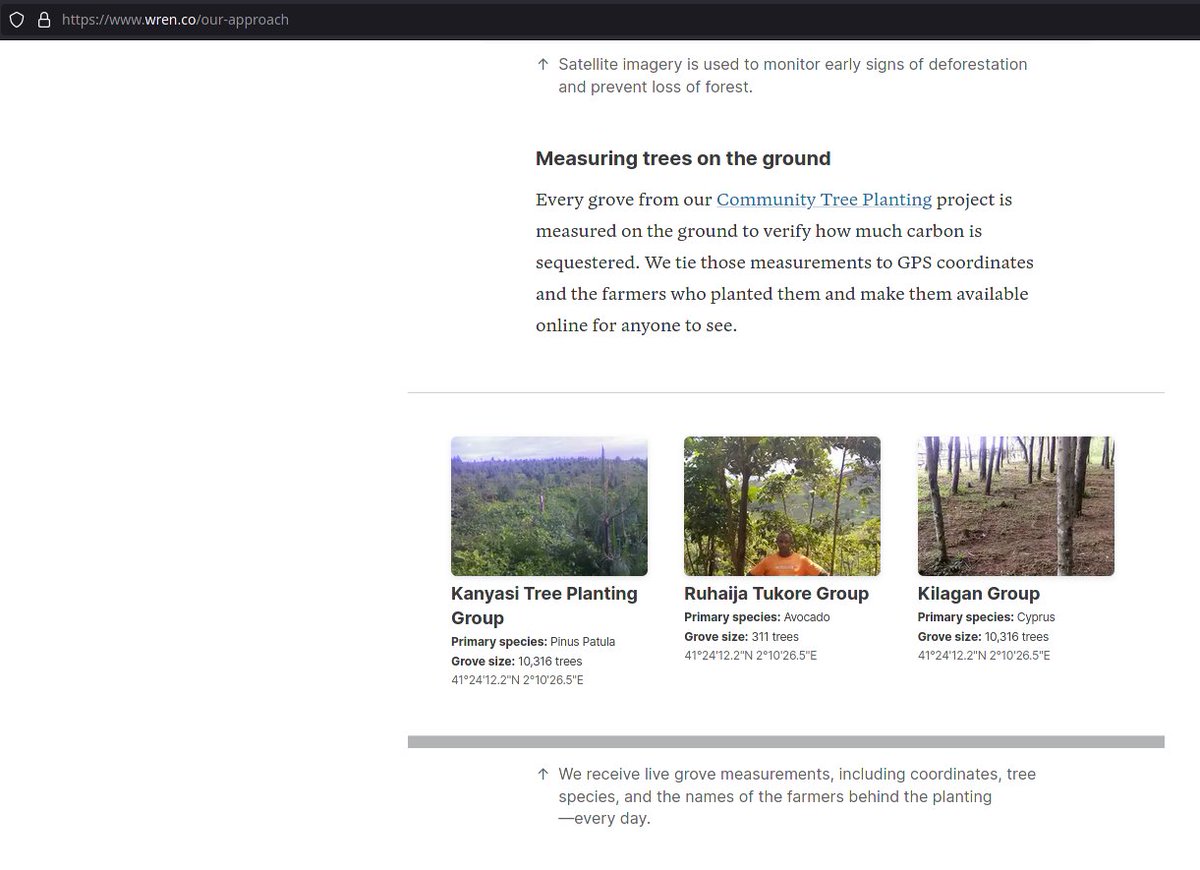
Document Question Answering is now a first class citizen in @huggingface transformers! With just 3 lines of code, you can process any document like so:
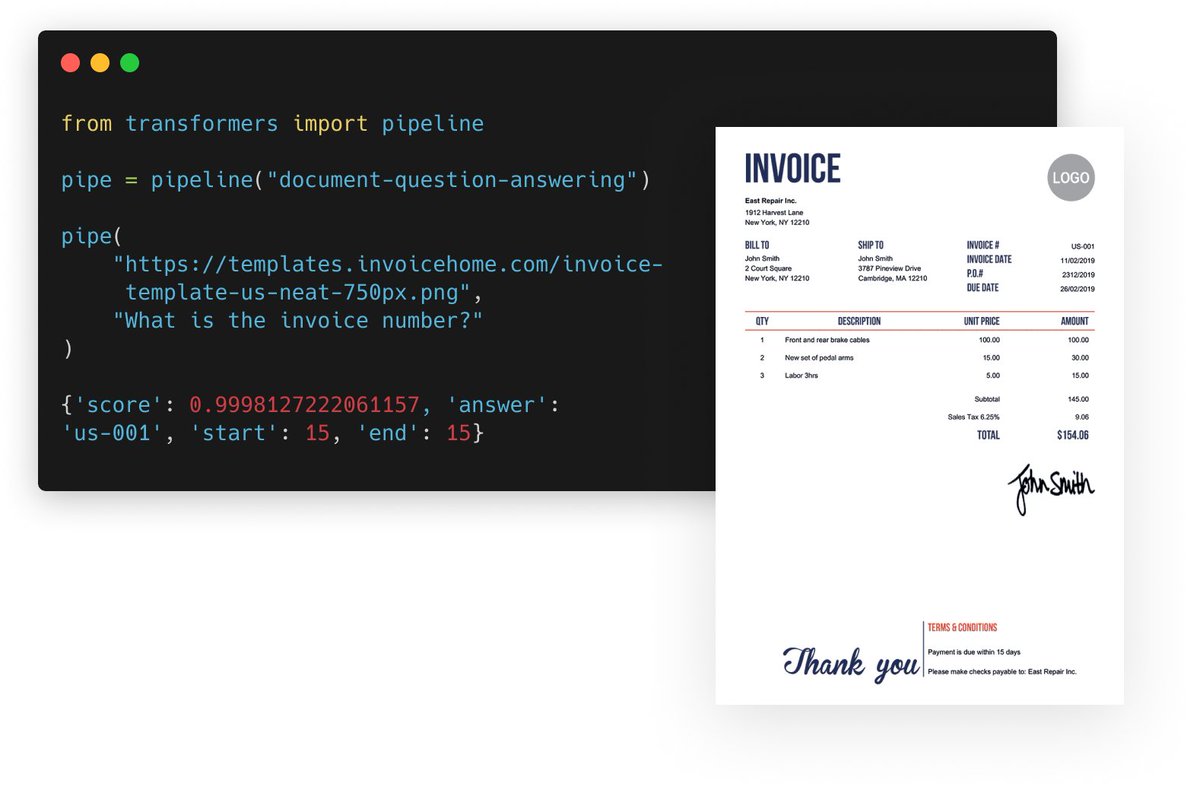
36
228
1,794
Alberto Barradas retweeted

10 Sep 2022
This week ARHeMLab visited Institute of Neural Engineering @Tu Graz, Europe leader in Brain Computer Engineering. Thank you Gernot, Selina, Valeria and Alberto. We had a wonderful and useful lesson of humility. But above all we have found friends. See you in Rome @metroxraine.

2
3
10 Sep 2022
Information is overwhelming these times! I have learned that my roles as an educator are to curate the information I use for my #research and provide to my students. I'm looking into #AITools that can help manage large amounts of information alongside with your biological #brain.
8 Sep 2022

Hopeless back-log of interesting papers daily; I guess all this work is not really for us - for future AIs with bandwidth to read them? What happens when they start writing papers too? Is it inevitable, that no matter their cognitive power, academics are doomed to be overwhelmed?
1