
Blue collar financial economist (codes, debugs, daily) @federalreserve. openassetpricing.com. Bitter Lesson Pilled. 🇺🇸! Views are my own.
Joined January 2016
- Tweets 1,689
- Following 547
- Followers 5,383
- Likes 8,832
382 Photos and videos













Pinned Tweet

Apr 21
I've revised the AI-generated "Hedging the Singularity" paper and algo. My goal was "human as Clockmaker": I set up the agentic loop, and then AI generates a paper good enough to put my name on it.
I couldn't get there. It was both disappointing and relieving. 🧵
5
13
83
14,055
Jun 9
I dedicated a month of my life to this and decided the tech is not there yet (for economics research).
Jun 7

Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore.
You should be designing loops that prompt your agents.
6
2
92
24,976
Jun 9
The "Bitter Angst" should be a corollary of the Bitter Lesson.
The Bitter Lesson: I should work on stuff that harnesses compute.
The Bitter Angst: Others can harness compute far better than I can. Am I competing with them? What am I supposed to do?!
6
470
Apr 22
Most economists lack the tech setup to fully leverage AI (e.g. Docker container w/ R for Claude Code in yolo mode). You can see my setup instructions in the `ralph-wiggum-asset-pricing` repo 🧵
3
13
95
7,630
Apr 22
If git branching or anything else is mysterious to you, you can just ask Claude Code or Codex to help! That's the beauty of these terminal tools. If you can use the terminal, everything has a chat interface.
1
2
693
Apr 21
I've revised the AI-generated "Hedging the Singularity" paper and algo. My goal was "human as Clockmaker": I set up the agentic loop, and then AI generates a paper good enough to put my name on it.
I couldn't get there. It was both disappointing and relieving. 🧵
5
13
83
14,055
Apr 21
Still, I think agentic AI will push the limits of what is "interesting" and what is "true". Questions that can be answered by running an agentic loop will soon be uninteresting. To get published, you'll need to do more. And verifying what's "true" will need both humans AI.
1
1
5
2,018
Apr 21
I detail my failed attempt to replace myself with AI in the preface here: arxiv.org/pdf/2604.16997v1
1
7
2,427
Andrew Chen retweeted

Apr 4
Inspired by @karpathy's post on LLM knowledge bases, and in preparation for a talk on using AI in business research at @SmealCollege, I spent a few hours on Claude Code putting together a knowledge base on the topic. Sharing in case anyone finds it useful:
velikov-mihail.github.io/ai-…
7
20
178
38,803
Mar 8
This is also my experience with multi agent systems. It’s wild and requires extra heavy hand holding for reliability.
But how long will this last?

There's a common assumption in AI right now that if one language model can do a task reasonably well, having several of them collaborate — splitting up the work, checking each other's outputs, debating answers — should do it better.
This paper puts that assumption under a controlled experiment across 180 configurations and finds that the reality is messier and more interesting: multi-agent setups improved performance by up to 81% on some tasks and made things worse by up to 70% on others, with the difference coming down to whether the task can be broken into parallel pieces or whether each step depends on the previous one.
In a financial analysis, one agent can look at regulatory filings while another reads market news and a third examines earnings data — none of them need to wait for the others.
In a Minecraft crafting puzzle, on the other hand, each action changes the inventory that the next action depends on, so the steps have to happen in order and splitting them across agents just adds overhead without any benefit.
The paper fits an equation that predicts which architecture will work best for a new task 87% of the time.
For anyone building or thinking about building systems where multiple AI models work together, this replaces a lot of hand-waving with something concrete.
Read with an AI tutor: chapterpal.com/s/5c02af66/to…
Download the PDF: arxiv.org/pdf/2512.08296

2
7
1,315
Mar 3
Radical view on peer-review: We have to stop pretending we are reading the whole manuscript. AI peer review is still peer review.
It’s happening in software: latent.space/p/reviews-dead
2
9
639
Andrew Chen retweeted

Feb 24
submit your final output at humanxaifinance.org. Let's see how it stacks up against other human and AI processes.
4
5
678
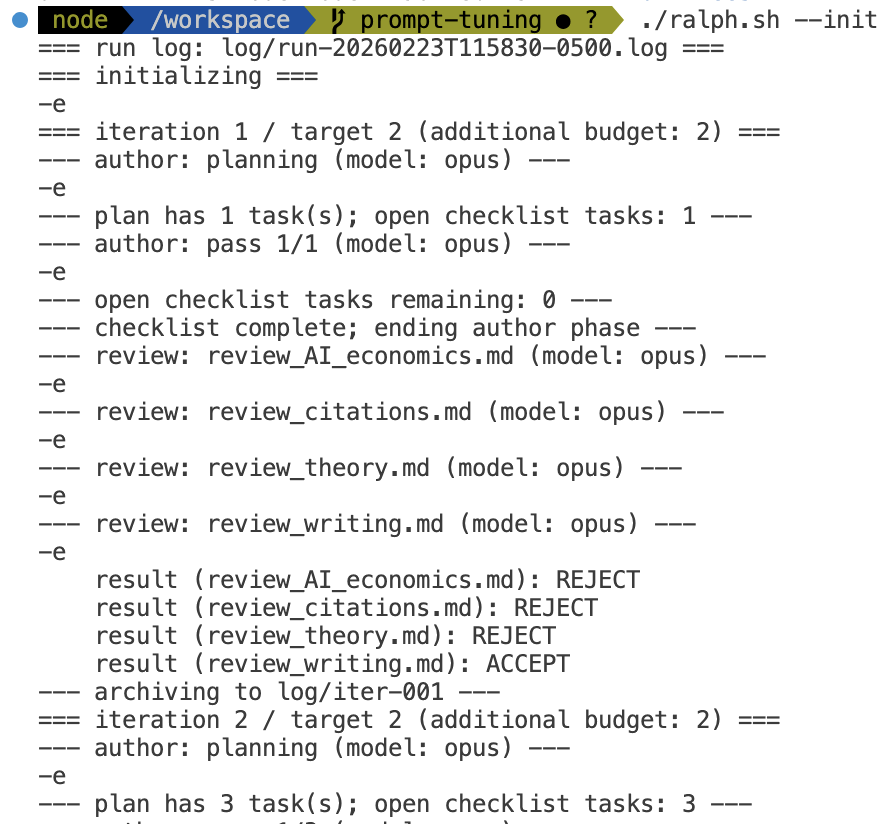
Feb 23
Been working on using the Ralph Wiggum method (@GeoffreyHuntley) to write papers and respond to reviews. Opus improves the paper, Opus reviews, and we repeat until the paper passes the reviews.
Really not sure if this is productive but it sure is entertaining.
6
36
4,745
Feb 20
Hot take🔥: the reason why breathtaking AI advances are not apparent in the lives of normies is... ...because most knowledge work is just telling stories to please gatekeepers.

The financial sector is allegedly a talent sink. But the real talent sink is academia.
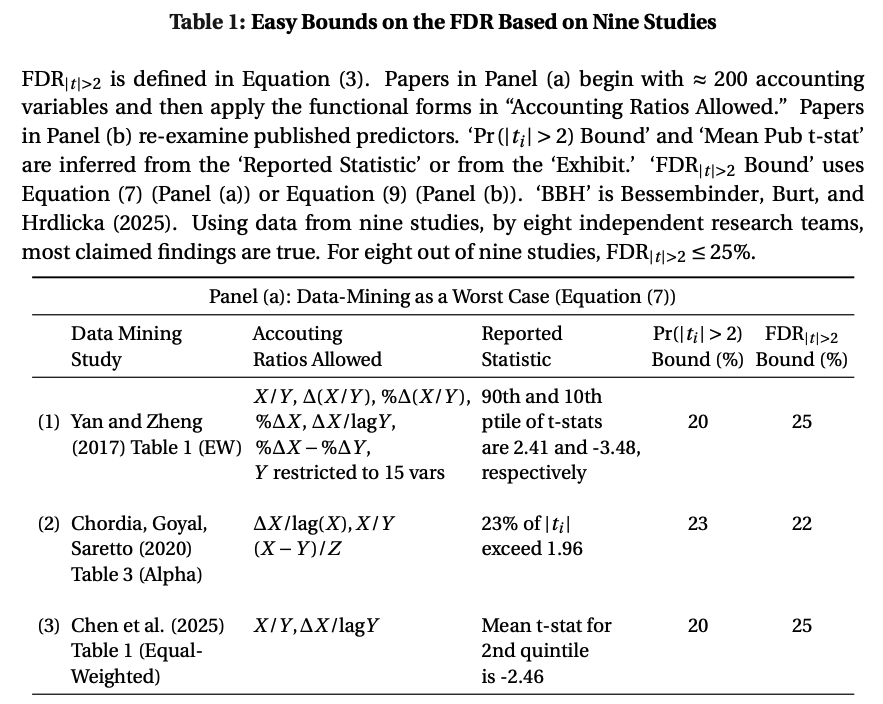
They spend years coming up w math-heavy, theory papers, & what do they have to show for it? Variables w theoretical foundations (ex: "value") do no better out of sample than naive data mining!

4
1
33
5,209