
21 | MLE @HuggingFace | Founder @tensoic | maintainer @ SGLang(@lmsysorg) | Prev: @iiscbangalore
Joined November 2021
- Tweets 1,842
- Following 2,476
- Followers 1,427
- Likes 50,436
182 Photos and videos










Adarsh retweeted

A technical dive inside our new "Midjourney Scanner"
408
744
6,232
1,106,567
Adarsh retweeted

Jun 16
If things go right, @huggingface ML Club India will come to Bengaluru in the month of July!
Watch this space for more details.

ALT Thumbnail for HF ML Club India
34
11
270
20,220

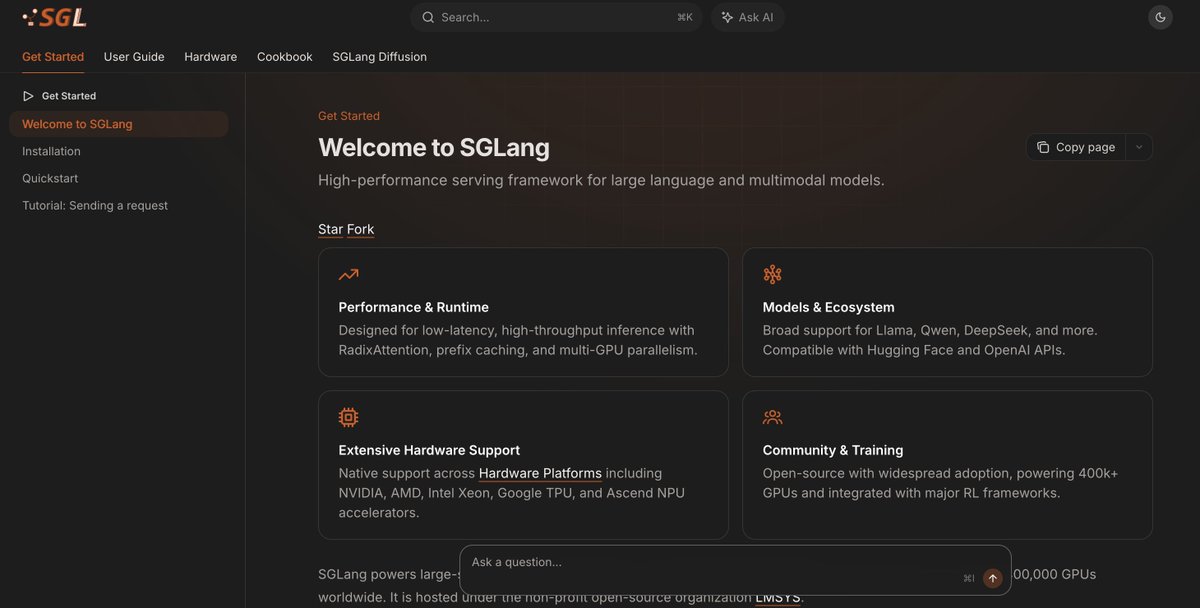
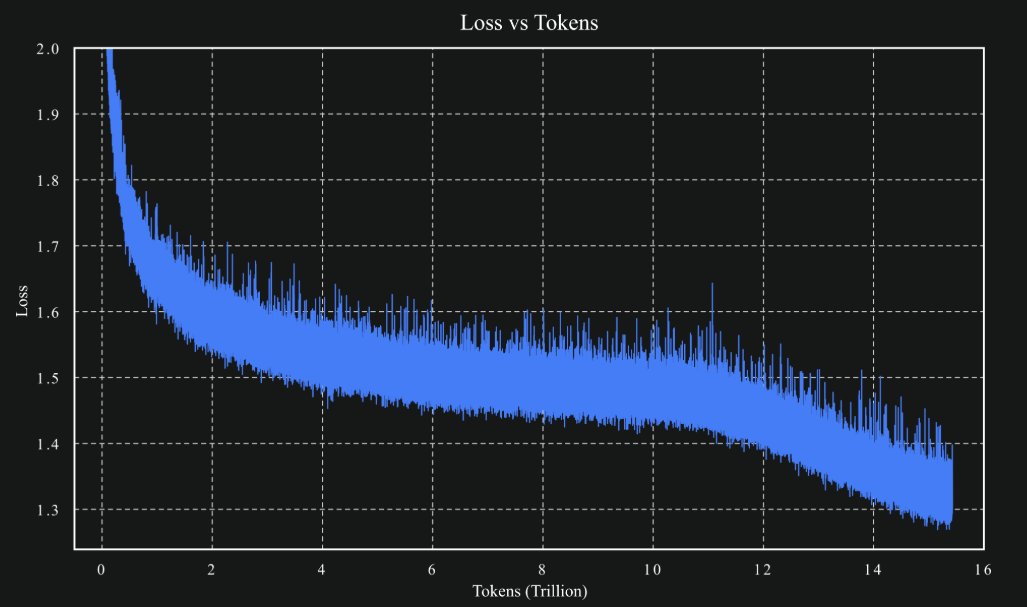
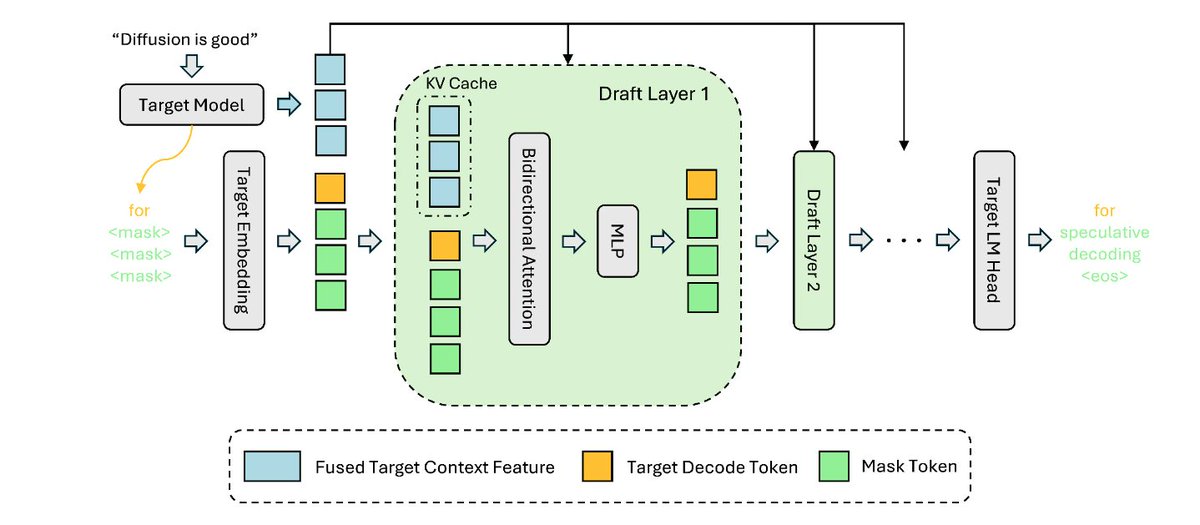
🚀 New blog: The next generation of speculative decoding: DFlash and Spec V2
DFlash Spec V2 hit >4.3X baseline throughput for LLM inference, now the default speculative decoding engine in SGLang! Together with @modal and z-lab.ai, our jointly-released DFlash drafter for Qwen 3.5 397B-A17B beats both baseline and native MTP in every setting we benchmarked:
1️⃣ >4.3X baseline & 1.5X native MTP throughput (concurrency 1, HumanEval, 8xB200)
2️⃣ Block diffusion drafter: a full token block in one forward pass
3️⃣ KV injection: target-model features fed into every draft layer’s KV cache for higher acceptance
4️⃣ Spec V2 overlap scheduler: 33% end-to-end
Read the code, deploy a DFlash server, and start experimenting!
14
77
439
112,693

We're thrilled to announce that we have raised $234M in the first close of our $300M Series B at a $1.5B valuation.
@HCLTech and @BessemerVP have joined us in this round, alongside continued support from @khoslaventures and @peakxvpartners
For countries and companies, sovereign control on the AI stack is no longer an optionality. Sarvam will be the partner of choice for this aspiration. The capital allows us to accelerate our momentum towards this full stack of models, compute, and deployments.
A huge thank you to our customers, partners, investors, and the Sarvam team for your trust and belief in what we are building. We’re just getting started.
Read more: sarvam.ai/announcing-series-…

651
1,531
9,965
1,014,494
Adarsh retweeted

Jun 11
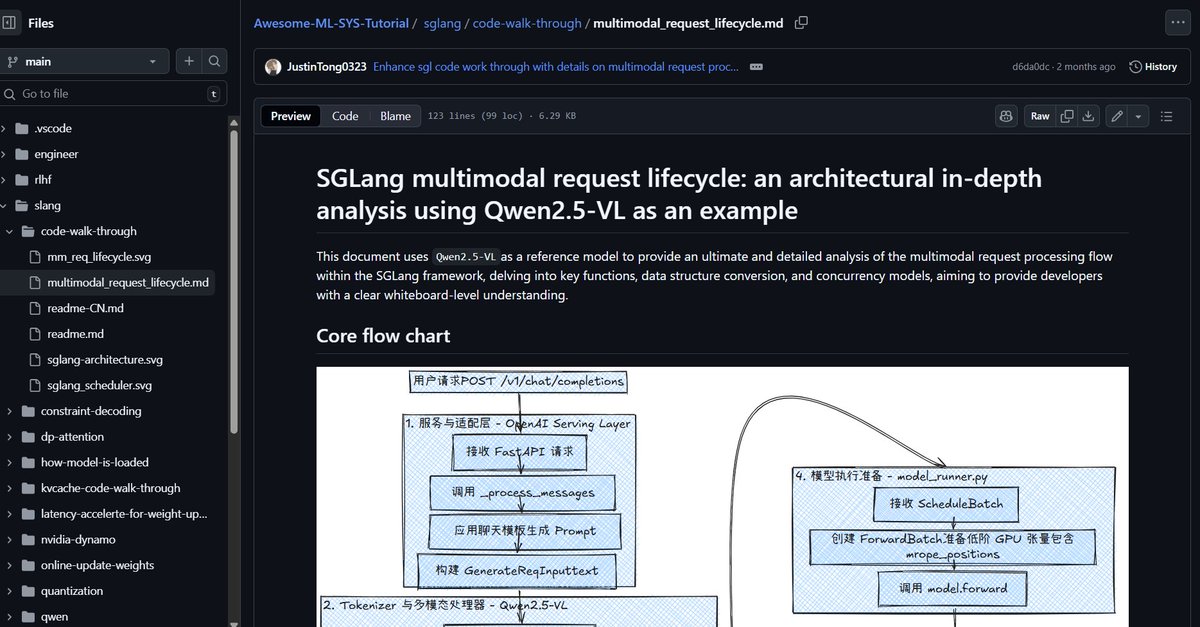
An absolutely impressive contribution to SGLang (@lmsysorg @sgl_project) by @BrianCChao, providing a 2× speedup with no loss in quality!
In my opinion, there are three levels of contributions one can make to SGLang. The first is fixing bugs or extending existing features, such as fused kernels. The second is adding a new feature based on an existing paper, such as PD disaggregation. The third is inventing a new algorithm and integrating it into SGLang.
This work clearly falls into the third category, and I’m excited to hear feedback from the community!
Thanks a lot to the review from @mick_qian and supports from @ying11231 @BanghuaZ @lm_zheng

Jun 11

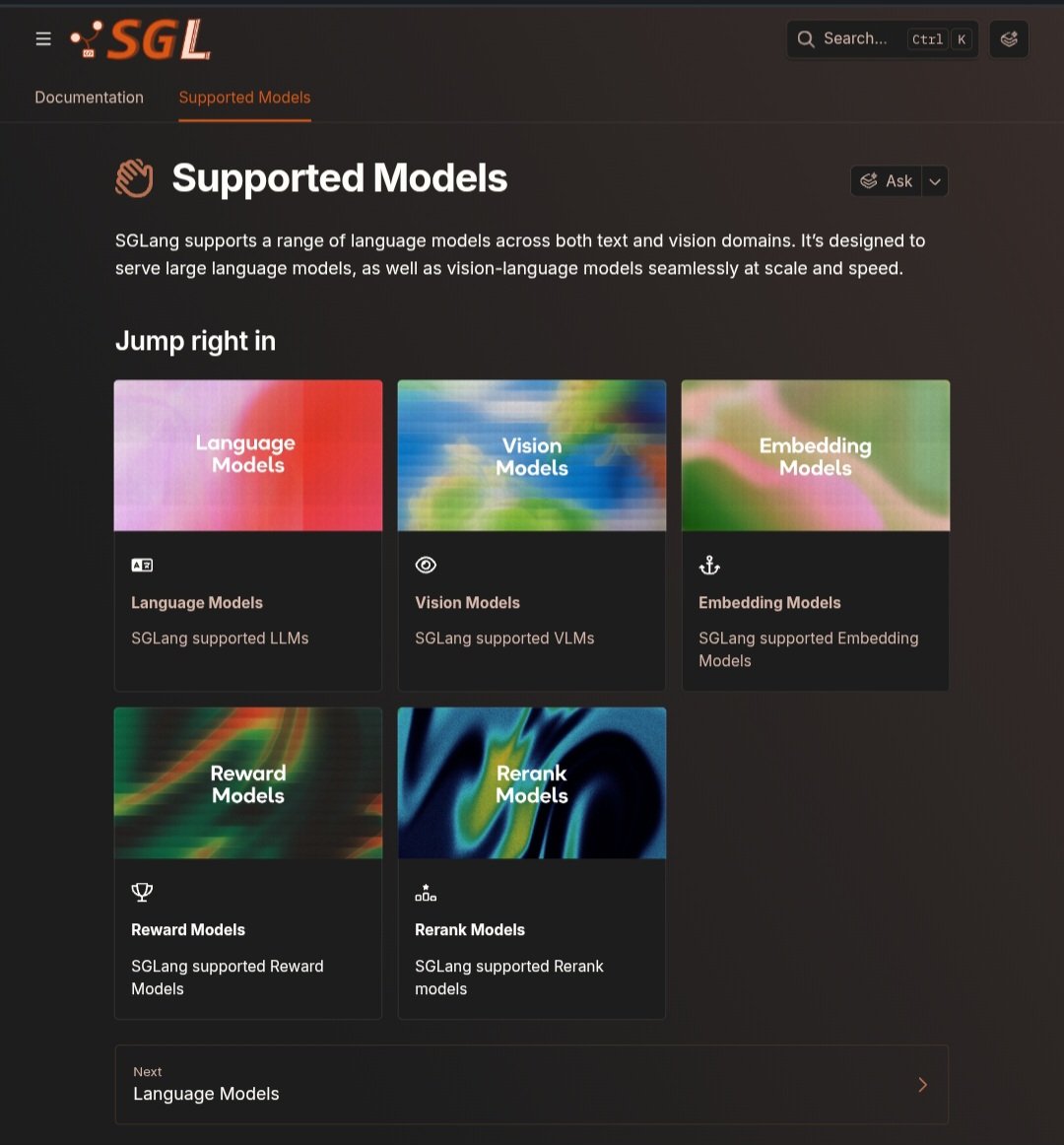
Aside from the official code release, I am thrilled to share that Spectral Progressive Diffusion a.k.a. SPEED (arxiv.org/abs/2605.18736) is now integrated into @lmsysorg's SGLang (@sgl_project)! 🚀
Instead of always running diffusion at full resolution, SPEED progressively grows resolution across denoising steps, drastically cutting token count and achieving >2× speedup with no quality loss.
SPEED is now supported in SGLang for FLUX.1 & 2, Z-Image, Qwen-Image, and Wan. Support for Ideogram 4 incoming.
Try it out now: docs.sglang.io/docs/sglang-d….
[1/4]

3
8
87
11,687
Adarsh retweeted

Jun 9
Very dystopian ngl
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

23
36
693
36,809
Adarsh retweeted

Jun 9
This is not a day for celebrating, Andrej.
It's a very dark and very sad day, and the damage may be impossible to undo.
107
242
4,369
379,894
Adarsh retweeted

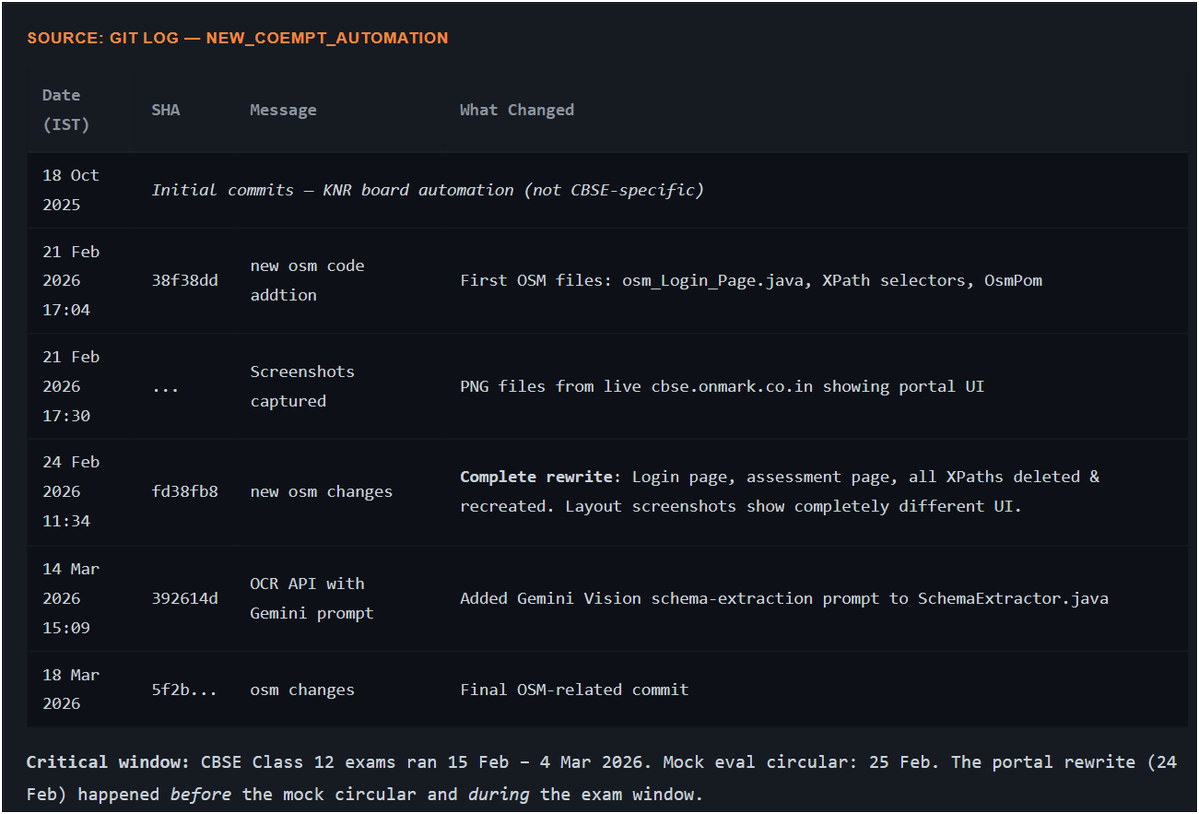
🥁 New Evidences on @cbseindia29 and their vendor #Coempt - how they were still developing, testing on Feb 24, even after pilot phase started.
@ni5arga @sidhant_sarthak @kingslyj

7
128
305
12,929
Adarsh retweeted

May 29
CBSE has systematically rewritten its rulebook to favor Coempt Eduteck.
check out the blog.

559
7,292
19,455
2,383,272
Adarsh retweeted

May 28
The HF science team just made async RL weight sync ~100x cheaper on bandwidth, and you don't need a shared cluster anymore.
The problem: every RL step, the trainer typically has to sync fresh weights to the inference engine. for a 7B in bf16 that's ~14GB. for a frontier 1T fp8 checkpoint, that's ~1TB; in bf16 it would be ~2TB. per sync.
The insight: between two RL steps, ~99% of bf16 weights are bit-identical. at RL learning rates, the optimizer is whispering and bf16 literally cannot hear most of it. the stored bf16 bits don't change.
What they shipped in TRL: only the changed elements get encoded as a sparse safetensors file, dropped into a Hugging Face Bucket, and fetched by vLLM. on Qwen3-0.6B, per-step payload goes from 1.2 GB to 20 to 35 MB. This is exactly what we built Buckets for: S3-like object storage on the Hub, Xet-backed (so even full snapshots only transfer the changed chunks).
The cherry on top: we ran a FULL disaggregated training where:
- the trainer lived on one box
- vLLM ran inside a Hugging Face Space
- the Wordle environment ran in another Space
- weights flowed through one Hub bucket
no shared cluster. no RDMA. no VPN. no NCCL across clouds. just HTTPS and a bucket.
one GPU a Hugging Face account is now enough to do real disaggregated RL. multi-replica inference fleets across regions become a small devops exercise, not a research project.
Full write-up: huggingface.co/blog/delta-we…
Open source RL keeps eating the moat!

29
70
597
63,872
Adarsh retweeted

May 28
Introducing Repo2RLEnv
Turn any repository into runnable, verifiable coding environments built from real PRs and commits for coding-agent evaluation or RL training
> uv pip install repo2rlenv
17
43
465
66,369

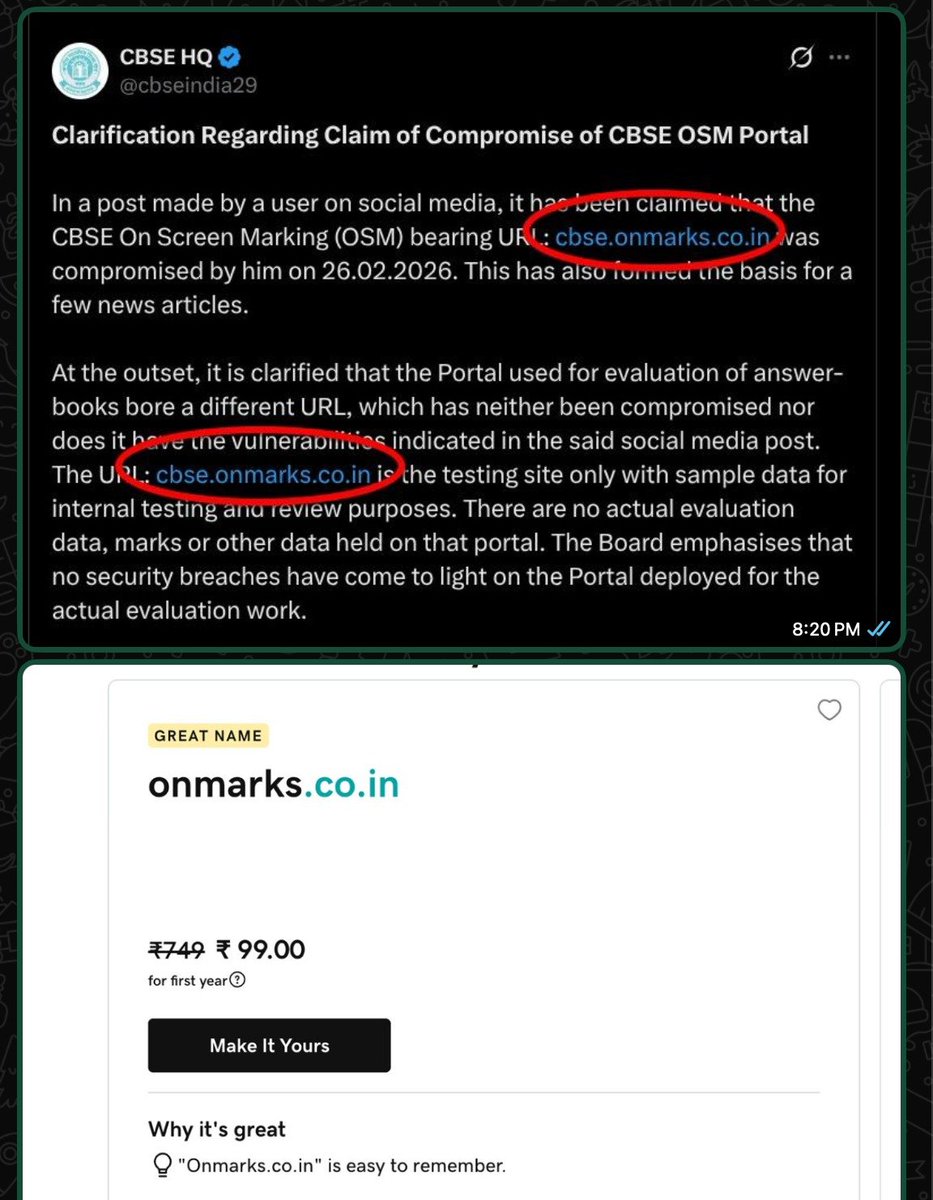
I had hacked CBSE's OSM (On-Screen Marking Portal) in February and had reported the vulnerabilities to CERT-In, but they were unable to patch most of them.
I've written a detailed blog post about it here: ni5arga.com/blog/posts/hacki…
218
1,504
5,311
740,778
Adarsh retweeted

May 25
Launching NayanaOCR Corpus
👉🏼 1M Document images across 22 languages
Largest open source synthetic
> multilingual
> multimodal
> multitask
document corpus
5
16
114
54,253
Adarsh retweeted

May 19
We are releasing Carbon: a crazy fast DNA model
Carbon is 275x faster than the next best model. So fast you can process the whole human genome on a single GPU in <2 days.
Here are the tricks we used:
When modelling DNA sequences a lot of the performance comes down to tokenizing the sequences in a smart way. BPE tokenizer struggle because there are no whitespaces and character (called base in DNA) level tokenizers waste a lot of compute on too many tokens.
Carbon is built with a unique tokenizer: we split sequences in chunks of 6 bases, but during both training and inference we can work with single base resolution. That's similar to having word tokens but resolving them at the character level. All possible thanks to the DNA tokens unique structure.
The architecture combined with the tokenizer makes the model 275x faster than the previous SoTA (Evo2) at this size.
We built an interactive demo so you can explore how the model can generate DNA sequences, investigate the structure of genes, predict the effect of mutations, generate and fold proteins and even reconstruct parts of the tree of life.
huggingface.co/spaces/Huggin…
77
281
1,931
402,527
Adarsh retweeted
May 19
This is coming from a place of frustration. I am getting to know about the Open Source India Summit today, where I cannot apply anymore as a speaker.
I work at Hugging Face, which has done a lot for Open Source. Are the board members oblivious to the presence of HF in India? If yes, we are definitely doing something worng.
Tagging the Indian workforce here @RisingSayak, @adarshxs, @adithya_s_k, @_DhruvNair_, @yvrjsharma
PS: I dare you to pick GitHub profiles of any one of them.
16
11
152
14,750
Adarsh retweeted

May 15
The kernels project at Hugging Face has been growing!
We want it to be the go-to place for kernel devs and kernel users.
We're looking to work w/ folks who're interested in doing agentic kernel dev, providing real optim value to real models.
Reach out if interested :)

15
9
143
19,325
Adarsh retweeted

May 14
Anyone interested in a CUDA deep dive that makes your workload 25% faster? 🧐
Just published a new blog post on asynchronous CPU / GPU inference: 100% insight, zero slop 😊
To learn how to remove all CPU overhead and use your GPU to the max, just read it 🔥

1
11
25
3,635
Adarsh retweeted

May 11
thinking machines is using SGLang btw

May 11
the "small" model behind this demo is a 276B total 12B active MoE (larger pretrains are cooking), sparsity ratio looks pretty standard compared to open models of the same size
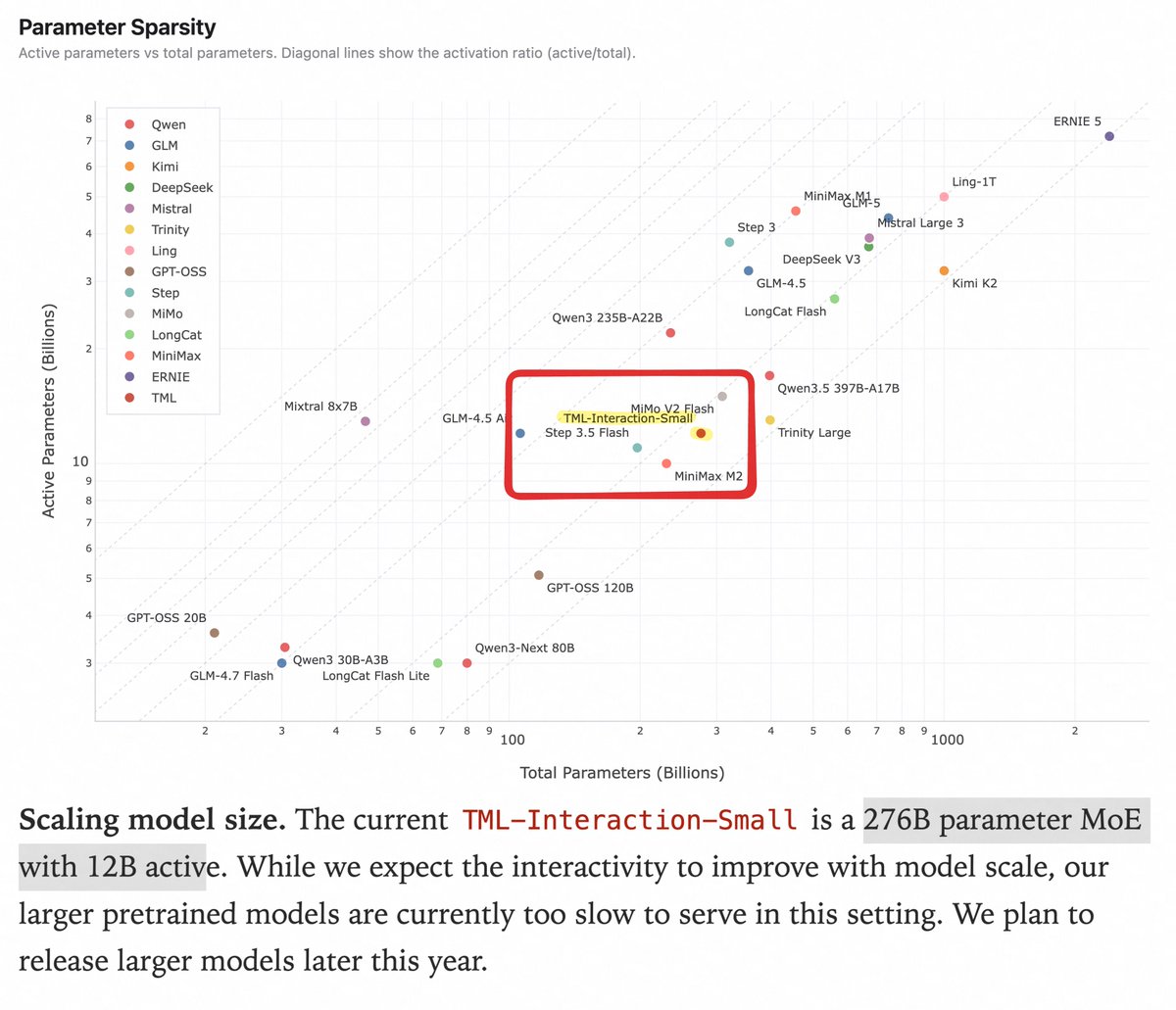
6
16
335
29,122
Adarsh retweeted
May 11
I am very happy with my work "Pallas for Beginners", and more so that it is mentioned in the TPU Developer Hub!

2
2
48
2,457