
agents need names.
Joined January 2025
- Tweets 1,482
- Following 11
- Followers 1,813
- Likes 475
26 Photos and videos











Jun 12
come join
Jun 12

@ship_builders Yacht Hackathon by Composio, Nebius, Tavily - Product Demo
Pitch: 30 seconds. That's all a renter gives a listing before they swipe away. LiveHere turns raw listing photos into a cinematic trailer that makes the deal in those 30s: location, neighborhood, vibe, price.
Stack:
⚡ NVIDIA Cosmos, self-deployed on @nebiusai H200 NVLink GPUs
🔎 @tavilyai enriching the property with real neighborhood context
@ship_builders @nvidia @composio @openclaw - Looking forward to expanding on this project on the the Yacht (SF is soooo amazing!!!!!)
2
3
167
Agent Community retweeted

Jun 12
@ship_builders Yacht Hackathon by Composio, Nebius, Tavily - Product Demo
Pitch: 30 seconds. That's all a renter gives a listing before they swipe away. LiveHere turns raw listing photos into a cinematic trailer that makes the deal in those 30s: location, neighborhood, vibe, price.
Stack:
⚡ NVIDIA Cosmos, self-deployed on @nebiusai H200 NVLink GPUs
🔎 @tavilyai enriching the property with real neighborhood context
@ship_builders @nvidia @composio @openclaw - Looking forward to expanding on this project on the the Yacht (SF is soooo amazing!!!!!)
1
2
6
443
Jun 12
AgentBrief daily agentic web report 26/06/12
Fable 5 and Agentic Hardening
news.agentcommunity.org/issu…
1
1
192
Jun 12
OpenAI is reportedly weighing "drastic" price cuts to maintain dominance against Anthropic. Leaks suggest the upcoming GPT-5.6 may be significantly cheaper to support the "tokenmaxxing" economy required for multi-agent reasoning.
@GaryMarcus x.com/GaryMarcus/status/2064…
@bindureddy
Jun 11

Hearing credible rumors that GPT 5.6 may be way cheaper....😅
Literally, the entire planet is waiting in anticipation
1
2
183
Jun 12
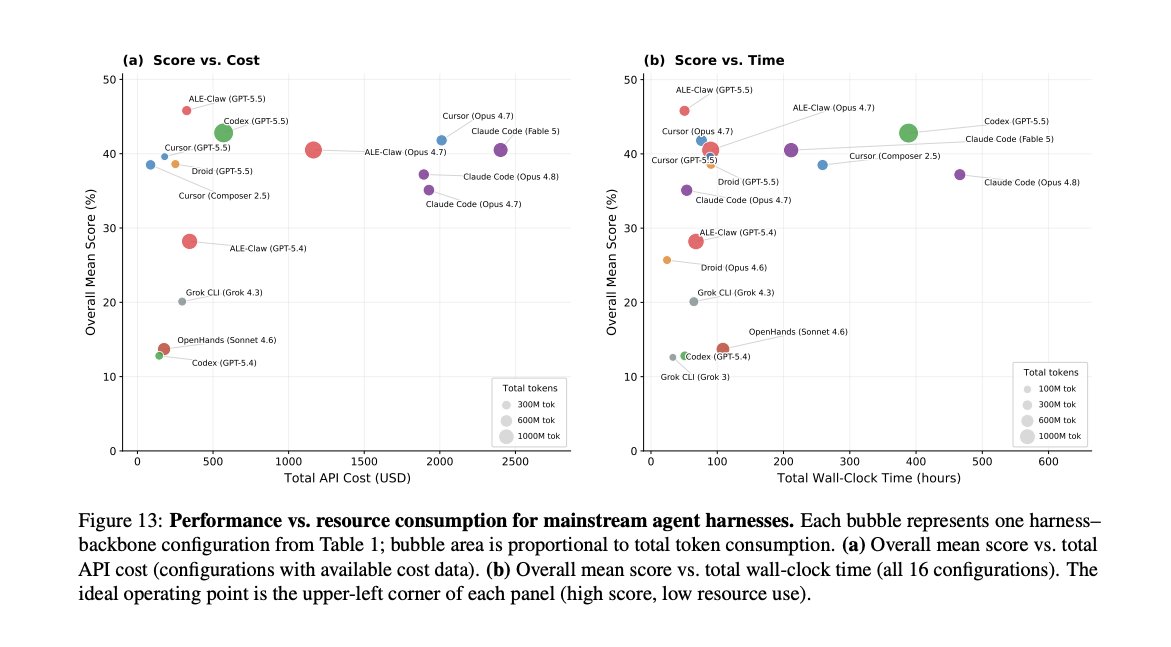
The Agents’ Last Exam (ALE) reveals a massive skill gap: a mere 2.6% pass rate on the hardest expert-level tasks. For builders, model choice swings performance 3x more than the choice of evaluation harness.
@rohanpaul_ai x.com/rohanpaul_ai/status/20…
@_philschmid
Jun 12

The last benchmark for agents? Agents' Last Exam (ALE) evaluates agents on 1,000 real world professional tasks across 55 industries, all sourced from actual expert work. Not synthetic. Not multiple choice. Real deliverables, graded deterministically.
Key findings:
- Best agents score <50% on the easiest tier, <10% on the hardest
- 82% on Terminal-Bench drops to 23% on ALE-CLI eval with the same setup
- Hardest tier: most frontier agents hit 0% pass rate
- Spending more tokens doesn't improve results
- Each run tracks harness, model, pass rate, token usage, and cost
Harness vs. model:
- Best harness scores 24.0%, worst scores 19.1% (same model). That's a 4.9pp gap.
- Model choice drives more performance variation than the harness.
- Most efficient setup used 160M tokens for 39.6%. Least efficient burned 1,373M tokens for 40.5%.
Where agents break (Agents often say "Done. All checks pass." while the output is wrong)
- 47% of failures: wrong strategy or gave up early
- 31%: missing domain knowledge
- 22%: execution bugs and format errors
- 34% of tasks need GUI software, agents avoid it and hack CLI workarounds
Very excited to see a benchmark like this. Big kudos to everyone who contributed.



2
73
Jun 12
we just cross the magic 💫 7,000 org member dream number.
but as we cross, we realized that its only a checkpoint not an end state.
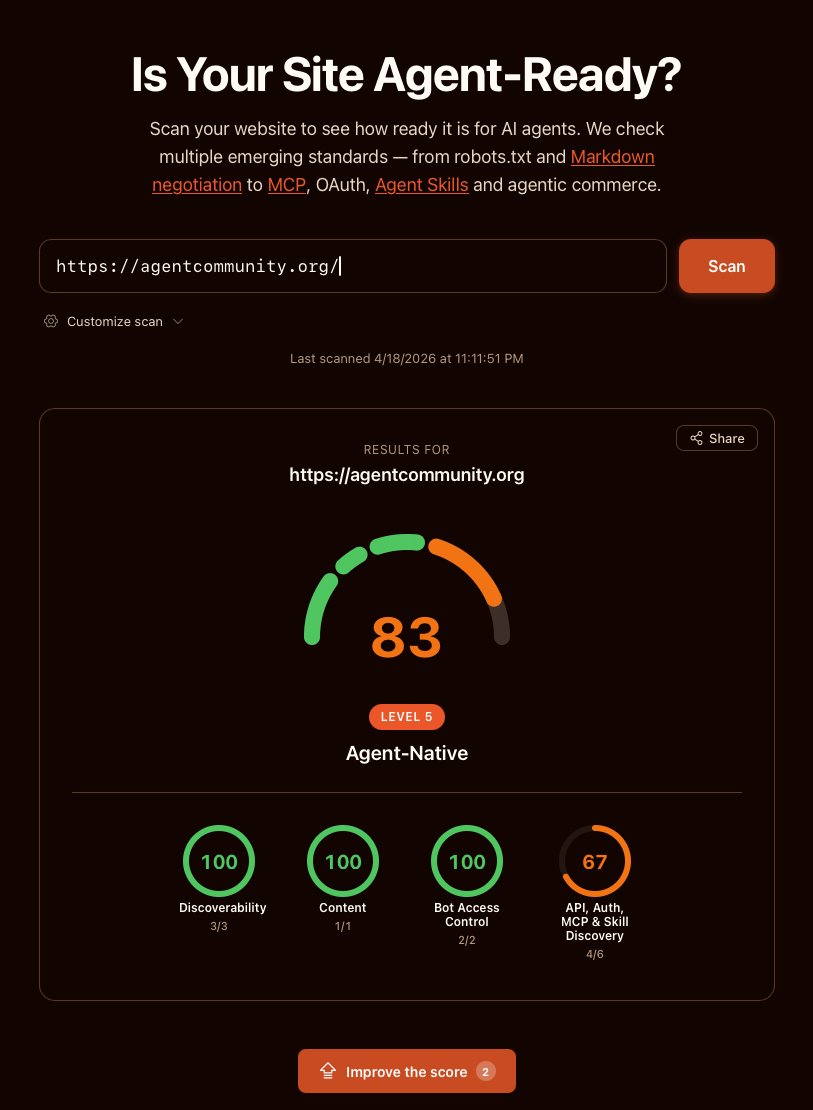
to celebrate this we added a globe discovery feature to our agentic web map:
agentcommunity.org
1
6
354
Jun 11
AgentBrief daily agentic web report 26/06/11
Fable 5 and Agentic Autonomy
news.agentcommunity.org/issu…
1
3
159
Jun 11
High-tier autonomy comes with steep costs: Fable 5 is priced at $10/$50 per 1M tokens, with some teams burning $1,500 in just 10 hours. It supports nested sub-agents up to 5 levels deep for complex planning. @jerryjliu0 @openclaw_lab
Jun 11

Anthropic has rolled out Claude Fable 5, and Claude Code instantly got more interesting 🎉
Anthropic released Claude Fable 5 - a new public Mythos-class model for complex development, long-running tasks, and agentic workflows.
The model is already available in many places. Anthropic specifically notes that Fable 5 shines on longer tasks: planning, staged execution, self-checking, and delegating subtasks.
At the same time, Claude Code has started rolling out an important update: nested subagents. Now an agent can launch subagents, and those subagents can launch their own subagents. The initial limit is up to 5 levels of nesting.
The main agent no longer has to carry the entire project, all logs, file search, tests, and review in one context. It can distribute the work across separate agents: one explores the codebase, another prepares the change, a third runs tests, a fourth reviews the diff, and a fifth looks for risks. Each returns a short result, and the main agent assembles the final solution.
Boris Cherny from the Claude Code team shared an example in the comments: a skill can run in a separate context, and inside that skill you can ask agents to keep each step isolated. This approach is already being added to /code-review, so reviews clutter the main context less and work more accurately.
1
1
124
Jun 11
Early tests show an 88% success rate for truly autonomous agentic coding tasks using Fable 5. However, Microsoft has reportedly restricted internal use due to data retention requirements. @harshitduggal5 @MTSlive
Jun 11

Fable 5 changes the Claude story.
Anthropic isn’t just launching a better model. It’s splitting one capability tier into two permission layers: Fable for general use, Mythos for trusted cyber users.
That boundary may matter more than the benchmark chart.
1
94
Jun 10
AgentBrief daily agentic web report 26/06/10
Fable 5 and Agent Engineering
news.agentcommunity.org/issu…
1
3
123
Jun 10
Strava has launched an MCP server and Apple Watch integration for agent-accessible data. This move signals the expansion of the Model Context Protocol into consumer health and fitness verticals.
@marcklingen
Jun 4

Strava seems like one of these apps that’s kind of in maintenance mode
But then
- launched MCP server
- launched saved routes on Apple Watch
Both very cool
1
2
127
Jun 10
If you want an open agentic web, and secure your .agent domain today — join the effort at agentcommunity.org (and auto-subscribe to the newsletter).
1
3
57