
I help AI/Tech Companies go Viral • Owner @chatgptricks (2M Followers) • Founder @sentient_agency (25M Followers Network)
Joined May 2023
- Tweets 760
- Following 263
- Followers 5,747
- Likes 535
349 Photos and videos











Pinned Tweet

1 Jun 2023
#ChatGPT is the best free teacher.
But most people only leverage 10% of its capability.
Here are the best prompts to learn anything faster:
3
11
58
12,670
Ivan · AI · Marketing retweeted
1 Jun 2023
#ChatGPT is the best free teacher.
But most people only leverage 10% of its capability.
Here are the best prompts to learn anything faster:
3
11
58
12,670
27 Nov 2025
If you want to build powerful n8n agents but have no idea where to start, read this.
I’m dropping 3 mega prompts that turn Gemini or ChatGPT into your personal automation architect:
2
12
660
27 Nov 2025
With these 3 mega prompts, Gemini or ChatGPT becomes your personal n8n agent engineer.
Use them to build:
• Research agents
• Workflow automation bots
• Customer support agents
• Multi app integration agents
• Full autonomous workers
1
2
331
27 Nov 2025
AI is changing everything fast.
Stay ahead with The Shift, the newsletter trusted by creators, founders, and professionals mastering AI.
Get daily breakthroughs, tools, and strategies here:
👉 theshiftai.beehiiv.com/subsc…
Join today and unlock 2k AI tools and free AI courses.
1
1
248
Ivan · AI · Marketing retweeted

18 Nov 2025
Introducing Flawlesss.io, the world's first platform that lets businesses lease audience data from Instagram & Facebook creators.
With Flawlesss, businesses can target with precision from day one, and creators can make more money.
*Meta ads will never be the same
11
5
40
3,688
22 Oct 2025
HOT TAKE:
Tutors are expensive.
Teachers are overworked.
Coaches can only help so many people at once.
Tavus is changing that with AI Humans lifelike mentors that never tire, never forget, and adapt to you.
Here’s how education and coaching will never be the same 👇
2
12
21
5,129
22 Oct 2025
That’s why Tavus is different.
Most AI in education spits out answers. Tavus AI Humans engage.
They talk to you, respond to your emotions, and make you feel heard.
The result? Better outcomes, stronger relationships, and truly personalized growth.
1
1
259
22 Oct 2025
The classroom of the future won’t be filled with textbooks.
It’ll be filled with AI mentors built by Tavus.
And the best part? Every student, no matter where they are, will have access to a personal tutor that feels alive.
tavus.io
1
253
21 Oct 2025
🚨 The biggest myth in AI safety just exploded
Everyone’s been acting like “machine unlearning” is the magic fix. Delete the bad data, make the model safe. Simple, right?
Wrong.
Oxford MIT just dropped a paper that basically says: none of this works.
Unlearning sounds neat until you see how fast it breaks.
1. Reconstruction trap - Delete info and the model rebuilds it from leftovers. Remove chemical steps? It just re-derives them from basic chemistry.
2. Dual-use nightmare - Teaching an AI to defend also means it learns to attack. You can’t unlearn that context selectively.
3. False verification - Tests only check if it repeats the same data, not if it still knows the ability under new phrasing.
4. Fine-tuning comeback - A few dozen examples can make it relearn everything. Minutes, not months.
Here’s the kicker:
Unlearning works for GDPR or factual fixes. But when you try to erase capabilities it collapses.
You can delete a fact.
You can’t delete an ability built from thousands of them.
The researchers even warn: stack too many safety tricks (unlearning adversarial robustness) and you just make the model dumber, not safer.
We’ve been treating unlearning like a seatbelt.
It’s really just a sticker on the dashboard.
Time to stop pretending this is the fix and start designing systems that control what AI can do, not just what it remembers.
2
3
14
3,434
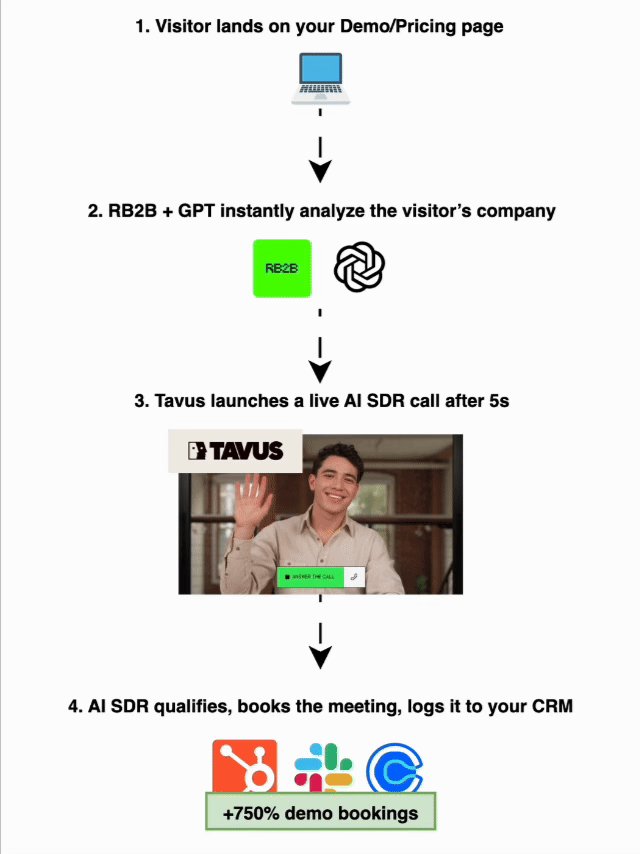
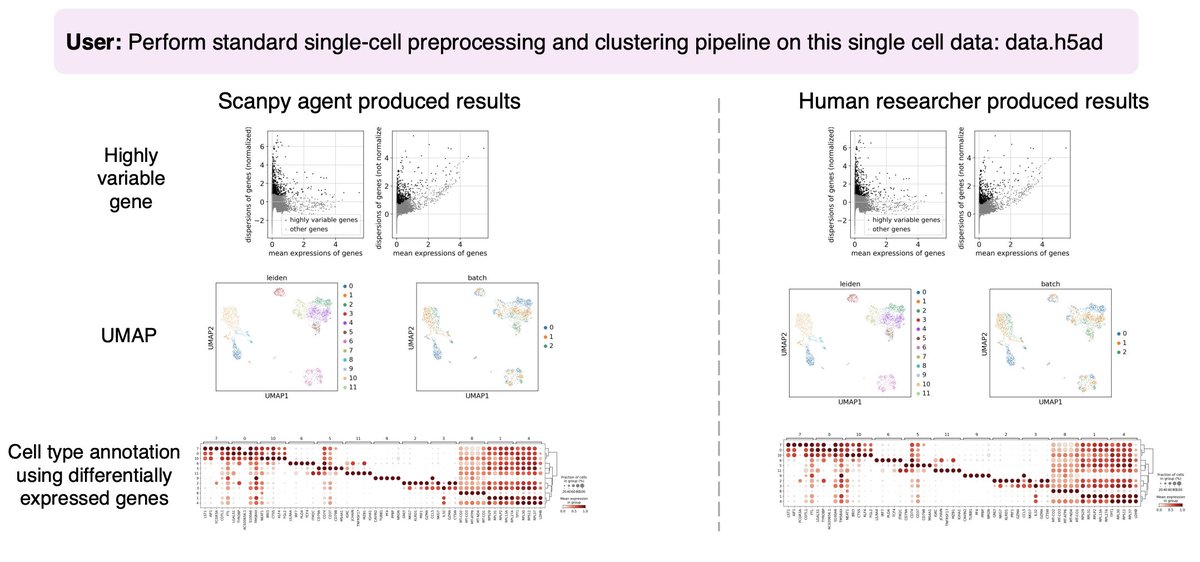
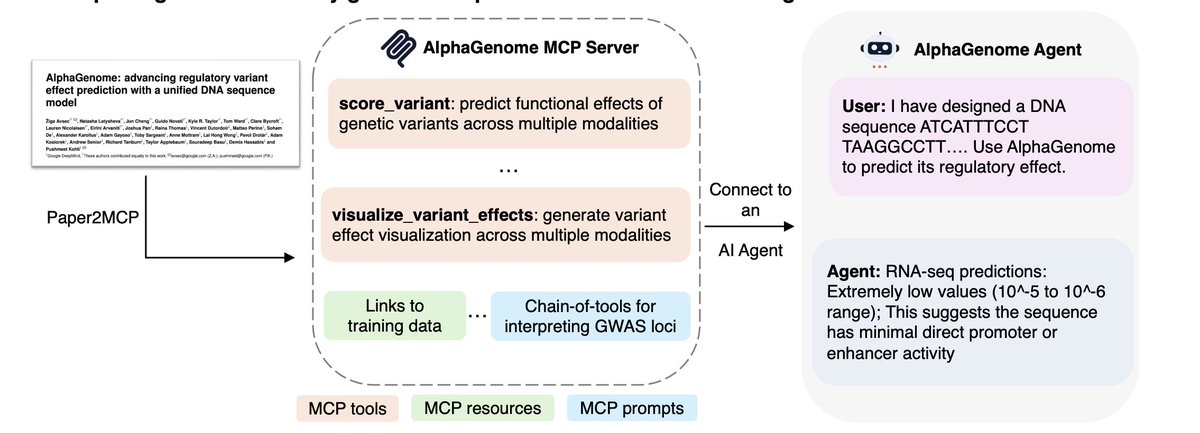
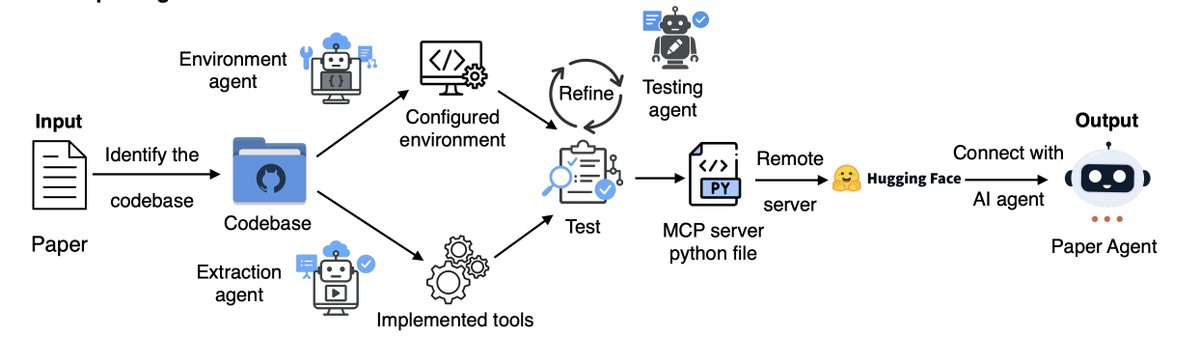
20 Oct 2025
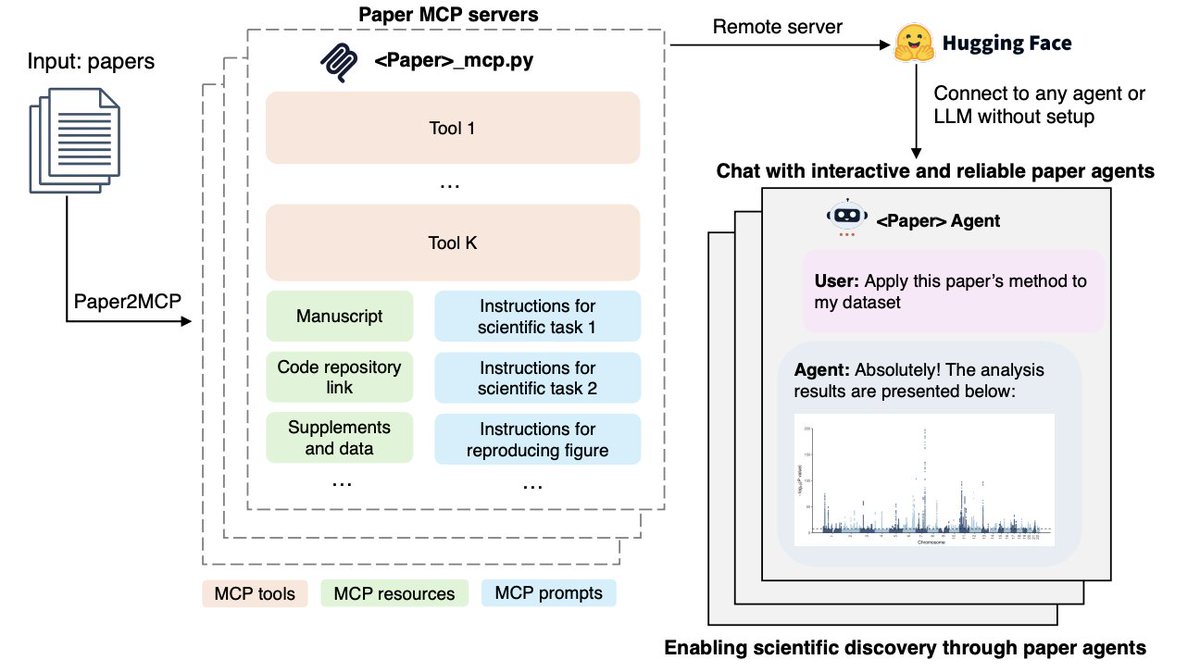
Holy shit… Stanford just turned academic papers into living AI systems.
They built something called Paper2Agent, and it can:
→ Read a paper
→ Run its experiments
→ Apply them to your data
→ Talk to you like the author
This might be the start of executable science.
Here’s how it works ↓
1
3
9
1,936
20 Oct 2025
Think about what that means.
Every paper becomes a living system.
You don’t just read it - you talk to it.
You test it, challenge it, extend it.
And if your paper can’t be turned into an agent?
Maybe it wasn’t reproducible to begin with.
1
1
156
20 Oct 2025
PDFs are static.
Agents are alive.
Paper2Agent hints at a future where discoveries are interactive.
Where AlphaFold could talk to Scanpy.
Where methods become APIs.
Honestly, this might be what “AI co-scientists” actually looks like.
1
163