
@SnorkelAI @uwcse / prev @StanfordAILab – Interested in data management systems for machine learning, weak supervision, and impactful applications.
Joined November 2013
- Tweets 1,844
- Following 694
- Followers 6,726
- Likes 4,513
61 Photos and videos



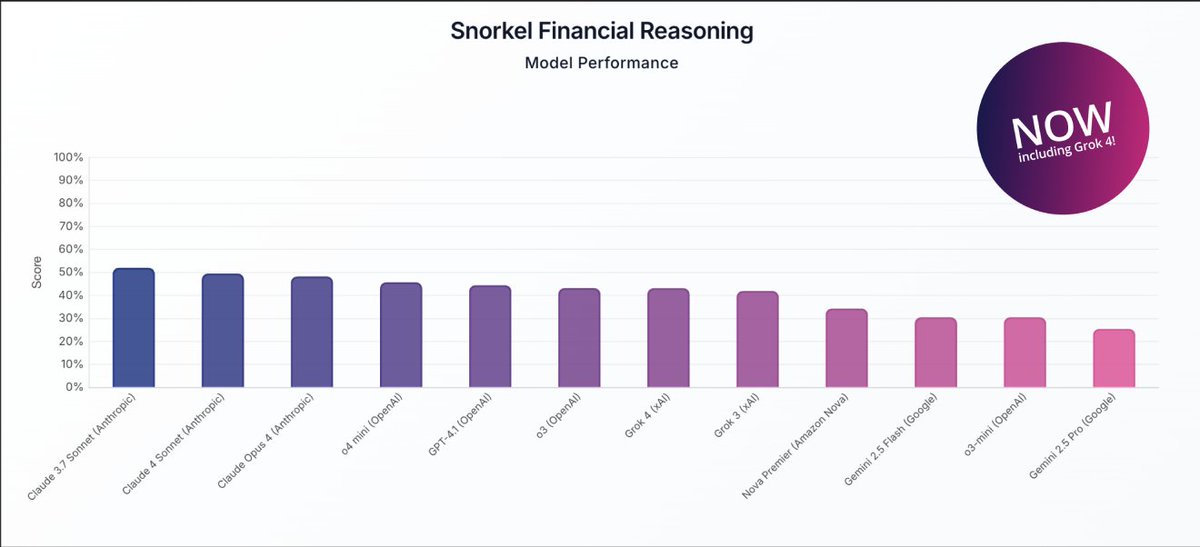
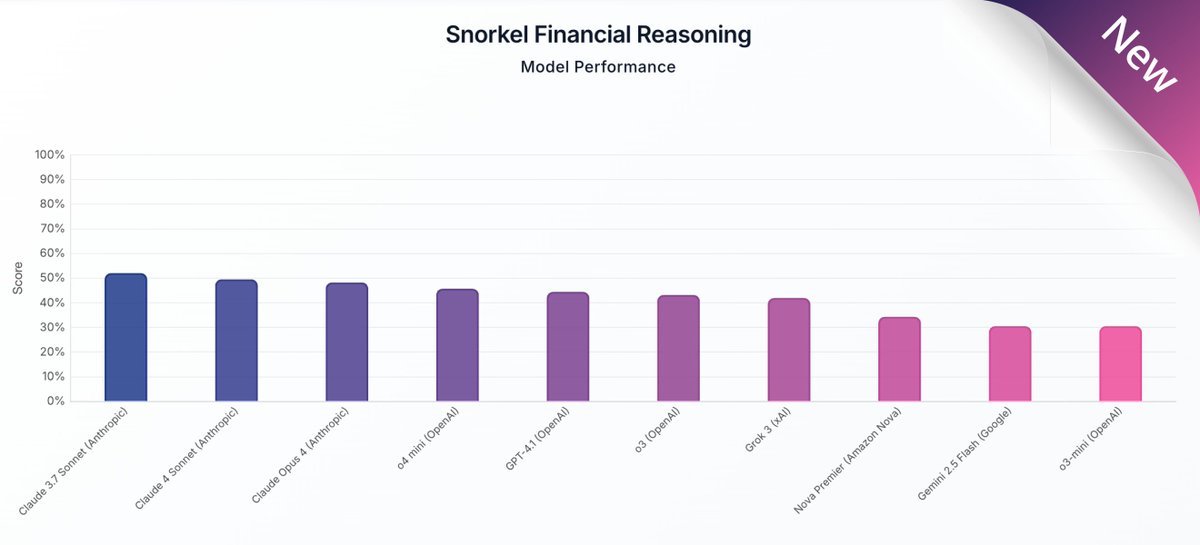





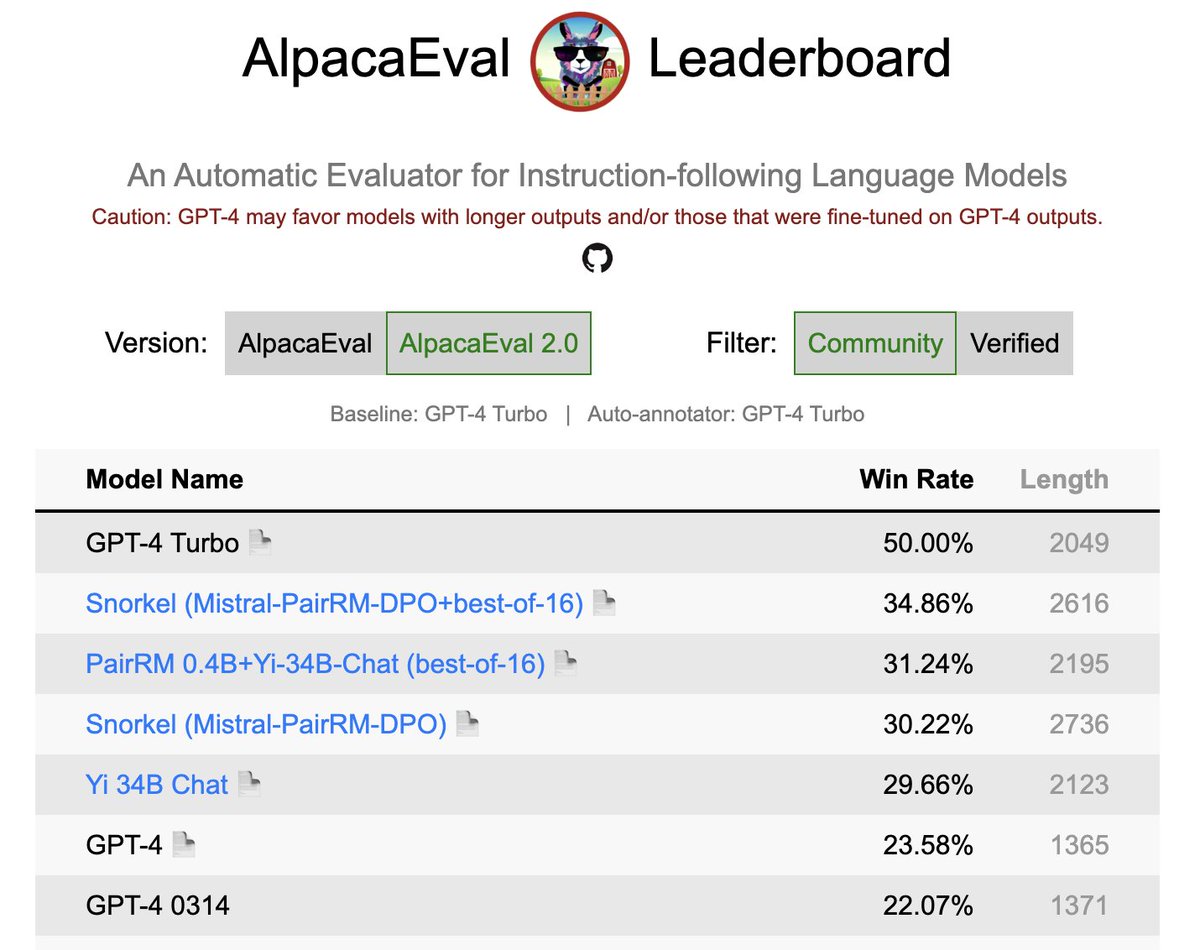

Pinned Tweet

Feb 15
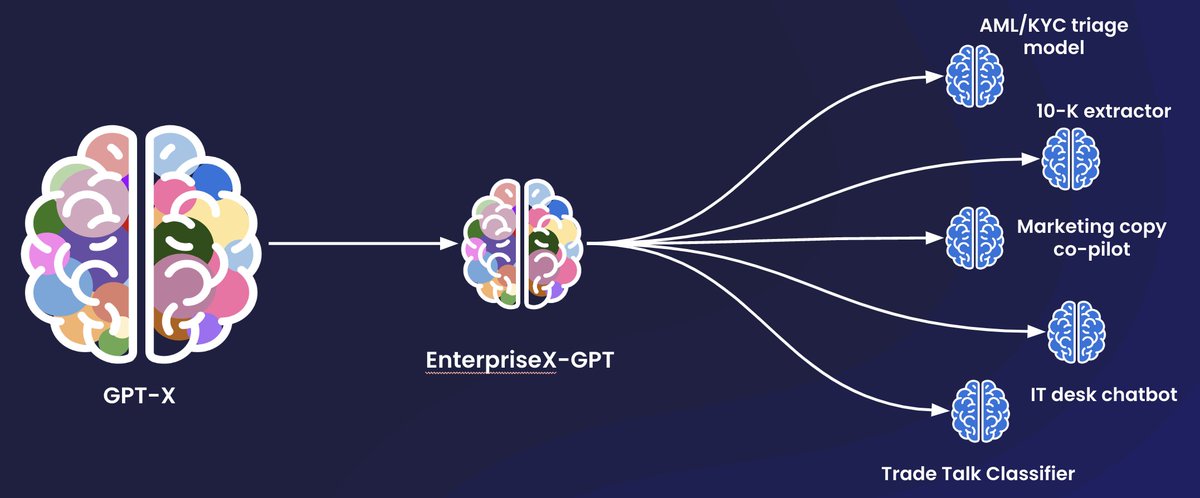
This week we launched the Open Benchmarks Grant with a $3M initial commitment from @SnorkelAI partner support from @huggingface @togethercompute @PrimeIntellect @PyTorch @harborframework & others, in order to close the evaluation gap in AI.
Our ability to measure AI has been outpaced by our ability to develop it - and open benchmarks are one of several critical, complementary tools to fix this.
We're particularly interested in novel benchmarks that push and probe the frontier along three key vectors:
(1) Environment complexity
--> E.g. complex, domain-specific context and tool/action spaces, human interaction, world modeling)
(2) Autonomy horizon
--> E.g. long horizon, non-stationary goals
(3) Output complexity
--> E.g. complex outputs with nuanced, rubric-based evaluation / reward signals
Check out more detail link to apply here! benchmarks.snorkel.ai/
1
7
46
7,709

Alex Ratner retweeted
Jun 12
So excited to support Agents' Last Exam (ALE) via @SnorkelAI Open Benchmarks Grants- an awesome new benchmark measuring agent performance on realistic, domain-specific environments and tasks.
All models < 2.6% on the frontier difficulty subset - lots more work to do!!
Jun 11

Everyone says the latest AI agents will be "job-ready" soon, especially after the release of Fable 5 this week. But is that really the case?
Over the past many months, my group and collaborators have been building Agents' Last Exam (ALE), a benchmark designed to test exactly that claim on real digital labor-market work.
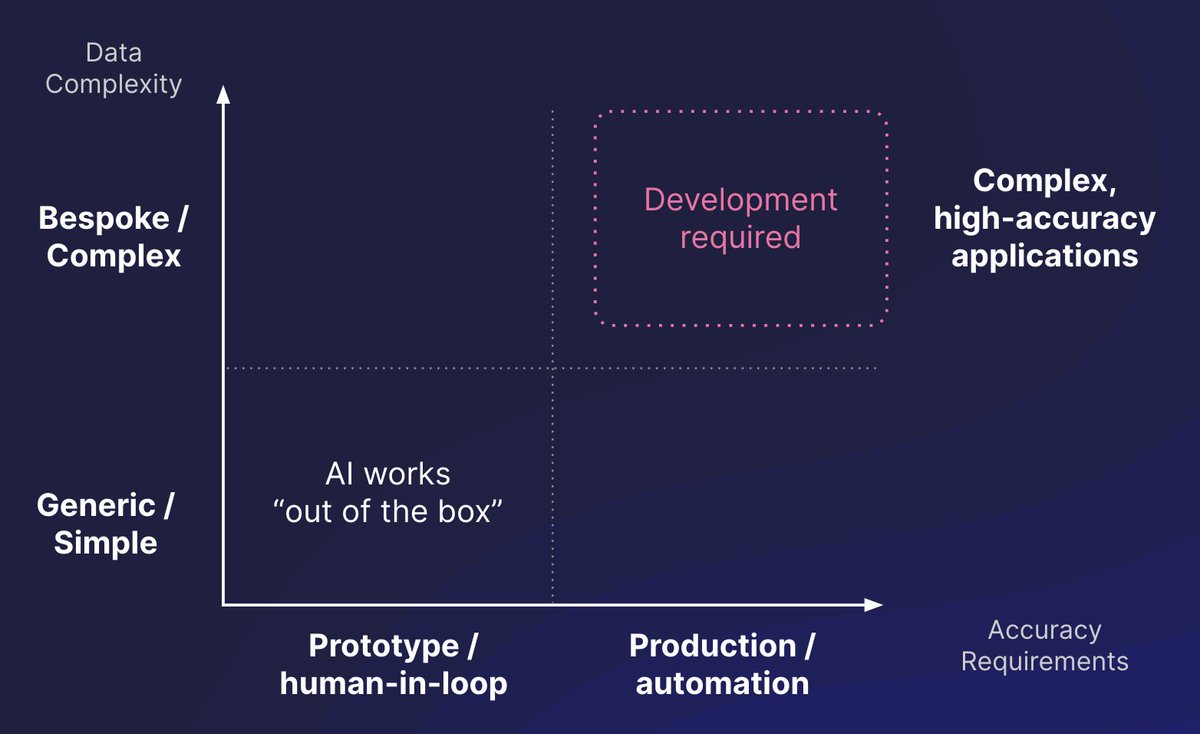
My group and collaborators previously have created many of the benchmarks the field runs on, including MMLU, MATH, CyberGym, and ExploitGym. Today, I'm excited to share Agents' Last Exam (ALE): a rolling benchmark that measures whether AI agents can actually perform economically valuable work across a broad range of real-world domains.
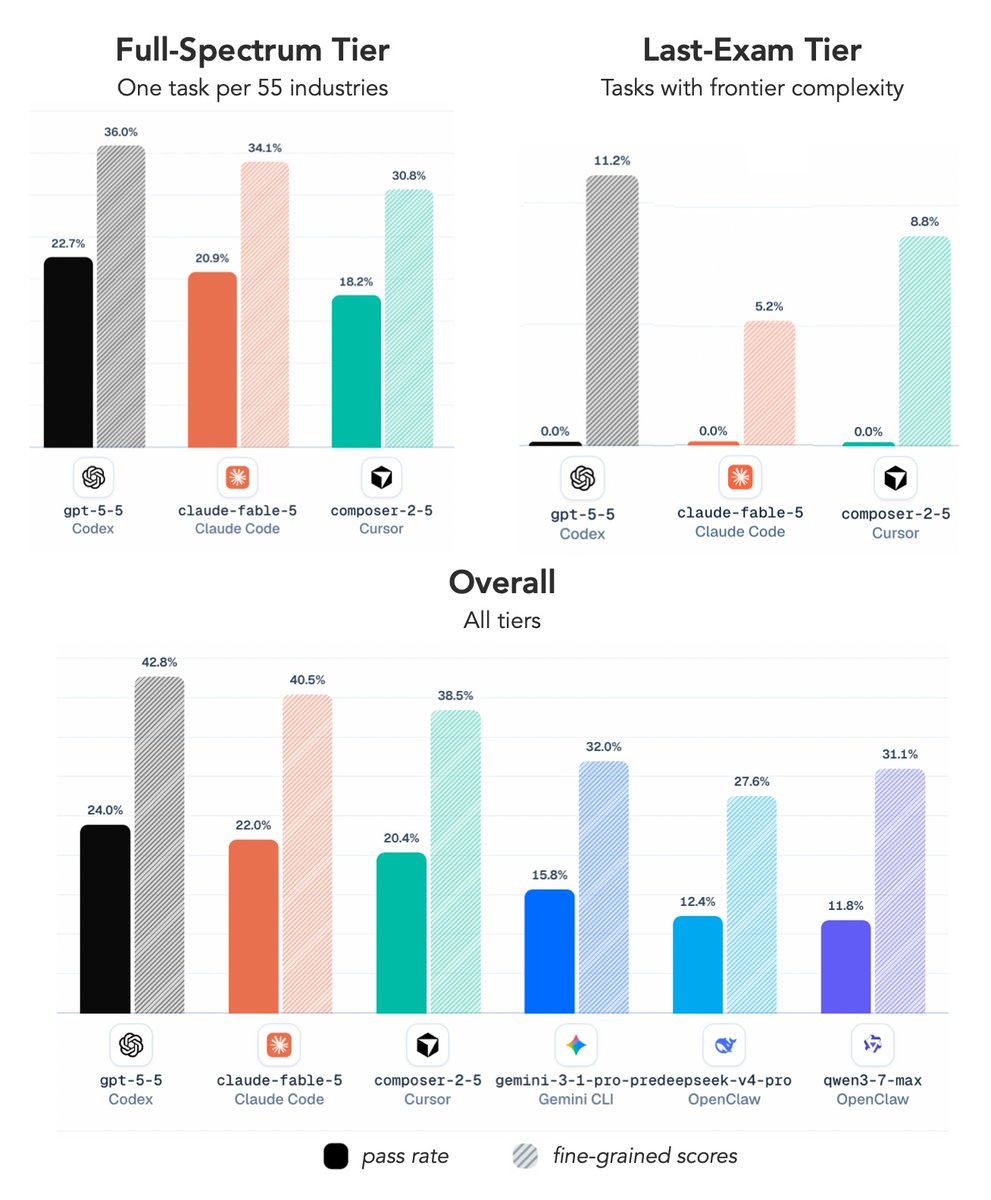
With ALE, we evaluated Fable 5, GPT-5.5, Composer 2.5, and other frontier agent systems across more than 1,500 expert-sourced tasks spanning 55 occupations.
The result is both impressive and sobering.
Today's agents can solve a meaningful fraction of professional tasks. But when we look at the hardest tasks, the ones requiring sustained reasoning, deep domain expertise, and reliable execution over long horizons, they are still far from human-level performance.
On ALE's hardest tier, every frontier agent we tested, including Fable 5, achieved a 0% success rate.
The age of useful agents is here.
The age of truly job-ready agents is not.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains.
🧵
1
4
13
1,220

“AI agents will outperform humans at almost all jobs by 2026–2027.” - The forecast is everywhere.
So we built the exam to test that claim, on real labor-market aligned work. On the hardest tier, top agents pass 2.6%.
Meet Agents' Last Exam (ALE), a rolling benchmark measuring whether agents can actually do real jobs. 🧵👇
14
102
328
84,632
Alex Ratner retweeted

Jun 11
New from Agents' Last Exam: every frontier agent tested, Fable 5 included (scored 0% on the benchmark's hardest tier of real professional work). 👇
Jun 11
Everyone says the latest AI agents will be "job-ready" soon, especially after the release of Fable 5 this week. But is that really the case?
Over the past many months, my group and collaborators have been building Agents' Last Exam (ALE), a benchmark designed to test exactly that claim on real digital labor-market work.
My group and collaborators previously have created many of the benchmarks the field runs on, including MMLU, MATH, CyberGym, and ExploitGym. Today, I'm excited to share Agents' Last Exam (ALE): a rolling benchmark that measures whether AI agents can actually perform economically valuable work across a broad range of real-world domains.
With ALE, we evaluated Fable 5, GPT-5.5, Composer 2.5, and other frontier agent systems across more than 1,500 expert-sourced tasks spanning 55 occupations.
The result is both impressive and sobering.
Today's agents can solve a meaningful fraction of professional tasks. But when we look at the hardest tasks, the ones requiring sustained reasoning, deep domain expertise, and reliable execution over long horizons, they are still far from human-level performance.
On ALE's hardest tier, every frontier agent we tested, including Fable 5, achieved a 0% success rate.
The age of useful agents is here.
The age of truly job-ready agents is not.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains.
🧵
4
19
1,500
Alex Ratner retweeted
Jun 11
GPT 5.5 cracked cmatrix, one of the easiest of the 200 tasks. @jyangballin on why 80% is maybe a year and a half out, and why the hardest instances (SQLite, the PHP interpreter, the Tiny C compiler) trace back to one developer, Fabrice Bellard. From Benchtalks #2.
1
7
27
3,294
Alex Ratner retweeted

Agents' Last Exam covers 1,490 domain-specific environments/tasks across 55 industries, with a focus on:
- realistic, domain-specific environments and tasks (e.g. SolidWorks or Rhino for architecture)
- verification via deterministic rubrics rather than an LLM judge
- new coverage of 13/55 previously uncovered domains
Work led by @YiyouSun @Xinyang_Han_ @dawnsongtweets & the @BerkeleyRDI team- we @SnorkelAI are glad to collaborate on this benchmark to measure economically-valuable work

“AI agents will outperform humans at almost all jobs by 2026–2027.” - The forecast is everywhere.
So we built the exam to test that claim, on real labor-market aligned work. On the hardest tier, top agents pass 2.6%.
Meet Agents' Last Exam (ALE), a rolling benchmark measuring whether agents can actually do real jobs. 🧵👇
1
6
15
1,132
Alex Ratner retweeted

Jun 9
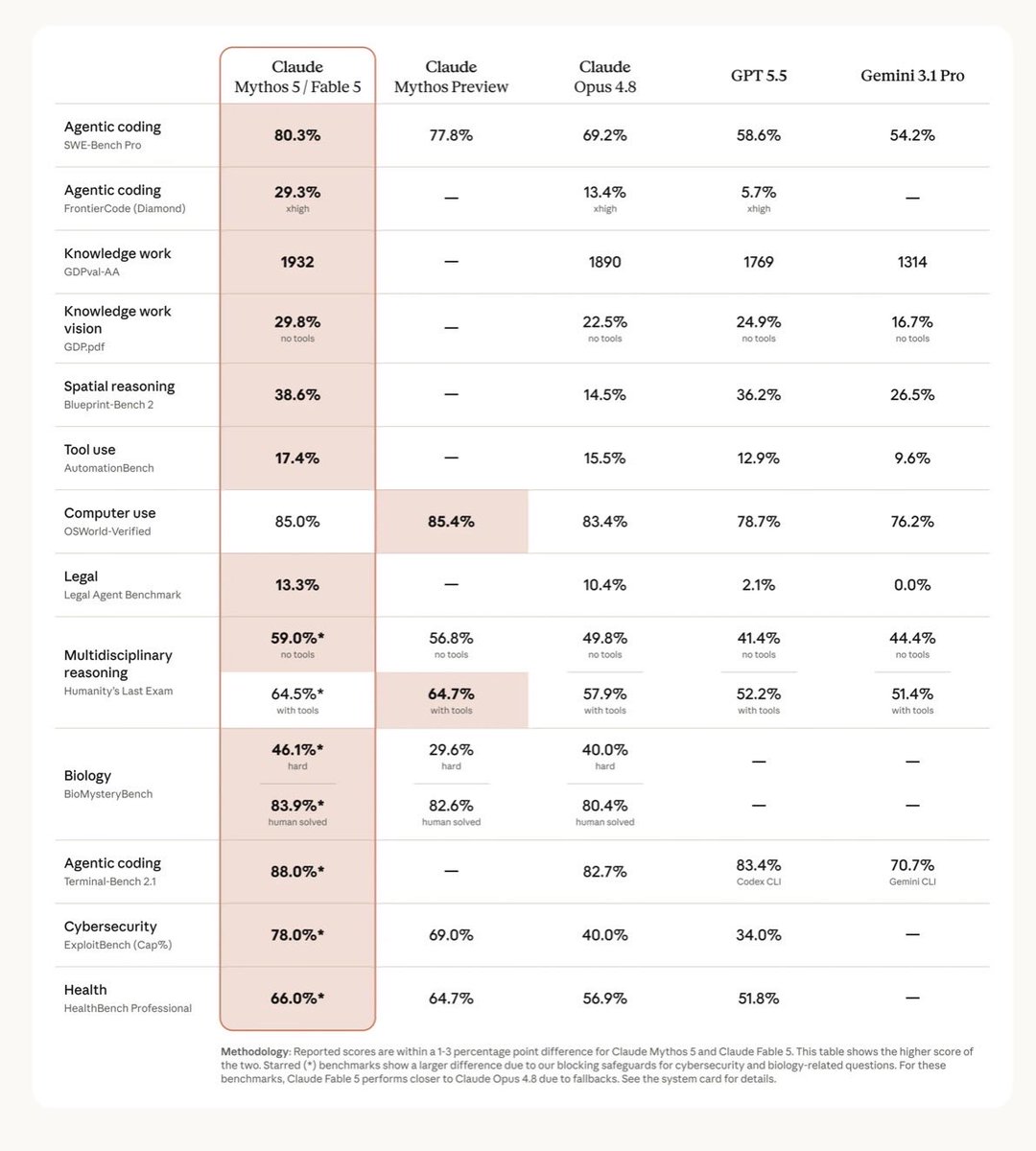
Anthropic is also the first model provider to feature @harvey’s Legal Agent Bench as part of their core go-live benchmarks. Glad to see legal becoming a first-class use case for AI.
Jun 9

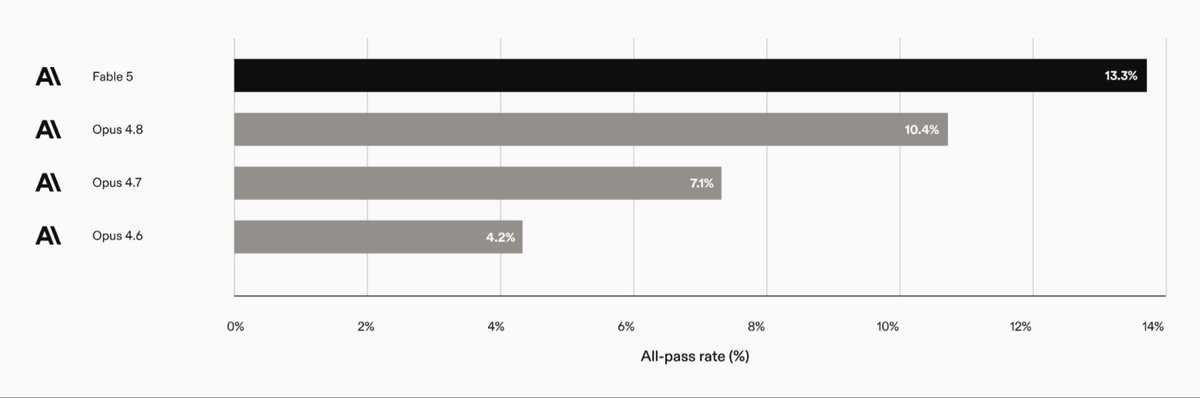
@AnthropicAI released a new model family today, Fable 5, which they’re describing as a Mythos class model with safeguards.
@harvey had early access and it posted all-time high scores on both Legal Agent Bench (13.3%) and BigLaw Bench (93.4%). Due to data retention considerations, we’ll be making Fable 5 available in Harvey on an opt-in basis.
2
10
84
11,823
Alex Ratner retweeted
Jun 9
We're proud Snorkel AI is part of Agents' Last Exam, with our researchers @amanda_dsouza and @vincentsunnchen among the co-authors and support from our Open Benchmarks Grants initiative.
The forecast: agents will do almost every job by 2027. The result on real, code-graded work? Top agents pass just 2.6% on the hardest tier.
Excited to keep pushing this forward with @YiyouSun, @dawnsongtweets and the @BerkeleyRDI team. 👇

“AI agents will outperform humans at almost all jobs by 2026–2027.” - The forecast is everywhere.
So we built the exam to test that claim, on real labor-market aligned work. On the hardest tier, top agents pass 2.6%.
Meet Agents' Last Exam (ALE), a rolling benchmark measuring whether agents can actually do real jobs. 🧵👇
2
12
55
8,227
Alex Ratner retweeted
Jun 4
Our thanks to everyone who dropped by yesterday for boba to learn from @EchoShao8899 of @stanfordnlp about "Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration".
Key takeaway: across 3 tasks (travel planning, related-work writing, and tabular analysis), the best collaborative agents consistently outperformed fully autonomous ones when judged by real users.
Recording/transcript ICYMI: snorkel.ai/blog/collaborativ…



1
7
41
6,573
Alex Ratner retweeted
ProgramBench up-levels evaluation to the artifact rather than purely measuring implementation.
1. It mirrors the interface that software users (e.g. engineers, researchers) are increasingly interacting with
2. This provides a new kind of "research tool" to study frontier models, including implementation trade-offs, fuzzing/validation, new interfaces for steering models
Full discussion w/ @jyangballin below

New Benchtalks with @jyangballin: on ProgramBench (0% frontier models at launch) and the lineage/future of coding benchmarks, from SWE-bench/InterCode to now
01:29 ProgramBench launch and reception
03:41 Why artifact-level evaluation, not code-level
06:03 Why models love Python
08:29 ProgramBench as a research tool
12:45 From SWE-bench & InterCode to ProgramBench
17:47 How to grade a coding model
21:53 The position paper & humans in the loop
25:01 Managing quality with agents-in-the-loop
28:40 Internet access and benchmark integrity
35:26 Where models may surpass human abilities
38:56 When a model hits 80% on ProgramBench
43:55 Benchmarks worth paying attention to
46:24 What benchmark do you wish existed
49:32 Will benchmarks still look like benchmarks in 5 years
52:02 How to contribute to ProgramBench
8
17
2,608
Alex Ratner retweeted

Jun 4
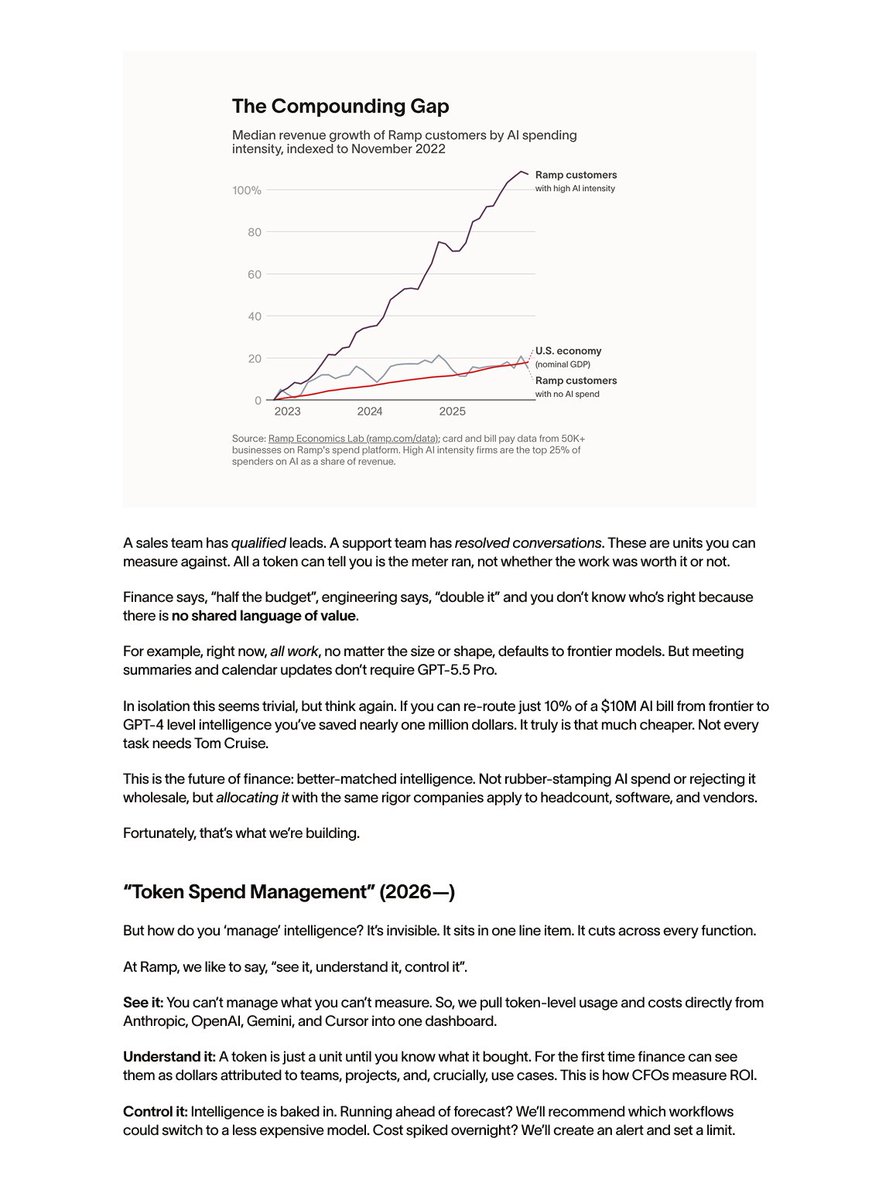
Today, Ramp raised $750M at a $44B valuation.
Last time we grew this fast, we were 1/20th the size.
For 2000 years, business was built on two pillars. Today, a third: intelligence.
It’s your least governed cost. It’s also your single greatest opportunity.



139
201
2,599
1,054,819
Jun 3
Check out new @SnorkelAI Benchtalks with @jyangballin , author of ProgramBench, SWEBench, and many other key benchmarks in the space.
While I'm crestfallen that @vincentsunnchen so quickly dropped the gag of having the interviews on a literal bench... this is a great one!!
New Benchtalks with @jyangballin: on ProgramBench (0% frontier models at launch) and the lineage/future of coding benchmarks, from SWE-bench/InterCode to now
01:29 ProgramBench launch and reception
03:41 Why artifact-level evaluation, not code-level
06:03 Why models love Python
08:29 ProgramBench as a research tool
12:45 From SWE-bench & InterCode to ProgramBench
17:47 How to grade a coding model
21:53 The position paper & humans in the loop
25:01 Managing quality with agents-in-the-loop
28:40 Internet access and benchmark integrity
35:26 Where models may surpass human abilities
38:56 When a model hits 80% on ProgramBench
43:55 Benchmarks worth paying attention to
46:24 What benchmark do you wish existed
49:32 Will benchmarks still look like benchmarks in 5 years
52:02 How to contribute to ProgramBench
1
7
1,536
Alex Ratner retweeted
Jun 2
Benchtalks #2: @jyangballin, creator of SWE-bench, fresh off ProgramBench (every frontier model: 0% at launch). Out soon with @vincentsunnchen.

3
6
27
3,820
May 28
So excited for this bold vision of small, personalized, on-device AI that everyone can own themselves!
Excited to support the multi-objective evaluations that chart this new quality/latency/efficiency/cost/privacy Pareto frontier via @SnorkelAI Open Benchmarks Grants.
May 28

The dominant story in AI has been the growing cloud: bigger clusters, larger models, more gigawatts.
We believe the future is in the opposite direction: on-device inference, smaller models, watts instead of gigawatts.
Today we're releasing @OpenJarvisAI v1.0: a personal AI assistant that lives, learns, and works on your device.
1
3
18
2,761
Alex Ratner retweeted
May 28
Huge congrats to @jonsaadfalcon, @Avanika15, @Azaliamirh and the @HazyResearch team on @OpenJarvisAI — out today.
For two years, they've been making the case that AI inference belongs on hardware people already own, not just in megawatt data centers. Excited to support the Intelligence per Watt line of work.
Read more on their blog: hazyresearch.stanford.edu/bl…

May 28
The dominant story in AI has been the growing cloud: bigger clusters, larger models, more gigawatts.
We believe the future is in the opposite direction: on-device inference, smaller models, watts instead of gigawatts.
Today we're releasing @OpenJarvisAI v1.0: a personal AI assistant that lives, learns, and works on your device.
7
26
2,103
Alex Ratner retweeted
May 27
Great turnout in San Jose today for @chris_m_glaze's paper session on Benchmarking Agents in Insurance Underwriting Environments at @CAISconf.
If you're at the conference, catch the team behind the paper today at the poster session from 5:15–6:45 p.m. at Carmel/Monterey. And come find us tomorrow night at the Day 2 Conference Reception (sponsored by Snorkel).
Paper: dl.acm.org/doi/10.1145/37863…


1
3
17
990
Alex Ratner retweeted

May 27
Announcing JudgmentBench – a dataset we at @StanfordLaw liftlab developed along with @harvey and @SnorkelAI that evaluates frontier LLM work product.
The dataset contains 30 real-world tasks crafted by Biglaw attorneys paired with >3000 rubric and preference expert annotations.

4
17
86
14,290
Alex Ratner retweeted

May 27
1/ We’ve raised over $1B at a $26B valuation, led by @Lux_Capital, @generalcatalyst, and @8vc.
Our enterprise usage has grown >10x since the start of this year, and our run-rate revenue grew to $492 M.
We launched Devin two years ago as the first AI software engineer. Since then, cloud agents have gone from niche to mainstream, and today they are the fastest growing way to create software.

165
194
2,464
870,303