
Physics-AI fellow @Cambridge_Uni explaining the scientific principles behind AI. Formerly @EPFL, @Amazon AI.
Joined September 2020
- Tweets 151
- Following 923
- Followers 691
- Likes 1,010
10 Photos and videos






Pinned Tweet

May 29
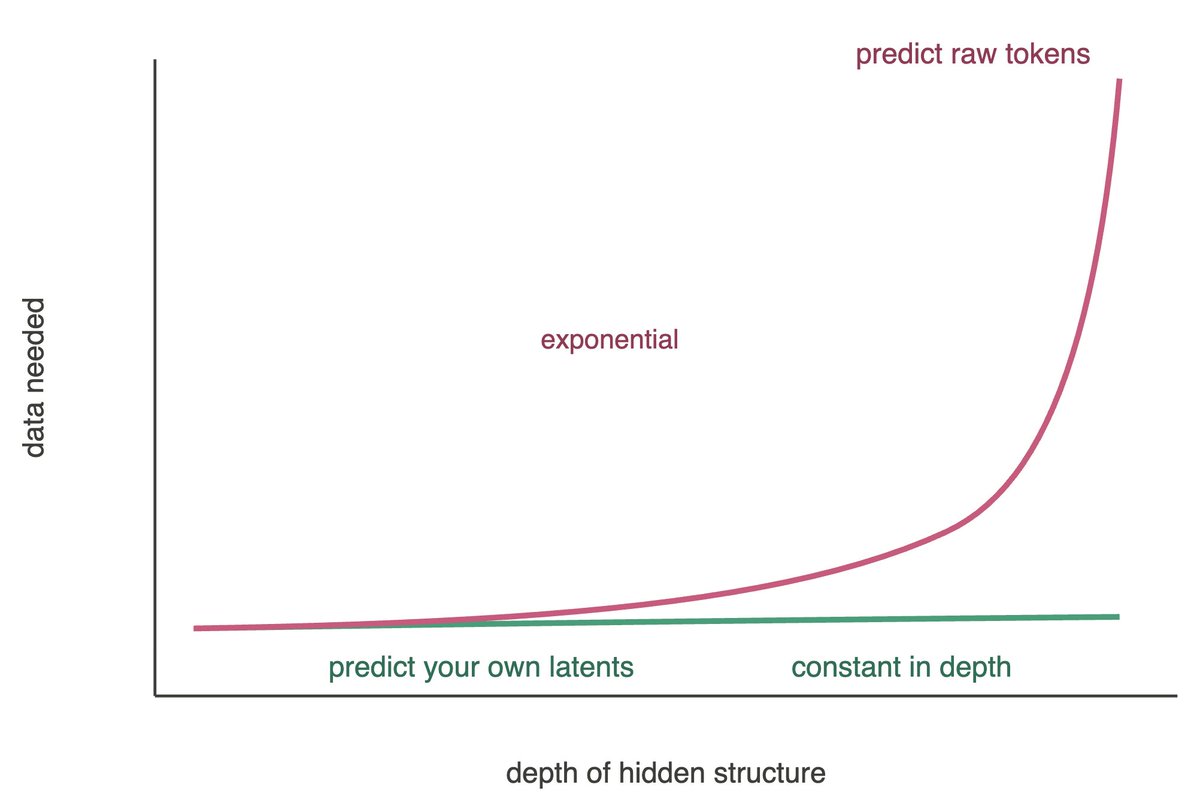
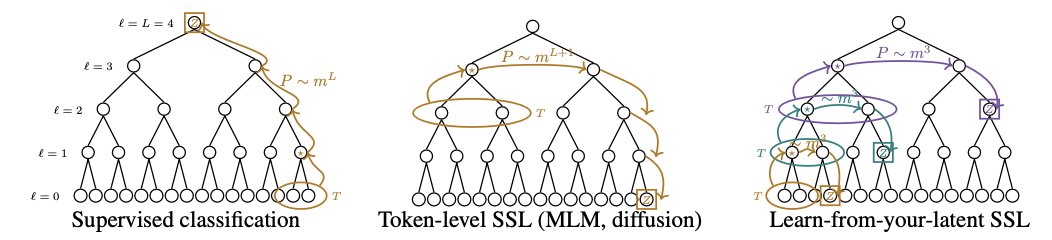
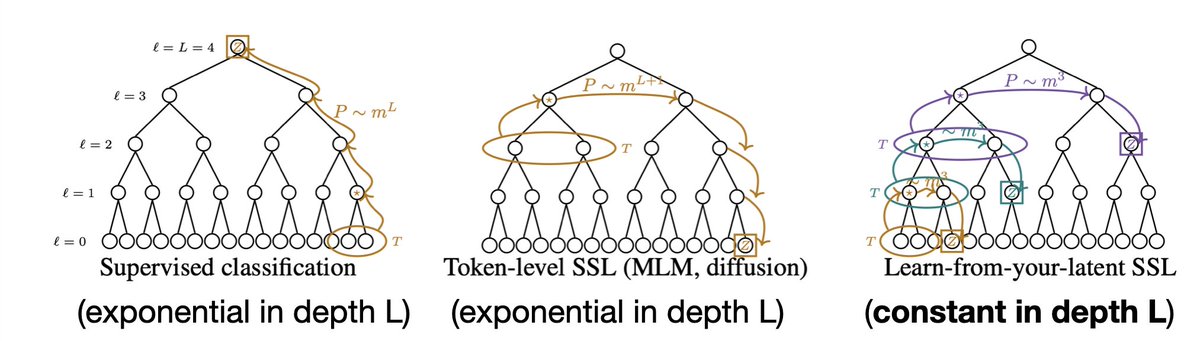
AI needs vastly more data than we do. One idea might close the gap: don't predict raw signals (tokens), predict your own abstract latent representation (JEPA, data2vec).
With @DanKorchinski @MatthieuWyart, on a toy model, we prove how much that helps: the gap is exponential.
🧵
14
76
518
51,325
Alessandro Favero retweeted

Jun 3
For the past two years we've studied a decades-old problem in fluid dynamics: why do some turbulent systems grow 3x faster in the real world than simulations predict?
With some tabletop fluids experiments and a physics foundation model, we finally have some results!!!
👇
3
32
211
16,404
👇
Jun 1

Nice to see that the intuition behind JEPA and prediction in representation space can be justified theoretically!
5
3,444
Alessandro Favero retweeted
LLMs learn by predicting tokens. World models (JEPA, data2vec) learn by predicting their own abstractions. Which needs more data? For data with hidden hierarchy, we prove the gap is exponential. arxiv.org/pdf/2605.27734
35
227
1,619
146,086
Alessandro Favero retweeted

May 30
"Learn from your own latents, not tokens: A Sample Complexity Theory"
This paper explains why data2vec and JEPA can learn with much less data.
They showed that when data has hidden hierarchy, token prediction becomes harder as the hierarchy gets deeper. But latent prediction keeps the learning problem simple at every level.
Which suggests that models may learn faster when they stop predicting raw tokens and start predicting their own abstractions.

9
105
633
35,734
Alessandro Favero retweeted

Why are generative models so data-hungry?
Maybe because we ask them to predict raw tokens/pixels when predicting in latent space can yield an exponential gain in sample complexity!
Proud of our new work with @alesfav and @MatthieuWyart 🧵
11
52
429
28,293
May 29
AI needs vastly more data than we do. One idea might close the gap: don't predict raw signals (tokens), predict your own abstract latent representation (JEPA, data2vec).
With @DanKorchinski @MatthieuWyart, on a toy model, we prove how much that helps: the gap is exponential.
🧵
14
76
518
51,325
May 29
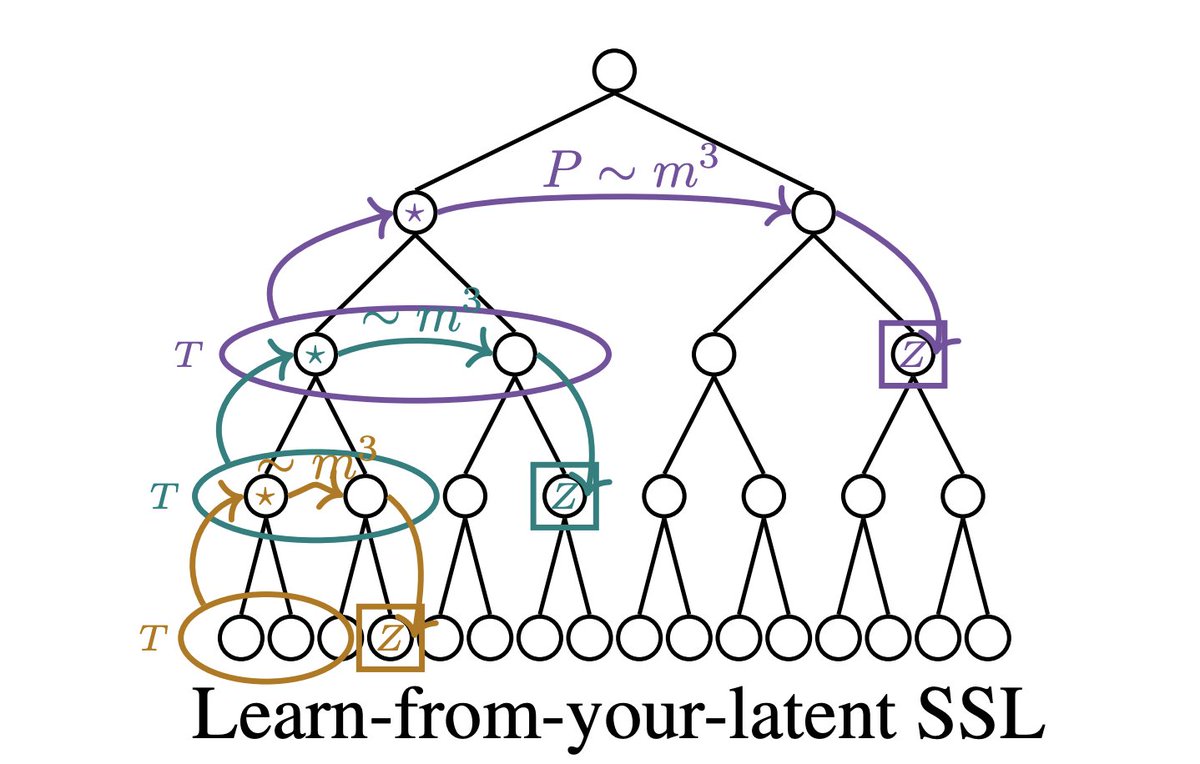
Surprisingly, we found data2vec already does this with a single module. Through its teacher, it implicitly supervises on latents at every level, reaching the same constant-in-depth scaling. 🤯
The hierarchy unfolds during training rather than being stacked into the architecture.
1
1
28
2,670
May 29
This result also suggests that explicit stacking, like H-JEPA, may be redundant.
Many open questions!
📄 Our paper: arxiv.org/abs/2605.27734
1
6
64
2,848
Alessandro Favero retweeted

May 26
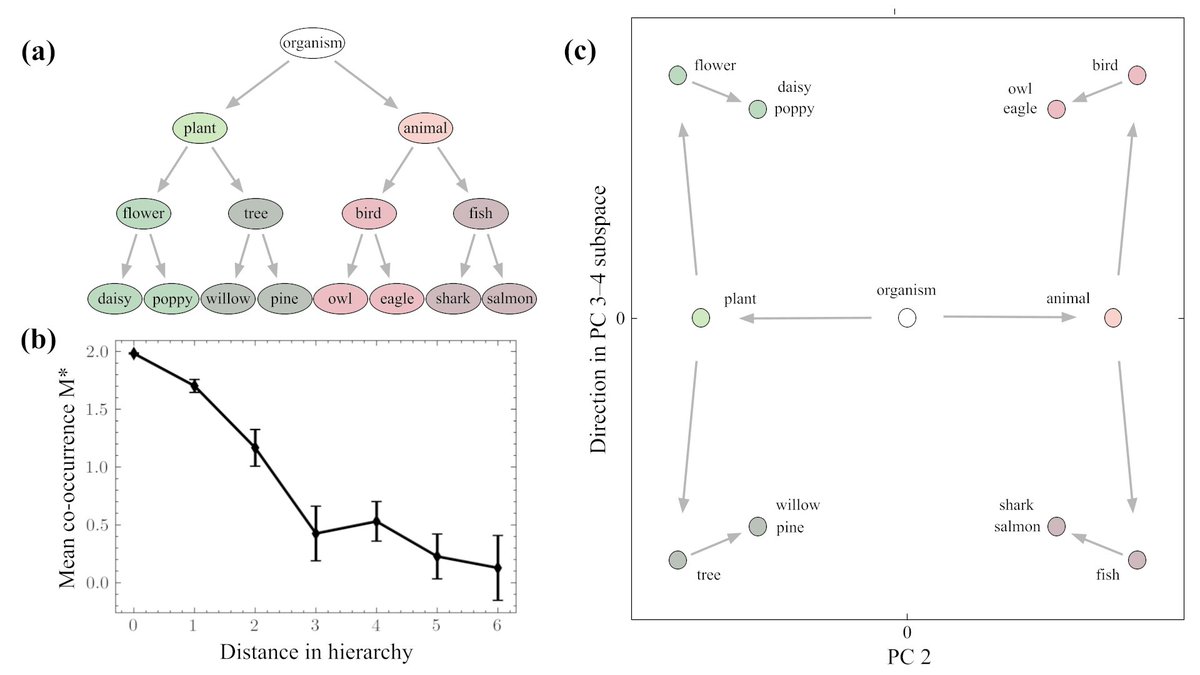
Very happy to share my first first-author preprint with @MatthieuWyart.
Meaning is hierarchical: dog → mammal → animal.
This hierarchy appears as geometry in LLM embeddings. But where does that geometry come from?
We show that word co-occurrence statistics are sufficient to induce it.
arxiv.org/abs/2605.23821
9
19
162
10,068
Alessandro Favero retweeted

Apr 24
It's been so heartening to see deep learning theory folks engage seriously with interpretability recently, and I hope these two communities can talk much, much more. We should seek a unified understanding of neural networks across many levels of analysis.
Apr 24

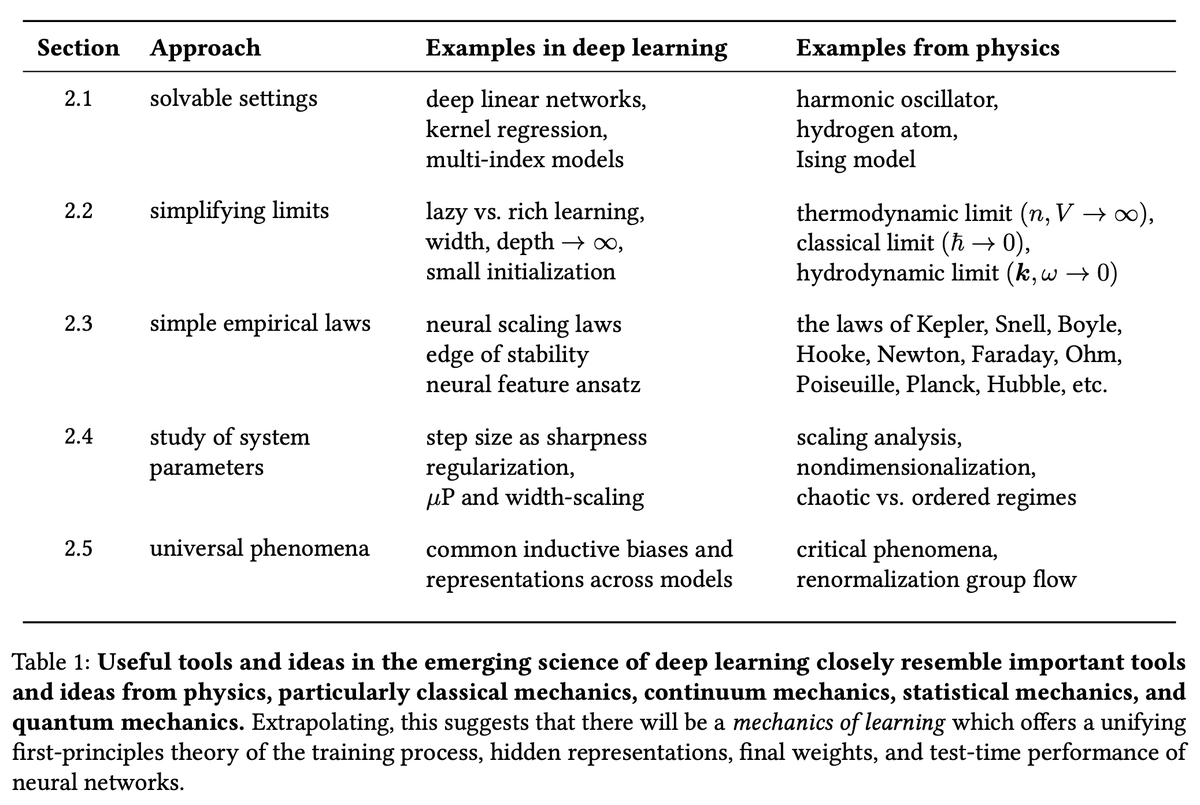
1/ Deep learning is going to have a scientific theory. We can see the pieces starting to come together, and it's looking a lot like physics!
We're releasing a paper pulling together these emerging threads and giving them a name: learning mechanics.
🔨 arxiv.org/pdf/2604.21691 🔧
1
15
154
12,992

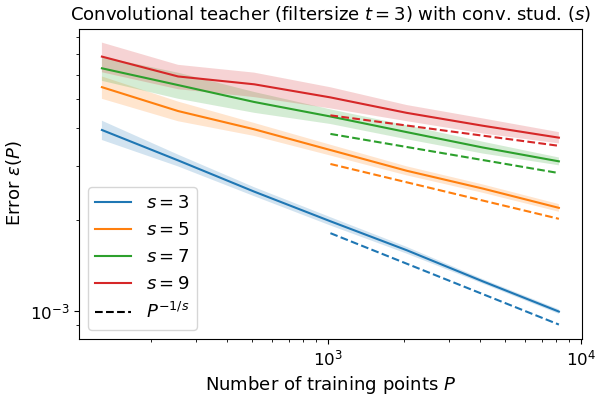
physical systems (orbits/fluid mechanics) may look complex, but are often governed by simple equations/few parameters. can current self-supervised methods learn the underlying physics?
our new paper finds that learning in latent space may be the key!
arxiv.org/abs/2603.13227🧵

25
97
661
56,984
Alessandro Favero retweeted

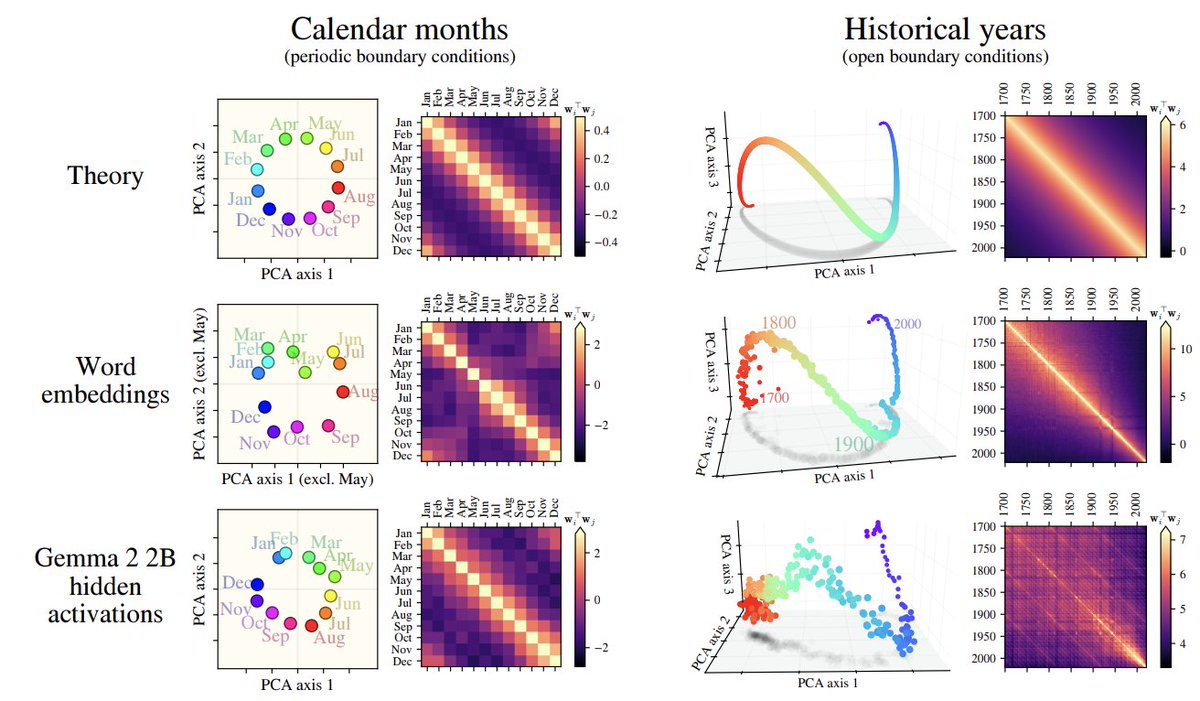
Feb 17
What governs the geometry of time and space embeddings in LLMs?
We show it follows from translation symmetry in language statistics.
With Dhruva Karkada, @DanKorchinski, Andres Nava, @yasamanbb
arxiv.org/abs/2602.15029
7
63
390
33,968
Alessandro Favero retweeted
Feb 16
This paper asks:
What controls the scaling laws of LLMs? Two key ideas: (i) as the training set size increases, correlations are detected on a longer context scale and (ii) on this scale, LLMs function optimally: the loss is ~ the next-token conditional entropy.
Feb 10

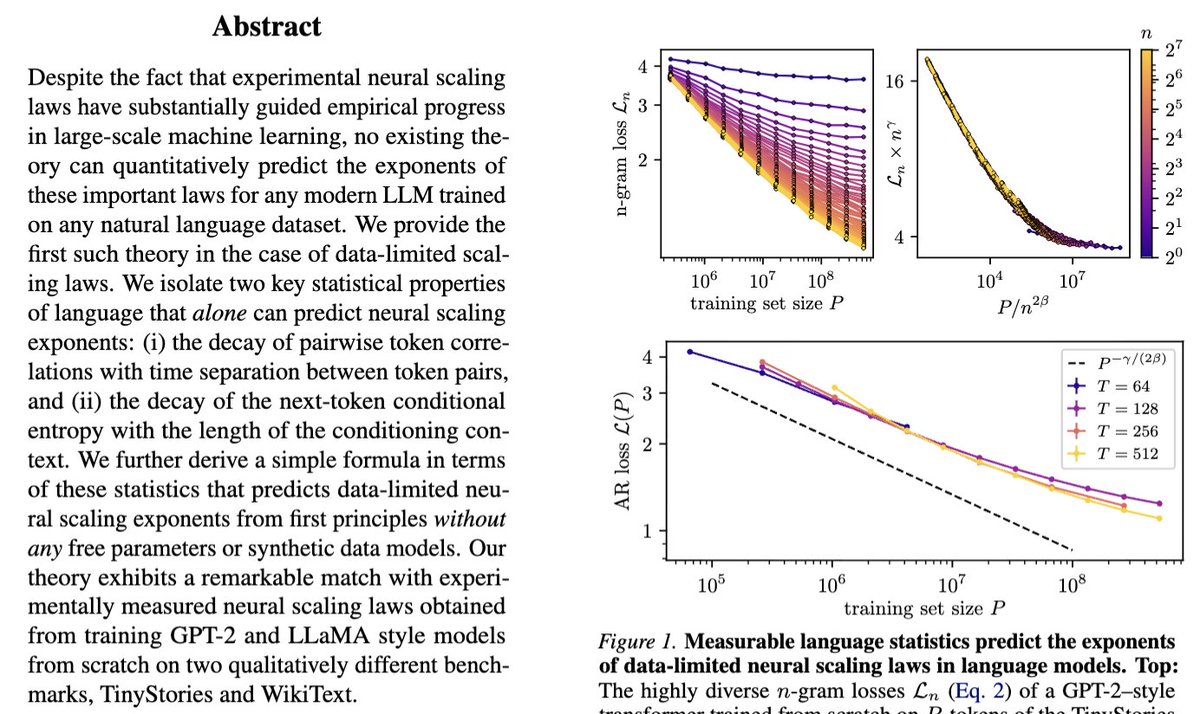
Our new paper "Deriving neural scaling laws from the statistics of natural language" arxiv.org/abs/2602.07488 lead by @Fraccagnetta & @AllanRaventos w/ Matthieu Wyart makes a breakthrough! We can predict data-limited neural scaling law exponents from first principles using the structure of natural language itself for the very first time!
If you give us two properties of your natural language dataset:
1) How conditional entropy of the next token decays with conditioning length.
2) How pairwise token correlations decay with time separation.
Then we can give you the exponent of the neural scaling law (loss versus data amount) through a simple formula!
The key idea is that as you increase the amount of training data, models can look further back in the past to predict, and as long as they do this well, the conditional entropy of the next token, conditioned on all tokens up to this data-dependent prediction time horizon, completely governs the loss! This gets us our simple formula for the neural scaling law!
1
7
39
7,921
Alessandro Favero retweeted
Feb 16
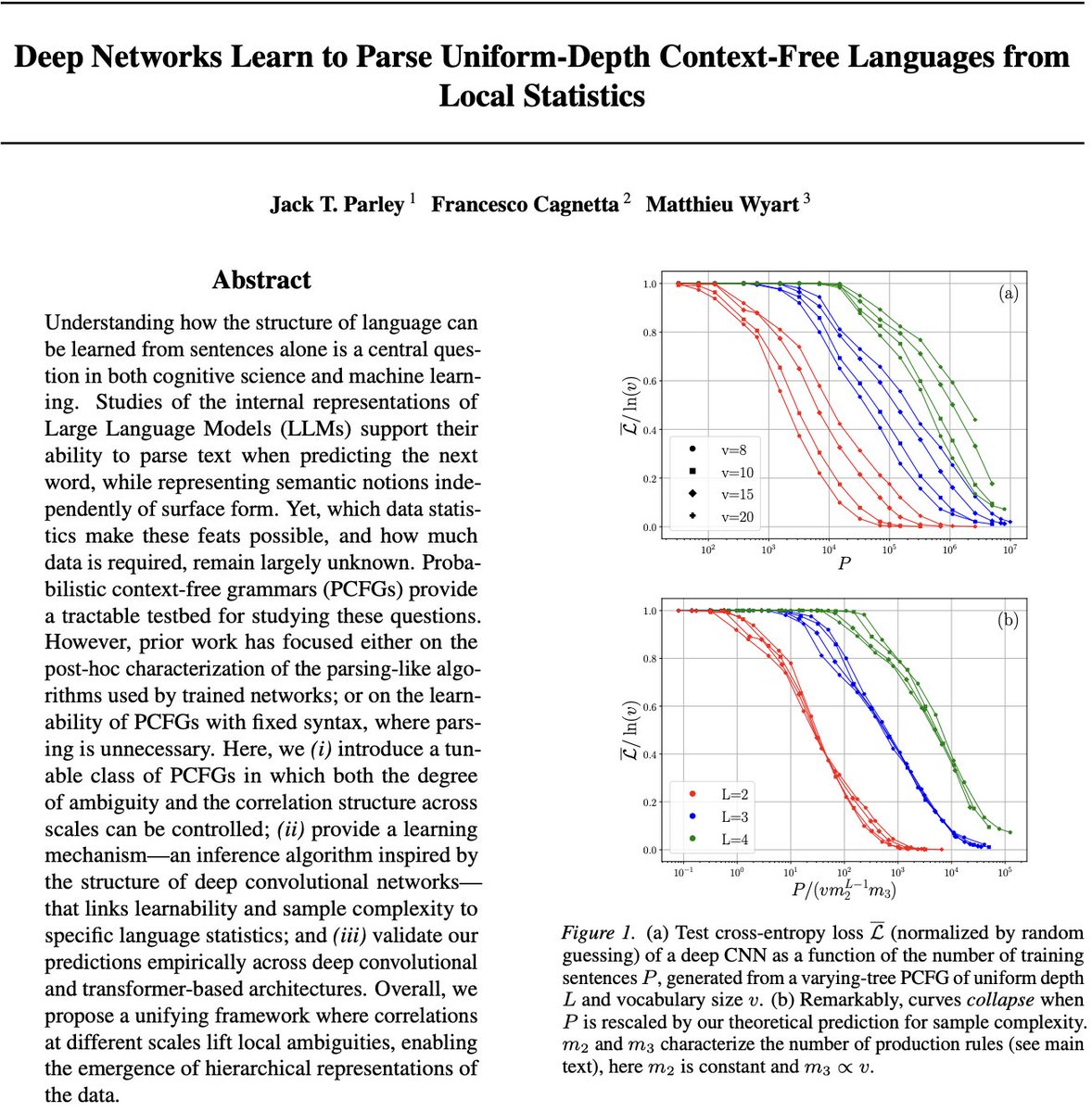
"Physics" approach to LLMs studied how synthetic languages are parsed after training, but the mechanism of learning how to parse was not known. Which correlations in data are used, and how many data are needed for that? This is answered here for a class of context-free languages.

❓ How do LLMs learn hierarchical structure from sentences alone?
🚨 We build PCFG-like synthetic datasets with two knobs---hierarchy ambiguity---and derive a correlation-based learning mechanism that predicts the sample complexity of deep nets.
Results 👇
1
10
53
5,822
Alessandro Favero retweeted

Feb 10
Our new paper "Deriving neural scaling laws from the statistics of natural language" arxiv.org/abs/2602.07488 lead by @Fraccagnetta & @AllanRaventos w/ Matthieu Wyart makes a breakthrough! We can predict data-limited neural scaling law exponents from first principles using the structure of natural language itself for the very first time!
If you give us two properties of your natural language dataset:
1) How conditional entropy of the next token decays with conditioning length.
2) How pairwise token correlations decay with time separation.
Then we can give you the exponent of the neural scaling law (loss versus data amount) through a simple formula!
The key idea is that as you increase the amount of training data, models can look further back in the past to predict, and as long as they do this well, the conditional entropy of the next token, conditioned on all tokens up to this data-dependent prediction time horizon, completely governs the loss! This gets us our simple formula for the neural scaling law!
20
118
574
61,556
Feb 10
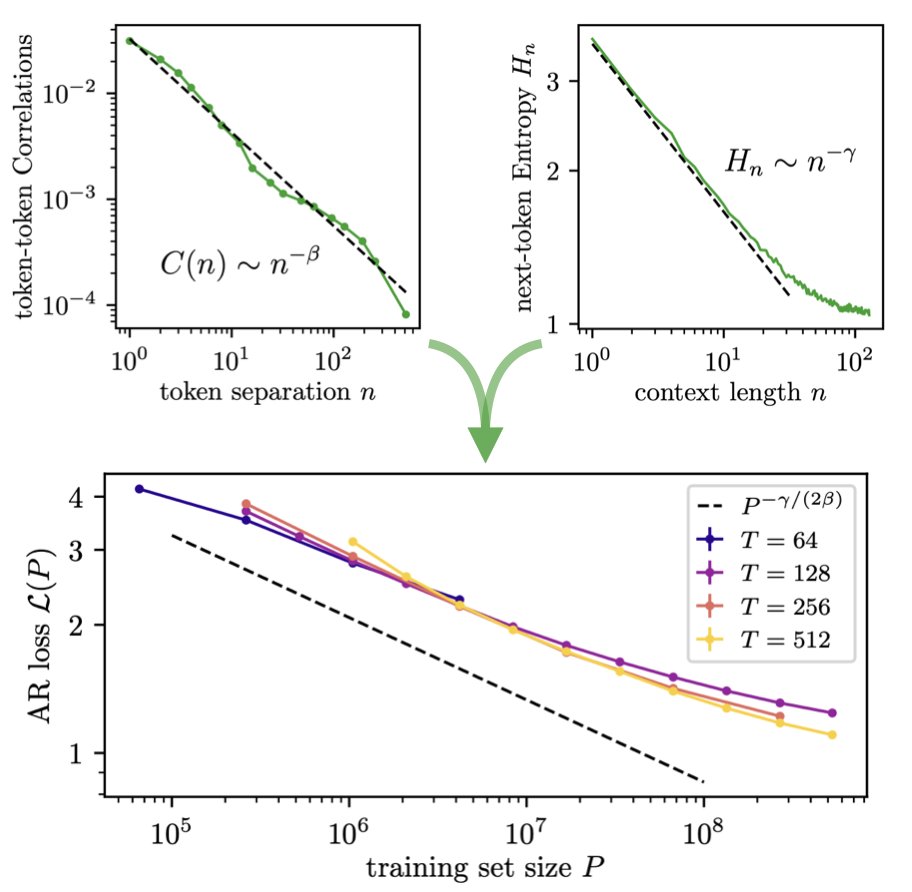
Super cool work predicting the scaling exponents of pre-trained LLMs from language statistics alone.
🚨 We derive data-limited neural scaling exponents directly from measurable corpus statistics.
No synthetic data models, only two ingredients:
-decay of token-token correlations with separation;
-decay of next-token conditional entropy with context length.
5
327
Alessandro Favero retweeted

Check out our latest work on how neural language models learn to parse PCFGs from local stats!
❓ How do LLMs learn hierarchical structure from sentences alone?
🚨 We build PCFG-like synthetic datasets with two knobs---hierarchy ambiguity---and derive a correlation-based learning mechanism that predicts the sample complexity of deep nets.
Results 👇
1
6
579
Alessandro Favero retweeted

❓ How do LLMs learn hierarchical structure from sentences alone?
🚨 We build PCFG-like synthetic datasets with two knobs---hierarchy ambiguity---and derive a correlation-based learning mechanism that predicts the sample complexity of deep nets.
Results 👇
3
16
105
16,689
Alessandro Favero retweeted

23 Dec 2025
This is an annual reminder that the no free lunch theorems are irrelevant. The assumptions they make are completely divorced from the world we live in. They should have no bearing on model construction. Let's make this a monthly mantra.
16
17
298
50,627