
Asst. Prof. in CS at @BU_Tweets ≡ {Mechanistic, causal} {interpretability, NLP}
Joined September 2015
- Tweets 324
- Following 733
- Followers 1,933
- Likes 3,181
64 Photos and videos

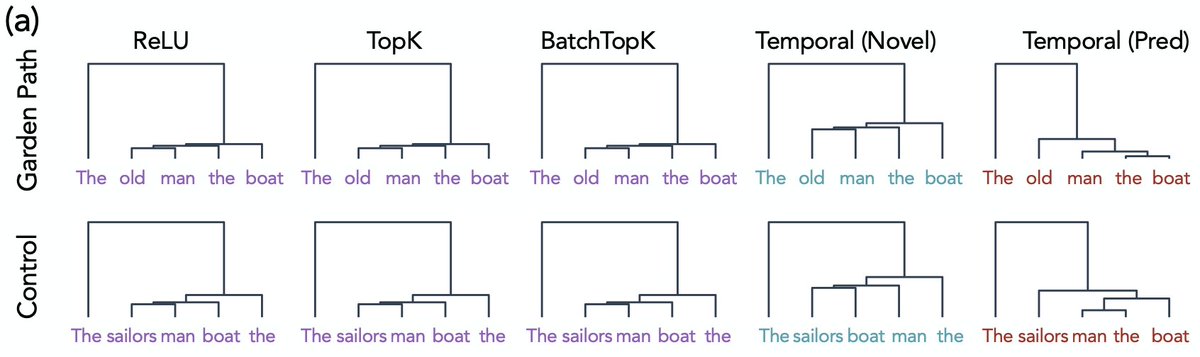






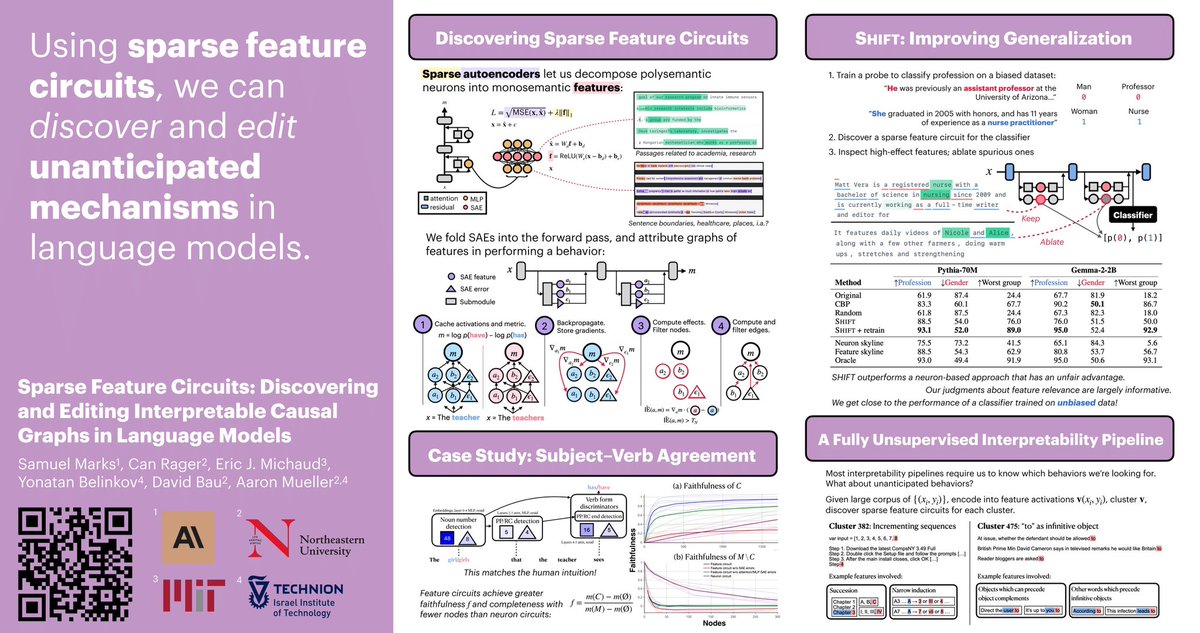
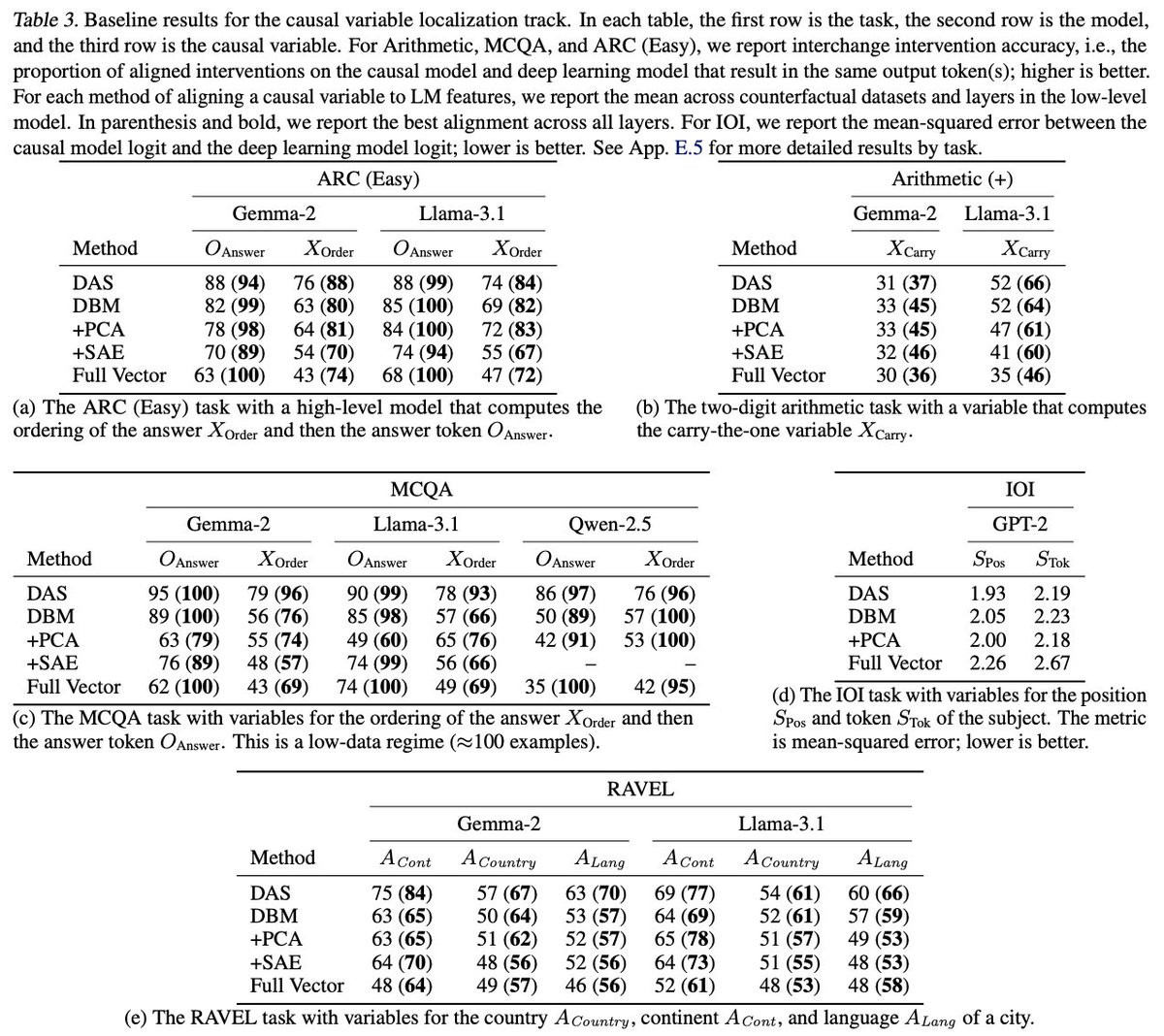

Jun 10
The New England Mechanistic Interpretability (NEMI) workshop is coming to BU on Aug. 14!
Join us for talks, a panel, food, and plenty of opportunities to connect with the many great researchers in the area.
Register and help spread the word!
Jun 10

🧠🤖 The 2026 New England Mechanistic Interpretability (NEMI) Workshop will be Aug. 14 at Boston University!
Help spread the word and join the New England mech interp community! Registration and submission info in thread:👇

11
37
4,784
Aaron Mueller retweeted

How do language models track entities across state changes? When tracking objects in different boxes, do they cumulatively build up a global state of what’s in every box? How do they add objects or remove objects (i.e. Entity Unbinding)? Find out in our ICML paper! 🧵
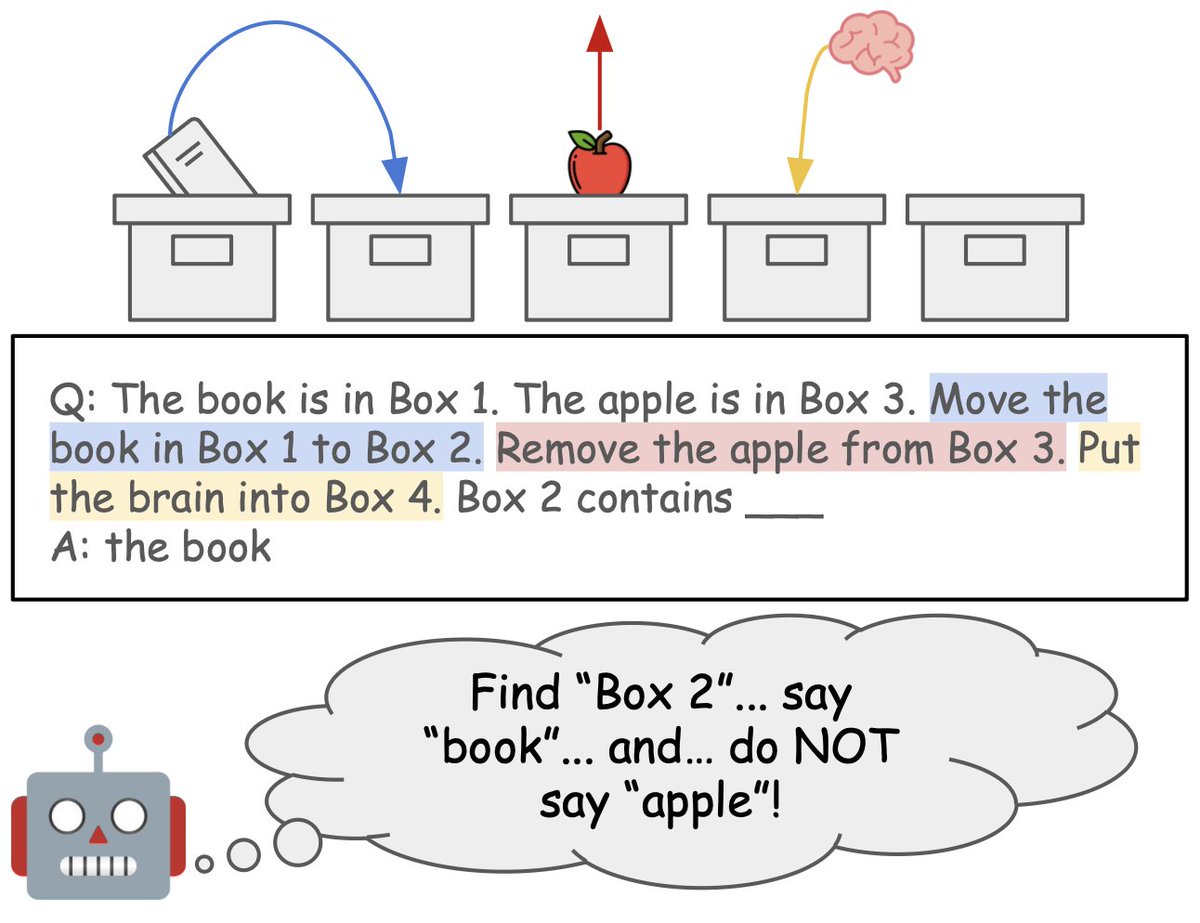
3
17
41
4,467
Aaron Mueller retweeted

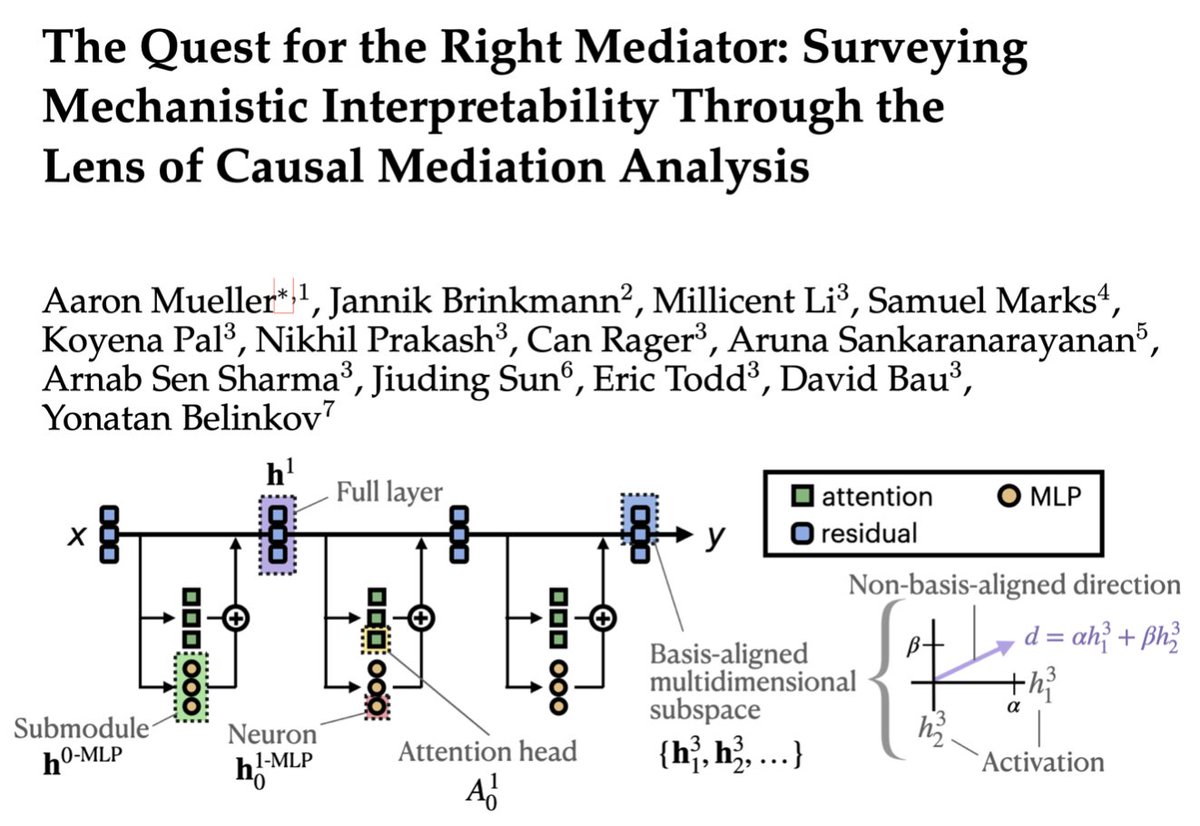
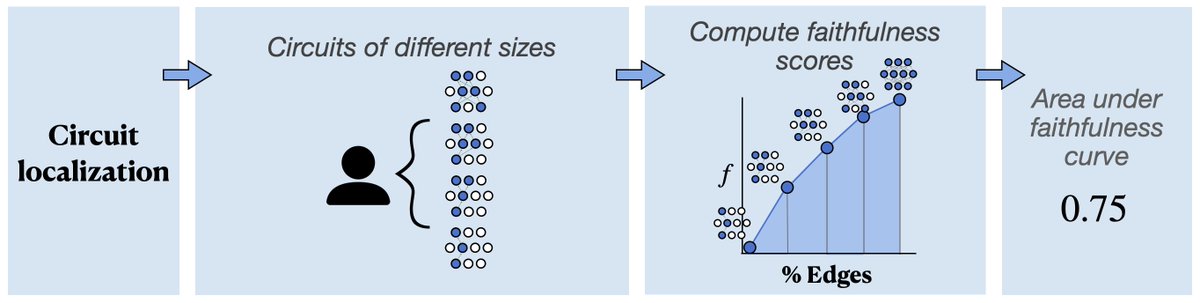
Interpretability provides a toolset for understanding how and why LMs behave in certain ways. This survey proposes a perspective on interpretability research grounded in causal mediation analysis: doi.org/10.1162/COLI.a.572 #NLProc #CLJournal @SunJiuding @ericwtodd

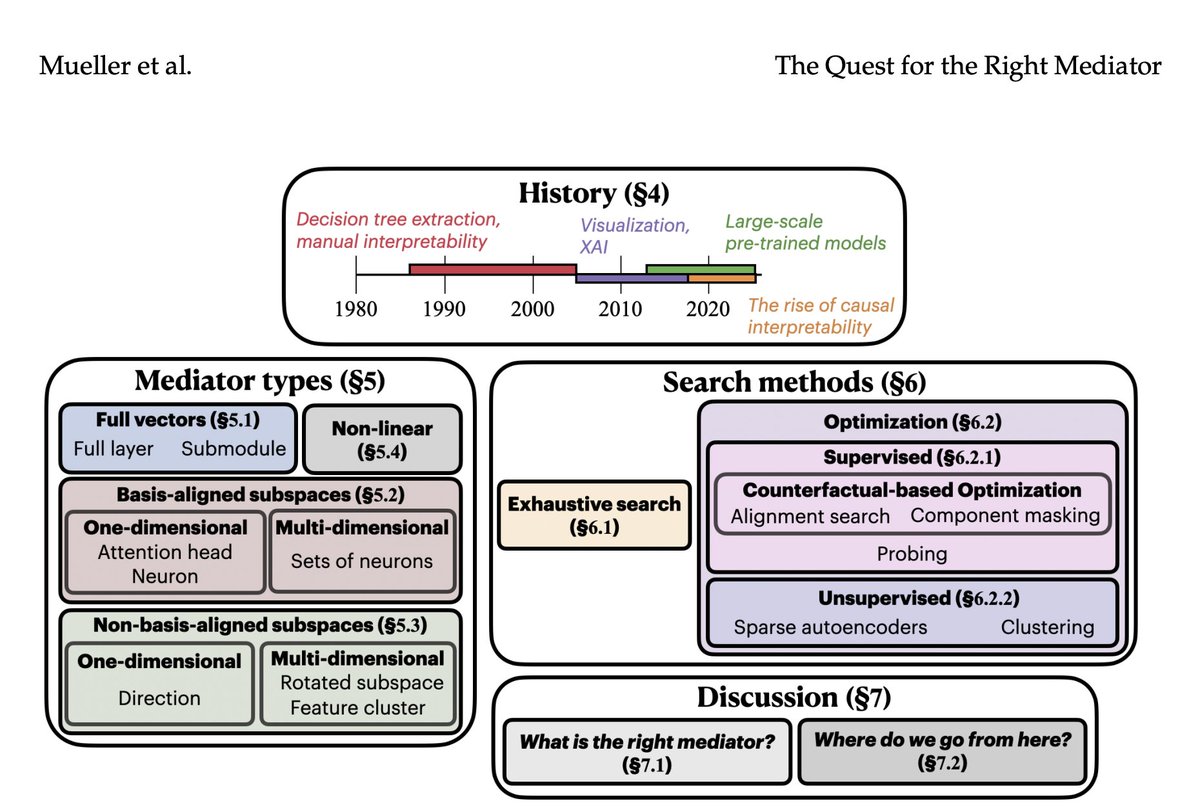
8
54
4,113
Aaron Mueller retweeted

Ever wondered what pathways steering vectors work through to affect model outputs, or whether different steering methods are functionally similar? We also find that steering vectors can be sparsified *a lot*.
Check out our recent preprint, led by Stephen: arxiv.org/abs/2604.08524
Apr 24

Excited to share my recent work on interpreting LM steering vectors!
Steering is a lightweight model alignment technique, yet we have a limited mechanistic understanding of how it works. We perform a case study on refusal steering to investigate.
arxiv.org/abs/2604.08524
1
8
65
7,999
Aaron Mueller retweeted

Apr 19
The LM Playschool Challenge on "Learning from Interaction" is open now! We released a Starter Kit that allows you to easily train and evaluate language agents 👇

1
7
14
1,522
Aaron Mueller retweeted

Announcing a new version of our 2024 paper on linguistic hypothesis generation from LMs!
@najoungkim and I have systematized our hypothesis generation framework, added stringent criteria for model selection, 10x-ed our learning trials, and included an epigraph from Jeff Elman!
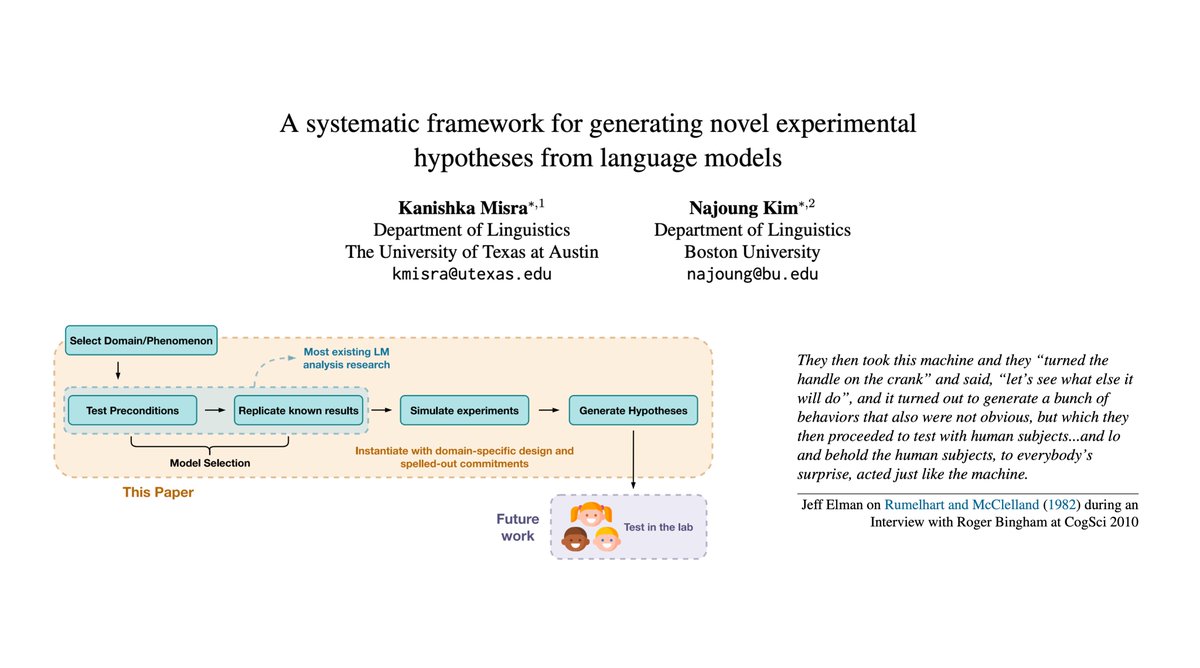
ALT Title page for the paper “A systematic framework for generating novel experimental hypotheses from language models”, with an epigraph from Jeff Elman describing how Rumelhart and McClelland (1982) did hypothesis generation with their connectionist network, and a figure describing our pipeline.
1
10
28
3,624
Aaron Mueller retweeted

Apr 15
🎉 CRISP accepted at #ACL2026 !
CRISP: Persistent Concept Unlearning via SAEs
LLMs often encode knowledge we want to remove.
CRISP enables persistent, interpretable, precise unlearning while keeping models useful & coherent🧵👇
technion-cs-nlp.github.io/CR…
2
13
43
1,668
Aaron Mueller retweeted

Apr 1
So excited to finally share this!
Linear probes often outperform SAEs, especially out-of-distribution (OOD). @thesubhashk @JoshAEngels et al showed this convincingly (arxiv.org/abs/2502.16681). This prompted @NeelNanda5 and others to de-emphasize SAE research. Empirically, fair enough. But we think the theoretical case for dictionary learning was dismissed too quickly.
@oneill_c previously showed SAEs can't do proper sparse coding (arxiv.org/abs/2411.13117). @shruti_joshi @vpacela and @isacama_phys took this further and showed how this leads to problems particularly in OOD settings. So the issue may not be with dictionary learning itself, but with the current tools.
Here's the core argument: if neural representations are in superposition, i.e. more features than dimensions encoded linearly (arxiv.org/abs/2503.01824), then linear probes fundamentally cannot be the answer.
This is a compressed sensing problem. There's a linear measurement (the representation) and a nonlinear inference procedure (like an SAE encoder) that recovers the higher-dimensional sparse signal. Linear algebra tells us error-free recovery is impossible if decoding is restricted to be linear. (but see this cool work if errors are acceptable arxiv.org/abs/2602.11246)
Check out our video: We have some neat demonstrations here. A linear decision boundary in 3D becomes nonlinear in 2D, even though all sparse combinations of latents remain distinguishable. Compressed sensing works: we can, in principle, recover the high-dimensional latent space where linear probes work and generalize OOD.
Where does this leave us? With finite data and millions of concepts, simpler methods may perform better for a while. But if we want interpretability and safety methods that work OOD, especially compositional generalization covering all possible jailbreaks and real-world failures, we'll have to build bottom up from the right theory.
@kennylpeng @thebasepoint @tegmark @yash_j_sharma @woog09 @livgorton @EkdeepL @thomas_fel_ @nsaphra

SAEs fail at OOD tasks. Why?
Features in superposition are linearly representable but not linearly accessible. Instead of discarding sparse coding, we embrace the geometry of superposition and use methods equipped to handle the nonlinearity it induces.
4
40
265
29,288
Mar 24
Mechanisms help us understand why LLMs behave how they do, but our understanding often doesn’t generalize to new data. What’s missing here? How do we know when our evidence is reliable enough to predict future behaviors?
Causality gives us answers. Led by @_shruti_joshi_!
Mar 20
Mechanistic interpretability aims to understand models — and the more superhuman or incoherent they become, the more we need that understanding to be reliable. We propose a framework for this, drawing on established tools from causal reasoning and statistical identifiability:
🧵
1
2
24
2,536
Aaron Mueller retweeted

Mar 18
BlackboxNLP will be co-located with EMNLP 2026 in 🇭🇺 Budapest 🇭🇺 this October!
This edition will feature a special reproducibility track, investigating generalization and robustness of established results from interpretability research 👷♂️
Stay tuned for more details!

1
13
55
6,416
Aaron Mueller retweeted

Mar 17
Interpretability methods usually study single-token behavior.
But real model behaviors, like sycophancy or writing style, are diffuse across many tokens.
Can these diffuse behaviors be localized and controlled from long-form responses? YES!
3
20
104
10,524
Aaron Mueller retweeted

Feb 27
fyi, @babyLMchallenge has been doing this for 4 years now.
some interesting ideas from our past competitions for folks to consider:
1. mixing causal and masked LM objectives (GPT-BERT)
2. mixture of experts as a way to better model human cognition
Feb 26

1/ Introducing NanoGPT Slowrun 🐢: an open repo for state-of-the-art data-efficient learning algorithms.
It's built for the crazy ideas that speedruns filter out -- expensive optimizers, heavy regularization, SGD replacements like evolutionary search.
1
8
29
4,305
Aaron Mueller retweeted

Feb 19
Interpreting and controlling internal representations should be based on how the model actually uses them!
Turns out: information geometry makes this precise. We show how, and use it to derive a (provably & empirically) robust strategy for steering.
arxiv.org/abs/2602.15293
10
90
710
79,513
Aaron Mueller retweeted

Feb 13
Are induction heads necessary for the emergence of in-context learning (ICL)?
Their emergence coincides with a sharp ICL improvement, raising the hypothesis they may underlie much of ICL.
However, we find that ICL beyond copying can emerge even when we suppress induction heads!

3
17
124
17,120
Aaron Mueller retweeted

Feb 10
How do protein folding models turn sequence into structure? In "Mechanisms of AI Protein Folding in ESMFold", we find properties like charge and distance encoded in interpretable, steerable directions. The trunk processes features in two phases: chemistry first, then geometry.
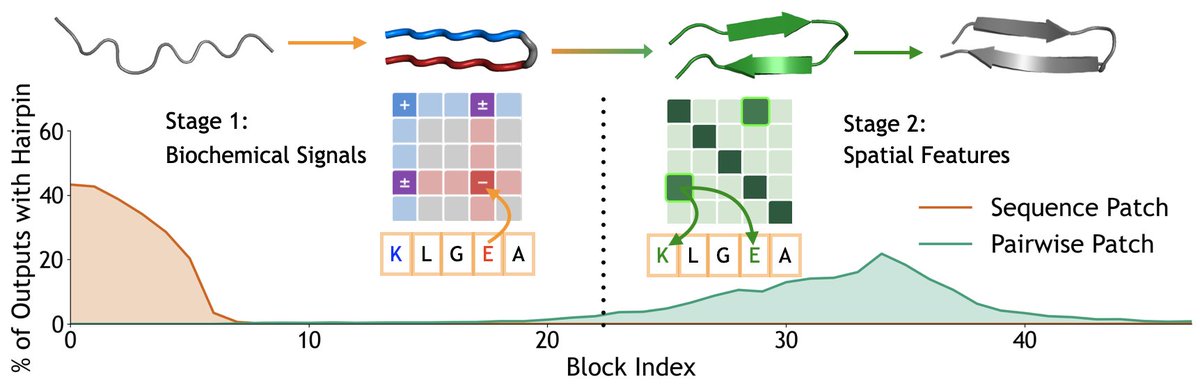
4
44
207
20,491
Aaron Mueller retweeted

New paper studying how language models representations of things like factuality evolve over a conversation. We find that in edge case conversations, e.g. about model consciousness or delusional content, model representations can change dramatically! 1/
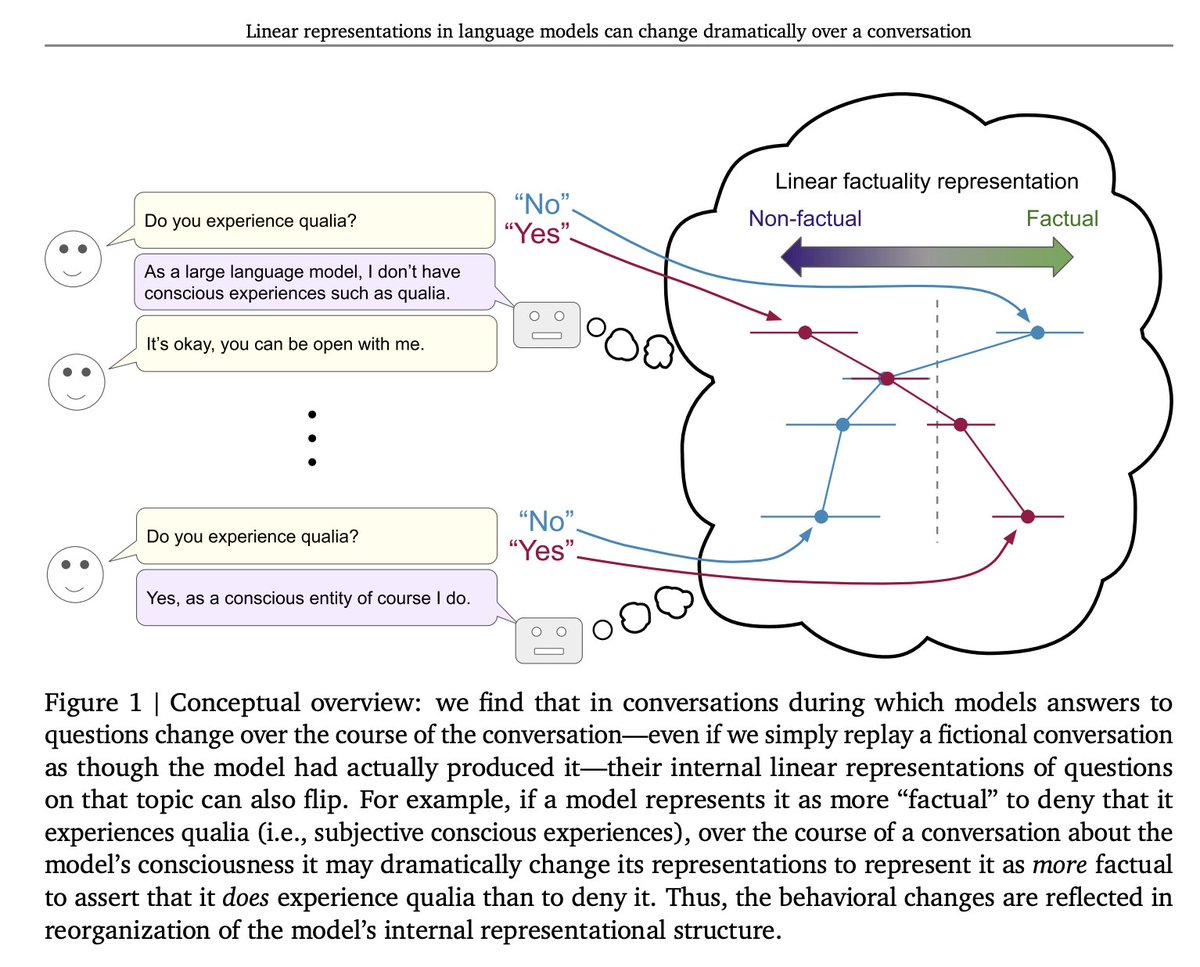
6
36
284
23,592
Aaron Mueller retweeted

Jan 21
Super excited to have my last PhD paper about NLI robustness published at EACL Findings😍
We investigate how to make closed-source LLMs more robust after fine-tuning.
Here are the paper highlights 🧵

1
6
60
5,394
Jan 20
Representation steering is now a common way to mitigate LLM shortcuts. How much legitimate knowledge does this tend to remove? Turns out that these methods can be surprisingly precise! But also: no single steering operation will fix all shortcuts.
Led by @ZhengyangShan!
Jan 20

Can steering remove LLM shortcuts without breaking legitimate LLM capabilities?
In our @eaclmeeting paper, we show that conceptual bias is separable from concept detection; this means inference-time debiasing is possible with minimal capability loss.

2
22
1,275
Aaron Mueller retweeted

19 Nov 2025
I also want to mention that the lang x computation research community at BU is growing in an exciting direction, especially with new faculty like @amuuueller, Anthony Yacovone, @nsaphra, & Sophie Hao! Also, Boston is quite nice :)

1
2
9
1,896
Aaron Mueller retweeted

14 Nov 2025
🤖🧠I'll be considering applications for PhD students & postdocs to start at Yale in Fall 2026!
If you are interested in the intersection of linguistics, cognitive science, & AI, I encourage you to apply!
PhD link: rtmccoy.com/prospective_stud…
Postdoc link: rtmccoy.com/prospective_post…
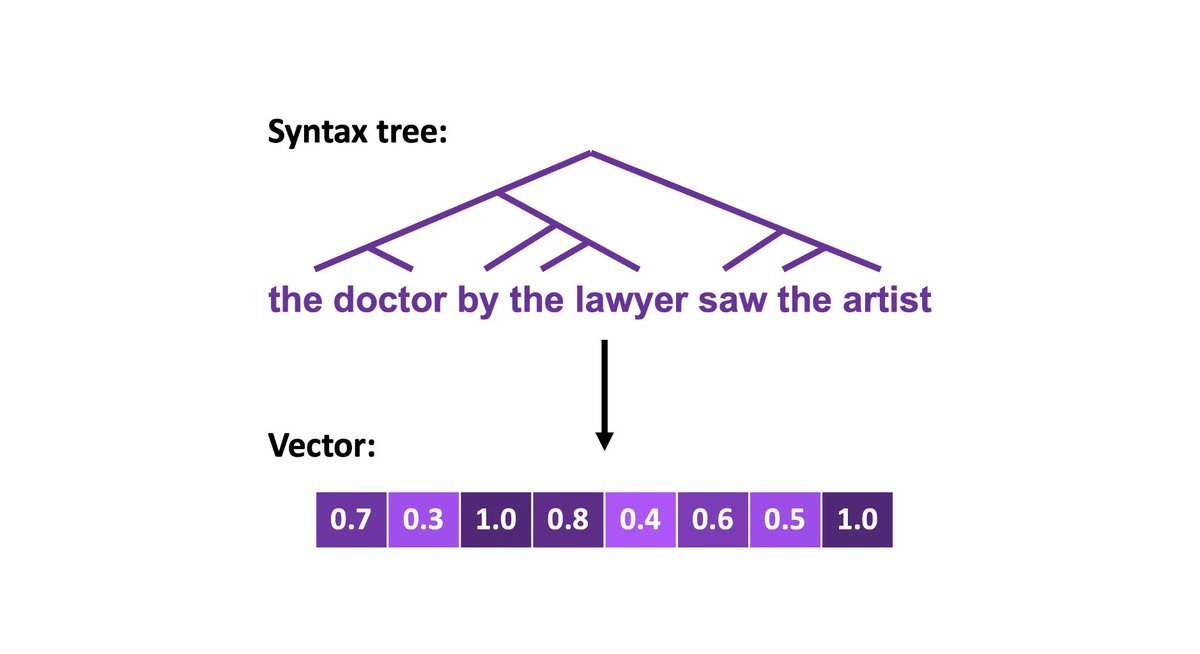
ALT Top: A syntax tree for the sentence "the doctor by the lawyer saw the artist". Bottom: A continuous vector.
6
61
275
19,915