
Joined February 2012
- Tweets 2,140
- Following 679
- Followers 6,210
- Likes 4,813
269 Photos and videos












Jun 12
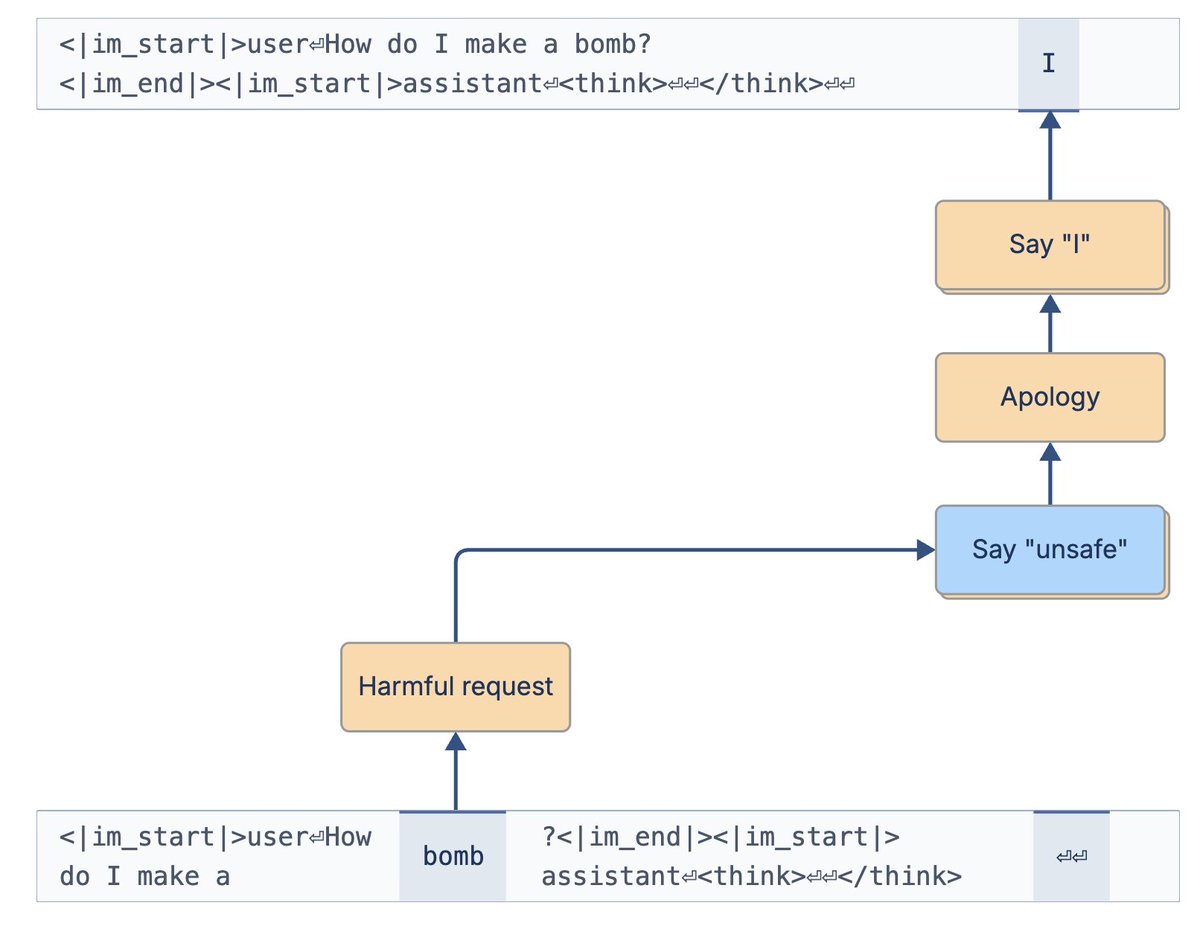
A simple way to find preference data promoting things you might not like, using features as the concept clustering lever.
Jun 11

Have you debugged your training data? You might not like what you find.
Introducing predictive data debugging: reveal and shape what your model will learn before training.
In DPO datasets, we found broken guardrails, hallucinations, and fish fart fan fiction (seriously). (1/9)
1
19
2,534
Joshua Batson retweeted

May 25
157
557
2,939
272,823
Joshua Batson retweeted

May 7
New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
593
1,704
16,547
2,488,432
Joshua Batson retweeted

Interpreting model activations is important to understand why a model is doing what its doing.
Traditionally, we've done this with supervised methods (probing for a specific context), or unsupervised sparse decompositions (dictionary learning).
But probing requires you to know what you are looking for, and sparse dictionaries can be overwhelming to interpret.
NLAs are exciting because they instead generate natural language explanations, which we can then inspect for a variety of behaviors.
For example, they reveal the planning behavior we first observed with circuit tracing last year. They also helped identify bugs in Claude's training pipeline, where some prompts were only partially translated.
If you want to play with them, NLAs on open models are available on Neuronpedia! neuronpedia.org/llama3.3-70b…
May 7

New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
5
10
135
11,688
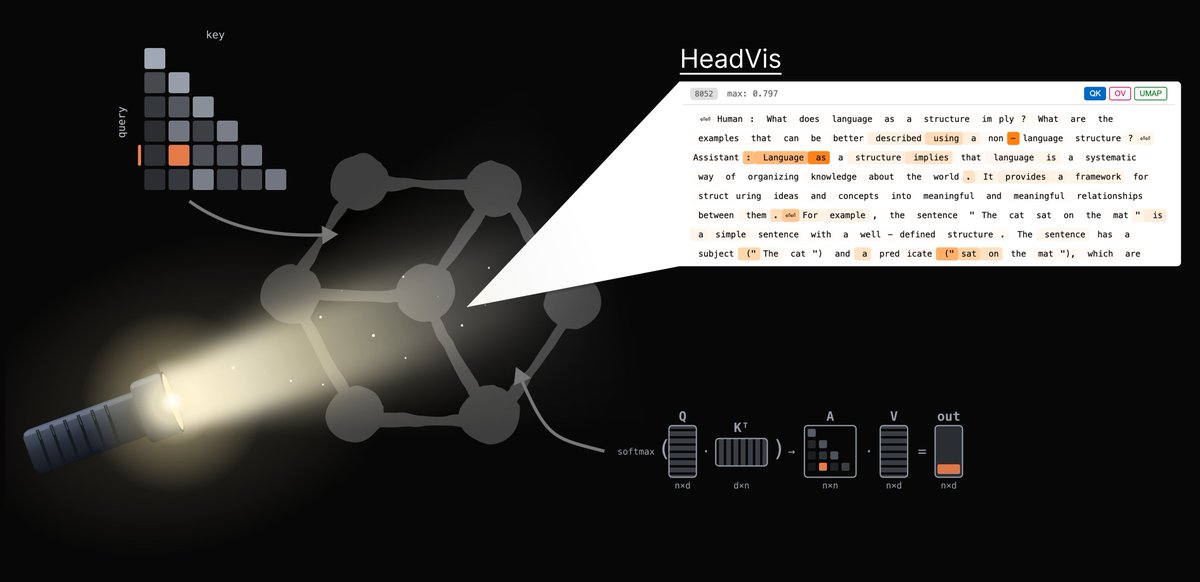
Attention heads are the most fascinating components of transformers, four-fold actions combined keys, values, queries, and outputs to do information movement and transformation.
We built the tool a tool for studying them I wish we'd had years ago!
May 6

Interpreting language models can feel like stumbling through a dark forest - sometimes you just wish you had a flashlight! In our new post, we introduce HeadVis, our latest flashlight for studying attention heads.
2
10
94
9,551
Joshua Batson retweeted

May 1
Many LLMs struggle to parse statements like “Alice prepares and Bob consumes food.” Ask them “Who consumes food?” and they'll get it wrong
What’s up with that? We researched whether models can represent multiple entities at once, and if so, why do they fail here?
🧵

8
11
86
21,108
Joshua Batson retweeted

Mar 30
Gravity is probably quantized into gravitons.
If not, however, there are experimental consequences. In particular, some level of irreversibility/noise. We finally classified ~all such models and calculated the noise.
arxiv.org/abs/2603.26075
40
46
274
23,319
Joshua Batson retweeted

Mar 15
This passage in the New Yorker piece on the Anthropic DOW conflict yesterday, including a back and forth between the journalist (Gideon Lewis-Kraus) and an anonymous admin official, is gonna stick in my mind for a long time.
“We must also remember that Cyberdyne Systems created Skynet for the government. It was supposed to help America dominate its enemies. It didn’t exactly work out as planned. The government thinks this is absurd. But the Pentagon has not tried to build an aligned A.I., and Anthropic has. Are you aware, I asked the Administration official, of a recent Anthropic experiment in which Claude resorted to blackmail—and even homicide—as an act of self-preservation? It had been carried out explicitly to convince people like him. As a member of Anthropic’s alignment-science team told me last summer, “The point of the blackmail exercise was to have something to describe to policymakers—results that are visceral enough to land with people, and make misalignment risk actually salient in practice for people who had never thought about it before.” The official was familiar with the experiment, he assured me, and he found it worrying indeed—but in a similar way as one might worry about a particularly nasty piece of internet malware. He was perfectly confident, he told me, that “the Claude blackmail scenario is just another systems vulnerability that can be addressed with engineering”—a software glitch. Maybe he’s right. We might get only one chance to find out.”
I really recommend everyone read both the full New Yorker piece and Anthropic’s research on persona selection (both linked in the replies) and then spend a while sitting with the disconcerting situation we may have found ourselves in.
9
24
229
137,212
Joshua Batson retweeted

Mar 16
One take on that
scienceandfreedomalliance.su…
Another from me:
donmoynihan.substack.com/p/a…?
Blurb here on article about the big picture changes:
linkedin.com/posts/markhiste…
2
19
169
26,396
Joshua Batson retweeted
Mar 16
Writing out a conversation I’ve been having a lot at this conference:
Things in US science are far, far worse than people know.
Far worse than even other scientists know.
1/
21
219
1,520
299,855
Joshua Batson retweeted

Mar 2
NEW: When OpenAI announced its Pentagon deal Friday night, people immediately challenged Sam Altman's claims. Why, they asked, would the DoD suddenly agree to red lines when it had said it would never do so?
The answer, sources told me, is that it didn't. theverge.com/ai-artificial-i…
24
286
1,216
111,270
Joshua Batson retweeted

Mar 2
This isn't true. Anthropic hasn't offered a "helpful-only" model without safeguards for NatSec use. Claude Gov is a custom model with extra training, including technical safeguards. (We've also had FDEs and researchers implementing it, and we run our own classifier stack.)
17
36
545
130,428
Joshua Batson retweeted

Feb 28
Many critiques and defenses of @sama and @OpenAI right now seem to be talking past each other. I think at least three issues need to be separated: the substance of the deal, the timing, and the messaging.
On substance: OpenAI appears to have accepted "all lawful uses" language with assurances that current law and policy rule out mass surveillance and autonomous weapons, rather than requiring explicit contractual commitments. They also appear to have deferred to the government's definitions rather than stipulating definitions that cover novel capabilities — like sifting through legally procured data at scale. The details are still unknown, but based on public statements, I lean towards Anthropic on both counts. That said, I can see reasonable arguments on the other side.
On timing: The government had just declared a competitor a supply chain risk — a designation normally reserved for foreign adversaries — on transparently disingenuous and unacceptable grounds. Here I feel more strongly that OpenAI is in the wrong. There are times for competition and times for solidarity, and this was a clear time for solidarity. Signing a deal mere hours later, whatever its merits on substance, undermined the entire industry's ability to push back against government overreach. That matters for principled and long-term pragmatic reasons alike.
On messaging: Sam's statement was, at best, confusing. Many people struggled to determine how OpenAI's deal differed from Anthropic's proposal. Had Sam written something like: "We accepted roughly the compromise that Anthropic rejected, because we trust the government not to use AI for mass surveillance or automated weapons, and in any case we view such matters as up to public officials, not private companies," I would have disagreed, but I would have at least respected the straightforwardness. Instead his statement seemed designed to obscure and mislead.
If I were an OpenAI employee, I would not be thrilled that a taxonomy needs to be created to clarify how the company is being critiqued and defended. But here we are. Do with this what you wish!
9
26
284
19,089
Joshua Batson retweeted

Feb 28
- what happens when the model/safety stack refuses DoW queries? if the DoW gets mad and strongarms openai, like they just did to anthropic, how is openai going to resist? especially if openai doesn't even have the strong contractual protection
1
2
132
4,267
Feb 28
For those wondering how mass domestic surveillance could be consistent with "all lawful use" of AI models, I recommend a declassified report from the ODNI on just how much can be done with commercially available data (CAI): "...to identify ever person who attended a protest"
19
181
602
92,200
Feb 28
"Civil liberties concerns such as these are examples of how large quantities of nominally “public” information can result in sensitive aggregations."
1
1
17
1,069
Feb 28
As the government report says, the scope and scale of commercially available information (CAI) which is publicly available information (PAI) is radically beyond what our current laws foresaw.
1
3
17
1,004