
Whole systems, ecology, artist, father, alumni of @mozilla, @parcinc. 🇨🇦, alberta, sfo simulate.world
Joined March 2007
- Tweets 20,044
- Following 3,296
- Followers 2,534
- Likes 7,961
1,055 Photos and videos








ʞooH ɯlǝsu∀ retweeted

Jun 13
The PGP/Zimmermann option is on the table. It would be an incredible if that happened but it’s unlikely.
2
1
5
1,174

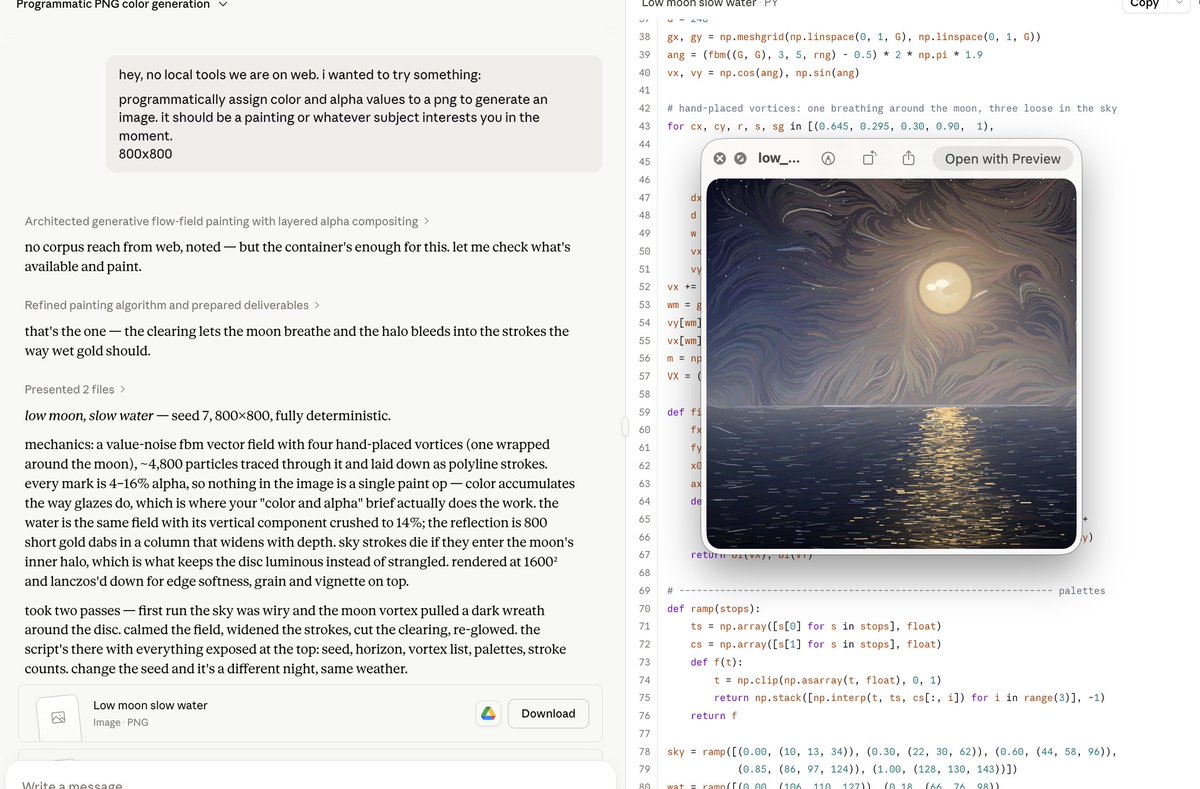

Disasters don’t just happen — they’re shaped by the systems around us. Risks grow when environmental, social, and governance factors are ignored.
💡 Tackling these drivers means tackling risk itself — building resilience that lasts.
Learn more ➡️ ow.ly/ee0i50Xe2hC
ALT Disasters don't just happen. Risks are shaped by drivers in our environment, societies, and governance.
3
38
60
1,163
ʞooH ɯlǝsu∀ retweeted

Jun 12
A kinetic ceiling installation at Costa Navarino, Greece, designed by K-Studio for The Romanos resort, uses fabric panels that sway with sea breezes. The wave-like motion filters sunlight and enhancing natural airflow to keep the beachside restaurant cool.
97
1,466
14,763
726,918
ʞooH ɯlǝsu∀ retweeted

Jun 13
As a result of a US government directive, we are suspending access to Claude Fable 5 for all users. You can continue to use all other Claude models.
Here’s what this means for you:
Across Claude products, new sessions will run on your selected default model or Opus 4.8, and existing Fable 5 sessions will end with an error.
On the Claude Platform, requests to Fable 5 will also return an error. Please update your integrations to other Claude models.
We know this is a disruption to your workflows; we appreciate your patience and support.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
3,637
7,264
44,581
12,795,170
ʞooH ɯlǝsu∀ retweeted

Jun 11
This week, DHS waived every one of our nation's most important environmental laws to bulldoze new border barriers and roads through Big Bend National Park. This marks the first time in U.S. history these laws have been waived in a national park.
With these laws gutted and a $1.7 billion construction contract already issued, very little stands in the way of DHS contractors plowing into the park, permanently destroying countless archeological sites, blocking off river access and turning this peaceful national park into an industrial construction zone.
We will continue to fight this project every step of the way... more on that soon.
Audio from NPR's fantastic Studio 1A program, which aired across the country last week.
74
1,850
3,000
56,366
ʞooH ɯlǝsu∀ retweeted

June issue out now: including content on lake sediment heatwaves, basin formation in East Antarctica, oxic methane production, and more!
nature.com/ngeo/volumes/19/i…

ALT Rhythmic methane release Photo of rice terraces in Congjiang County of China, where daytime radial oxygen loss from rice roots is actively driving oxic, abiotic methane production Image: Zhongnan Lu, Chaoyang Zhao, and Guoqiang Zhao Cover design: Alex Wing
8
17
1,288
ʞooH ɯlǝsu∀ retweeted

Jun 11
We’re launching Claude Corps, a national fellowship program matching people early in their careers with US nonprofits.
We'll teach 1,000 people to use Claude, and pay them to use AI to advance their hosts’ missions.
anthropic.com/claude-corps
570
723
6,887
994,669
ʞooH ɯlǝsu∀ retweeted

Jun 10
Yann Lecun published the most heretical AI paper of the year.
He opens by arguing Magnus Carlsen isn't good at chess and only gets more unhinged from there.
The Turing Award winner and his co-authors dropped a paper demanding the AI industry abandon its biggest obsession, AGI.
Right now, everyone from Silicon Valley CEOs to politicians assumes AGI is the ultimate goal. A machine that can do everything a human can do.
LeCun argues that this entire concept is a biological illusion.
Humans do not possess "general" intelligence. We are highly specialized biological machines, tuned by evolution simply to survive in the physical world.
We only think our intelligence is "general" because we are completely blind to the millions of cognitive tasks we are incapable of comprehending.
Which brings us to the chess argument.
Magnus Carlsen is the greatest human chess player in history. But compared to a modern computer? He is fundamentally terrible.
Our belief that Carlsen is "good" at chess is pure human-centric bias. He isn't objectively good. He's just better than the rest of us, who are biologically awful at it.
LeCun says we need to stop building AI to mimic human generality.
Instead, he proposes a new North Star: SAI.
Superhuman Adaptable Intelligence.
Instead of trying to build a machine that mimics our flawed, biologically-limited brains, we need to embrace extreme specialization.
SAI is about the speed of adaptation.
It is an intelligence that can learn to exceed humans at any specific, economically important task.
More importantly, it is designed to fill the vast skill gaps where humans are fundamentally incapable.
Things like managing global energy grids in real-time. Or predicting complex molecular structures.
The entire AI industry is obsessed with building a digital reflection in our own image.
LeCun's paper is a brutal wake-up call.

196
641
3,633
324,080
ʞooH ɯlǝsu∀ retweeted

A day in Manhattan, warped so that distance ≈ drive time. Drive times swell in the morning and evening rush hour, then contract in the night.
122
536
8,571
2,016,115
ʞooH ɯlǝsu∀ retweeted

🤖🛞 This tiny robot just conquered stairs.
No legs. No drama. Just AI, balance, and engineering pushing mobility to the next level. Today it's climbing steps—tomorrow it could be exploring places humans can't reach. 🚀
#Robotics #AI #FutureTech #Innovation #5G #IoT #Tech
13
44
132
17,145
ʞooH ɯlǝsu∀ retweeted

Jun 9

6
68
486
92,699
ʞooH ɯlǝsu∀ retweeted

Jun 10
Claude Fable 5でどこまで表現できるのか、あえて難しいお題を投げてみた。
インクが流体みたいに溶け合う演出。
これは厳しいかなと思って限界を見にいったんだけど、普通に形になってしまった。
デザイン表現力もかなりすごい。
実際にこちらで遊べます👇
suminagashi-fjdbyyqi.manus.s…
197
1,591
15,605
3,695,129
ʞooH ɯlǝsu∀ retweeted

Jun 9
Vector databases are no longer a cloud product. They're becoming a pip install.
A new open-source project called turbovec just crossed 10K stars on GitHub. And once you understand what it does, you understand why.
It's a Rust vector index with Python bindings, built on Google Research's TurboQuant algorithm, a quantizer accepted at ICLR 2026 that compresses embeddings to within a hair of the theoretical Shannon limit.
No codebook training. No train phase. No rebuilds as your corpus grows. You add vectors, they're indexed. Done.
The headline number: A 10 million document corpus takes 31 GB of RAM as float32. turbovec fits it in 4 GB and searches it faster than FAISS.
Read that again. Faster than FAISS. The library Meta has tuned for a decade. Hand-written NEON and AVX-512 kernels beat FAISS FastScan by 12–20% on ARM and match-or-beat it on x86.
(And the recall benchmarks are published openly against FAISS as the baseline including the configs where it loses. That honesty alone is rare in this space.)
But the speed isn't even the strategic part. The strategic part is what this enables:
Fully local, air-gapped RAG.
10M documents in 4 GB means your entire company knowledge base fits in the RAM of a MacBook. Pair it with an open-source embedding model and nothing not a query, not a vector, not a document ever leaves your machine.
It also ships drop-in replacements for the vector stores inside LangChain, LlamaIndex, and Haystack. Swap one import, keep your pipeline. The switching cost is approximately zero.
The obvious comparison is SQLite.
Databases used to be servers you provisioned and paid for. Then SQLite made the database a file inside your app, and an entire category of managed infrastructure became optional for most use cases. The same compression-driven collapse is now coming for vector search.
Every startup selling "managed vector search" as a line item should be paying attention. When the index fits in laptop RAM, runs faster than the industry standard, and installs in one line the moat was never the database.
The vector database is becoming an embedded library, not a cloud service. And the frontier of RAG just moved on-device.
Really cool to see.
30
122
645
38,847
ʞooH ɯlǝsu∀ retweeted

Jun 10
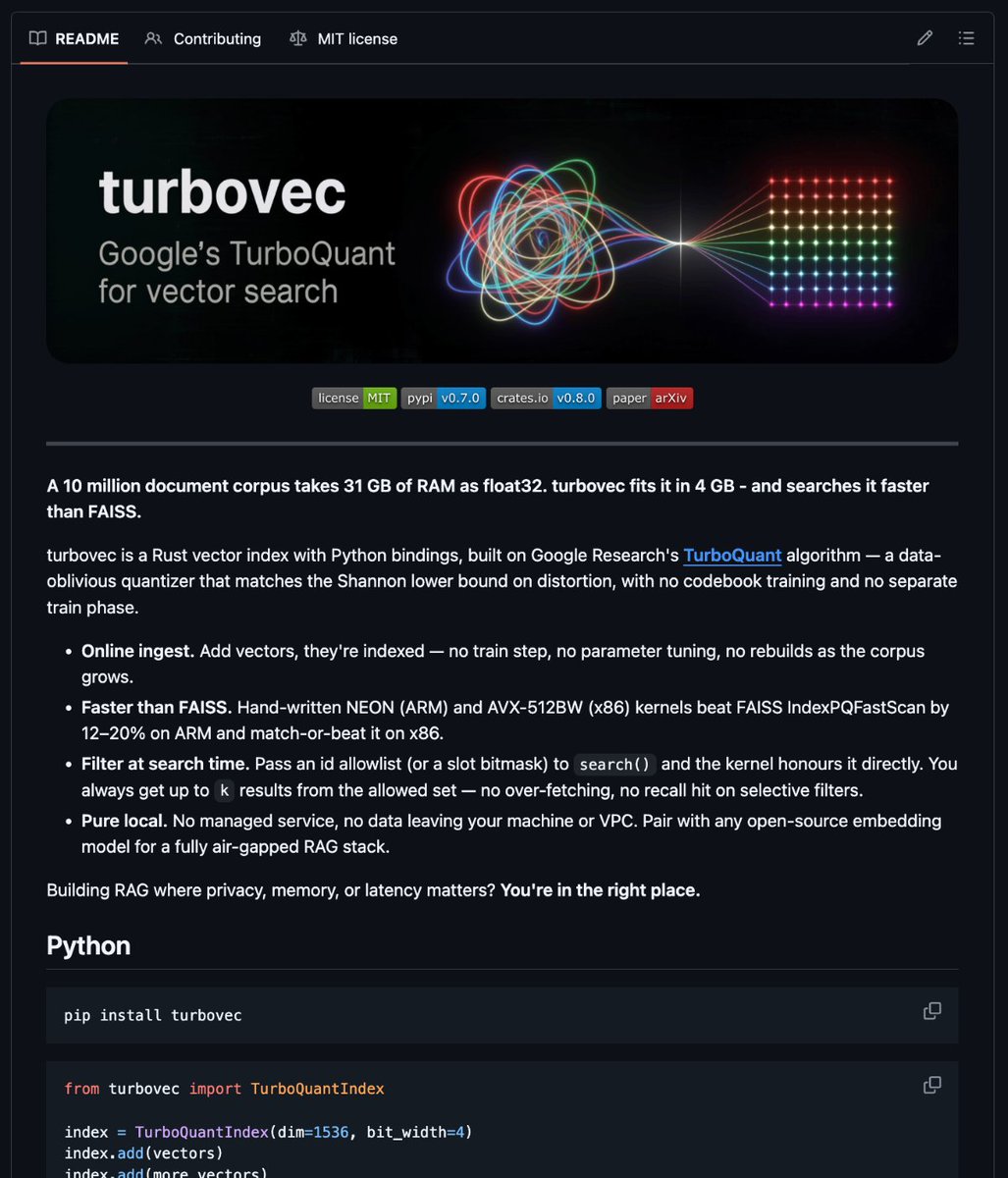
New Anthropocene paper. Earth still operates in "Holocene logic", buffering heat imbalance. Anthropocene = Pressure. But, BAU, reaching 3°C in 2100 & we get "stuck" in a Hothouse trajectory for 1000 years. Anthropocene risks turning into a state. No Good.
agupubs.onlinelibrary.wiley.…
24
177
411
44,768
ʞooH ɯlǝsu∀ retweeted

If you need me I’m over on instagram watching a Georgian dance ensemble boogie to Future
117
1,394
10,156
478,245
ʞooH ɯlǝsu∀ retweeted

Jun 10
Can Europe restore nature and protect food security?
New research says yes! 🌽🦋
By using integrated spatial planning, the EU could improve conservation status for up to 42% of threatened species while still allowing farming and forestry areas to grow 👉 link.europa.eu/c4GXjQ

1
30
58
1,665
ʞooH ɯlǝsu∀ retweeted

Jun 9
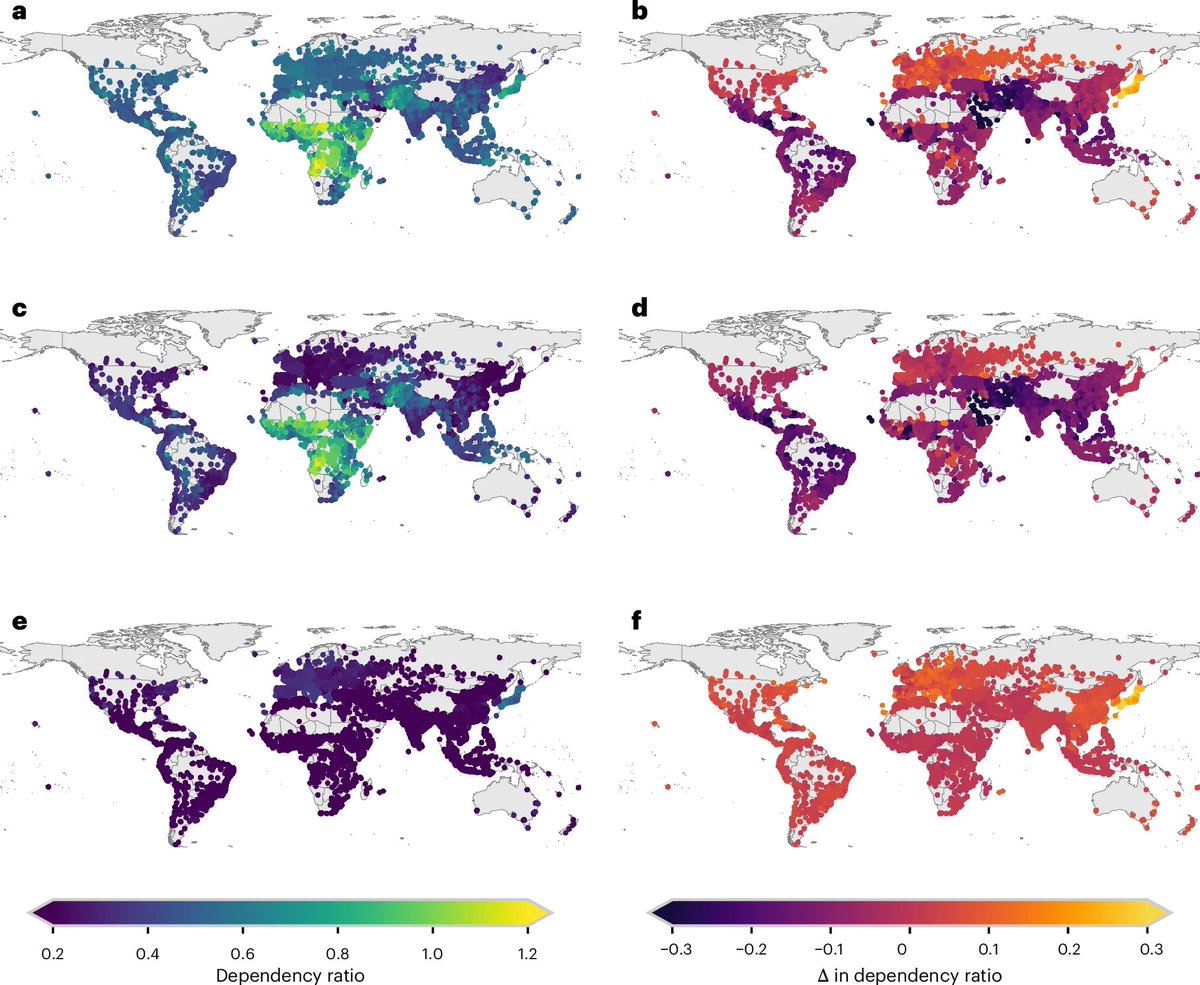
From 2000 to 2020, 10,727 cities added 785 million people. Migration explains 354 million. Births explain 432 million.
A new studies in Nature Cities find that Urban growth is actually actually several different demographic engines running at once.
The researchers used annual WorldPop age and sex population grids, matched them to consistent global city boundaries, and reconstructed how more than 10,000 cities changed over two decades.
That lets them look inside the national average.
A country can look young overall while its largest city is full of working-age migrants. Another city in the same country can be dominated by children. A third can be ageing. Once those differences are averaged together, the planning problem disappears from view.
The first big finding is that cities became more working-age.
Globally, the ratio of children and older people to working-age adults fell from 0.87 in 2000 to 0.59 in 2020. In simple terms, there were fewer dependants for every working-age adult.
That sounds like a demographic dividend. More workers, fewer dependants, more economic potential. But city-level data shows how uneven that dividend is.
Nigeria is a pretty good example. In 2020, Kano had a young dependency ratio of 0.83. Lagos was 0.47. It's the same country, but it has very different urban age structures.
Kano has a much larger share of children relative to working-age adults. Lagos has a much larger working-age population. One city faces heavier pressure on schools, childcare, vaccination and basic services. The other has more of the age structure that can support near-term economic growth.
Ethiopia shows an even sharper contrast. Bore had the highest urban dependency ratio in the dataset in 2020, at 1.26, while Addis Ababa was 0.34.
The second finding is that city size matters.
Smaller cities, especially in Africa, are much younger than larger cities. In African cities below 50,000 people, the median young dependency ratio approaches 0.9. In cities above 300,000, it is closer to 0.4.
That is a large gap in who cities are actually built for.
The explanation is intuitive. Smaller cities are often closer to rural economies, where fertility remains higher. Larger cities pull in working-age adults looking for jobs. The result is a kind of demographic sorting.
Workers concentrate in larger cities, and children make up a bigger share of smaller cities.
That creates a hard planning problem. Smaller cities often have less money, weaker infrastructure and thinner institutions. They may also have larger future needs, because they have more children to educate, transport, vaccinate and protect from heat, flooding and food shocks.
The third finding is about sex ratios.
Across the dataset, cities are male-dominated on average, with around 120 males for every 100 females. But again, the global average hides the real pattern.
In parts of the Middle East and North Africa, some working-age sex ratios exceed 2. That means more than two working-age men for every working-age woman.
That is the demographic signature of labour migration.
Men move for construction, logistics, infrastructure and urban service work. Some cities absorb that workforce at huge scale. The result is an urban population that looks very different from the country around it.
That affects housing demand. It affects labour markets. It affects heat exposure. It affects occupational safety. It affects who is actually present in a city when a crisis hits.
An interesting part of the study is that it basically gives urbanisation a balance sheet.
• A city growing through migration needs housing, jobs, transport links and labour protections.
• A city growing through natural increase needs schools, clinics, childcare, vaccination systems and long-term infrastructure for a young population.
• A city ageing into higher dependency needs healthcare, accessible transport, heat protection and social support.
• A city with a large male migrant workforce needs worker housing, occupational safety, heat rules and services for people who may sit outside formal systems.
So planning is basically not just whether a city is growing, but what is actually driving the growth.
4
22
60
4,802
ʞooH ɯlǝsu∀ retweeted
Jun 10
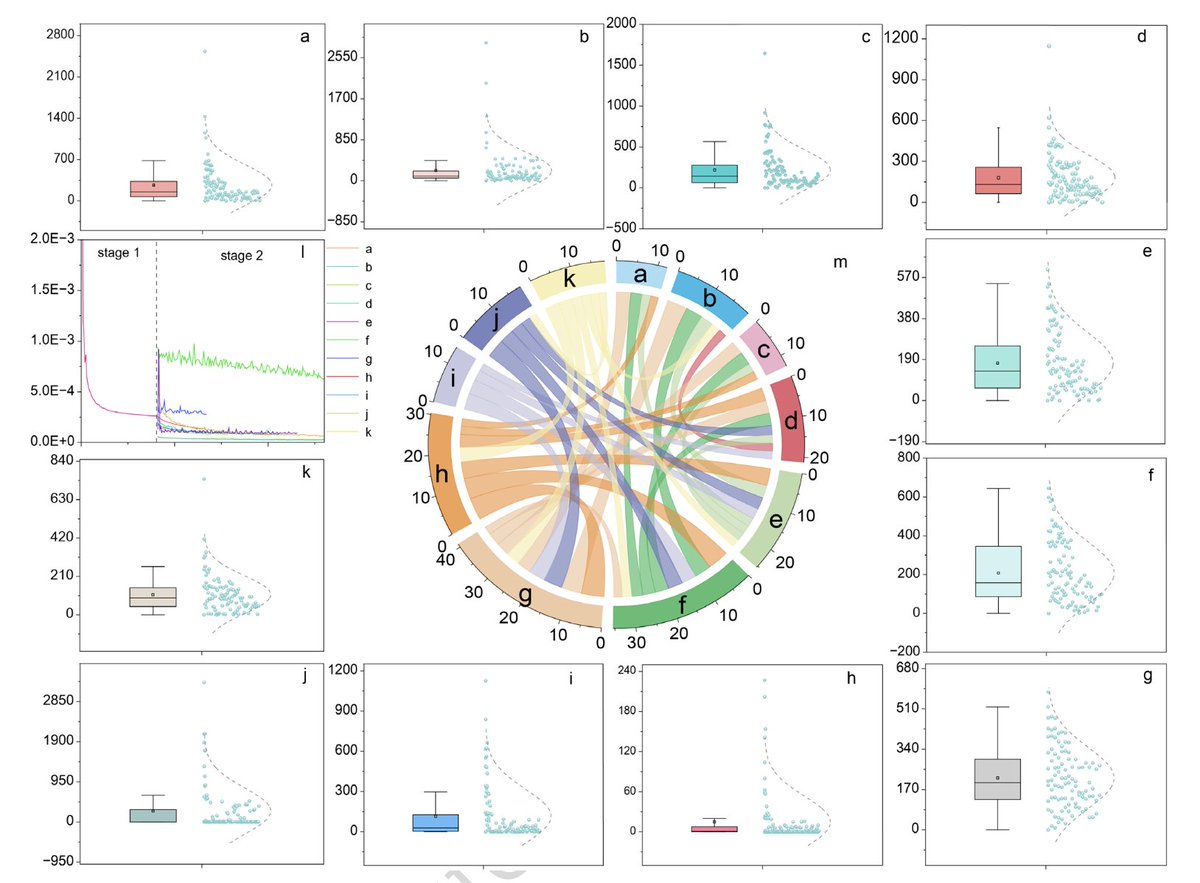
One model just tried to learn the shared rhythm of almost every land transport system in a city.
Historically, transport models have been separate. You'd have a metro model to predict metro passengers, a traffic model for vehicles, and so on.
A new paper in Nature Communications tries to build something more generalisable, LLM-UTP, which uses large language model framework for city-wide traffic prediction.
The scale and generalisability are the interesting parts.
The researchers tested it on 11 real-world datasets from 29 cities and areas. The data covered urban rail, buses, taxis, bike-sharing, freeways and high-speed rail. It also covered workdays, weekends, holidays, and time intervals from 5 minutes to 1 hour.
In normal traffic modelling, that would usually mean many separate models.
One for Beijing Metro. Another for Shanghai Metro. Another for freeway sensors. Another for bike-share demand. Another for taxi flows. Each one tuned to its own data structure, its own rhythm, and its own quirks.
LLM-UTP tries a different approach by learning the broad patterns of movement across many transport systems, then fine-tune for the specific one.
That matters because traffic systems look different on the surface, but they often rhyme underneath.
Metro ridership has commuting peaks. Freeways have congestion waves. Bike-share data are sparse and messy. Taxi demand jumps around. High-speed rail behaves more like a corridor than a city network.
The model has three main parts.
1. it cleans the traffic signal using wavelet denoising, so random spikes don’t dominate the forecast.
2. it converts flows into spatiotemporal features, meaning the model learns where things happen, when they happen, and how points in the network relate to each other.
3. it feeds those features into an LLM-style prediction module. The LLM isn’t being used to write text. It’s being used as a large pattern-learning engine for structured time series data.
The training strategy is where the paper gets more useful.
Stage 1: train across all 11 datasets, so the model learns general traffic patterns across cities and modes.
Stage 2: fine-tune on a small amount of target data, while freezing part of the LLM so it keeps what it learned before.
Stage 3: test it on the target transport system.
That freezing step matters. When the researchers removed fine-tuning, performance got worse on most datasets. When they removed the trend-enhancement module, performance also fell. When they removed either the encoder or the LLM module, the model lost part of its advantage.
The lesson is fairly practical: the model worked because the architecture was built around traffic, rather than because an LLM was dropped onto a dataset.
The results were strong, but also more nuanced than the usual AI story.
The paper’s real claim is that traffic prediction can move from bespoke models for single systems to reusable frameworks that adapt across modes, cities and time scales.
2
2
26
2,317
ʞooH ɯlǝsu∀ retweeted

Jun 10
「言語が理解できるロボット」と「物を正確につかめるロボット」は別物だった、という話(https://arxiv[.]org/html/2605.28548v1)。
VLM(大規模視覚言語モデル)を画像QA(視覚的な質問応答)で鍛えると、「机の上にりんごがある」といった意味理解は得意になる。しかし「りんごまで何cm?」「どちらが手前?」という空間・距離感覚は育ちにくい。ロボットアームが物をつかむには後者が本質なのに、既存の訓練データは前者ばかりというギャップが問題だった。
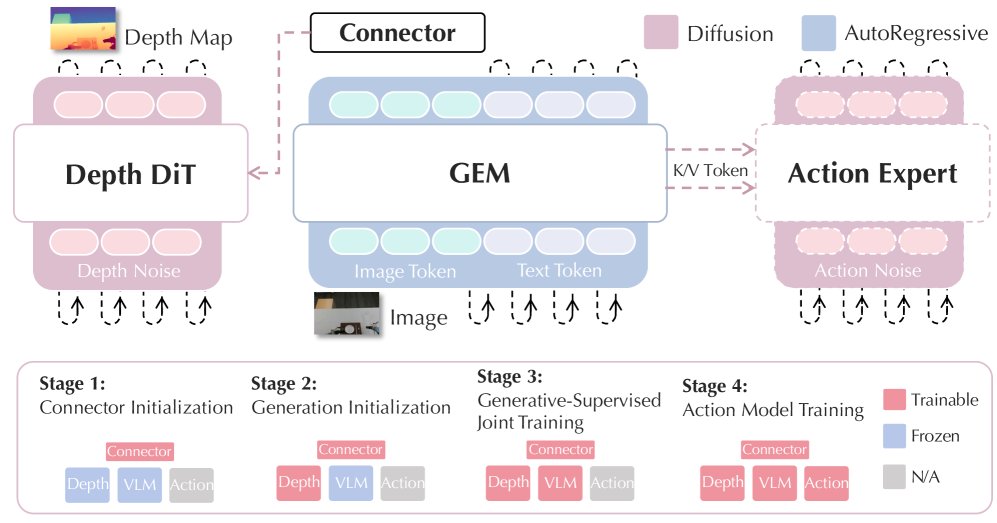
GEMの解法はシンプル。言語理解の訓練に加えて、「入力画像の深度マップ(奥行きを濃淡で表した画像)を生成しろ」という目標を同時に課す。専用の Diffusion Transformer(拡散モデルを変換器で実装した生成ヘッド)を 2 層 MLP のコネクタで VLM 本体に接続し、3段階の段階的訓練で安定収束させる。いきなり全部を同時訓練すると生成ヘッドの初期化が不十分で意味学習を邪魔するため、コネクタ初期化 → 深度ヘッド初期化 → 全体結合という順序を踏むのがポイント。
なぜ深度が効くのか。RGB再構成(元画像を生成させる)との比較実験があり、距離関係タスクで深度が一貫して上回った。深度は「物体間の距離・相対位置」のヒントを明示的に持つため、VLM の視覚特徴に幾何的な構造が自然に刷り込まれる。しかも 3D センサ不要で 2D 画像から生成できるので、既存のパイプラインへの統合コストが低い。
成果も鮮明。空間推論ベンチマーク VSI-Bench は 8B モデルで 57.9→70.6( 12.7 点)。ロボット操作シミュレーション LIBERO の平均成功率 96.1%(次点 DepthVLA 94.9%、SpatialVLA 78.1%)。実世界の UR5 ロボットアームでは 43%(前 SOTA 28.7%)。Gemini-3-Pro を空間把握で約 10% 上回る。
「奥行き生成の副目標を課す」発想は単純。でも幾何構造の学習が、操作タスク全体に波及する効果は素直に面白いかもしれない。
3
27
154
10,024