
ai researcher | making the stochastic parrot smarter @Aleph__Alpha
Joined March 2020
- Tweets 1,499
- Following 199
- Followers 1,796
- Likes 10,070
Photos and videos
Pinned Tweet

5 May 2024
A dream is what you think about before you fall asleep in your bed.
A project is what you think about in the morning when you wake up to plan your actions.
Don’t follow your dreams, build projects.
6
2
81
6,262
Alessio Serra retweeted

Jun 9
mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy


Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
359
644
5,637
3,885,294
Jun 7
efficiency goals
train: useful flops per wall-clock day, constrained by correctness, deterministic recovery, mfu and goodput.
serve: useful tokens/sec/watt, constrained by quality, long-context behavior, latency and deployment overhead.
48
Jun 6
today the problem is integrating agents into human workflows
soon the problem may be integrating humans into agent workflows
1
1
104
Alessio Serra retweeted

Jun 4
tl;dr It’s the Age of Research
Something is off about models:
1) Training is so sample inefficient
2) Very long thinking trajectories: models will do the right thing only after exhausting all other possibilities
3) Generalization is whack. Waymo can’t handle construction on highway. No teenager would have this problem.
Unclear why December was an inflection point for coding agents. No single clear attributable change.
Google is still pre-December on coding capabilities.
5-10x speed up in work. 3 weeks to implement paper in ye olden days. 2 days with codex can do many things in parallel.
Humans see, hear, talk, everything all at once. Of course that’s how it should be for models.
Big update on how quickly we got to an intern level coding agent. Didn’t expect that in 2025.
Jun 3

I sat down with @lukaszkaiser to get into whether the architecture he helped invent is actually enough, and what's next in generalization, coding agents, RL and more. Lukasz co-authored "Attention Is All You Need," the paper that introduced the transformer and worked on reasoning models at OpenAI so he’s been a key part of major shifts in the field. We hit on:
▪️ The case for and against a new architecture coming after the transformer
▪️ What’s required for model generalization in the physical world
▪️ How much coding agents have improved his AI research productivity
▪️ The next domains for RL
▪️ Why Anthropic initially won coding
▪️ Future research directions he’s excited about
0:00 Intro
1:12 Transformers vs. Human Learning
8:37 How Do We Get Physical World Generalization?
10:52 What Comes After Transformers
13:59 How Much Have Agents Improved Lukasz's AI Research Productivity?
17:21 How Close Is an AI Research Intern?
26:06 RL Beyond Verifiable Tasks
35:38 App Companies: Build Models or Lean on Labs?
46:21 Multimodal Is Still Missing Something
49:46 OpenAI's Bet on Reasoning
55:26 The AI Coding Wars
59:26 Focus vs. Keeping Embers Burning
1:02:09 Open Source vs. Closed Source Gap
1:05:15 Quickfire
YouTube: youtu.be/N1geOimmdDo
Spotify: bit.ly/4foudX0
Apple: bit.ly/4uGUhkO
2
13
179
28,864
Jun 3
nice moe design approach:
start from the serving bottlenecks in latency- and throughput-sensitive regimes, shrink the expert dimension, then reinvest the savings into larger top-k more experts.
better accuracy per flop.
arxiv.org/pdf/2601.18089

1
86
Jun 2
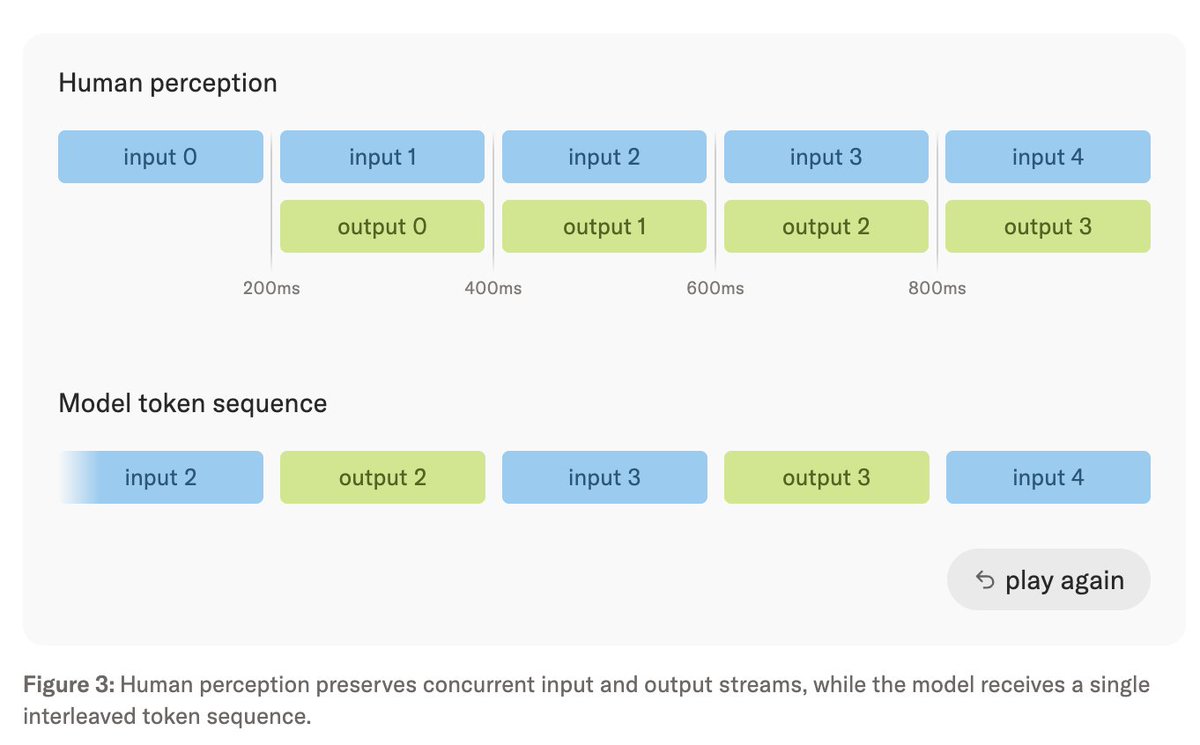
the discretization approach used here reminds me of CPU clock for synchronizing state updates
every 200ms, audio/video/text streams are sliced into one timestep and fed to the model as the next interaction step
i wonder how much you can transfer from computer architecture ideas
May 11

People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/int…
2
116
Jun 1
EMO gets semantic-level expert specialization by forcing tokens from the same document to route within a shared expert pool.
cool result: for a domain/use case, you can keep only 25% of experts and get just a 1% absolute performance drop.
arxiv.org/abs/2605.06663

1
63
Alessio Serra retweeted

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

562
1,154
10,960
4,946,357

Alessio Serra retweeted

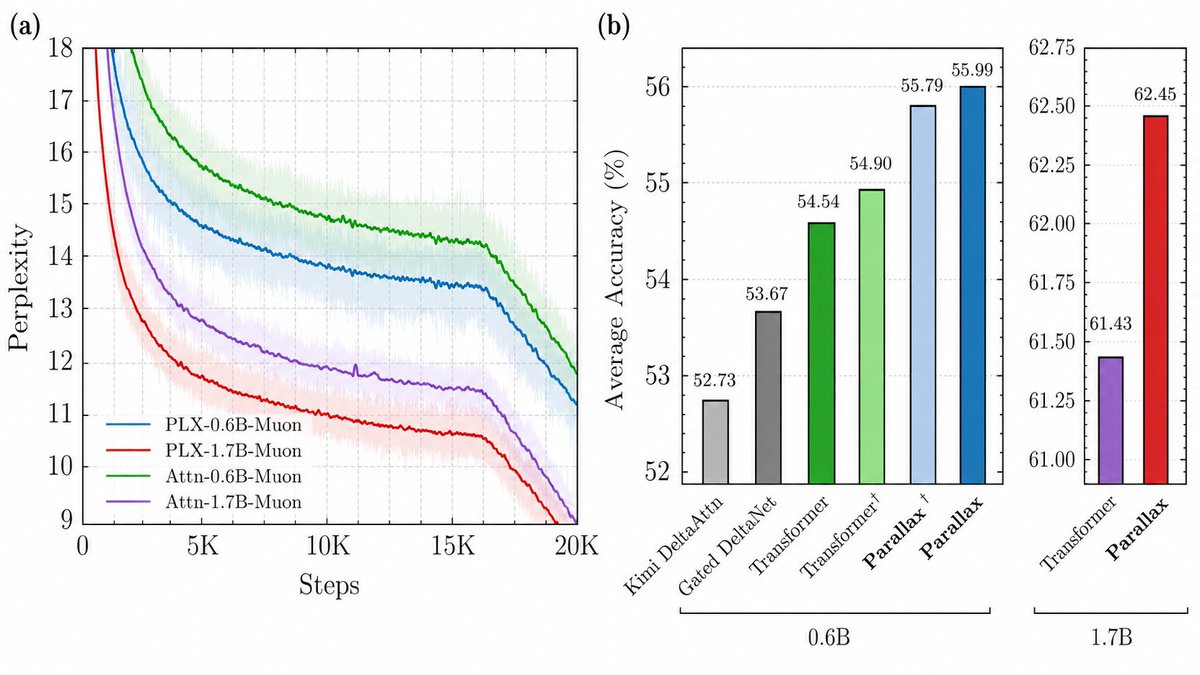
May 29
~1/7~Introducing Parallax → a stronger attention variant that achieves a Pareto improvement over vanilla attention at 0.6B and 1.7B scales.
Parallax has better perplexity, better downstream accuracy, and a decode kernel that matches or beats FlashAttention.
🧵
8
63
516
91,587
May 29
llama may have made long context extension look easier than it is.
OlmPool holds data extension fixed and finds llama 3 extends far better than qwen-3 and olmo-3, mainly because it avoids qk norm and sliding window attention while pretraining at 8K.
allenai.org/papers/olmpool

68
May 28
we need a new term for the $1T pre-IPO valuation
the second case is already within rounding distance
May 28

We've raised $65 billion in Series H funding at a $965 billion post-money valuation, led by @AltimeterCap, Dragoneer, @Greenoaks, and @sequoia.
This investment will help us advance our research and expand our capacity to meet growing demand for Claude.
2
87
May 28
wonder how much data from mythos made it into this post-train
opus 4.8’s big deltas are USAMO GraphWalks, as was for mythos

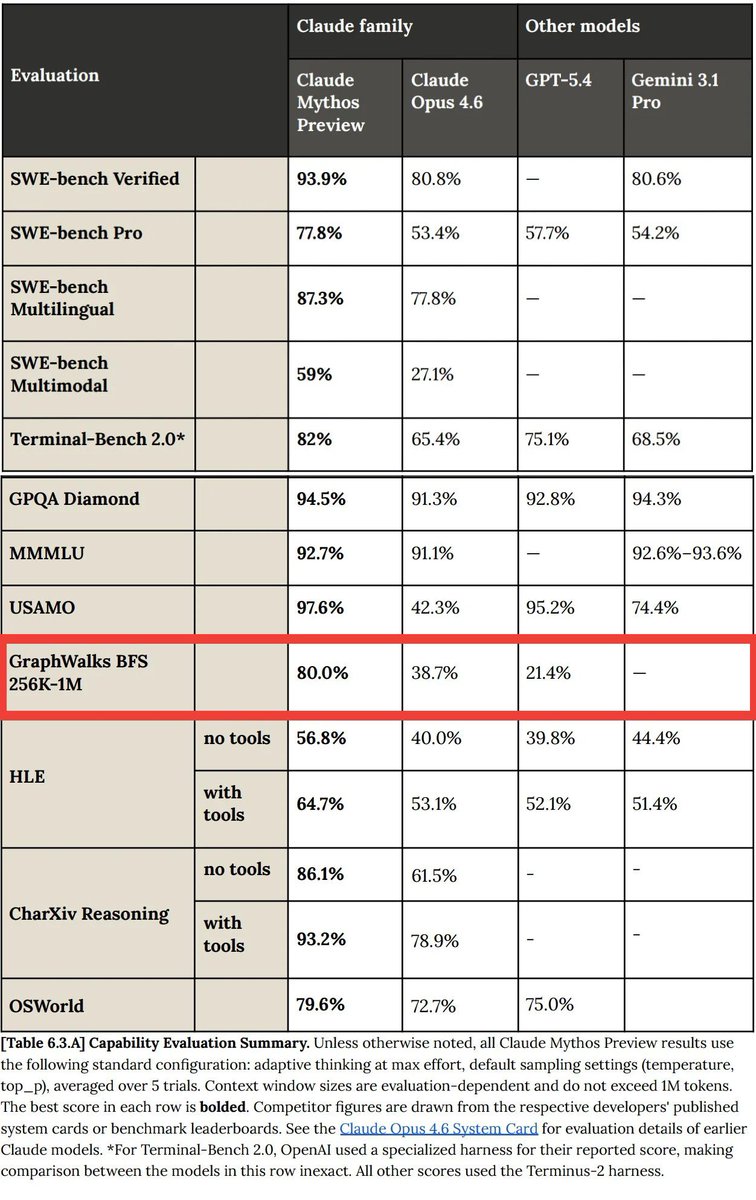
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
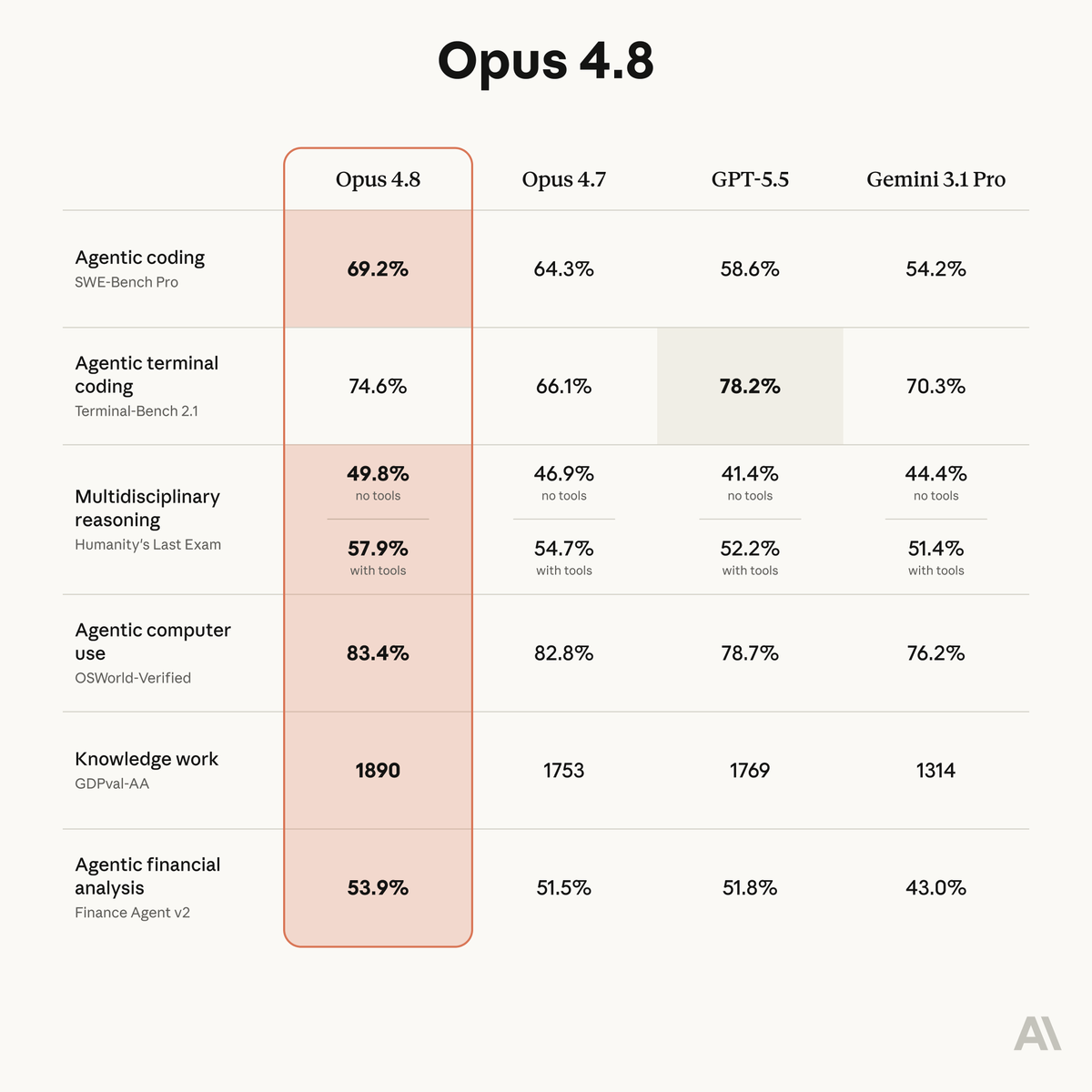
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
65
May 27
interesting direction for memory consolidation at the cache eviction boundary
before clearing a filled KV cache, the model runs N recurrent passes over accumulated context and updates persistent fast weights inside its SSM blocks
alphaxiv.org/abs/2605.26099

1
55
May 27
most impressive result is mimo-v2.5-pro from @Xiaomi
beats deepseek-v4-pro despite being smaller (1.02T-A42B vs 1.6T-A49B)
May 26

Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
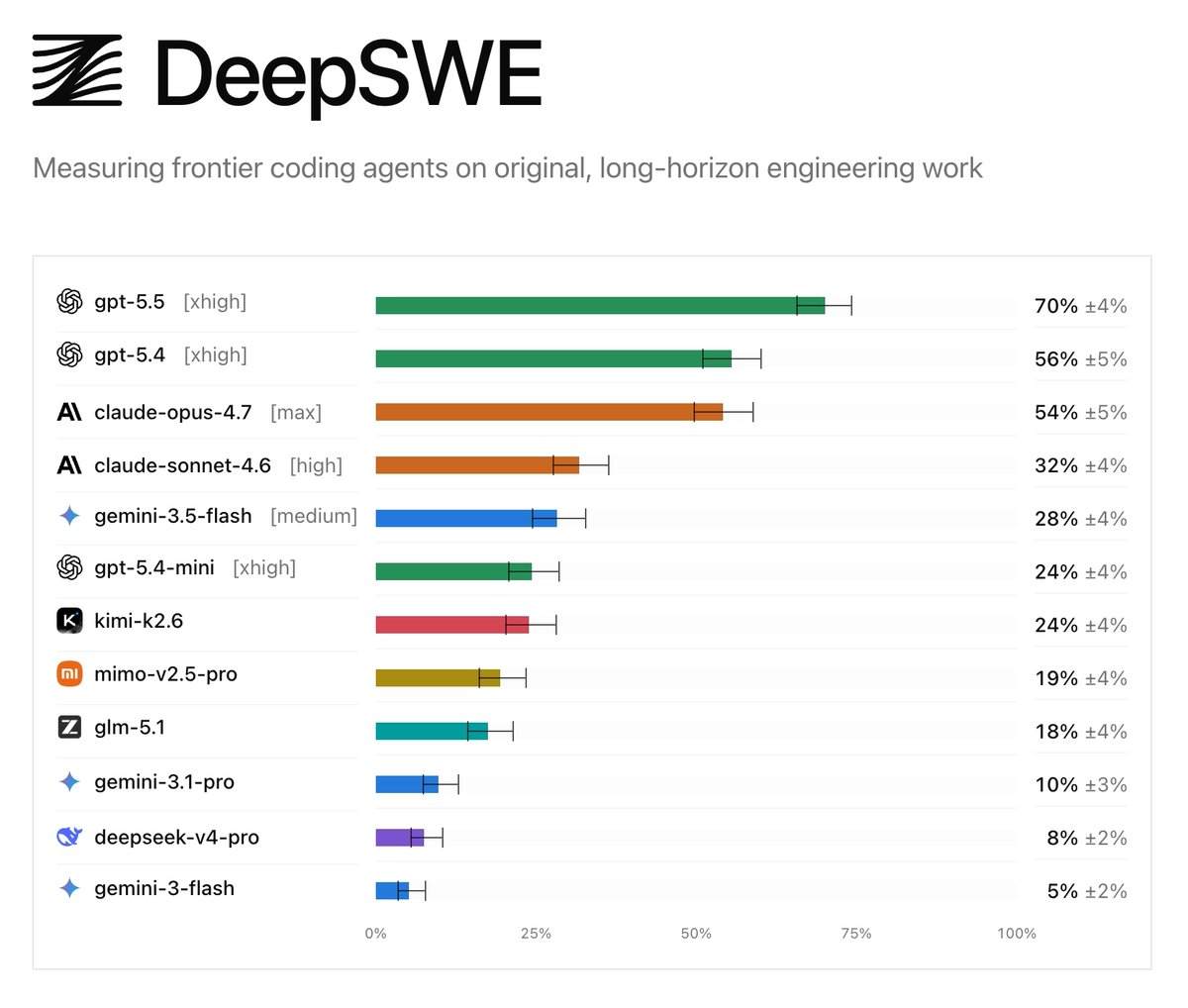
1
1
206
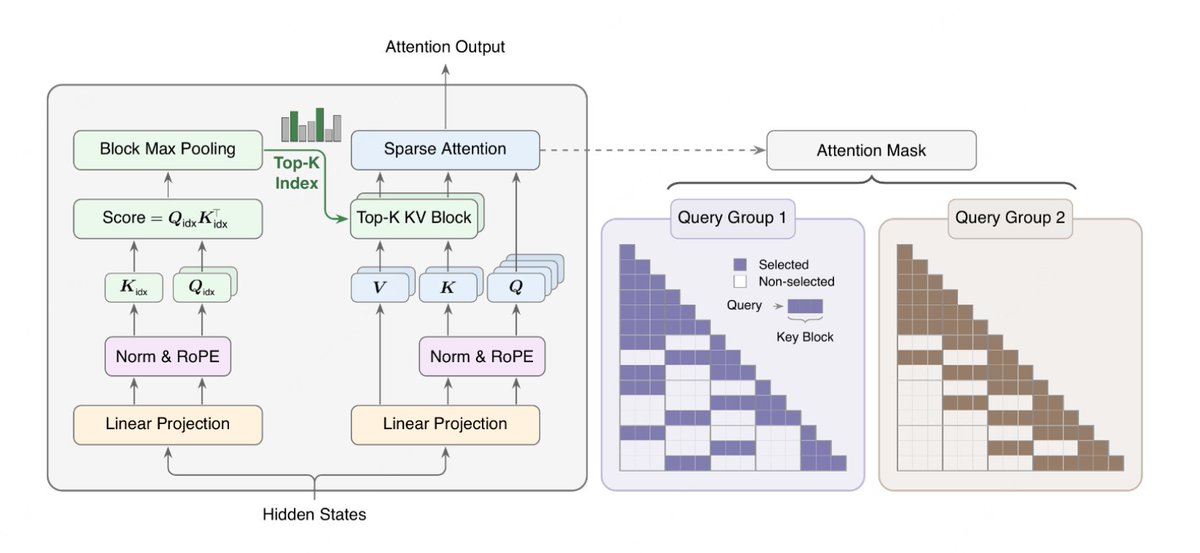
May 26
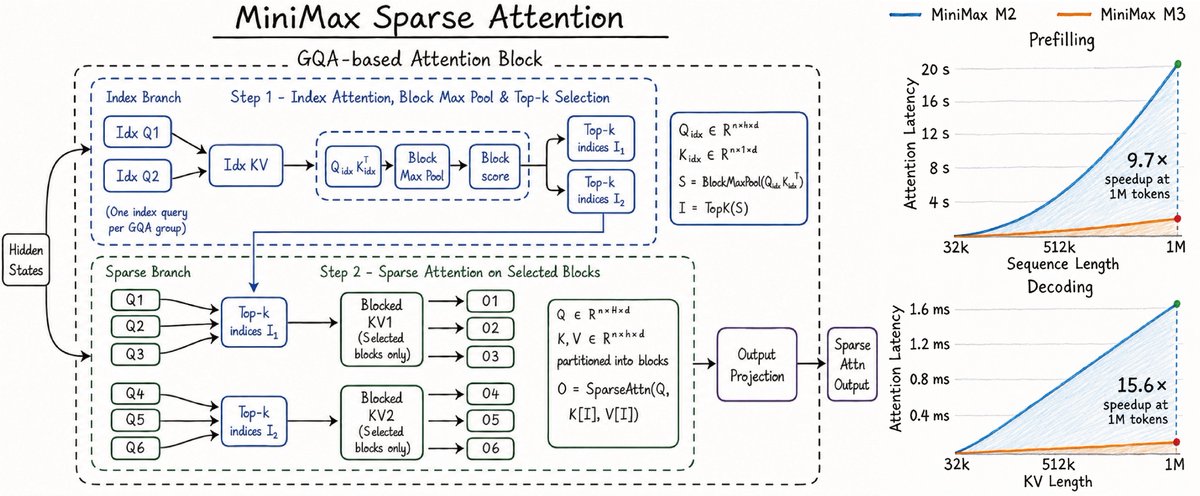
new sparse attention variant for 1M context from @MiniMax_AI
it adds a tiny GQA index branch to pick top-k KV blocks, then runs attention on the original KV for those blocks.
closer to CSA-style block routing than DSA, but without doing attention in compressed MLA space

1
1
128

May 26
the transformation from electron to tokens is such an incredible journey
2
43