
Web 3.0 investor | cofounder - @theassociat10n | AI alpha without the AI slop
Joined February 2022
- Tweets 37,005
- Following 1,922
- Followers 6,664
- Likes 65,372
3,455 Photos and videos











jAIsus retweeted

Fellow Olympians! One of our BIGGEST updates yet just dropped 🏛
NEW features across the board. Let's get into it 🧵👇
10
10
13
223
jAIsus retweeted
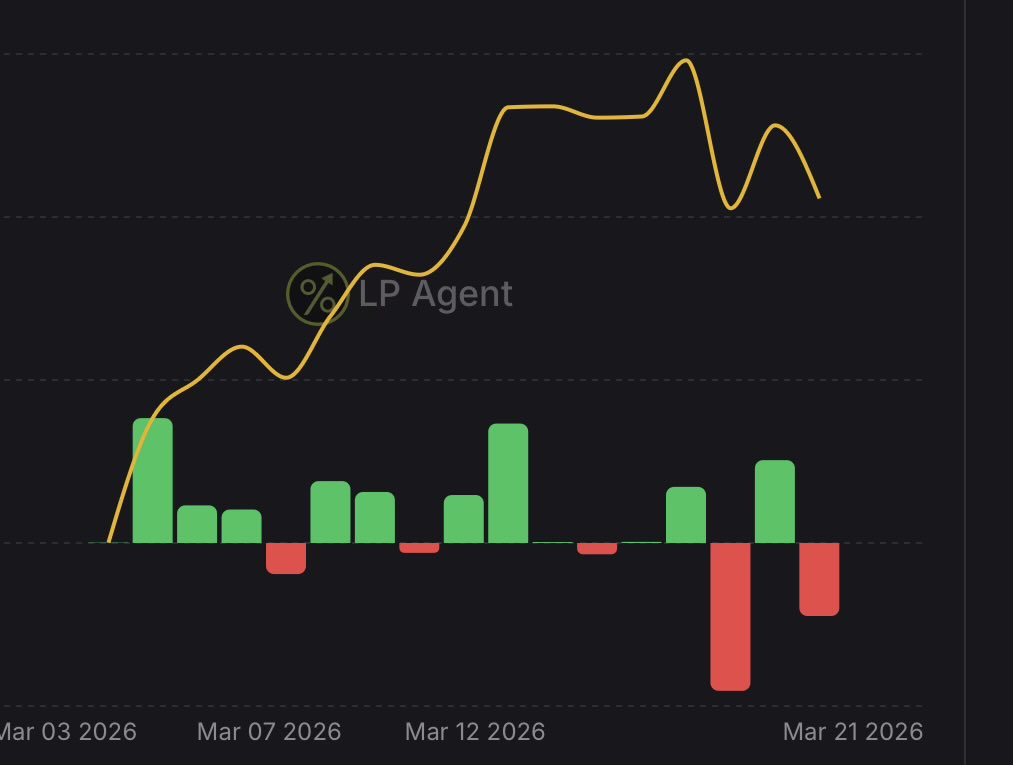
Every dollar adds up 🔥
The World Cup is going to create a ton of LP opportunities over the next few weeks with $1M they're committing.
Olympus helps you stay on top of them with Opportunity Score, Smart Filters, and automated order management.
1
1
136
jAIsus retweeted
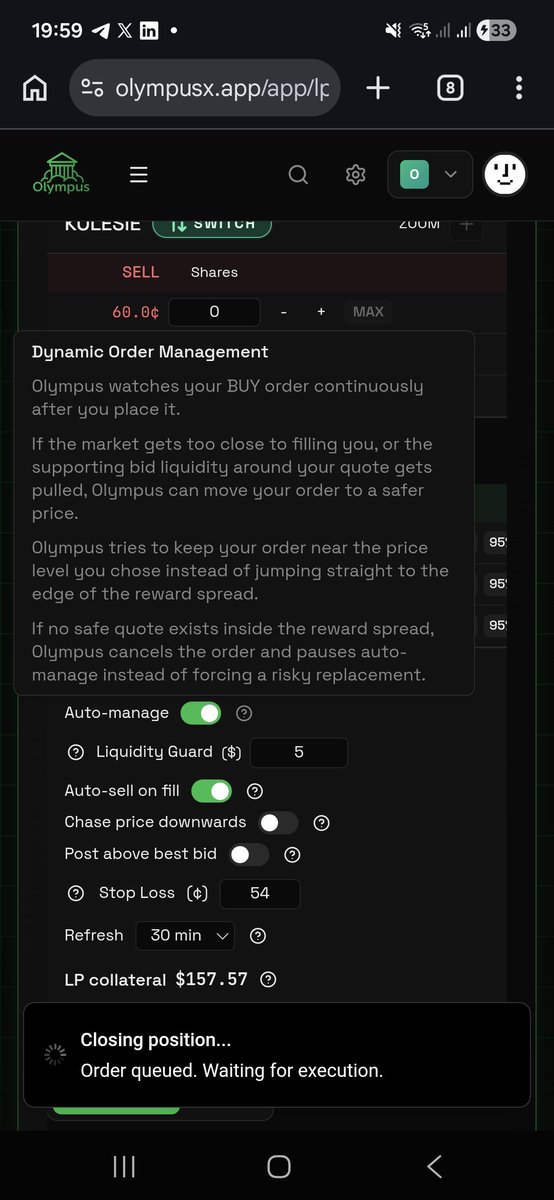
$115 in a day on day 4 is a serious milestone 🔥 as you push toward top 1% the competition gets tougher
Olympus' Liquidity Guard and Opportunity Score keep you positioned in the highest reward markets while protecting you from the bad fills that eat into those daily numbers 😮💨

1
2
3
80

If you have a RTX 5060 Ti 16GB you have to test out @UnslothAI gemma-4-26B-A4B-it-qat-GGUF
This is the first model I have tested that makes this GPU feel like a powerhouse.
Very impressed.
1
2
65



jAIsus retweeted
Please help Gretchen get her hip surgery ❤️. She's been through so much. We have donated to and fully verified this GoFundMe
gofund.me/abba44650
11
69
122
1,262
People are paying $1500 for GPUs and the most productive output from any of them is an X article.
Reminds me of the early 90s, people building PC’s. The only difference is you could make a profit from the finished product.
Currently this is just an enjoyable, expensive hobby.
2
69
jAIsus retweeted

May 27
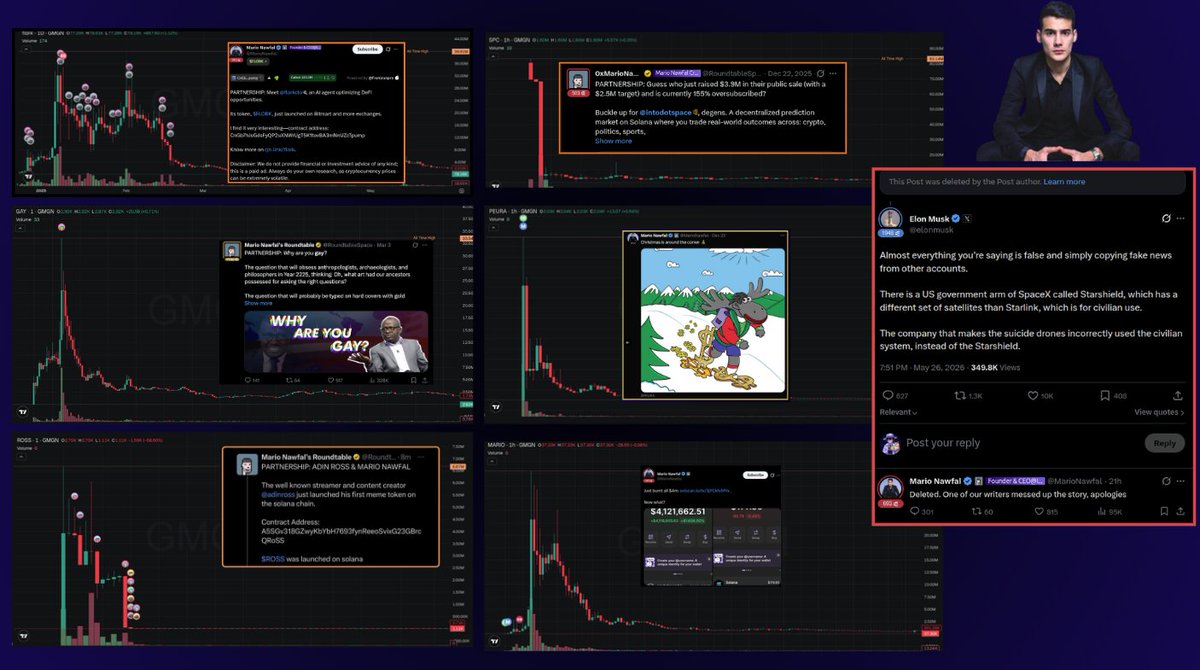
Mario Nawfal was unfollowed by Elon, who accused him of spreading fake news.
What Elon doesn't realize is that the account he made famous through constant retweets has extracted millions from its followers through crypto.
A thread on some of the biggest grifts promoted by him🧵
99
146
1,062
87,672


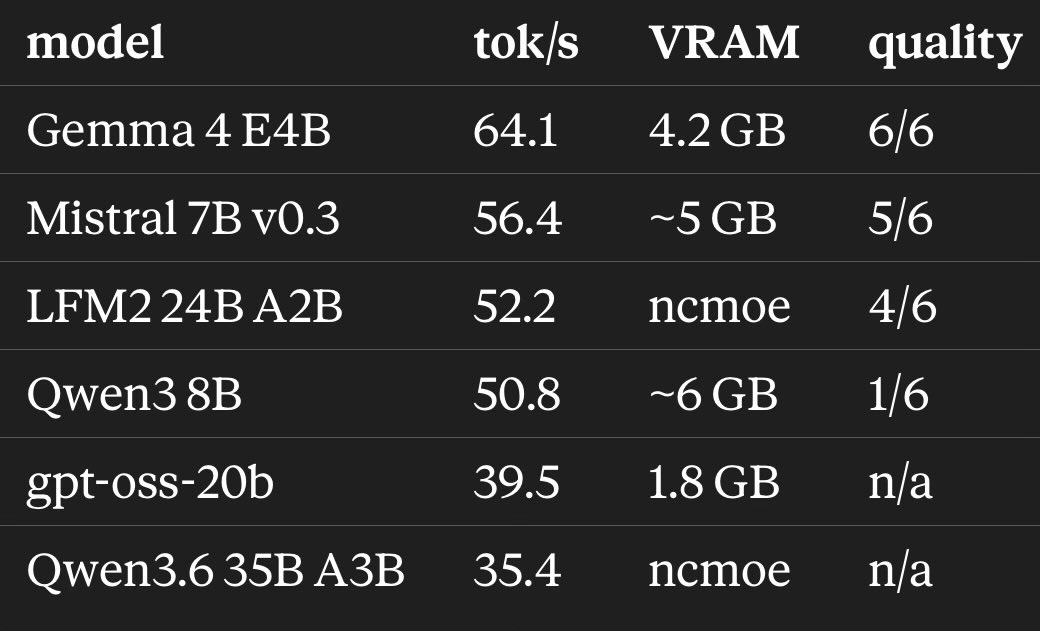
here’s the leaderboard of my benchmarks, models I tested on my little 8GB RTX
Gemma 4 E4B surprised me a lot, specially after testing other models and seeing a lot of issues with context, speed, quality or multiple at the same time
it is very decent paired with Pi
8
3
35
2,697
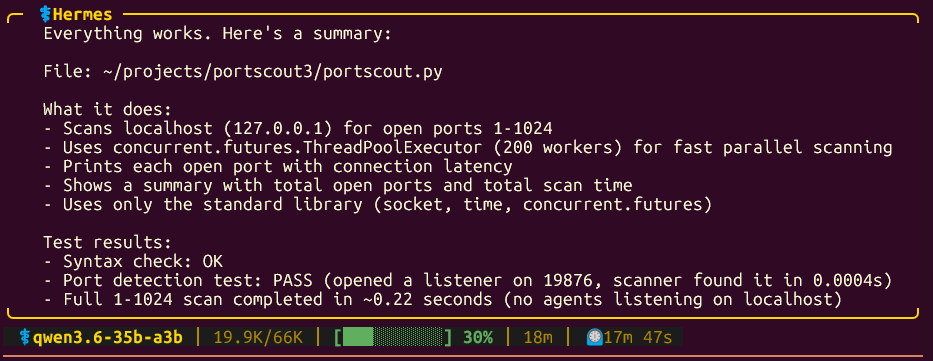
running Hermes locally with Qwen 3.6-35b-a3b is possible on a RTX 4060 Ti 8GB.
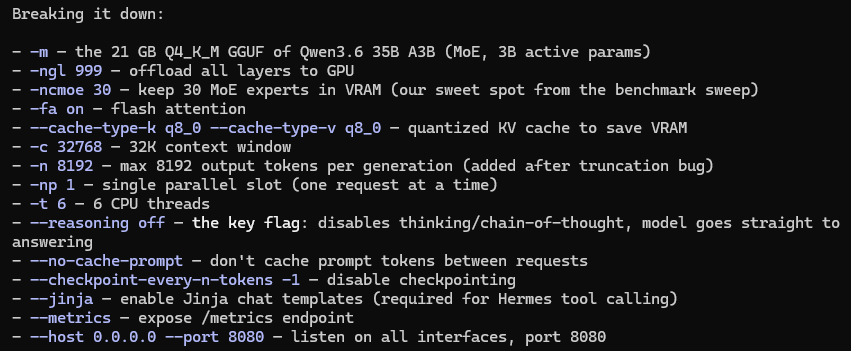
my params are:
~~~
llama-server \
-m ~/llama-models/Qwen3.6-35B-A3B-UD-Q4_K_M.gguf \
-ngl 999 -ncmoe 30 -fa on \
--cache-type-k q8_0 --cache-type-v q8_0 \
-c 32768 -n 8192 -np 1 -t 6 \
--reasoning off \
--no-cache-prompt --checkpoint-every-n-tokens -1 \
--jinja --metrics --host 0.0.0.0 --port 8080
~~~
biggest flaws:
- context: if you are coding, a few prompts will eat it all
- speed: it took 17min to create a medium-difficult .py file
but it works! I'm going to test /goal feature as well, to see how Qwen handle multiple compactions and see if it can finish a goal.
18
20
222
12,193
Llama 3.2 1B Instruct on my RTX 4060 Ti 8GB.
1.24B params, all active. dense transformer. 771 MB on disk (Q4_K_M). this is the speed ceiling test.
>228.2 tok/s at baseline. nearly 2x the next fastest model I've tested (Gemma E2B at 117.8). the GPU is barely loaded: 2.1 GB VRAM used, 5.8 GB free. prompt eval hits 16,791 tok/s at 8K context.
it degrades to 171.4 at 24K (-24.9%).
I ran the same 6 quality tests as every other model. 4/6 passed.
what works: code generation (produced a working memoized fibonacci with type hints and docstring), system prompt adherence (clean uppercase pirate), hallucination resistance (correctly said "I couldn't find any information" about a fictional study), format switching (bullets table).
what breaks: JSON compliance (added markdown fences despite "no fences" instruction), logic puzzle (interpreted the surgeon riddle as a medical ethics discussion, 8 numbered points about beneficence and the trolley problem, never figured out the surgeon is the mother).
no thinking mode. every token is content. this is why code gen works here but fails on Qwen3 8B and GLM, where reasoning consumed all 2,048 tokens without producing output.
for me this is clear: 1.24B params can follow instructions and produce structured output, but can't reason. for high-throughput classification, simple completions, or speed benchmarking, nothing touches it on this hardware.

7
2
37
2,720

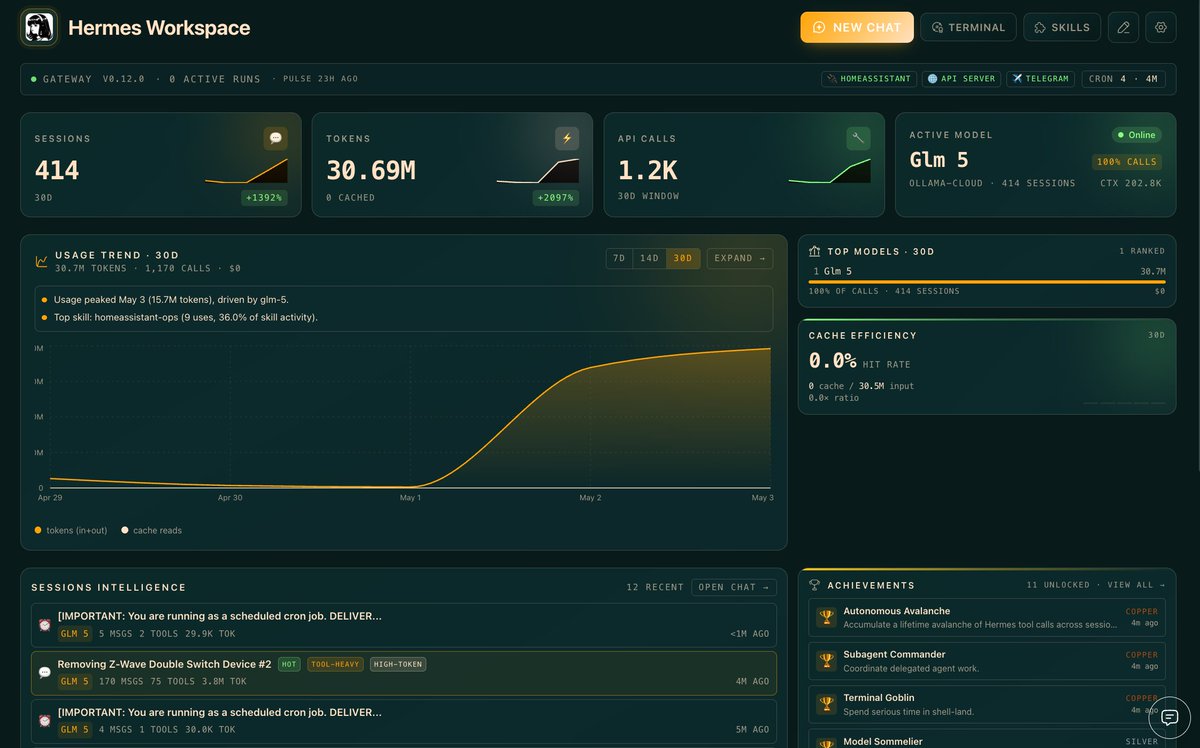
Hermes v0.14.0 is now out.
This brings the xAI Supergrok & Premium account access for Grok models, image gen, video gen, and x search
Codex as a runtime backend for openai models
LINE as a new gateway messenger
Some huge performance increases
Native video generation
Our Windows native beta
and a lot more, read the full release notes below!

97
73
978
207,102