
Be a good human. BD @TensorWaveCloud
Joined October 2010
- Tweets 2,927
- Following 0
- Followers 4,584
- Likes 8,118
212 Photos and videos














Brad Bokal retweeted

8 Oct 2024
TensorWave thinks it can break Nvidia’s grip on AI compute with an AMD-powered cloud tcrn.ch/3NnQ80Z
3
6
22
22,425

3 Aug 2024
Nvidia delays leaving you scrambling to figure out what now? Hit me up and let’s talk @AMD #MI300X we have ready to go. @tensorwave
#nvidiadelays #blackwell #gpus
2
5
592
Brad Bokal retweeted

25 Jul 2024
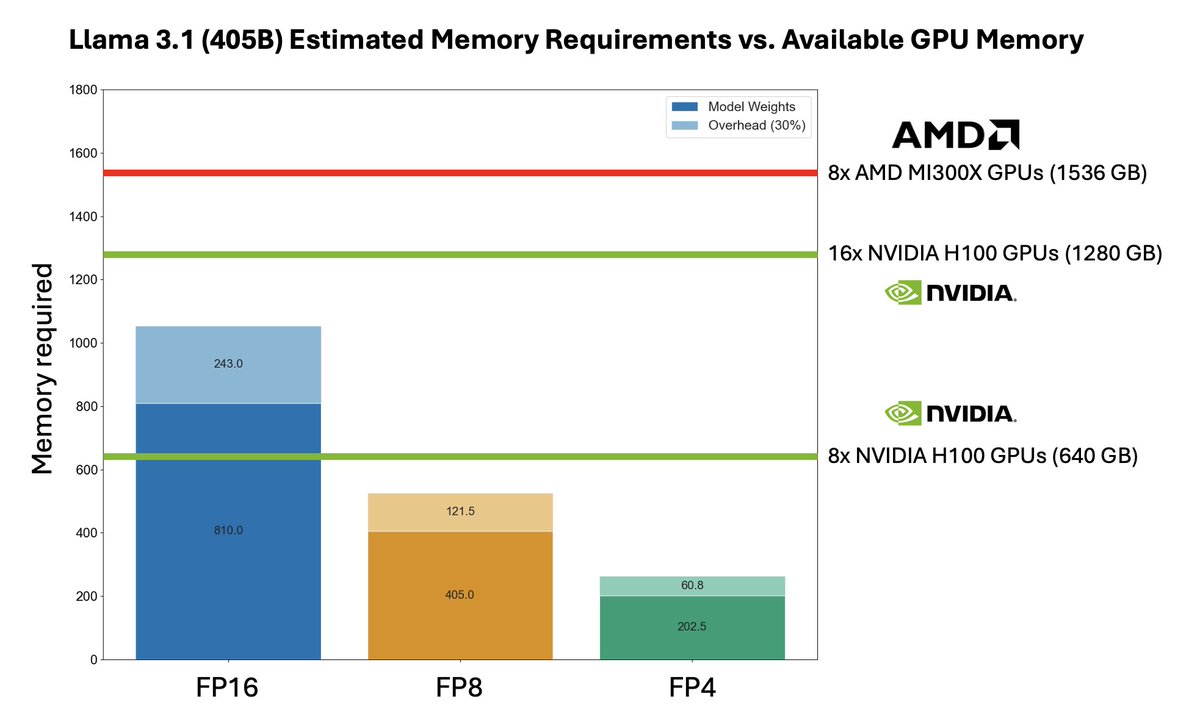
Llama 3.1 405B could be the catalyst for much greater #AMD adoption for AI inference 📈
@AMD's MI300X may be uniquely suited to cost-effective Llama 3.1 405B inference. Its 192GB of memory allows a single 8xMI300X node to serve Llama 3.1 405B in its native FP16 precision - whereas two 8xH100 nodes are required on @nvidia.
As we have previously covered, a single NVIDIA 8xH100 node only has 640GB of memory - not enough to hold Llama 3.1 405B’s full 810GB of FP16 weights in memory at once. This means that providers are forced to deploy two 8xH100 nodes with interconnect to serve 405B in FP16 precision, forcing them to accept a significant cost and complexity penalty.
Nvidia’s future H200 and B100 come with 141GB and 192GB of high bandwidth memory respectively - but unlike those, AMD MI300X is available now. @LisaSu noted on AMD’s Q2 earnings call that AMD was demand-limited on MI300X for the remainder of 2024. Will Llama 3.1 405B alone flip that narrative?
We are starting to see adoption and support increase. Both @FireworksAI_HQ and @LeptonAI are hosting Llama 3.1 405B on AMD MI300X chips. They stand out as the lowest cost providers of Llama 3.1 405B. However, it is important to note they are serving the model at FP8 and INT8 precision respectively.
Furthermore, projects like GPU.cpp from @answerdotai (@jeremyphoward, @austinvhuang) are making it easier than ever to write and run portable code across different chip (hardware & software) architectures - decreasing the CUDA lock-in.
What is your view? Long #AMD?
3
40
178
37,812
Brad Bokal retweeted

23 Jul 2024
Researchers have introduced a new method to speed up long context windows in LLMs. Their adaptive structured sparse attention mechanism reduces Time-to-First-Token latency without affecting accuracy or needing extra training. Learn more: buff.ly/4bR7NYI #LLMs #research

3
5
555

ollama run llama3.1:405b
Tested in @tensorwave with @AMD MI300X
🤯
31
125
1,073
98,164
Brad Bokal retweeted
19 Jul 2024
Milestone Unlocked 🚀 We have achieved FP8 on @AMD's MI300X.
Discover the implications for AI workloads in our latest blog post.
Click to learn more! 👉 buff.ly/3zNX7gp

4
5
19
3,207
17 Jul 2024
Running out of #compute credits? If you are a startup let’s talk. We are building something special and welcome your feedback! @tensorwave #compute #ai #GPU
49

New achievement unlocked! 🔐
Thanks to our friends over at @mkoneai & @Gradient_AI_ , we've cracked the code on a real-time chat with 1M context window using Llama 70B!
Which is cool by itself, however, thanks to our MI300X's and their massive 192GB of memory per card; These accelerators are pivotal for running long context models efficiently, allowing model parameters and large context caches to be stored on fewer cards.😎
Also I'm pretty sure the only company that's tackling this is Google’s Gemini 1.5 Pro.
However, Google's impressive models come with significant limitations:
❌ Feature Gaps: No real-time chat with cached context
❌ Limited Customization: Minimal fine-tuning capabilities
❌ Scalability Constraints: API rate limits restrict large-scale deployments
❌ Cost Inefficiency: High expenses for long context token usage
🔗 Read the full report here: lnkd.in/gZSiyiB9

5
23
1,662
Brad Bokal retweeted
16 Jul 2024
A TensorWave Report: Unlocking real-time chat with 1M context Llama3-70B model on AMD’s MI300X tensorwave.com/blog/unlockin…
4
9
558
Brad Bokal retweeted
14 Jul 2024
AMD does it again! We love to see AMD growing presence in the AI and data center market 🚀
#AMD #TensorWave #AI #CloudCompute
buff.ly/4dUyQ83
2
5
18
845
Brad Bokal retweeted

2 Jul 2024
Just dropped my first blog post (out of three) on getting started with AMD ROCm for AI! 🚀
Thanks to @tensorwave and @cognitivecompai for hooking me up with some sweet MI300x GPUs. If you're curious about AMD's answer to CUDA, check it out.
open.substack.com/pub/qnguye…

4
5
20
1,815
Brad Bokal retweeted

21 Jun 2024
Alex Rodriguez asked a question. Reggie Jackson answered it.
(Shouts to the producer and rest of the desk for staying out of Reggie’s way and just letting him talk. I doubt they expected this answer. But it’s a great few minutes of television.)
2,193
41,552
162,364
19,257,387
Brad Bokal retweeted
12 Jun 2024
A TensorWave Report: AMD’s MI300X Outperforms NVIDIA’s H100 for LLM Inference
There has been much anticipation around AMD’s flagship MI300X accelerator. With unmatched raw specs, the pressing question remains: Can it outperform NVIDIA’s Hopper architecture in real-world AI workloads? We have some exciting early results to share.
Read the full article here: blog.tensorwave.com/amds-mi3…

18
22
93
154,033

Can someone explain what @realGeorgeHotz did here?
MLPerf is a benchmark suite that is used to evaluate training and inference performance of on-premises and cloud platforms, usually used for Nvidia GPUs?
So he got an AMD GPU to benchmark on an Nvidia benchmark meaning he transliterated the Nvidia instructions for AMD GPU meaning if he continues that's Nvidia dominance over, right?
31
49
1,115
961,369
Brad Bokal retweeted

27 Mar 2024
I asked Lenovo's North American president about demand for AMD's Instinct MI300X GPU, and he gave a pretty interesting response. Note that this was before Nvidia's Blackwell announcement, but I think the comment is still very relevant. crn.com/news/computing/2024/… #amd #nvidia

1
15
63
14,662
24 May 2024
Going to the @genaisummitsf and want to talk GPUs? Ping me and let’s talk about the @AMD MI300X
1
102
Brad Bokal retweeted
30 Apr 2024
Check out this bootcamp to hear our CEO, Darrick Horton 🌊, dive into TensorWave’s real-world application of AI fabrics, showcasing our strategies in design, management, and future expansions!
#Bootcamp #AI #Event
linkedin.com/events/aiinnetw…
3
13
758
Brad Bokal retweeted

30 Apr 2024
🚀 AMD's MI300X outshines NVIDIA! TensorWave praises MI300X for AI tasks over NVIDIA’s H100.
🌐 Cost-effective, planning 20k units!
💾 Boasts 192GB HBM3e, top speed 5.3TB/sec.
🔍 Explore MI300X's impact on AI tech.
#Innovation #Tech #AMD #AI bit.ly/3Ul3DBU

2
12
952
Brad Bokal retweeted
10 May 2024
Glad to be of service 💪🌊
4 May 2024

Hey @Gradient_AI_ I converted your model into an adapter, that can be applied to any Llama3-70b to give it 524k context. Thanks @winglian for showing the way. Thanks @tensorwave and @CrusoeEnergy for providing the compute! Thanks @thomasgauthierc and @arcee_ai for the tools! Thanks to my crew @latkins and @FernandoNetoAi!

1
1
7
761
Brad Bokal retweeted
15 May 2024
Exciting collaboration alert! 🚀 Aviz and TensorWave are joining forces to enhance GPU services! Together, we're pushing the boundaries of innovation and making waves 🌊 🌊
#AI #CloudComputing #Innovation #collaboration

#AvizNetworks & #TensorWave collaborate to boost #GPU services with #RoCE-based #AIfabrics to meet the growing demands for AI-driven applications.
Read here- hubs.li/Q02xdbm60

1
9
894