
Game Dev, Freelancer and Remote Worker since 2015
Joined August 2013
- Tweets 4,845
- Following 619
- Followers 300
- Likes 6,844
255 Photos and videos



My friends have their board game live on @Kickstarter – only 2 more hours to go!!
Give Boardquest: Tales of Liria a little boost if you got $1 to spare.
Or get the whole thing if you're into board games. 🎲🎲
kickstarter.com/projects/boa…
1
1
1
68

10 Mar 2024
Only few days to go with our campaign on Kickstarter. Pledge now and become part of our Credits section!!
#kickstarter #boardgame #tabletopgames #boardquest #talesofliria
kickstarter.com/projects/boa…
2
128
Behsaad Ramez retweeted

28 Feb 2024
Continue your career with Larian Studios.
We're currently taking applications for numerous new roles across our departments, and encourage you to register with us even if you don't see your specific role!
larian.club/ApplyNow

336
2,109
11,512
707,009
Behsaad Ramez retweeted

22 Feb 2024
Nos ha gustado Boardquest: Tales of Liria. ¡Y en español!
buff.ly/3T6jTat

1
2
201
24 Feb 2024
Our game just got funded on kickstarter:
kickstarter.com/projects/boa…
We may or may not go to retail with this, so grab the opportunity to get a copy now!
#talesofliria #boardquest #kickstarter #boardgame
1
3
5
241
Behsaad Ramez retweeted

22 Feb 2024
Jake has been around releasing indie games and sharing his knowledge with devs for forever. He might be the world’s foremost expert on solitaire game design at this point ?! x.com/GreyAlien/status/17606…
22 Feb 2024

LAUNCH ANNOUNCEMENT!
Regency Solitaire II is now out on Steam and @itchio
Steam: store.steampowered.com/app/2… (please leave a review)
Itch: greyaliengames.itch.io/regen… (we make more $ if you buy it here)
Enjoy and please RT! Thanks :-)
1
11
52
12,020
Behsaad Ramez retweeted

21 Feb 2024
Amigos. Les comparto este Kickstarter de un proyecto en el que participé el año pasado haciendo vfx y sfx.
Es un juego de mesa su versión en videojuego:
kickstarter.com/projects/boa…
1
1
5
210
21 Feb 2024
Wir sind jetzt live auf kickstarter kickstarter.com/projects/boa…, wenn ihr möchtet, könnt ihr uns supporten, kleine beträge wie unter 10€ helfen auch sichtbarkeit zu erhöhen. Ende der Werbedurchsage 😀
1
28
13 Feb 2024
For anyone looking for a board game that combines fantasy strategy with fast paced yet deep mechanics look no further and subscribe to Boardquest: Tales of Liria launching on February 21 2024 #boardgame #kickstarter #tabletoprpg backerkit.com/call_to_action…
2
29
Behsaad Ramez retweeted

23 Nov 2023
OpenAI leaked Q* so let’s dive into Q-Learning and how it relates to RLHF.
Q-learning is a foundational concept in the field of artificial intelligence, particularly in the area of reinforcement learning. It's a model-free reinforcement learning algorithm that aims to learn the value of an action in a particular state.
The ultimate goal of Q-learning is to find an optimal policy that defines the best action to take in each state, maximizing the cumulative reward over time.
Understanding Q-Learning
Basic Concept: Q-learning is based on the notion of a Q-function, also known as the state-action value function. This function takes two inputs: a state and an action. It returns an estimate of the total reward expected, starting from that state, taking that action, and thereafter following the optimal policy.
The Q-Table: In simple scenarios, Q-learning maintains a table (known as the Q-table) where each row represents a state and each column represents an action. The entries in this table are the Q-values, which are updated as the agent learns through exploration and exploitation.
The Update Rule: The core of Q-learning is the update rule, often expressed as:
\[ Q(s,a) \leftarrow Q(s,a) \alpha [r \gamma \max_{a'} Q(s', a') - Q(s, a)] \]
Here, \( \alpha \) is the learning rate, \( \gamma \) is the discount factor, \( r \) is the reward, \( s \) is the current state, \( a \) is the current action, and \( s' \) is the new state. (See image below).
Exploration vs. Exploitation: A key aspect of Q-learning is balancing exploration (trying new things) and exploitation (using known information). This is often managed by strategies like ε-greedy, where the agent explores randomly with probability ε and exploits the best-known action with probability 1-ε.
Q-Learning and the Path to AGI
Artificial General Intelligence (AGI) refers to the ability of an AI system to understand, learn, and apply its intelligence to a wide variety of problems, akin to human intelligence. Q-learning, while powerful in specific domains, represents a step towards AGI, but there are several challenges to overcome:
Scalability: Traditional Q-learning struggles with large state-action spaces, making it impractical for real-world problems that AGI would need to handle.
Generalization: AGI requires the ability to generalize from learned experiences to new, unseen scenarios. Q-learning typically requires explicit training for each specific scenario.
Adaptability: AGI must be able to adapt to changing environments dynamically. Q-learning algorithms often require a stationary environment where the rules do not change over time.
Integration of Multiple Skills: AGI implies the integration of various cognitive skills like reasoning, problem-solving, and learning. Q-learning primarily focuses on the learning aspect, and integrating it with other cognitive functions is an area of ongoing research.
Advances and Future Directions
Deep Q-Networks (DQN): Combining Q-learning with deep neural networks, DQNs can handle high-dimensional state spaces, making them more suitable for complex tasks.
Transfer Learning: Techniques that enable a Q-learning model trained in one domain to apply its knowledge to different but related domains can be a step towards the generalization needed for AGI.
Meta-Learning: Implementing meta-learning in Q-learning frameworks could enable AI to learn how to learn, adapting its learning strategy dynamically - a trait crucial for AGI.
Q-learning represents a significant methodology in AI, particularly in reinforcement learning.
It is not surprising that OpenAI is using Q-learning RLHF to try to achieve the mystical AGI.

23 Nov 2023

What is the RLHF that OpenAI’s secret Q* uses ?
So let’s define this term.
RLHF stands for "Reinforcement Learning from Human Feedback." It's a technique used in machine learning where a model, typically an AI, learns from feedback given by humans rather than solely relying on predefined datasets.
This method allows the AI to adapt to more complex, nuanced tasks that are difficult to encapsulate with traditional training data.
In RLHF AI initially learns from a standard dataset and then its performance is iteratively improved based on human feedbacks.
The feedback can come in various forms, such as corrections, rankings of different outputs, or direct instructions. The AI uses this feedback to adjust its algorithms and improve its responses or actions.
This approach is particularly useful in domains where defining explicit rules or providing exhaustive examples is challenging, such as natural language processing, complex decision-making tasks, or creative endeavors.
This is why Q* was trained on logic and ultimately became adapt at simple arithmetic.
It will get better over time, but this is not AGI.
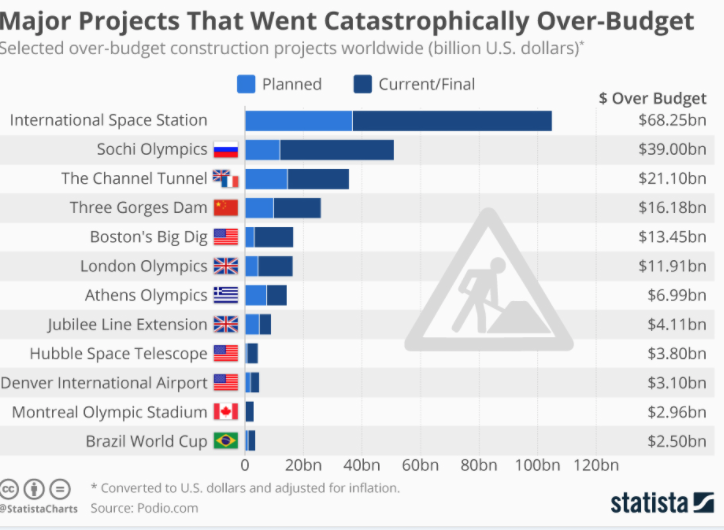
This graphic below is an overview and history of RLHF
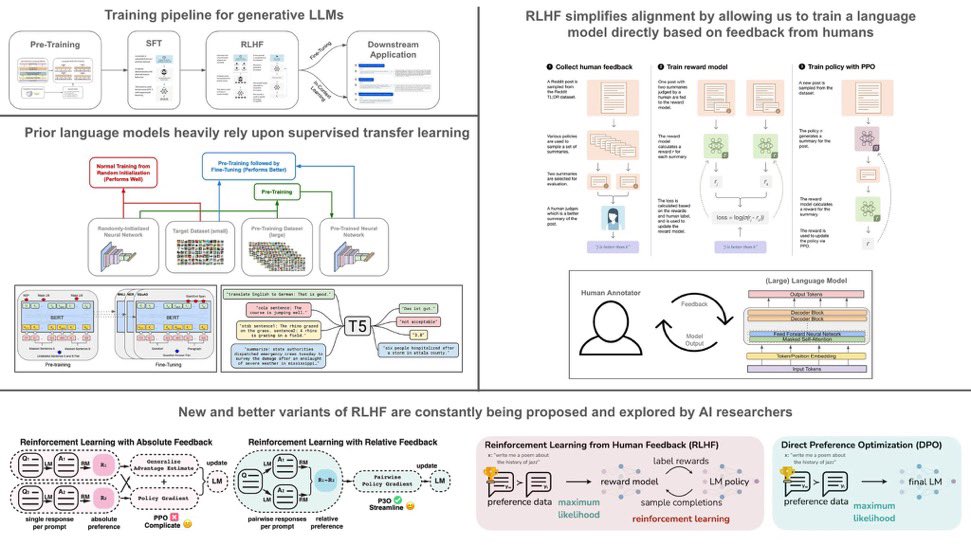
128
768
3,502
2,620,304

Tonight’s performance at Apple Puerta del Sol in Madrid made me a Guitarricadelafuente fan for life! It was an unforgettable moment with customers and our team.

ALT Tim and Guitarricadelafuente take a selfie together in front of a crowd of people at Apple Puerta del Sol.
229
803
11,772
1,401,261
Amazing meal with the incomparable chef @Dabizdiverxo at Lhardy in the heart of Madrid — with the best cocido madrileño! Thanks, Dabiz, for sharing how you’re using iPhone 15 Pro Max in your creative process!

ALT Tim and chef Dabiz Muñoz sit at a counter at Lhardy and chat over a meal.
225
769
10,342
1,730,860

Here is an open letter to our community:
on.unity.com/48rGiVu
2,089
2,583
10,786
6,922,314

Programming with GPT sucks and the programmers that are still writing code instead of prompts are superior. There, I said it.
👇This is a 2min story with the reasoning behind that statement.
Yes, of course it can help add a border to your button. And sure, you can ask it to loop through that array and do smth with the results.
But when a real complex problem comes around, such as the one I had today, it's absolutely garbage and continues to make mistakes and more obscure problems. It even lies about nonexisting functions or parameters. It's like pair-programming with a really, really, really dumb developer.
But here is the real kicker. As I dove into solving this problem with GPT instead of my own brain, I started noticing that I couldn't come up with any of the solutions myself anymore. I couldn't really modify GPT's code. My brain just wasn't capable. All I could do was re-prompt, try to be more specific and hope for the best.
I think this is because my brain didn't come up with the code itself. So it can't really comprehend what's going on easily, even if I read it, and it takes much more time than just coming up with it myself right away. That extra layer, it just turned into a burden.
The fact that this effect kicked in just mere hours after trying to use GPT for this programming problem, tells me that any programmer that starts to rely on GPT prompting too much, is done for.
The moment a real complex problem comes around, you're going to spend 10x the amount of time and all the time gains you got from GPT generating some of your button borders have now evaporated.
99
40
313
249,856
Behsaad Ramez retweeted

13 Jul 2023
161
2,874
9,301
973,843

Solasta is doing really well on a small budget. I promise you, in this specialist genre, there is room for everyone. Especially those without the bells and whistles. I’ll talk about this on greater depth one day, but not for now. There’s over 9 million CRPG players to play with.
1
2
23
1,724
Behsaad Ramez retweeted

4 Jul 2023
It died. I have worked for a startup in the past where we had a monolith and started separating it into 7 microservices before the product was even launched. Guess what happened?
1
2
120
32,603